中图分类号:TP399 文献标识码:A文章编号:2096-4706(2025)07-0040-07
Abstract: This paper aims to use the XGBoost model to predict obesity levels and explain the contribution of various featurestoobesityriskthroughtheSHAPmethd,soastoidentifykeyifuencingfactorsandprovideascientificbasisfor obesity prevention.Modeling isconductedbasedonmultiple featuressuchas familyhistoryofobesity,dietaryhabits,and frequencyofphysicalactivityXGBoostisused topredictobesitylevels,andSHAPvaluesareappliedtoanalyzethempactof eachfeatureonthe modeloutput,toexplainthecontributionofeach feature toobesityclasifcation.Family historyofobesity age,and dietary habitsare keyfactors afectingobesity.SHAPanalysis furtherreveals the specificcontributionsandimpactof thesefactorsonobesityclassification.BycombiningtheeffcientpredictiveabilityofXGBoostandtheexplanatoryanalysisof SHAP,thisresearchnotonlyidentifiesthekeyfeaturesthataffctobesitybutalsoprovidesascientificbasisforpersoalized health management and obesity prevention,demonstrating theapplication potential ofMachine Learming inthe fieldof public health.
Keywords: SHAP; XGBoost; Big Data; obesity level; health management
0 引言
对肥胖水平进行数据挖掘,是指通过分析与肥胖相关的各类数据,揭示肥胖的成因、发展趋势以及与健康风险之间的关系,从而为肥胖的预防、管理和治疗提供数据支持。数据挖掘是一种从大量数据中提取有用信息的技术,它通过统计分析、机器学习和人工智能算法来发现潜在的模式和规律。在肥胖数据挖掘过程中,常用的数据来源包括个人的健康记录、饮食习惯、运动数据、遗传信息、生活方式、社会经济背景等。这些数据可以帮助我们从多个维度了解肥胖的复杂性。例如,通过分析不同年龄、性别、地区人群的肥胖率,可以发现肥胖的流行趋势;通过分析饮食和运动的数据,可以揭示哪些行为习惯容易导致肥胖而通过分析遗传因素与肥胖的关系,可以帮助识别高风险人群。
