

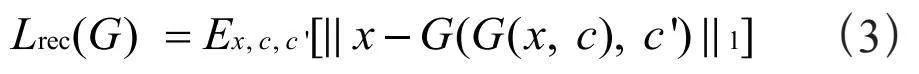

摘" 要:深度学习在图像识别任务中的表现依赖于数据集的大小,当样本稀缺时,模型难以获得优异的成绩。针对如何在少量数据的条件下训练出表现优越的识别模型这一问题,受生成对抗网络的启发,文章提出了一种基于多域数据扩充的小样本识别模型。该模型通过已有数据集训练生成模型,生成用于扩充数据集的伪样本。再利用这些扩充样本与真实样本协同训练小样本识别模型。实验结果表明,所提方法在识别准确率与模型训练的稳定性上有一定的提升。
关键词:小样本学习;多域;数据扩充;生成对抗网络
中图分类号:TP391.4;TP181" 文献标识码:A" 文章编号:2096-4706(2025)03-0061-07
Few-Shot Learning Method Based on Multi-Domain Data Expansion
CHEN Qi, XU Changwen, DONG Feifei, LI Zheng
(Jiangxi Earthquake Agency, Nanchang" 330026, China)
Abstract: The performance of Deep Learning in image recognition tasks depends on the size of the dataset. When the samples are scarce, the model is difficult to achieve excellent results. Aiming at the problem of how to train a superior recognition model under the condition of a small amount of data, inspired by the Generative Adversarial Networks, this paper proposes a Few-Shot Learning model based on multi-domain data expansion. The model generates a model through the training of existing datasets, and generates pseudo-samples for expanding the datasets. Then these expanded samples and real samples are used to train the small sample recognition model coordinately. The experimental results show that the proposed method has a certain improvement in recognition accuracy and stability of model training.
Keywords: Few-Shot Learning; multi-domain; data expansion; Generative Adversarial Networks
0" 引" 言
