


摘" 要:人工智能技术的迅猛发展,尤其是大语言模型(LLM)在自然语言处理领域的突破性进展,为教育数字化转型带来了新机遇。聚焦计算机类专业的数据结构课程的学习难题,利用开源LLM开发平台Dify,整合知识点文本表征、检索增强和文本生成等核心技术,设计并实现了一款智能学习助手。通过整合多源知识库,助手能精确匹配学生的个性化问题,并生成于学生问题意图一致的答案。实验结果表明,学习助手在辅助学生学习、提升学习效率以及减轻教师教学负担方面效果显著。
关键词:大语言模型;检索增强生成;智能学习助手
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2025)03-0050-06
Design and Implementation of Intelligent Learning Assistant Based on Large Language Model
ZHA Yinghua1, GUO Zhaoxia1, JU Huiguang2
(1.Nanjing Vocational University of Industry Technology, Nanjing" 210023, China;
2.Nanjing ASGEO Information Technology Co., Ltd., Nanjing" 211101, China)
Abstract: The rapid development of Artificial Intelligence technology, especially the breakthrough progress of Large Language Model (LLM) in Natural Language Processing field, has brought new opportunities for the digital transformation of education. Focusing on the learning difficulties of the data structure course in computer-related majors, using the open-source LLM development platform Dify, and integrating core technologies such as knowledge point text representation, retrieval enhancement, and text generation, an