对肥胖水平进行数据挖掘具有重要的现实意义,尤其是在当今全球肥胖率不断上升的背景下。肥胖已经成为一个全球性健康问题,不仅影响个人的身体健康,还带来了严重的社会和经济负担。通过数据挖掘,能够从大量的肥胖相关数据中提取有价值的信息,深入理解肥胖的成因、趋势以及其带来的潜在影响,从而为相关的预防、治疗和管理策略提供有力支持。数据挖掘可以为个性化健康管理提供依据。肥胖的成因复杂,涉及饮食习惯、运动量、遗传因素、环境因素等多方面。通过挖掘和分析这些因素的数据,能够为个体提供个性化的健康建议和干预方案。例如,机器学习模型可以帮助识别哪些因素对特定个体的肥胖影响最大,从而制定针对性的饮食和运动计划,实现有效的体重管理。这种个性化的健康管理不仅能够提高肥胖治疗的效果,还能预防肥胖进一步恶化。
1文献综述
近年来,随着大数据和人工智能技术的发展,机器学习在健康领域,尤其是肥胖预测中的应用越来越广泛。机器学习算法通过分析大量与肥胖相关的多维数据,能够有效识别出潜在的影响因素,并进行准确的风险预测。
Dugan等[]研究了机器学习技术在儿童早期肥胖预测中的应用。该研究使用了六种不同的机器学习算法,基于儿童的临床数据进行训练。研究结果表明,ID3算法表现最佳,准确率达到 8 5 % ,敏感性为89 % ,阳性预测值为 84 % ,阴性预测值为 8 8 % 。此外,该模型的树状结构揭示了影响儿童肥胖的关键因素,许多这些因素在现有文献中得到了独立验证。研究表明,利用临床数据和机器学习模型,可以有效地预测儿童肥胖的风险,为未来的干预和健康管理提供了科学依据。
Dirik探讨了机器学习技术在肥胖预测中的应用,旨在构建一个强大的预测模型,以识别超重或肥胖个体。该研究采用了多种机器学习算法,如多层感知机(MLP)、支持向量机(SVM)、模糊K近邻(FuzzyNN)、模糊无序规则归纳算法(FURIA)、粗糙集(RS)、随机树(RT)、随机森林(RF)、朴素贝叶斯(NB)、逻辑回归(LR)和决策表(DT),通过分析个体的身体特征和饮食习惯来预测肥胖风险。研究结果表明,随机森林模型(RF)在预测精度方面表现最佳,为早期识别超重和肥胖个体提供了强有力的工具,推动了肥胖相关疾病的早期检测、预防和治疗的应用。
Palmieri等[3]利用机器学习方法对肥胖女性的内脏脂肪进行分类,使用常规的实验室指标如血液化学浓度数据,研究表明,机器学习模型能够有效地从这些指标中提取出与肥胖相关的特征,进行内脏脂肪的高精度分类。该研究通过比较不同的机器学习分类器,发现其在精确度和召回率上均有显著提高,尤其在没有依赖昂贵医学影像技术的情况下,能够提供较为准确的肥胖风险预测。这一研究推动了个性化健康管理,并为相关疾病的早期诊断提供了新的思路。
综上所述,机器学习方法为肥胖预测提供了强大的工具,能够有效处理高维和复杂数据。
2 创新点
使用SHAP解释肥胖水平的预测填补了当前研究中的重要空白。虽然机器学习模型(如XGBoost、随机森林等)已广泛应用于肥胖预测,但这些模型的“黑箱”特性限制了其在医学领域的可信度和应用价值。SHAP通过提供特征贡献的透明解释,能够帮助更深入地理解肥胖预测中的关键驱动因素,如饮食、运动、遗传因素等。这种可解释性在临床实践中具有重要意义,有助于开发个性化干预措施,推动肥胖管理和预防策略的制定。目前,关于SHAP在肥胖预测中的研究仍然较少,因此这一领域的探索不仅具有学术创新性,还可以为公共健康领域带来实际应用价值。这一研究方向能够推动机器学习在医疗健康中的应用,为临床医生提供更具解释性和信赖度的决策支持工具。