随着计算机技术的发展与软硬件设备的更新,深度学习在图像[1]领域取得了不俗的成绩,特别是在图像识别领域,现阶段流行的识别模型已经超越了人类的水平。但基于深度学习的识别模型的性能很大程度上依赖于数据集的质量。数据量大、种类多、标签精细能够给模型训练带来更大的优势,使识别模型的识别准确率更高、泛化性能更好。然而,在现实生活中,并非所有领域都可以构建包含大量样本的数据集,许多领域存在数据瓶颈的问题。如医疗领域,由于隐私保护和病例的稀有性,该领域的数据处于相对封闭的状态;再如自然灾害中的地震数据,由于现代科学的地震监测时间较短、震级较大的地震发生频率低等原因,数据样本的获取难度较大;又或是地方方言等非结构化数据,构造数据集费时费力,构建该类领域的大型数据集也存在一定的难度。在数据样本不足的情况下,采用深度学习方法训练识别模型时,模型的性能可能会受到影响,导致模型识别准确率较低。
现阶段,有不少研究学者致力于研究使用少量数据样本训练模型,并且使模型具有较好的性能。这类研究可以统称为小样本学习[2]。目前主流的小样本学习方法可以大致划分为四种不同的类型。第一类是基于度量学习[3]的方式,度量学习是一种学习样本之间近似程度的方法,通常是将样本映射到度量空间并设置适合任务的度量距离函数;第二类是基于数据增强[4]的方式,主要是通过生成数据样本来弥补因数据样本不足导致的识别准确率低的问题;第三类是基于元学习[5]的方式,这类方法主张跨任务学习,其核心思想是通过多种不同的任务训练学习者的学习能力,以便适应未知的新任务;第四类是基于迁移学习的方式,通常是将与分类任务相关的先验知识应用于目标任务中,协助模型训练。
本文所提的小样本学习方法是一种基于数据增强的方法,通过生成对抗网络[6](Generative Adversarial Networks, GAN)生成与任务相关的数据,协同真实数据样本训练模型,以提高模型的性能。目前较为流行的基于数据增强的小样本识别方法,如Chen[4]等人的文献中,通过将现有数据集进行形变,如重影、遮挡等方式,产生额外的数据样本并增加样本的多样性,从而提高模型的识别能力;Li等人[7]的研究中通过生成对抗网络增加数据样本的数量,以缓解小样本学习过程中因数据样本不足而性能不佳的问题;Wang等人[8]的工作中通过构造幻觉者生成与任务相关的幻觉样本,增加训练识别模型的数据量。大多数基于增加数据样本的小样本学习方法在生成数据的过程中,通常是针对特定的任务训练生成器生成数据,关注的是单一风格的数据生成。这类生成方法生成的数据样本风格单一,多样性较差,难以一次性生成多种类别的数据,甚至会发生模式坍塌的现象。如果在测试阶段直接应用于未知类别的样本中,可能会生成分辨率低、类别不清晰的样本,导致小样本模型训练效果不佳。受上述问题的启发,本文提出一种基于多域数据[9]生成的小样本识别模型,通过多域生成模型,缓解单一生成模型生成样本缺乏多样性、面对不同任务时生成样本质量差的问题。所提方法的基本思想是嵌入多域生成对抗网络,增加数据样本的数量和提高样本的多样性,进而提高模型的识别准确率。区别于其他的利用生成模型生成数据样本的方法,本文所提的方法可以一次训练生成多种类别的样本,生成模型的数据样本覆盖面更广。本文的主要贡献可归纳为以下几点:
1)本文针对数据样本不足而导致识别模型性能较差的问题,提出一种基于数据增强的小样本模型。该模型通过生成多域的数据样本,增加训练数据集的数量和提高数据集的多样性,帮助小样本识别模型更好地提取样本特征,从而提高小样本的识别准确率。