intelligent learning assistant has been designed and implemented. By integrating multisource knowledge bases, the assistant can accurately match students personalized questions and generate answers consistent with the intent of students questions. Experimental results show that the learning assistant has significant effects in assisting student learning, improving learning efficiency, and reducing the teaching burden on teachers.
Keywords: Large Language Model; retrieval-augmented generation; intelligent learning assistant
0" 引" 言
在人工智能的发展历程中,大语言模型(Large Language Model, LLM)的崛起标志着一个重要的转折点。它们不仅在自然语言理解领域取得了显著成就,而且在文本生成、知识问答和逻辑推理等高级认知功能上展现出卓越的能力[1]。例如,ChatGPT、通义千问和文心一言等生成式AI应用,已经能够与人类进行符合语言习惯的情境化交互,这为教育领域的数字化和智能化转型提供了前所未有的机遇和挑战[2]。
然而,LLM在带来革命性效果的同时,也存在一些亟待解决的问题。由于模型的知识基础主要来源于训练数据,而现有的主流大模型多基于公开数据构建,难以获取实时性、非公开或专业领域的知识,这导致了知识的局限性。当遇到未在训练中学习过的问题时,模型可能会产生不准确或有偏见的内容,甚至编造信息,从而误导信息接收者[3]。在高等教育领域,这种误导可能会使学生对专业知识产生错误的理解,影响知识体系的准确性,甚至导致整个知识体系出现偏差,进而影响教育的价值[4]。
为了解决这些问题,研究者们提出了微调(Fine-Tuning)和检索增强生成(Retrieval-Augmented Generation, RAG)等技术。微调技术通过使用特定领域的数据集对预训练模型进行进一步训练,以提高模型在特定任务或领域的表现。然而,这一过程需要大量高质量的标注数据和计算资源[5]。相比之下,RAG技术结合了信息检索和文本生成,通过检索外部知识库中的信息来引导生成过程,从而提高内容的准确性和相关性[6]。RAG技术因其高可用性和低门槛,已成为LLM应用中最受欢迎的方案之一。
