


摘" 要:针对PM2.5浓度预测问题,选取北京市顺义监测站的每小时空气质量数据及其对应的气象数据作为研究样本,提出了一种融合多头注意力机制的GRU模型(Attention-GRU)。该模型利用门控循环单元(GRU)捕捉时间序列中与目标特征的长期依赖关系,并通过多头注意力策略来优化多特征与PM2.5浓度的权重分布,关注影响较大的特征因素,从而提升预测的准确性。实验结果表明,与传统方法相比,融合多头注意力机制的GRU模型在均方根误差(RMSE)、平均绝对百分比误差(MAPE)和决定系数(R2)等指标上表现优异,验证了该方法的有效性和优越性。
关键词:多头注意力机制;PM2.5预测;门控循环单元(GRU);空气质量
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2025)04-0074-07
Research on the Application of Attention-GRU in PM2.5 Concentration Prediction
ZHANG Lipeng, LIU Qingjie
(Institute of Disaster Prevention, Langfang" 065201, China)
Abstract: Regarding the problem of PM2.5 concentration prediction, hourly air quality data and corresponding meteorological data from the Shunyi monitoring station in Beijing are selected as research samples, and a GRU model (Attention-GRU) integrating a Multi-head Attention Mechanism is proposed. The model makes use of the Gated Recurrent Unit (GRU) to capture the long-term dependency relationship with the target feature in the time series. Moreover, it optimizes the weight distribution of multiple features and PM2.5 concentration through a multi-head attention strategy, focusing on the feature factors with greater influence, so as to improve the prediction accuracy. Experimental results indicate that compared with traditional methods, the GRU model integrating a Multi-head Attention Mechanism performs outstandingly in the indicators such as Root Mean Square Error (RMSE), Mean Absolute Percentage Error (MAPE), and coefficient of determination (R2), validating the effectiveness and superiority of this proposed method.