2)不同于其他基于数据增强的小样本识别方法,本文的生成模型并非只关注当前的识别任务或单一类别的数据集,而是一种能够生成多种不同类别数据的模型。此外,为了避免因生成效果不佳而导致模型训练困难的现象,本文在模型训练的过程中添加了谱归一化和模式坍塌损失,使生成模型尽可能生成逼真的数据样本。
3)所提方法的有效性在小样本学习常见的任务:5-class5-shot、5-class10-shot和5-class20-shot中得到了验证。本文分别在五种不同类型的小样本数据集上进行实验,实验结果表明,本文所提的方法在小样本识别任务的准确率上有一定程度的提高,说明增加多域的数据样本能让模型更快更好地适应新任务,提高模型训练的稳定性。
1" 相关工作
1.1" 小样本学习
在机器学习领域,数据集在模型训练、验证和测试阶段起着至关重要的作用,是该领域发展不可或缺的部分。但并非每个领域的数据都能轻易获取,有些数据需要耗费大量人力物力进行细致的预处理,有些领域的数据样本因隐私保护、出现频率低等原因难以获得,这些都导致难以构造该领域的大型数据集,进而使得涉及该领域的任务因缺乏数据而影响模型训练的性能。
小样本学习(Few-shot Learning, FSL)是一种在数据样本较少的情况下,训练模型并使模型能够有效完成目标任务的方法,常用于计算机视觉领域。FSL不同于传统的分类模型,传统的分类模型是通过数据集训练模型,数据集中仅包含与目标任务相关的某两类或几类的数据集合。为了确保模型的泛化能力,避免发生过拟合,传统分类模型的数据集中需要包含大量的数据样本。与深度学习模型不同,人类可以仅从少量样本中建立对未知事物的认知,FSL正是模仿这种人类认知的模型,是人工智能向人类智能发展的研究方向。FSL通过利用多种不同类别的数据集并在多个不同类型的分类任务中训练模型,使识别模型具备从少量样本中学习和概括的能力。当模型遇到未知任务和新数据样本时,仅需少量样本就能进行准确判断,从而降低识别模型的训练成本。
1.2" 数据扩充与生成对抗网络
在少样本学习中,因数据样本不足而导致模型训练效果不佳是最主要的问题。不少学者将数据合成技术应用于小样本学习中,通过扩充数据数量来克服数据不足的问题。数据合成是一种学习现有数据间的分布,生成与原始数据风格类似的逼真数据。将扩充数据用于模型训练的核心目标是通过增加数据样本数量与多样性,帮助模型训练,提高模型的性能与泛化能力。数据合成方法广泛运用与图像分类、风格迁移等任务中,在图像数据合成领域,生成对抗网络[6]是较为流行的方法。GAN是一种端到端的图像生成模型,通常由两个模块组成:生成器和判别器,生成器主要根据目标任务生成数据样本,判别器主要判断输入样本是真实样本还是生成的伪样本,并将结果反馈给生成器,生成器需要根据反馈结果调整模型参数,进而改进生成样本的质量。生成器的目标是尽可能生成逼真的数据样本欺骗判别器,而判别器的目标是尽可能准确地区分真实样本与虚假样本。生成器与判别器在这种对抗、交替迭代的训练过程中逐渐提升自己的性能。
1.3" 元学习