3 模型的理论概述
3.1 XGBoost算法理论
XGBoost(eXtremeGradientBoosting)是一种基于梯度提升的高效实现,其核心思想是通过逐步构建新的弱学习器来改进已有模型的预测误差。它使用加权决策树作为基础模型,并在每次迭代中通过最小化损失函数更新模型。
3.1.1 XGBoost算法步骤
步骤内容如下:
1)初始化模型。从常数模型开始,预测所有样本的平均值。2)计算残差。用当前模型的预测值与真实值之间的差距作为残差。3)拟合弱学习器。通过构建一棵决策树,拟合这些残差来最小化损失函数。4)更新模型。将新树的预测值加到当前模型中,并重复步骤2)和3),直到达到预定的树数或误差足够小。5)正则化。在每次迭代时通过正则化控制模型复杂度,防止过拟合。
3.1.2 XGBoost核心公式
损失函数(含正则项)为:
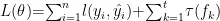
其中 l 表示预测值与真实值之间的损失; 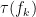 为正则化项,控制模型复杂度。
为正则化项,控制模型复杂度。
正则化项为:
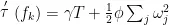
其中 T 表示树的叶子结点; 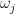 表示叶子节点权重,y和 ϕ 表示正则化参数,用于控制树的生长。
表示叶子节点权重,y和 ϕ 表示正则化参数,用于控制树的生长。
树的每个叶节点权重通过下式求解:
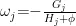
其中 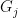 表示目标函数对模型输出的一阶导数(梯
表示目标函数对模型输出的一阶导数(梯
度); 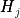 表示目标函数对模型输出的二阶导数(Hessian矩阵)。
表示目标函数对模型输出的二阶导数(Hessian矩阵)。
树的结构分裂的分裂点通过以下增益公式确定:
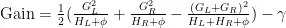
其中 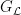 ,
, 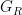 表示左、右子树的梯度和;
表示左、右子树的梯度和; 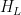 ,
, 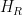 表示左、右子树的Hessian和。
表示左、右子树的Hessian和。
3.2 SHAP理论
SHAP(SHapleyAdditive exPlanations)是一种解释机器学习模型输出的方法,其基于合作博弈论中的Shapley值。Shapley值提供了一种公平分配特征贡献的方法,使得每个特征对模型输出的贡献能够被量化。SHAP值在模型解释中尤为重要,因为它不仅能解释整体模型的特征重要性,还可以解释单个预测的特征贡献[4-5]