Keywords: Multi-head Attention Mechanism; PM2.5 prediction; Gated Recurrent Unit (GRU); air quality
0" 引" 言
城市化和工业化的快速发展导致大气污染问题日益严重,特别是在北方地区,冬季采暖与不利的气象条件叠加,常引发频繁的污染事件,严重影响人民的健康和正常生产[1]。作为大气污染监测的重要指标,PM2.5是雾霾的主要成分,其浓度在很大程度上反映了大气环境质量。因此,准确、高效地预测PM2.5浓度对于探索大气污染物浓度变化规律、挖掘大气污染形成的内在原因、制定切实有效的大气环境管理措施具有重要意义[2]。
近年来,为持续打好蓝天保卫战,国家出台了一系列空气质量持续改善的相关政策法规,PM2.5浓度预测方法研究也成为焦点,研究者们尝试从不同的角度、使用不同的方法来探索更优的预测方法。最初研究者从传统的回归统计方法开始研究,取得了一定的效果,随着深度学习的快速发展,一些研究者开始使用深度学习来进行探索,最常使用的例如人工神经网络[3]、支持向量机[4]和随机森林[5-6]等。相比于传统的统计方法,深度学习方法展现出了其特有的优势,能够更好地捕捉到PM2.5和其他特征因素之间的非线性关系。彭玉青等人[7]将局部注意力机制与长短期记忆网络(LSTM)结合,与其他基准模型对比准确性有较大的提升。王平等人[8]提出了基于季节趋势分解的时间序列混合预测模型,充分考虑了PM2.5浓度的季节性趋势,将季节趋势信息进行挖掘后使用深度学习算法,为PM2.5浓度预测提供了新思路。彭豪杰等人[9]为解决传统机器学习算法无法深层挖掘数据特征以及深度学习算法在数据较少时效果不佳的问题,提出了一种基于深度学习与随机森林的组合模型,在预测精度上有所提高。
这些传统方法通常将所有特征同时输入网络,但忽略了不同区域、季节或时间点的特征变化对预测结果的影响,导致模型难以适应复杂、多样化的实际应用场景。这种“一刀切”的特征处理方式在面对特定时空条件下的差异时,无法有效捕捉局部特征对PM2.5浓度变化的关键作用。因此,这些模型往往在不同地域或不同时间段的泛化能力较差,表现出一定的局限性。
为了克服这一问题,本文提出了一种基于多头注意力机制的门控循环单元(GRU)模型(Attention-GRU),旨在通过选择性地关注与PM2.5浓度高度相关的特征因子,过滤掉无关或噪声信息,从而提升模型的预测精度。多头注意力机制的引入使得模型能够在不同特征维度间分配不同的权重,灵活调整对重要特征的关注度。这一机制不仅增强了模型在处理复杂时序数据时的表现,还提高了对局部特征的捕捉能力,使其在应对不同地域和时间点的PM2.5浓度变化时更加稳健。
通过多头注意力机制的加持,Attention-GRU模型能够更好地理解各个特征因子对PM2.5浓度的不同影响。例如,某些天气因素可能在特定区域或时段对PM2.5浓度有显著影响,而在其他情况下则作用较小。通过动态调整注意力权重,模型能够针对不同的时空条件自动调整预测策略,提高预测结果的准确性和泛化能力。这使得Attention-GRU模型相比于传统方法具备更强的适应性,能够在多变的现实环境中保持稳健的预测性能。