元学习是小样本学习中常用的方法之一,它是一种学会学习的方法。元学习在训练过程中关注的不是学习的结果,而是学习的过程,目的是训练一个能够快速学习的模型。元学习模型的训练过程通常可以概括为两个阶段:一是设置多个任务来训练模型,使模型在训练过程中获得经验,提高完成任务的能力;二是将训练好的模型应用于未知任务中,以增强模型的泛化能力,使其更好地适应新任务。如Finn等人[10]的工作中设置了两种不同的学习者——基础学习者和元学习者。基础学习者需要完成多种不同类型的任务,并在完成任务后将参数反馈给元学习者;元学习者则需要根据基础学习者的经验进行归纳总结,并应用于未知的新任务上。该方法的核心思想是通过基础学习器的学习经验来获得一个好的初始化权重,使元学习者能够在良好的初始化基础上快速收敛。元学习方法能够有效地缓解因数据不足导致的模型训练性能不佳的问题,提高模型的泛化能力和快速适应能力。
2" 本文所提模型
本节主要介绍所提方法,即一种基于多域数据扩充的小样本学习方法。该方法的核心思想是通过多域生成模型扩充样本数量、提高数据样本的多样性,从而提升模型在小样本识别任务中的识别准确率和泛化能力。
2.1" 多域图像生成
生成对抗网络是近来广泛运用于图像生成任务的一种模型,在图像合成任务中取得了令人印象深刻的成绩。多域图像生成的问题可以描述为:给定风格域的图像数据,通过风格迁移模型生成其他多种风格域的数据图像。在本文中,我们主要关注一个大类的数据,如多种不同种类的狗、鸟等数据集。为了使模型能够生成多域的数据样本,我们给相应的数据集添加了唯一的域类别标签,通过标签确定图像类别。具体来说,在训练过程中,我们设置独热向量作为风格域标签,向量大小与训练数据集中包含的类别数量一致。针对具体的类别,每个类别由唯一的独热向量表示。例如,如果数据集中一共包含4个不同类别的数据,则每个类别对应的独热向量为{1000}、{0100}、{0010}、{0001},独热向量的大小随着数据集中包含的类别数量增减。本文涉及的独热向量为人工设置标签,生成模型需要学习输入类别域到输出类别域的映射。在模型训练过程中,源风格域数据和目标风格域的标签作为模型输入,通过模型训练后生成属于目标风格的数据样本。
2.2" 多域生成对抗网络
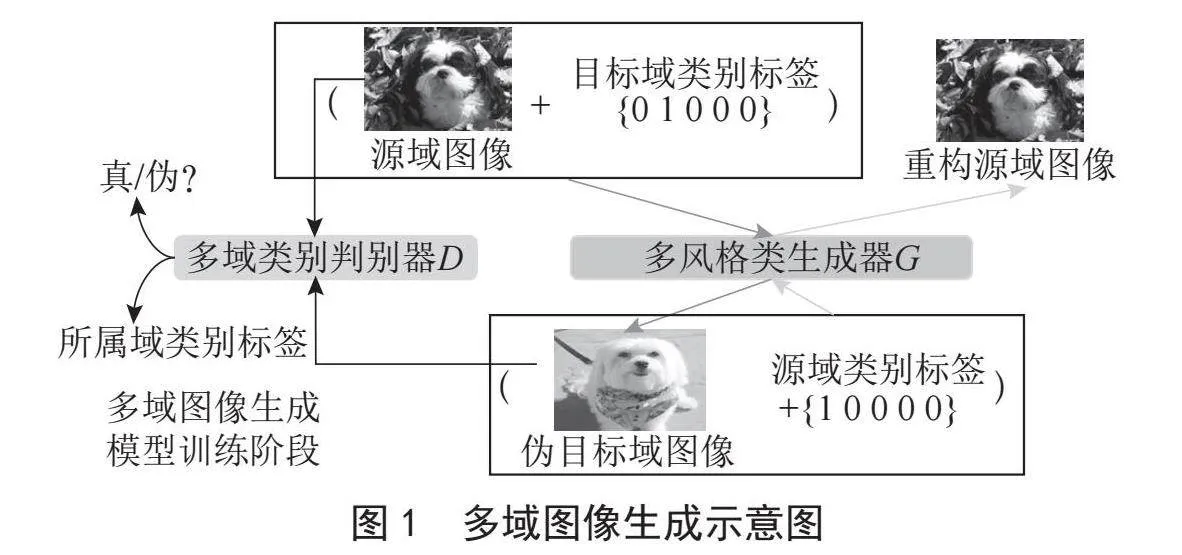
为了有效解决多类图像生成问题,本文以多域图像生成模型星状生成对抗网络[9](Star Generative Adversarial Networks, StarGAN)为基准模型。StarGAN模型一共包含两个模块:生成器与判别器。与单类别GAN模型类似,StarGAN模型的生成器的目标是生成尽可能逼真的数据样本,而判别器的目标则是尽可能准确地判别输入样本的真伪。StarGAN模型训练过程示意图如图1所示,从图中可以看出,生成器根据输入图像数据与目标域类别标签,生成属于目标类别的伪图像数据。此外,为了提高生成样本的质量,使模型能够生成更加逼真的图像数据,生成器还需要通过输入伪图像数据和域类别标签来生成重构源域图像。判别器除了需要判断输入图像的真伪之外,还需要判别图像所属的类别,并输出与判断类别对应的域类别标签。
StarGAN的对抗损失函数与常见的损失函数类似,目的是使判别器与生成器相互对抗,在博弈中提升各自的性能,要求生成器生成尽可能逼真的样本,判别器尽可能多地判别出输入图像的真伪。如式(1)所示:
(1)
StarGAN还包含域分类损失和重构损失。域分类损失由两部分组成,分别为针对真实样本的域分类损失和针对生成伪样本的域分类损失。在训练过程中,要求判别器尽可能多地判断出图片所属的类别。域分类损失协助模型实现多域数据样本生成,生成更加贴合目标域的图像。如式(2)所示:
(2)
为了实现多域之间的相互转换,StarGAN设置了重构损失,即在模型训练的过程中,生成器要实现源域与目标域图像的相互转换,通过生成的伪目标域图像和源类别标签生成的伪重构源域图像,该损失函数的目的是使二者之间的差异尽可能小,损失函数,如式(3)所示:
(3)
其中,G表示生成器,D表示判别器,x表示真实的源域类别图像,c表示目标域类别标签,表示源域类别标签,表示根据目标域标签生成的伪图像,表示重构图像。
2.3" 基于多域数据扩充的小样本学习
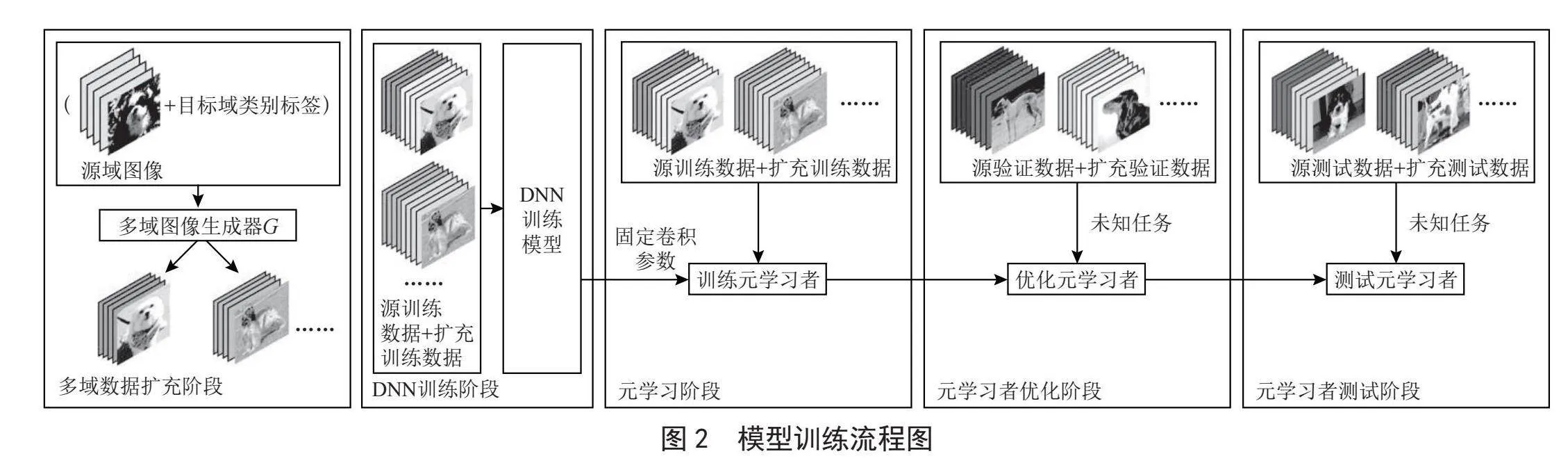
鉴于小样本学习任务中缺乏足够的数据样本,导致识别性能不佳的问题,本文通过设计一种嵌入多域数据生成的小样本学习方法,来增加模型训练的数据样本,从而提升小样本学习模型的识别性能。具体地,本文以Meta-Transfer Learning(MTL)为基准模型,将多域生成对抗网络模型嵌入至元学习框架中。如图2所示,所提出的小样本学习方法包含四个阶段:数据扩充阶段、深度神经网络[11](Deep Neural Networks,DNN)训练阶段、元学习阶段和元测试阶段。
具体介绍如下:
1)数据扩充阶段。该阶段主要是利用多域生成对抗网络扩充训练集的数据量,以提高训练模型的性能。在训练过程中,以训练集作为输入,生成多个类别的数据样本,并将生成的伪样本与真实样本组合,形成扩充后的训练集。
2)DNN训练阶段。该阶段与传统的DNN模型训练一致,为多分类识别模型。该阶段仅考虑扩充后的训练集数据,在模型训练完毕后,固定模型的卷积层参数用于下一阶段的学习。
3)元学习阶段。该阶段的目标是训练一个优秀的元学习者,使其能够快速适应未知任务并取得优异成绩。元学习阶段可以简单概括为两步:第一步是基础学习,即训练基础学习者,每个任务都对应一个基础学习者;第二步是元学习,即训练元学习者,根据基础学习者所学知识优化元学习者的参数。
4)元测试阶段。该阶段主要用于验证元学习者的性能,在未知任务上进行小样本识别任务测试,并通过测试结果评估元学习者的性能。
根据上述描述,本文所提模型的主要流程可以表述如下:首先,通过多域生成对抗网络扩充数据样本数量,用于下一阶段模型训练;其次,利用扩充后的数据集训练DNN模型,并在训练完成后固定卷积层参数;然后,训练元学习者,使元学习者在小样本任务中不断学习并累积经验,以更好地适应未知任务;最后,测试元学习者,通过未知任务检验其性能。
3" 实验及结果分析
在本节中,设计了一系列实验以验证所提模型的有效性。为了方便描述,将所提模型简称为DE-MTL(Data-Expansion for Meta-Transfer Learning)。
3.1" 实验设置
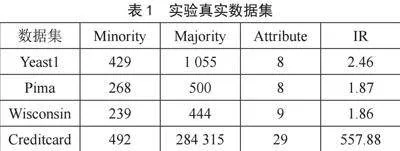
本文实验中,包含五种不同类别的数据集:StanfordDog、StanfordCar、CUB200_2011、FC100和mini-ImageNet。StanfordDog数据集包含了来自世界各地的120种不同类别的狗的图片;StanfordCar包含了196种不同类别汽车的图像(本文实验中仅采用150类);CUB200_2011数据集包含了来自世界各地的200种不同类别的鸟的图片;FC100包含了100种不同类别事物的数据集;Mini-ImageNet数据集包含了100种不同类别的事物,如气球、围巾、狗等大类。在所有实验中,均使用60%的类别数据作为训练集、20%的类别数据作为验证集、20%的类别数据作为测试集。