本文以计算机专业的数据结构课程为例,探讨了基于LLM的课程学习助手的设计和实现,旨在帮助学生更有效地掌握专业基础知识,同时减轻教师的教学压力。
1" RAG应用研究现状
RAG技术的核心理念在于融合检索机制与生成模型,最初由Lewis等人[7]于2020年提出。随着LLM时代的到来,RAG技术通过整合LLM的参数化知识和外部知识库的非参数化知识,增强了模型对背景知识的理解,提升了AI在处理知识密集型任务时的表现,以及生成内容的准确性和可信度。
RAG作为一种前沿的生成式AI技术,已在多个行业领域展现了巨大的应用潜力。在知识管理方面,周扬等人[8]设计了一套基于RAG技术的企业知识管理系统方案,通过检索前处理、知识检索、检索后处理等全流程检索技术提高知识构建的效率和检索的精确度。在问答系统方面,张鹤译等人[9]研究了结合大语言模型和知识图谱的问答系统,针对中医药领域,通过信息过滤、专业问答和知识抽取转化等技术提升了系统性能,为专业领域问答提供了新方法。在代码生成领域,Su等人[10]提出了一种名为ARKS的策略,该策略将LLM应用于代码生成,通过创建一个集成网络搜索、文档、执行反馈和代码演化的知识综合体,从而提高了LLM在代码生成中的执行精度。
教育领域对RAG技术的兴趣也与日俱增。余胜泉等人[11]开发了一种基于RAG的通用人工智能教师模型,该模型通过精调训练、检索增强认知、外部智能组件编排等手段,提升了LLM在教育场景中的应用能力。卢宇等人[12]的研究探讨了基于大模型的教学智能体的构建与应用,提出了一个包含教育任务设定、规划、能力实现、内容记忆与反思以及交互协作等模块的框架,旨在实现个性化教学和动态进化。
目前,教育领域主要采用基于ChatGPT的教学应用,对RAG技术的研究和应用相对有限。本文提出了一种智能学习助手,该助手利用RAG开源框架Dify的LLM语义表征、文本生成能力以及RAG的知识检索能力,整合课程相关的数字教材、教学辅导材料和网络资源等外部知识源,通过融合提示词和专业数据集,构建针对专业学习场景的个性化学习工具,扩展学生对数据结构的深入理解和应用能力。
2" RAG系统的架构分析
2.1" RAG的基础架构
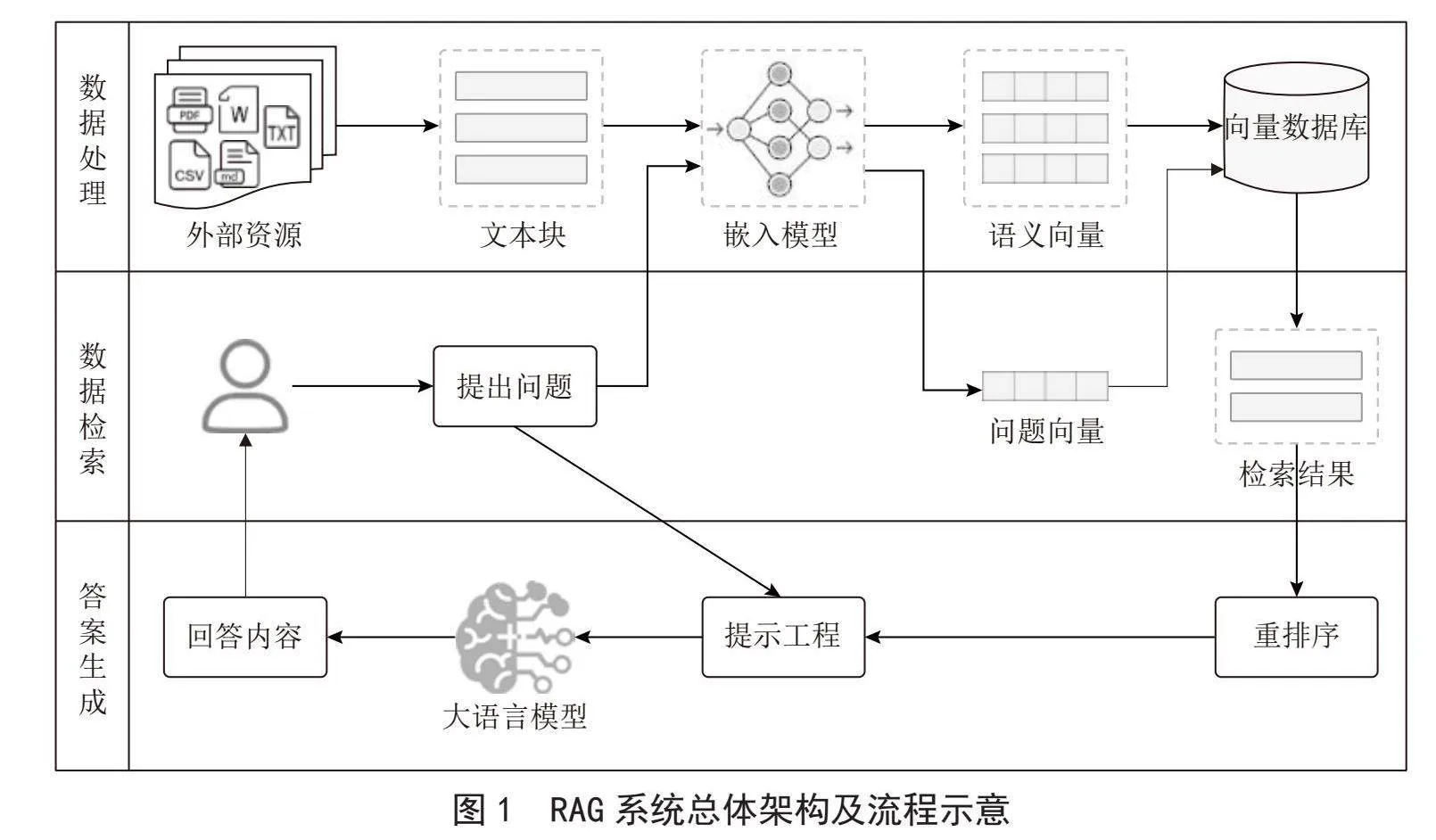