SHAP的理论基础是Shapley值,这是合作博弈论中用于分配合作收益的一种解决方案。给定一个包含多个参与者(即特征)的博弈,Shapley值通过计算每个参与者在不同排列下对整体收益的边际贡献,得到该参与者的平均贡献。
对于一个机器学习模型来说,可以将每个特征看作是“参与者”,而模型的输出看作是“收益”。SHAP值通过计算每个特征在所有可能组合中的边际贡献,来衡量该特征的重要性。
Shapley值计算式为:
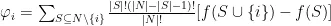
其中: 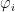 表示特征 i 的Shapley值; N 表示所有特征的集合; S 表示特征 i 之外的一个特征子集; f (S)表示只考虑特征子集 s 的模型预测输出;
表示特征 i 的Shapley值; N 表示所有特征的集合; S 表示特征 i 之外的一个特征子集; f (S)表示只考虑特征子集 s 的模型预测输出; 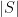 表示子集S 的大小,
表示子集S 的大小, 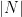 表示全部特征的数量。
表示全部特征的数量。
每个数据样本的预测值可以被分解为基线值加上所有特征的SHAP值之和:
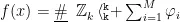
其中 f ( x ) 表示模型对样本 x 的预测值, 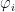 表示特征 i 的SHAP值, M 表示特征的总数,基线值是训练集中的所有样本的平均预测值。
表示特征 i 的SHAP值, M 表示特征的总数,基线值是训练集中的所有样本的平均预测值。
4数据获取与预处理
4.1 数据获取
本文模型训练采用的是De-La-Hoz-Correa等人在2019年收集的根据墨西哥、秘鲁和哥伦比亚个人的饮食习惯和身体状况,估计其肥胖程度的数据[]。数据包含17个属性和2111条记录,与饮食习惯相关的属性有:高热量食物的频繁摄入(FAVC)、蔬菜的摄入频率(FCVC)、主餐次数(NCP)、两餐之间的食物摄入量(CAEC)、每日饮水量(CH20)和酒精摄入量(CALC)。与身体状况相关的属性有:卡路里摄入监测(SCC)、身体活动频率(FAF)、电子设备使用时间(TUE)、交通工具(MTRANS),获得的其他变量有:家族肥胖史、性别、年龄、身高和体重。最后,标记所有数据,并根据方程创建类变量肥胖水平(NObesity),其值为:体重不足、体重正常、超重I级、超重II级、肥胖类型I、肥胖类型II和肥胖类型 I I I 。 7 7 % 的数据是使用Weka工具和SMOTE过滤器合成的, 23 % 的数据是通过网络平台直接从用户处收集的。表1为数据变量表。
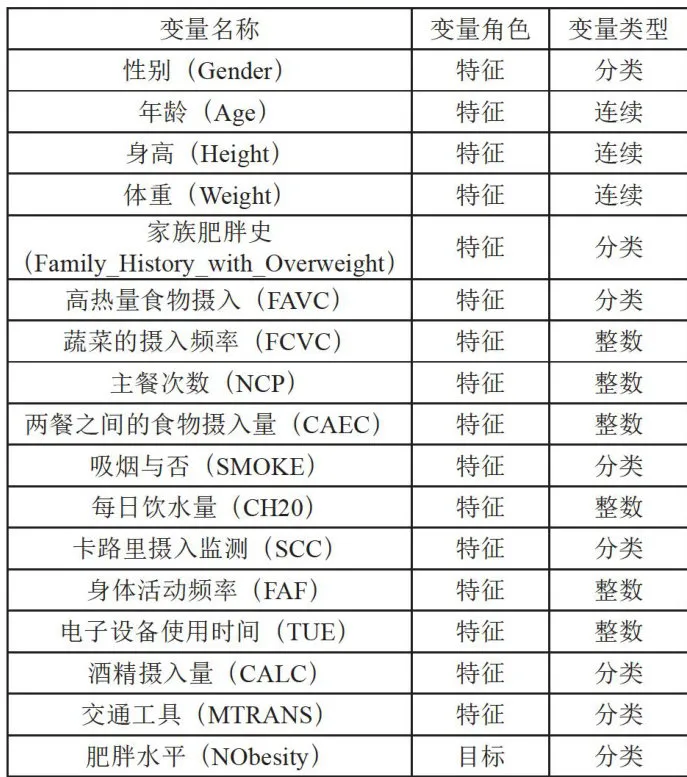 表1数据变量表
表1数据变量表4.2 数据预处理
数据集不存在缺失值和预测值。
由于某些特征变量和目标变量为类别变量,无法直接进行XGBoost分类预测的模拟,所以需要提前对其进行量化处理:如分别用0和1表示性别为女性和男性;NObesity(肥胖水平)从0至6分别表示为体重不足、体重正常、超重I级、超重ⅡI级、肥胖类型I、肥胖类型II和肥胖类型IⅢII,即数字越大代表肥胖水平越高。