本文数据扩充的生成器主要为残差网络,判别器为卷积模块,并额外添加了谱归一化用于模型训练。元学习阶段的模型主要以ResNet-12为主,连接全连接层用于类别输出。本文涉及的对比模型包括基准模型MTL及基于数据增强的IDeME-Net[4](Image Deformation Meta-Networks)、SGM[12](Squared Gradient Magnitude)和PMN[8](Prototype Matching Networks)的小样本识别模型。在元学习、测试阶段,采用小样本识别任务的通用形式(x-class,y-shot)的形式,在实际训练、测试中,本文涉及的小样本识别任务包括(5class,5shot、10shot、20shot),即任务中包含5类数据,且每类包含5个样本、10个样本或20个样本。具体地,针对每一个可复现模型,均在同样环境下进行实验,所有模型在对比实验中选取的迭代次数、超参数均保持一致。所提模型的训练过程如图2所示,首先训练生成模型按一定比例扩充数据集;其次将扩充数据集按比例划分为训练集、验证集和测试集,在训练集上训练DNN模型,固定DNN模型的卷积参数,为后续元学习提供先验知识;再训练元学习者并在验证集上进行微调;最后在测试集上对元学习者进行测试,小样本识别任务中的测试结果为最终展示结果。基准模型的训练过程与本文所提模型一致,但其采用的数据集为原始数据集,无数据扩充阶段。
3.2" 与基准模型对比
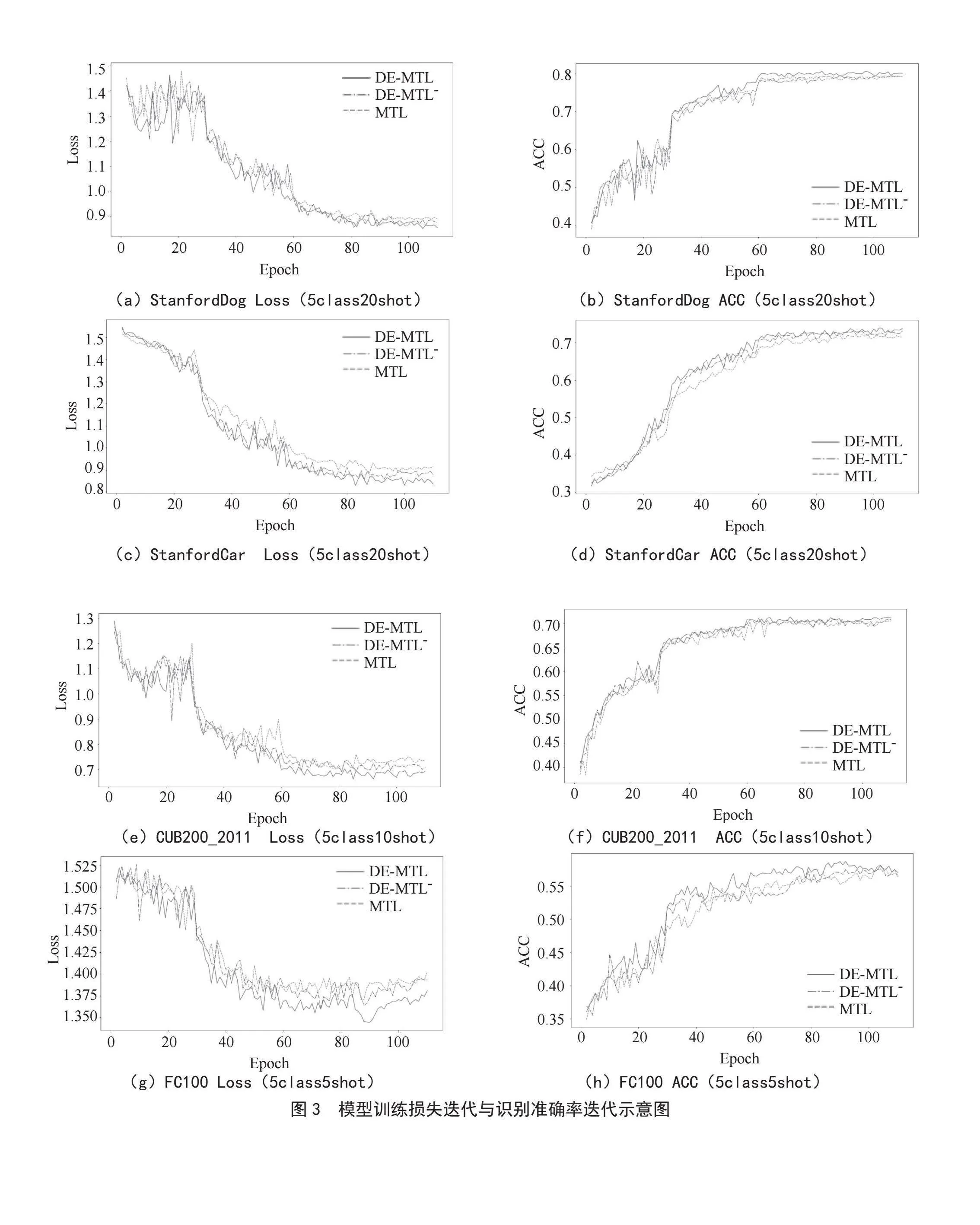
本节实验主要对比基准模型,在StanfordDog、StanfordCar、CUB200_2011和FC100四种数据集上分别设置了5class5shot、10shot、20shot的小样本识别任务,以验证所提模型的有效性。实验结果如表1所示。从表1可以看出,与基准模型MTL相比,所提模型在识别准确率上均有一定的提升,且在5class5shot任务中性能提升更为显著。这表明在识别样本较少时,扩充数据能更好地协助模型训练。为了进一步验证本文模型在识别准确率和训练稳定性上的改善,我们统计了部分实验中识别准确率迭代与训练损失迭代的数据。具体来说,在StanfordDog数据集上选取了5class20shot的实验结果;在StanfordCar数据集上选取了5class20shot的实验结果;在CUB200_2011数据集上选取了5class10shot的实验结果;在FC100数据集上选取了5class5shot的实验结果,实验结果如图3所示。从图中可以看出,与MTL模型相比,在训练后期,本文所提模型收敛过程更加平稳,识别准确率也有一定的提升。
此外,所提方法在数据扩充阶段采用了谱归一化策略。为了验证该策略对性能的影响,我们设计了一系列对比实验。实验结果中,DE-MTL-表示在数据扩充阶段未采用谱归一化,具体结果如表1和图3所示。从表1中可以看出,大多数添加了谱归一化策略的模型在识别准确率上有一定提升,这说明添加谱归一化能够一定程度提高生成样本的质量,进而提升模型的识别准确率,但不同数据集上的提升效果略有差异。从图3中也可以看出,添加谱归一化后,模型训练的稳定性也有所改善。结果表明,通过添加模型训练技巧,可以一定程度提升生成模型的生成质量和训练的稳定性,进而一定程度提高小样本识别准确率。