Zhao等[13]将RAG的基础范式根据检索器增强生成器的方式分为四类:基于查询的RAG、隐空间表示型RAG、概率表征型RAG以及投机性RAG。其中,基于查询的RAG时最为广泛使用的范式。在LLM生成文本响应之前,该方法首先从知识库检索并召回相关的文本信息,以此增强和扩展LLM的初始输入信息,其基础架构及流程如图1所示。
2.1.1" 数据处理
数据处理是将本地数据资源转为向量,建立索引并存入向量数据库的离线过程,也就是知识库构建过程,主要步骤包括数据提取、文本分割、向量化和入库等。
数据提取阶段主要针对PDF、DOCX、CSV等各种格式文档进行预处理,包括去重、过滤、删除不相关内容等,提取高质量的可用文本。文本分割阶段需考虑嵌入模型的Tokens限制、保持语义的完整性以及相关上下文的连贯性,常用的分割方法包括基于固定大小的分块方法和基于语义单元的分块方法。向量化阶段则是使用嵌入模型将文本转为用于语义搜索的嵌入向量,常用的文本类嵌入模型包括OpenAI的text-embedding系列、MokaAI的M3E等。入库阶段首先构建向量与文本块之间的索引,然后将其写入向量数据库,适用于RAG的数据库包括Chroma、Weaviate、Milvus等。这些数据库能够高效地支持向量检索,从而实现快速而准确的信息检索功能。
2.1.2" 数据检索
数据检索阶段的主要流程包括构建问题向量、执行检索以及结果重排序。首先,采用诸如BERT、GPT系列等预训练模型将用户问题转化为数值化的向量表示,该向量作为后续检索操作的基础查询向量。然后,通过计算查询向量与向量库中文档或信息片段的向量表示之间的相似度,根据得分检索最相关文档。最后,鉴于检索结果可能包含多个候选文档或信息片段,对其进行进一步筛选和排序以优化检索质量,一般通过对结果进行Top K筛选和Score阈值优化结果的准确性,还可以结合Rerank模型进行语义排序,提高与用户问题的相关性。
检索过程可采用向量检索、全文检索或混合检索等策略,其中向量检索擅长处理具有复杂语义的查询,全文检索则更适合精确匹配较短的字符序列或低频词汇。
2.1.3" 答案生成
在生成答案的过程中,首先进行信息整合。此步骤包括将从检索到的相关信息片段整合成连贯的上下文,作为构建一个或多个候选答案的基础。此阶段需要处理信息片段间的冗余、不一致或矛盾之处,确保生成的回答既准确又具有一致性。然后利用LLM的智能问答能力来生成答案。
生成过程通常涉及一系列技术手段,如多轮对话、条件生成以及提示工程等。其中,提示工程通过结合候选答案、原始问题以及精心设计的提示词等策略,引导模型生成准确且高度相关的回答,显著提高生成的答案与用户问题之间的匹配度,提升用户的总体满意度和交互体验。
2.2" Dify的核心组件