1" 理论基础
1.1" 门控循环单元(GRU)
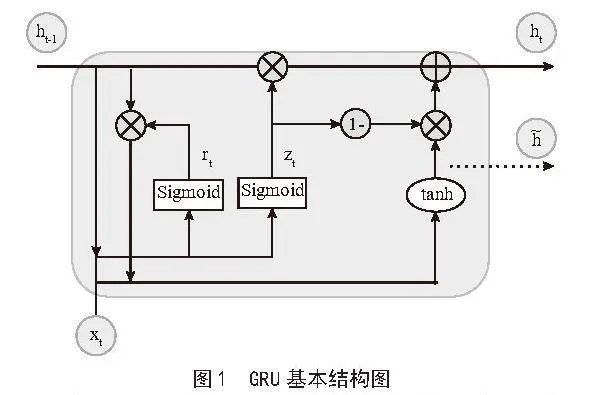
门控循环单元(Gated Recurrent Unit, GRU)是一种简化的循环神经网络(RNN)结构,旨在解决传统RNN在处理长序列时的梯度消失问题。GRU通过引入两个门控机制:重置门rt和更新门zt,有效地控制信息的流动,从而捕获长期依赖关系。其网络结构图如图1所示。
重置门和更新门的作用是通过门控状态,对前一时间步的状态信息ht-1与当前时间步的信息xt进行相应的运算,用以决定信息的重要程度,其中σ为Sigmoid激活函数[10]。计算式为:
(1)
(2)
候选隐状态通过结合重置门和上一时刻的隐状态进行计算,计算式为:
(3)
当前时间步的输出隐状态ht由前一时间步的状态信息ht-1提取部分信息,并结合候选状态保留相关内容。这个过程依靠更新门的遗忘机制与选择性记忆,并与当前时间步的候选状态共同决定最终输出。计算式为:
(4)
在式(1)~(4)中,,,,,分别表示前一时间步与当前时间步各输入层之间的连接权重矩阵; , , 分别表示每个GRU单元中的重置门、更新门和当前时间步隐藏层的偏置项;符号“·”表示点乘操作。
1.2" 多头注意力机制
注意力机制的核心思想启发于人类的视觉注意的过程。人类的视觉能够迅速识别出最为突出和值得注意的区域。类似地,注意力机制模拟人类的视觉注意过程,通过选择性地关注更为重要的信息,同时又忽略较为次要信息,从而达到对信息重要性进行分配的目的,使得模型更加准确[11]。
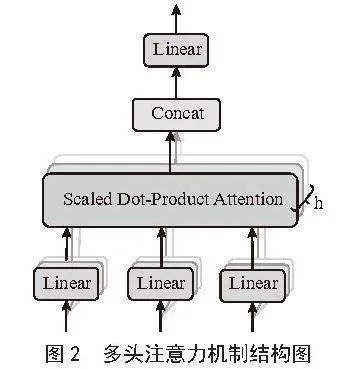
多头注意力机制(Multi-head Attention Mechanism)[12]同样也是模拟了人类的注意力方式。在模型训练过程中,对各特征变量的权重分配是不相同的。与传统的注意力策略相比,多头注意力机制的优势在于其增强了模型在不同位置上专注的能力。多头注意力机制的网络结构如图2所示。
Multi-Head Attention机制的计算主要涉及以下3个阶段:
1)V、K、Q是固定的单个值,计算Query和Key的相似度,得到对应权重系数。后对权重系数进行加权计算得到注意力得分si,计算式为:
(5)
2)使用Softmax函数对注意力得分进行数值转换,然后再进行归一化处理,得到权重系数,计算式为:
(6)
3)根据权重系数对第二步得到的权重系数进行加权求和,计算式为:
(7)
2" Attention-GRU神经网络
本文针对使用GRU模型进行PM2.5浓度预测时发现的问题进行了改进。原始GRU模型对历史序列中的数据赋予相等的权重,难以满足精确建模的需求。为解决这一问题,我们引入了在自然语言处理领域广泛使用的多头注意力机制,使模型能够根据输入序列的重要性动态调整权重,从而更有效地关注关键历史信息,降低预测误差。
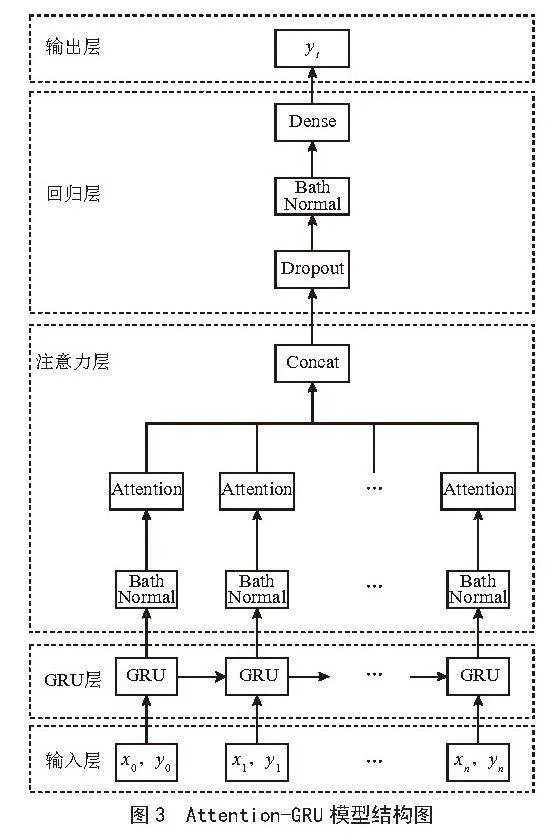
如图3所示,该模型由五个层次组成:输入层、网络层、注意力层、回归层和输出层。