3.3" 消融实验
为了使本文所提的生成模型更适应小样本识别任务,我们在StanfordDog、CUB200_2011、Stanford-Car数据集上设计了一系列关于数据生成量级的消融实验,并将性能最好的模型运用于后续的元学习阶段中。在数据生成阶段,我们分别设计了扩充原数据集5%、15%、30%和45%四种不同量级的数据,并在5class10shot的识别任务中与基准模型进行对比。基准模型在原始数据集上进行训练,实验结果如表2所示。实验结果表明,在三种不同的数据集上,30%的数据扩充量均达到了最好的性能,且在大多数扩充数据样本的场景下,模型识别准确率有不同程度的提升。然而,在StanfordDog和CUB200_2011数据集中,45%的数据扩充量反而使模型识别准确率小幅降低,这可能是因为生成的伪样本过多而导致数据失真,进而影响了识别模型的性能。这也进一步说明,数据扩充并非越多越好,在增加数据集多样性的前提下,还需要避免因伪数据过多而导致数据集过于失真的现象。
3.4" 与其他主流模型对比
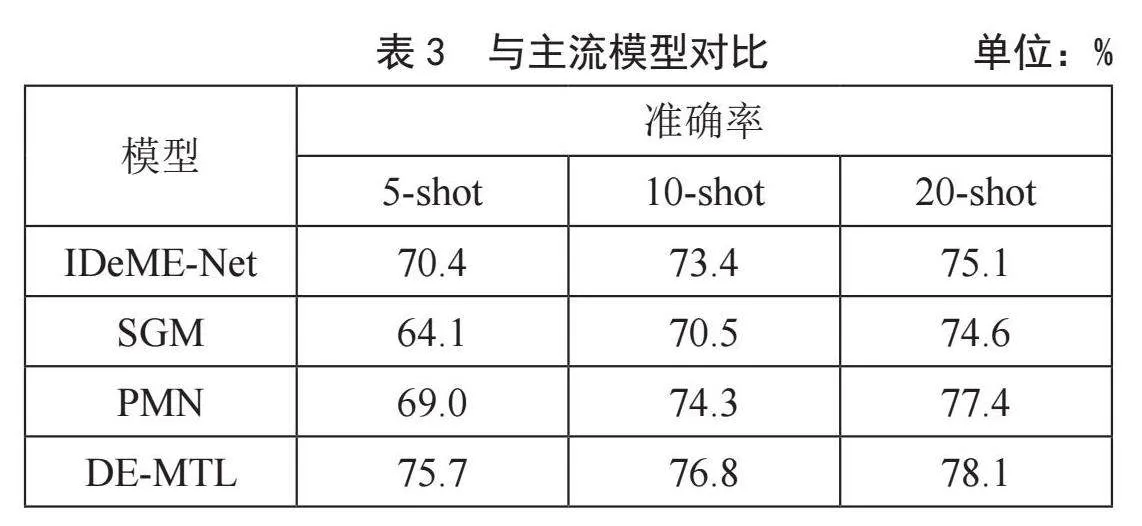
本小节将本文模型与现阶段较为流行的基于数据增强和数据扩充的小样本识别模型进行对比,以进一步证明所提模型的有效性。实验均在mini-ImageNet数据集上进行,验证了模型在5class5shot、10shot和20shot三种不同小样本识别任务下的性能。实验结果如表3所示,在涉及的实验中,本文所提方法均有优秀表现。特别是在5class5shot的实验中,本文方法相比第二好的模型性能提升最为明显。在本节实验中,对于可复现模型,采用本地复现结果;对于不可复现模型,则采用其研究中展示的最好结果。
4" 结" 论
本文提出了一种基于多域数据扩充的小样本学习方法,该方法在模型训练过程中增加数据样本的数量,从而缓解了小样本学习任务中因样本不足导致的性能不佳问题。传统的生成对抗网络一次训练只能实现两个类别的数据相互转换,而要实现多类别数据相互转换则需训练多个生成模型。相比之下,本文所提方法仅需训练一个生成模型,即可同时生成多个类别的数据,有效缩短了扩充数据样本的时间。此外,本文设计了一系列实验以验证所提模型的有效性。实验结果表明:与基准模型MTL相比,在扩充数据后,所提方法在识别准确率上有一定提升;与其他主流的小样本识别模型相比,所提方法在大多数任务中均表现出色。综上所述,本文所提方法能够有效提升小样本识别任务的性能。
参考文献:
[1] 张曰花,王红,马广明.基于深度学习的图像识别研究 [J].现代信息科技,2019,3(11):111-112+114.
[2] 晏明昊,强梦烨,陆琴心.基于ALDR注意力的少样本学习模型 [J].现代信息科技,2022,6(22):81-85.
[3] 沈媛媛,严严,王菡子.有监督的距离度量学习算法研究进展 [J].自动化学报,2014,40(12):2673-2686.
[4] CHEN Z T,FU Y W,WANG Y X,et al. Image Deformation Meta-Networks for One-Shot Learning [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:8672-8681.