Dify是一个专为LLM的开发和运维而设计的低代码开源平台,其核心目标在于简化并加速生成式AI应用的创建与部署过程。该平台集成了构建LLM应用所需的关键技术,包括对数百种模型的支持、直观的提示编排界面、高质量的RAG引擎、Agent框架以及灵活的工作流编排能力。此外,Dify还提供了一套用户友好的界面和API,为开发者节省了许多重复造轮子的时间,使其专注于业务需求和技术创新上。
2.2.1" RAG引擎模块
Dify的RAG引擎采用模块化设计,包含文件加载、预处理、检索和检索结果重排等模块。文件预处理模块支持自定义分隔符、设置token大小对文档进行分段,并采用Qamp;A分段技术对每个段落进行QA转化。相较于传统的“Q2P”(问题匹配段落)模式,Dify采用的“Q2Q”(问题匹配问题)模式能够在用户提问时找出与之最相似的问题,进而返回对应的分段作为答案,这种方式更直接地识别和响应用户问题。
Dify平台提供了三种高效的检索策略:向量检索、全文检索以及混合检索。向量检索基于近似最近邻(ANN)查询,通过Top-K筛选和Score阈值机制确保检索结果的相关性。全文检索基于BM25算法,专注于简短文本的精确匹配,确保查询的准确度。混合检索则结合了这两种方法的优势。为增强检索效果,Dify提供了N选1召回和多路召回两种召回算法,多路召回能够并行检索多个知识库,扩展信息来源。Dify还可以应用Rerank模型对检索结果进行语义重排,确保用户获得最匹配的Top-K结果。
2.2.2" 工作流编排模块
在优化复杂任务处理的框架中,工作流扮演了至关重要的角色,它通过将繁复的任务解构为一系列逻辑清晰、规模适中的节点,降低系统的内在复杂度,并减轻对精细提示工程及模型高级推理能力的直接依赖。Dify提供了两种类型的工作流应用:一是针对对话式应用场景的聊天流(Chatflows),适用于客户服务、语义搜索等场景;二是面向自动化/批量处理任务的工作流(Workflows),适用于数据分析、内容生成等任务。
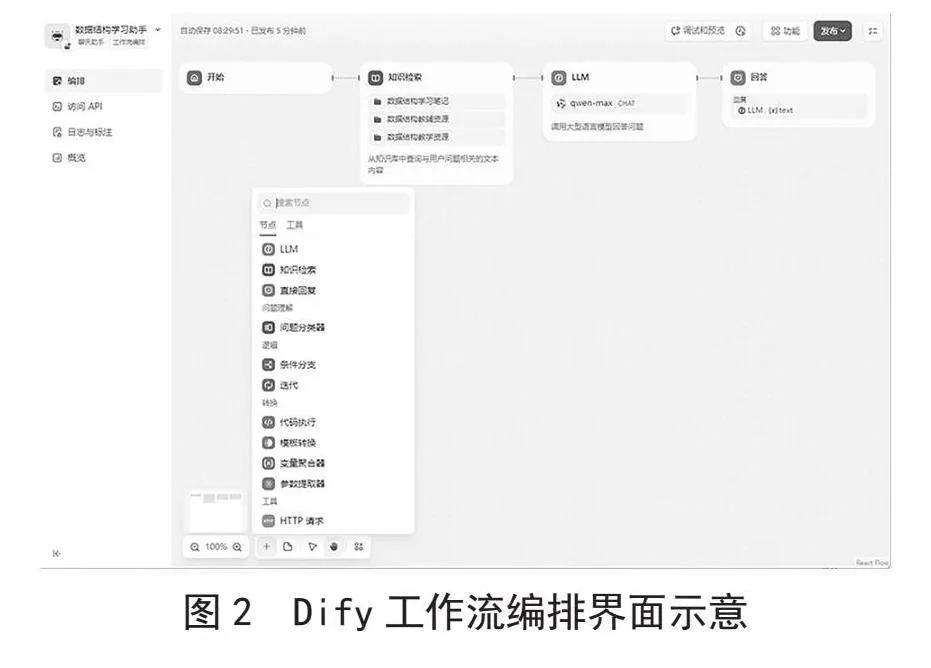
Dify提供了一个直观易用的可视化编排界面,使用户能够在画布上灵活地配置和连接任务节点,简化工作流的构建过程。图2所示的编排界面配置了多种核心节点,如:LLM、问题分类器以及条件分支和迭代等节点。用户可以通过定义一系列相互连接的节点来构建复杂的工作流程。
3" 智能学习助手的系统设计