与传统的GRU网络相比,Attention-GRU网络增加了一层多头注意力机制。传统的GRU网络是一种循环神经网络,通过隐藏层中的状态捕捉序列数据中的依赖关系。注意力机制是一种增强神经网络对输入数据关注度和表达能力的技术,使神经网络能够更加关注重要部分,忽略不重要部分。
在Attention-GRU网络中,时间序列中的每个时间步的输入都会先送入GRU网络单元中,然后其GRU网络层的输出再被作为注意力层的输入。注意力层主要是根据GRU的输出信息与目标特征的重要程度来分配不同的权重参数,也就是注意力值。随后再经过回归层,将前面输入的结果映射成预测值,最终在输出层输出预测结果。
通过引入多头注意力机制,基于注意力机制的Attention-GRU网络能够更好地捕捉输入序列中的相关信息,并在对输入进行编码时,更加精确地区分不同时间步的重要信息。因此,基于注意力机制的Attention-GRU网络在许多时间序列建模任务中具有卓越的性能。
3" 数据预处理
3.1" 数据来源和数据缺失值处理
本实验使用的空气质量数据来源于北京市生态环境监测中心,与之相对应的气象数据来自美国国家气候数据中心。将这两组数据按照时间进行整合,在整合后的数据中存在一些缺失值,为避免连续缺失值对模型训练产生不利影响,本实验对数据集进行了预处理。对于连续缺失10个时间步长的记录,直接予以删除,以减少模型受到的干扰。针对少数非连续的缺失数据,使用了随机森林算法进行填补,该方法通过其他特征之间的关系来推测缺失值,从而提升数据的完整性与准确性。对于无法通过随机森林填补的数据项,进一步采用后置填补法,即根据前后数据进行补全,以确保数据的合理衔接。
经过上述处理,最终获得了一个包含42 900条记录的数据集,涵盖了2019年1月1日至2023年12月31日期间监测站每小时的PM2.5数据。随后,将数据集划分为训练集和测试集,前38 610条数据用于模型训练,后4 290条数据用于测试,以进行后续实验分析。
3.2" 特征相关性分析
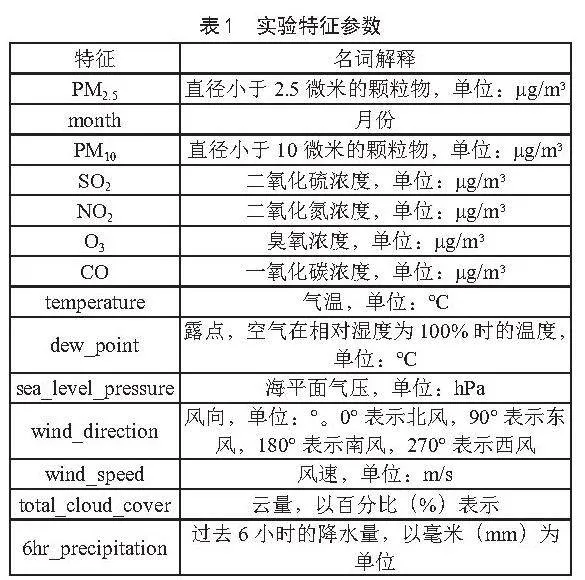
本实验使用的数据集特征参数共包含14个维度:PM2.5、month、PM10、SO2、NO2、O3、CO、温度、露点温度、海平面气压、风向、风速、云量、降水量。这些特征参数均为每小时采样一次,对应的实验特征参数如表1所示。
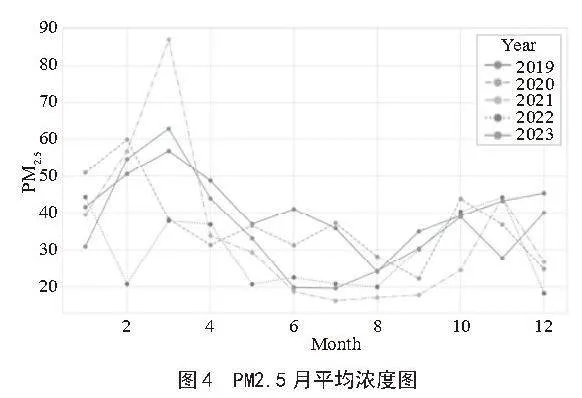
如图4可知,PM2.5是有明显的季节性趋势的,因此本研究将月份信息也考虑到PM2.5浓度的影响因素里面。
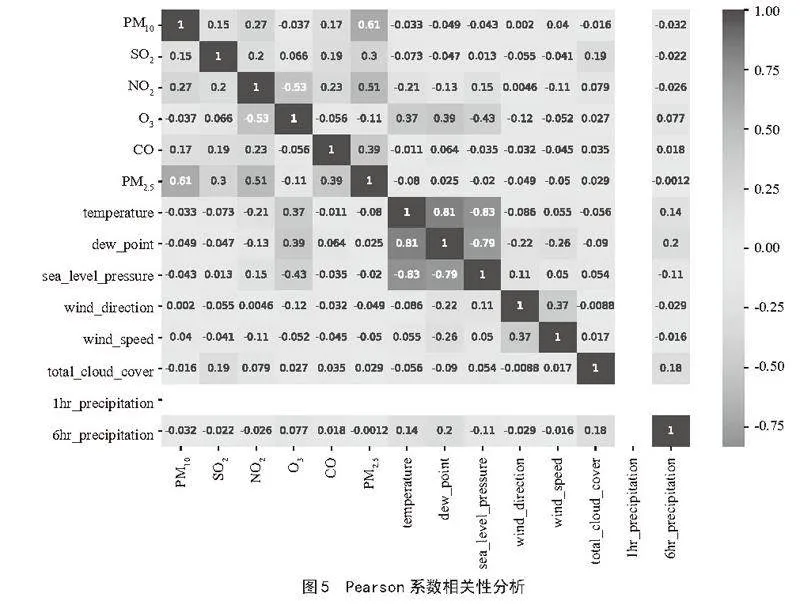
观察图5的Pearson系数相关性分析可知,PM2.5与PM10和CO之间有很强的正相关关系,与NO2有中等程度的正相关关系,这表明这些污染物可能来自相似的源头,如交通和工业排放。气象条件(如温度、露点、海平面气压、风向、风速和云量)对PM2.5的影响较小,降水在短时间内对PM2.5浓度也有一定的影响。
本实验旨在更好地探究PM2.5的规律特性,选定PM2.5、PM10、SO2、NO2、CO以及O3六种主要空气污染物质的浓度以及气象因素包含气温、露点温度、气压、风向、风速、云量、降水量和月份作为特征变量来进行下一步研究。
3.3" 数据归一化