[5] SUN Q,LIU Y,CHUA T S,et al. Meta-Transfer Learning for Few-Shot Learning [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:403-412.
[6] GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al. Generative Adversarial Networks [J/OL].arXiv.1406.2661 [stat.ML].(2014-06-10).https://arxiv.org/abs/1406.2661.
[7] LI K,ZHANG Y L,LI K P, et al. Adversarial Feature Hallucination Networks for Few-Shot Learning [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:13467-13476.
[8] WANG Y X,GIRSHICK R,HEBERT M,et al. Low-Shot Learning from Imaginary Data [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7278-7286.
[9] CHOI Y,CHOI M,KIM M,et al. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [J/OL].arXiv:1711.09020 [cs.CV].(2017-11-24).https://arxiv.org/abs/1711.09020.
[10] FINN C,ABBEEL P,LEVINE S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks [J/OL].arXiv:1703.03400 [cs.LG].(2017-03-09).https://arxiv.org/abs/1703.03400.
[11] 山世光,阚美娜,刘昕,等.深度学习:多层神经网络的复兴与变革 [J].科技导报,2016,34(14):60-70.
[12] HARIHARAN B, GIRSHICK R. Low-shot Visual Recognition by Shrinking and Hallucinating Features [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:3037-3046.
作者简介:陈琪(1997—),女,汉族,江西九江人,工程师,硕士研究生,研究方向:深度学习、图像处理;徐长文(1993—),男,汉族,江西乐平人,工程师,硕士研究生,研究方向:图像识别、网络安全与信息化;董非非(1982—),女,汉族,陕西西安人,高级工程师,硕士研究生,研究方向:固体地球物理;李正(1982—),男,汉族,江西新余人,高级工程师,本科,研究方向:计算机网络。