在数据结构课程的教学实践中,学生常面临理解难题,感到理论晦涩难懂,对学习产生抵触情绪,面对复杂问题时更是束手无策,导致学习积极性下降。为了克服这些学习障碍,教师通常会安排每周的答疑时间,但这仍难以实现对学生问题的即时反馈。随着LLM技术的应用日益普及,构建基于LLM的智能学习助手成为解决此类问题的有效路径,它的主要功能是向学生提供数据结构课程的学习资源,辅助分析复杂问题,并提供编程代码的提示,通过自测功能帮助学生评估对知识点的掌握程度,从而提高学习效率。
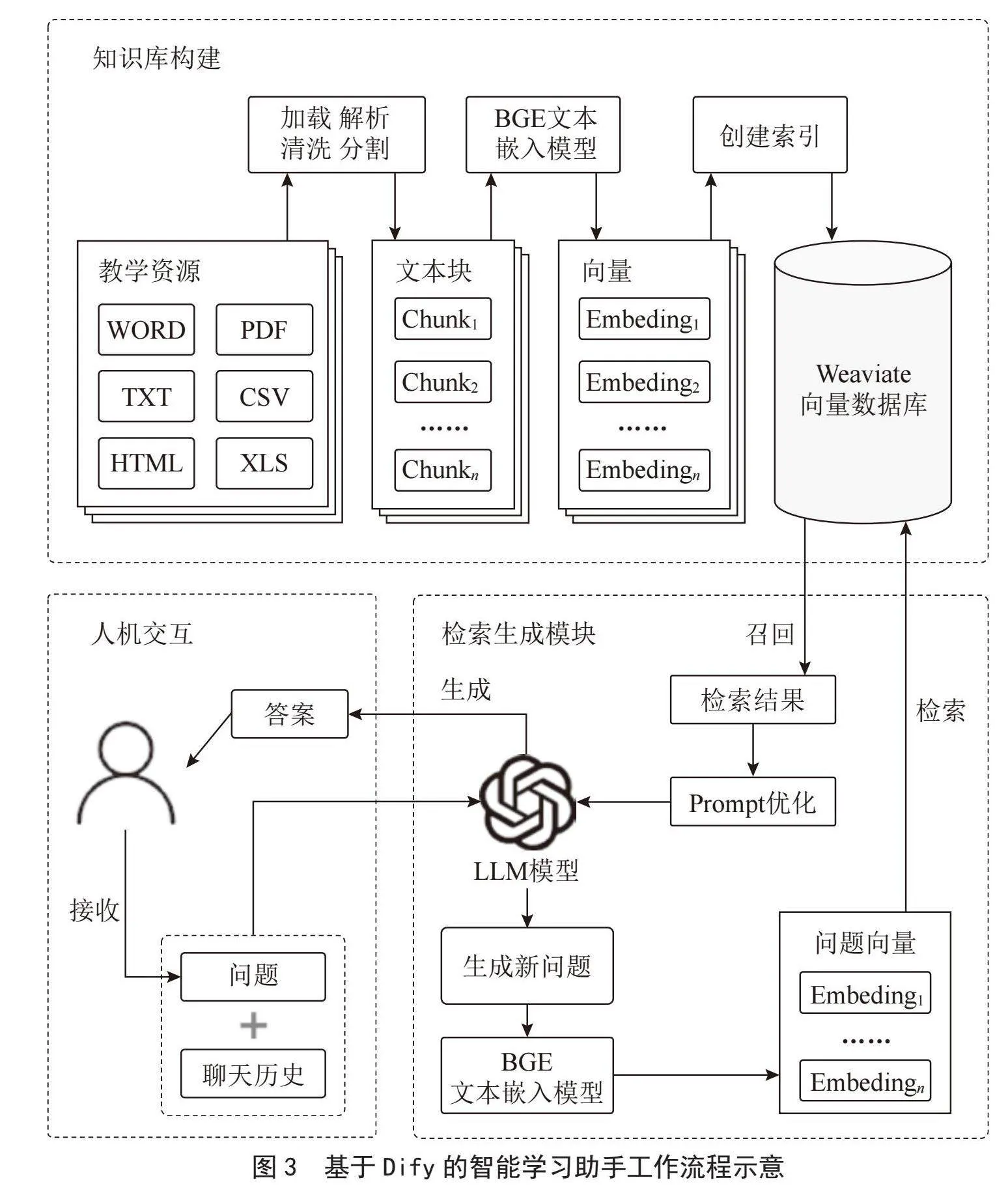
利用Dify平台提供的组件开发智能学习助手的工作流程如图3所示,总体分为三部分:一是知识库构建,指将数据结构课程的外部资源转为向量数据库;二是检索生成模块,使用RAG检索增强模型,支持对学生所提问题的检索与答案生成;三是人机交互模块,提供学生提问的UI界面。
3.1" 课程知识库构建
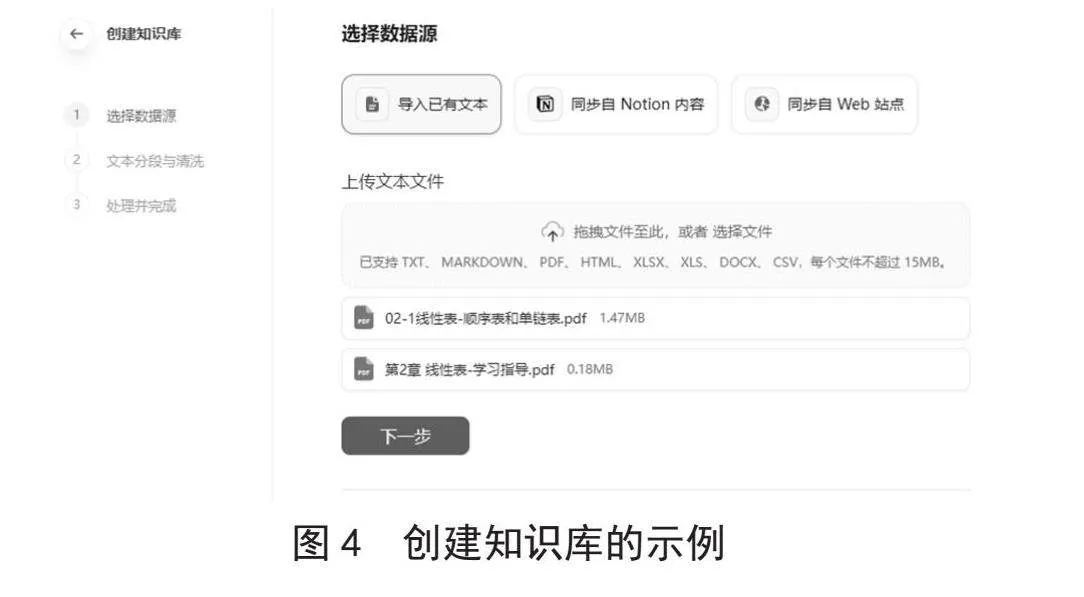
本阶段是将数据结构课程资源向量化,构建索引并存入数据库的数据准备离线过程。进入Dify的创建知识库界面,如图4所示。首先导入本地的教学资源文件,文件格式可以为MARKDOWN、PDF、DOCX等,本系统的教学资源主要来自智慧职教平台开设的SPOC在线课程,包括数字教材、学习资料、教案以及题库等。
文件上传后进行如图5所示的分文本分段与清洗设置,去除文本中的无关字符,如:空格、换行符和制表符等,减少后续Token的消耗;并采用Qamp;A分段技术对文本进行QA结构分割,保证了语义的完整性,减轻了人工整理问答对的工作量。
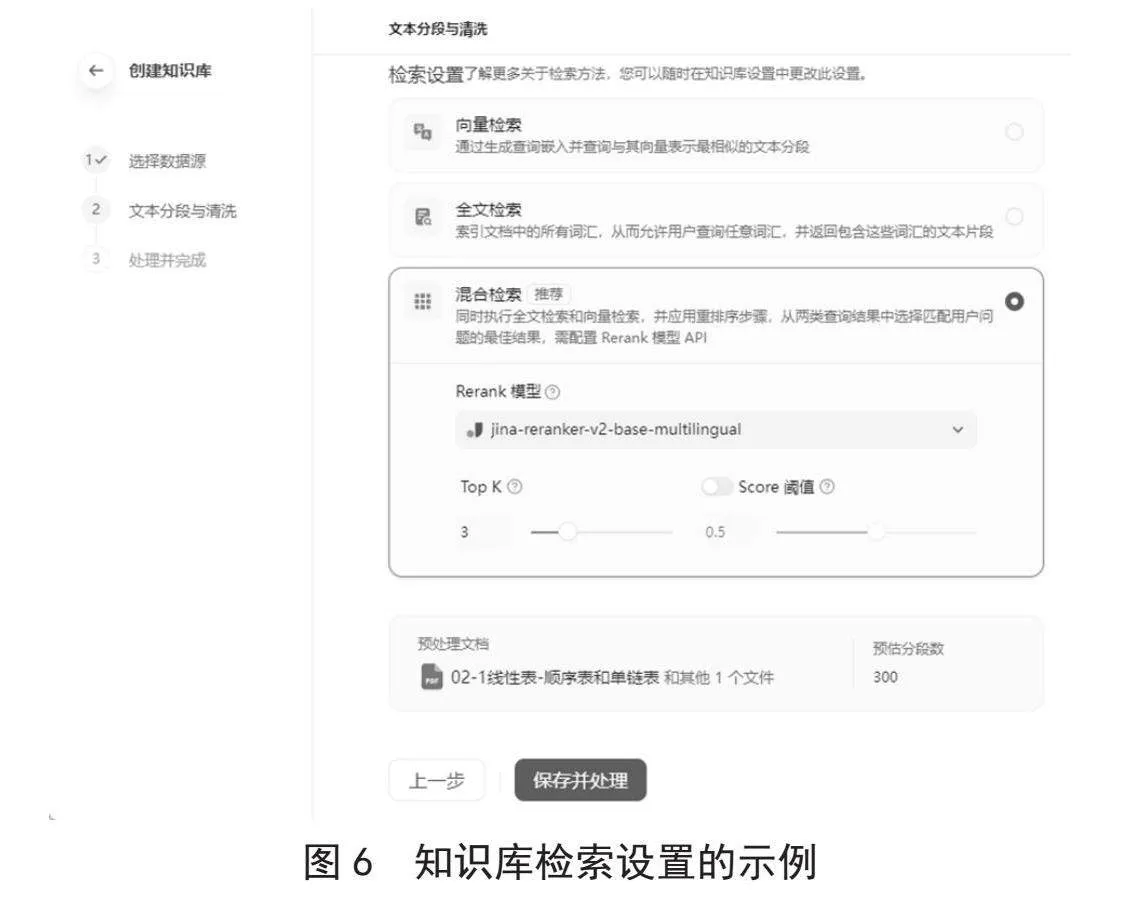
知识库检索设置如图6所示,选择向量检索与全文检索相结合的混合检索模式,并应用jina-reranker-v2-base-multilingual重排序模型从它们的查询结果中选择最匹配用户问题的结果,通过设置Top-K值和Score阈值筛选与问题相似度最高的文本片段,从多个维度提高检索的准确性和精确度。设置所有参数后,Dify对文本向量创建索引存入Weaviate向量库,完成知识库的创建。
3.2" 问题检索与生成模块
知识库创建后,便可以创建学习助手的应用,进入图7所示的应用编排界面完成问题检索与生成模块的提示词、上下文以及增强功能设置。
良好的提示词设计可以为LLM提供清晰的问题边界和上下文连贯性,是高质量答案输出的关键[14]。本文的提示词模板设定了学习助手的角色描述、技能要求以及输出规范,使回答更符合学生的学习需求。创建的知识库作为编排的上下文,通过设置多路召回可以从多个知识库获取答案,提高答案的准确性和多样性。对GPT-4o mini、Qwen-Max、GLM-4和ERNIE 4.0四种LLM进行召回测试的比较,GPT-4o mini和Qwen-Max在模型性能、Token成本与响应速度等方面表现更为出色,最终选择Qwen-Max模型。加载该模型后,结合提示词生成问题答案。