由于数据集中各个特征数据的单位不同,数据的衡量标准差距过大,例如本实验所使用的数据集中CO值介于0.1~4.6 µg/m³之间,而PM2.5的值则在1~500 µg/m³之间,如果不做其他处理,直接将原始数据集作为模型输入的话,势必会影响模型的预测性能。因此,本实验在模型训练前先将原始数据集进行Min-Max归一化操作,来保证每个特征数据项的值介于[0,1]区间内,使得训练数据更加平滑,同时也有助于模型训练时的收敛。Min-Max归一化计算式为:
(8)
其中,xi为某一时刻i的实际观测值,yi为该时刻i归一化后的值,x为所有实际观测值。得到归一化的预测结果后,本实验使用式(9)进行反归一化,将预测结果转换回原始的数值范围。
(9)
其中,x*为反归一化后得到的实际PM2.5浓度预测值,yi为该时刻i归一化后的值。
4" 实验与分析
4.1" 实验设置及评价指标
本实验使用Keras来搭建多特征PM2.5时间序列模型,构建Attention-GRU网络模型,以更好的捕捉到与PM2.5相似程度较高的特征权重信息,从而更好地预测未来PM2.5浓度。其中模型输入包括PM2.5、PM10、SO2、NO2、CO以及O3六种主要空气污染物质的浓度,以及气象因素包含气温、露点温度、气压、风向、风速、云量、降水量和月份,这14个维度的参数依次作为特征一同输入到网络中。
在构建网络模型时,采用了GRU,其中隐含层的单元数量设定为64个。在模型训练阶段,每个批次包含了30个样本进行训练,初始的学习率被设定为0.01,时间步长设为24。为了得到模型的最佳参数,训练时的迭代次数是一个需要调整的关键参数,一般来说,迭代次数越多,模型的训练效果会越精确。因此,在本实验中,迭代次数被设定为300次,以期达到较优的训练效果。
本实验通过三个指标来评估模型的预测精度:平均绝对百分比误差(MAPE)、决定系数(R-squared)和均方根误差(RMSE)。其中,较小的MAPE和RMSE值表明模型误差更小,预测精度更高;而较大的决定系数(R²)值则意味着模型的拟合效果更佳。相应的计算式为:
(10)
(11)
(12)
其中,m为测试集中的预测数量;yi为第i个样本的预测值;为第i个样本点的真实值。
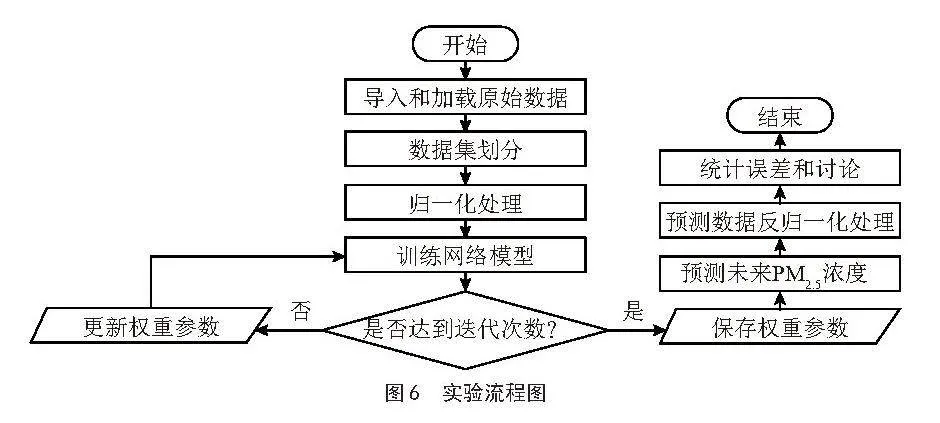
4.2" 实验流程
本文的实验流程如图6所示。实验首先导入并加载原始数据集,确保数据的完整性和一致性。接下来,对数据集进行划分,将其分为训练集、验证集和测试集,并对数据进行归一化处理,以消除量纲差异,提升模型训练的稳定性和效率。在数据预处理完成后,进行模型训练。选择多种模型进行训练,包括基础模型和经过改进的高级模型。在训练过程中,监控模型在验证集上的表现,根据设定的迭代次数和早停策略决定是否提前终止训练,以防过拟合并节省计算资源。同时,保存表现最佳的模型权重用于未来的PM2.5浓度预测。最终,实验对不同模型的预测结果进行误差统计与分析,评估其预测效果。通过对比不同模型在PM2.5浓度预测中的表现,讨论各模型的优缺点,从而为模型的改进和实际应用提供依据。
4.3" 实验对比与分析
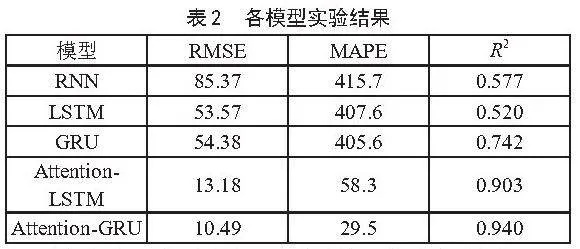
将本实验提出的Attention-GRU模型与传统的RNN模型、LSTM神经网络、GRU神经网络进行对比分析,所有模型均统一预测未来1小时的PM2.5浓度值。具体的实验对比结果如表2所示。