设置完成后便可以进行召回测试,检查设置的参数是否满足要求。最终进行应用的发布供学生学习使用。
3.3" 系统功能测试
3.3.1" 测试环境
本文采用搭载4核CPU、8 GB内存的华为云服务器进行系统部署,Qwen-Max作为内置生成语言模型,模型的检索参数Top-K = 3,Score = 0.5。
3.3.2" 功能测试
基于Dify平台搭建数据结构课程的学习助手,及时响应学生解决学习中的问题,给出问题答案,并提供答案引用的知识库,有效避免了大模型在专业知识上可能出现的错误或误导性信息,保证了答案来源的可靠性。当学生提问“如何快速掌握二叉树的后序遍历”时,系统在给出答案的同时提供问题答案的来源知识库,同时给出下一步的建议,引导学生的进一步思考,测试示例如图8所示。
4" 结" 论
本文详细介绍了基于大语言模型的RAG系统的设计和实现,并利用Dify平台为数据结构课程开发了一款智能学习助手。通过Dify提供的模块化工具和丰富的接口,快速搭建了课程知识库,并融合知识检索、知识增强与LLM生成技术构建了一个高效的RAG系统。这不仅显著加快了专业领域问答系统的开发进程,而且为课程教学提供了一种高效、可靠的智能辅助工具。经过综合测试和实践应用,该系统已被证明能在教学过程中稳定运行,有效辅助学生学习,它的成功实施不仅优化了教学资源的利用,也为学生提供了更加个性化和互动式的学习体验。
参考文献:
[1] 车璐,张志强,周金佳,等.生成式人工智能的研究现状和发展趋势 [J].科技导报,2024,42(12):35-43.
[2] 刘邦奇,聂小林,王士进,等.生成式人工智能与未来教育形态重塑:技术框架、能力特征及应用趋势 [J].电化教育研究,2024,45(1):13-20.
[3] 王耀祖,李擎,戴张杰,等.大语言模型研究现状与趋势 [J].工程科学学报,2024,46(8):1411-1425.
[4] 吴青,刘毓文.ChatGPT时代的高等教育应对:禁止还是变革 [J].高校教育管理,2023,17(3):32-41.
[5] 官璐,何康,斗维红.微调大模型:个性化人机信息交互模式分析 [J].新闻界,2023(11):44-51+76.
[6] GAO Y F,XIONG Y,GAO X Y,et al. Retrieval-Augmented Generation for Large Language Models: A Survey [J/OL].arXiv:2312.10997 [cs.CL].(2023-12-18).https://arxiv.org/abs/2312.10997.
[7] LEWIS P,PEREZ E,PIKTUS A,et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [J/OL].arXiv:2005.11401 [cs.CL].(2020-05-22).https://arxiv.org/abs/2005.11401?context=cs.
[8] 周扬,蔡霈涵,董振江.大模型知识管理系统 [J].中兴通讯技术,2024,30(2):63-71.
[9] 张鹤译,王鑫,韩立帆,等.大语言模型融合知识图谱的问答系统研究 [J].计算机科学与探索,2023,17(10):2377-2388.
[10] SU H J,JIANG S Y,LAI Y H,et al. EVOR: Evolving Retrieval for Code Generation [J/OL].arXiv:2402.12317 [cs.CL].(2024-02-19).https://arxiv.org/abs/2402.12317.
[11] 余胜泉,熊莎莎.基于大模型增强的通用人工智能教师架构 [J].开放教育研究,2024,30(1):33-43.
[12] 卢宇,余京蕾,陈鹏鹤.基于大模型的教学智能体构建与应用研究 [J].中国电化教育,2024(7):99-108.
[13] ZHAO P H,ZHANG H L,YU Q H,et al. Retrieval-Augmented Generation for AI-Generated Content: A Survey [J/OL].arXiv:2402.19473 [cs.CV].(2024-02-29).https://arxiv.org/abs/2402.19473.
[14] LIU P F,YUAN W Z,FU J L,et al. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing [J/OL].arXiv:2107.13586 [cs.CL].(2021-07-28).https://arxiv.org/abs/2107.13586v1.
作者简介:查英华(1969.11—),女,汉族,江苏南京人,副教授,硕士,研究方向:人工智能、智慧教育;郭朝霞(1981.06—),女,汉族,河南舞钢人,讲师,硕士,研究方向:移动应用开发;鞠慧光(1986.07—),男,汉族,江苏南京人,工程师,本科,研究方向:软件工程。