通过表2实验结果可以看出,基础模型中GRU相较于RNN和LSTM表现较好,但仍有较大的预测误差,其中RMSE为54.38,MAPE为405.6,R2为0.742。引入注意力机制后,模型性能显著提升。Attention-LSTM模型的RMSE降至13.18,MAPE为58.3,R2提升至0.903,显示出注意力机制对LSTM模型的显著改进。对比之下,Attention-GRU模型的表现最为优异,RMSE进一步降低至10.49,MAPE减少到29.5,R2提升至0.940。这表明,MultiHeadAttention机制在GRU模型中效果尤为突出,能够更有效地捕捉和利用时序数据中的关键特征。
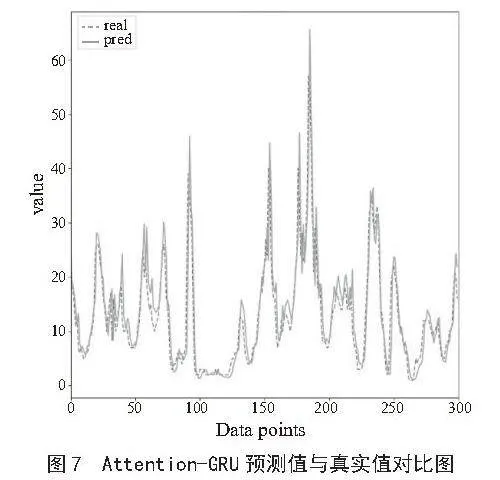
通过对比还可以发现,表中加粗的Attention-GRU比Attention-LSTM在RMSE和MAPE的误差更小,R2更接近于1,表明融入注意力机制的Attention-GRU模型能够更好地拟合未来PM2.5浓度的值。Attention-GRU模型在测试集上的预测值与真实值的对比如图7所示。从图中可以看出,即使在一些拐点,本实验的模型预测结果也与真实值非常接近。
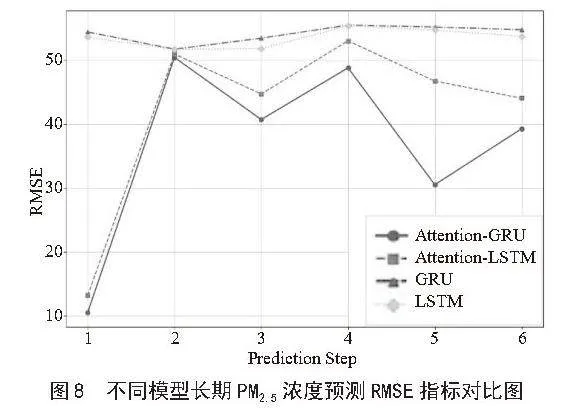
为了充分验证本实验提出的Attention-GRU的稳健性能,将其与Attention-LSTM、GRU和LSTM模型进行了后6小时较为长期的PM2.5浓度值预测实验,对比实验以RMSE作为评价指标。实验预测结果如图8所示。
从图8的结果可以进一步分析,Attention-GRU模型在各预测步长中的优势尤其明显。特别是在第3和第5步长上,Attention-GRU的RMSE值显著低于其他模型,说明它能够更好地捕捉数据的时序特征并有效应对复杂的PM2.5浓度波动。相比之下,尽管GRU模型在个别步长上表现较为接近,但整体误差较大,说明其在长时间序列预测中的能力仍有局限。
Attention-LSTM和LSTM模型的表现较为相似,尽管二者在不同步长上的误差稳定性较高,但在预测精度上不如GRU类模型。这表明LSTM在处理PM2.5浓度这种复杂多变的时序数据时,优势并不显著,尤其在引入Attention机制后,提升效果有限。
综合来看,Attention机制在GRU模型中的应用显著提升了模型的预测能力,使其在应对复杂时序数据时更加精确。而LSTM模型即使引入Attention,改进效果仍然不明显,可能与其网络结构和数据特征的匹配度有关。这表明在未来的模型设计中,可以重点考虑Attention机制与GRU的结合,以进一步优化大气污染物预测的模型性能。
5" 结" 论
在本文中,我们提出了一种将多头注意力机制融入GRU神经网络的模型Attention-GRU,用于PM2.5浓度的预测。通过与经典时间序列模型RNN、LSTM和GRU进行对比实验,实验结果表明,Attention-GRU在预测精度上显著优于其他模型,尤其是在长期预测中展现了较高的准确性和稳定性。这证明了多头注意力机制能够有效增强GRU对复杂时序数据的捕捉能力,并提升模型的预测性能。
尽管本研究在PM2.5预测上取得了不错的预测效果,但仍存在一些局限性。首先,模型未考虑工厂聚集地及人为活动等外部因素对PM2.5浓度的影响。这些因素可能在实际应用中起到关键作用,因此未来研究将会进一步探索更多潜在的影响因素。其次,本研究主要聚焦于单一的多头注意力机制,未来工作中可以尝试引入混合注意力机制或结合其他深度学习方法,以提高模型对复杂环境因素下PM2.5浓度的预测能力。
参考文献:
[1] 周珍,邢瑶瑶,林云,等.中央与地方政府PM2.5治理策略分析 [J].运筹与管理,2020,29(1):32.
[2] 王昭,严小兵.长江三角洲城市群PM2.5时空演变及影响因素 [J].长江流域资源与环境,2020,29(7):1497-1506.
[3] CORDOVA C H,PORTOCARRERO M N L,SALAS R,et al. Air quality assessment and Pollution Forecasting Using Artificial Neural Networks in Metropolitan Lima-Peru [J].Scientific Reports,2021,11(1):24232.
[4] LIU Y,ZHU J,LI E Y,et al. Environmental Regulation, Green Technological Innovation,And Eco-Efficiency:The Case of Yangtze River Economic Belt in China [J].Technological Forecasting and Social Change,2020,155:119993.
[5] 卢鋆镆,曾穗平,曾坚,等.基于随机森林的高分辨率PM2.5浓度时空变化模拟——以中原城市群核心区为例 [J].中国环境科学,2023,43(7):3299-3311.
[6] 夏晓圣,陈菁菁,王佳佳,等.基于随机森林模型的中国PM2.5浓度影响因素分析 [J].环境科学,2020,41(5):2057-2065.
[7] 彭玉青,乔颖,陶慧芳,等.融入注意力机制的PM2.5预测模型 [J].传感器与微系统,2020,39(7):44-47.
[8] 王平,许濒月,雷卓祎,等.基于季节趋势分解的PM_(2.5)浓度混合预测模型 [J/OL].山西大学学报:自然科学版,2024:1-10[2024-08-01].https://doi.org/10.13451/j.sxu.ns.2024045.
[9] 彭豪杰,周杨,胡校飞,等.基于深度学习与随机森林的PM2.5浓度预测模型 [J].遥感学报,2023,27(2):430-440,2023,27(2).
[10] 刘义卿,陈新房,赵晗清.基于ResNet+GRU组合模型的负电荷预测方法研究 [J].电脑与电信,2024,1(5):89.
[11] 任欢,王旭光.注意力机制综述 [J].计算机应用,2021,41(z1):1-6.
[12] LI J,WANG X,TU Z,et al. On the Diversity of Multi-Head Attention [J].Neurocomputing,2021,454:14-24.
作者简介:张黎鹏(2000—),男,汉族,河南洛阳人,硕士在读,研究方向:时间序列分析;通信作者:刘庆杰(1978—),男,汉族,河南洛阳人,教授,硕士,研究方向:大数据处理。
收稿日期:2024-08-21