由于肥胖水平是根据体重指数判断的,而体重指数的计算式为:
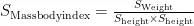
由此可见,体重和身高直接影响了样本的肥胖水平。所以在进行机器学习模拟之前,删去体重和身高变量。随后对其他特征变量进行相关性分析,结果如图1所示。
由图可知,各特征变量间的相关性水平均不高(最高为0.57),且特征变量间的相关性水平并不相似,因此不存在多重共线性问题,无须再剔除特征变量。
利用Scikit-learn库的train_test_split函数,将处理后的数据集按照4:1进行划分,其中 80 % 作为训练集, 20 % 作为测试集,最终将数据集划分为1689个训练样本和422个测试样本。
5 模型评估与解释
5.1 预测模型的评估
XGBoost并不是当前仅有的机器学习分类预测模型,在处理不同问题时,适用的机器学习模型可能会不同,因此机器学习模型通常需要合适的评价体系进行模型评估,本文通过对比XGBoost、随机森林和SVM(支持向量机)三种预测模型的准确率、精确率、召回率和F1得分对三种模型进行评估,结果如图2所示。
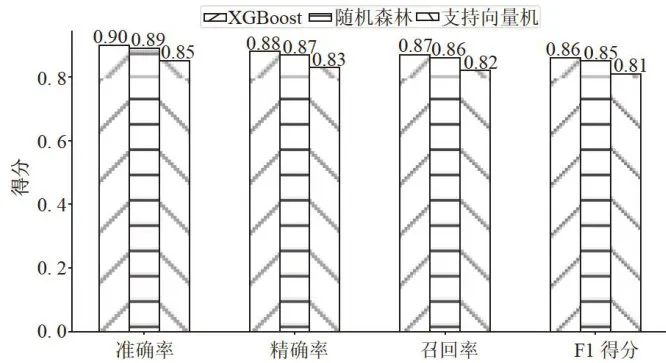 图2模型性能比较图
图2模型性能比较图可见本文选取的XGBoost模型在处理本文所研究的肥胖水平数据上更加具有优越性。
5.2 可解释性分析
在上述工作的基础上,本文引入SHAP模型对影响肥胖水平的因素进行可解释性分析[7-10]。
5.2.1 特征重要性分析
为了可视化不同特征对模型输出的平均影响,绘制影响肥胖水平的重要特征分析图,该图展示了每个特征的SHAP值的平均绝对值,用于衡量各个特征在模型预测中对输出结果的影响大小。结果如图3所示。
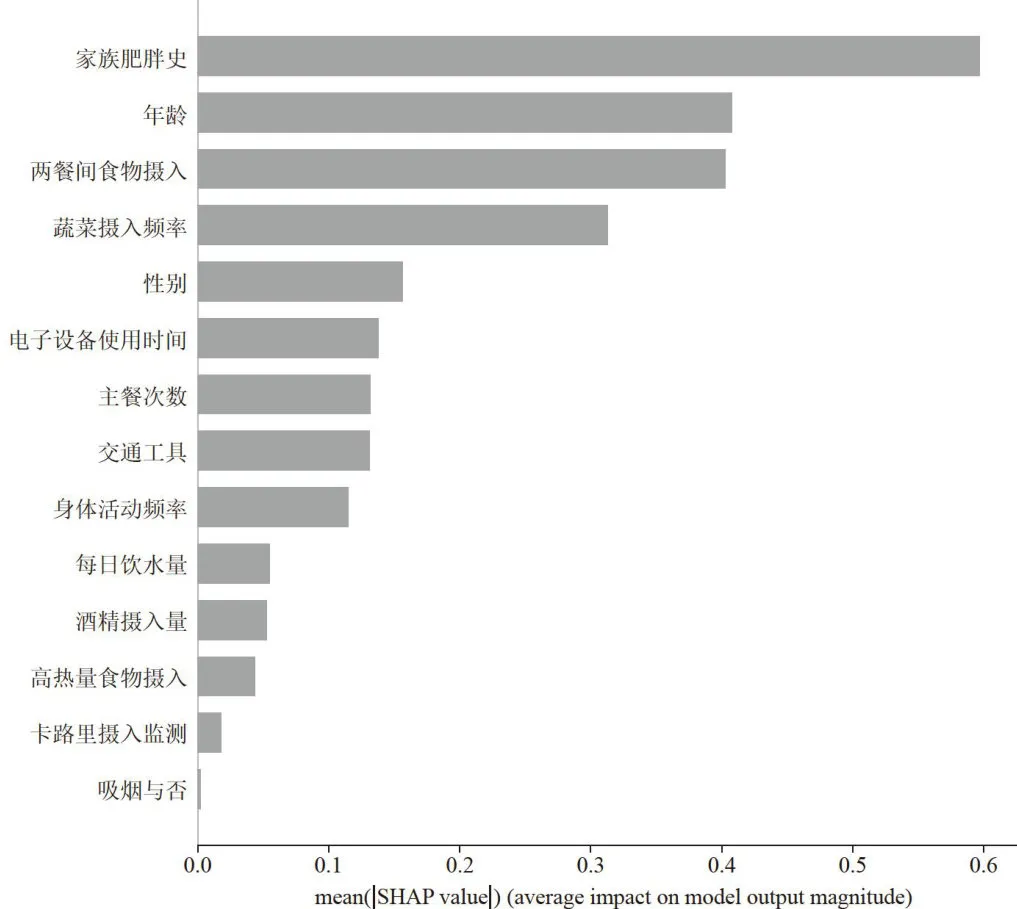 图3特征重要性分析图
图3特征重要性分析图由图可以看出,“家族肥胖史”是对模型影响最大的因素,平均影响值接近0.6,说明有肥胖家族史的人更容易预测出肥胖问题。其次是“年龄”,其SHAP值显示了年龄对肥胖的显著影响,影响力略小于家族肥胖史。“两餐间食物摄入量”和“蔬菜摄入频率”也是重要的影响因素,表明饮食习惯在肥胖预测中起到了很大的作用。性别对模型的影响较为中等,说明性别差异在某种程度上影响了肥胖的可能性。相比之下,“每日饮水量”“酒精摄入监测”和“卡路里摄入”等因素的影响较小,表明这些变量对模型预测肥胖的贡献有限。尤其是“吸烟与否”几乎没有影响,可能意味着吸烟在该模型中的作用微乎其微。
总体来看,家庭遗传、饮食习惯和年龄是肥胖预测中最关键的因素,而其他生活方式因素如身体活动频率和电子设备使用时间虽然也有一定影响,但相对较小。
5.2.2 SHAP总结图
如图4所示,SHAP总结图展示了各个特征对模型预测输出的影响。每一个点代表一个样本,颜色表示该特征的数值高低,深黑色为高,灰白色为低。SHAP值(横轴)反映了每个特征对于肥胖预测的贡献,值越大则表明该特征对于预测肥胖的影响越大。
在这张图中,“家族肥胖史”是最重要的特征,黑色的点主要集中在正SHAP值区域,这表明具有肥胖家族史的个体倾向于更高的肥胖风险。接下来的重要特征是“年龄”,随着年龄的增加,SHAP值也趋向正数,表明年龄越大,肥胖风险越高。然而,部分灰白点(较年轻个体)位于负值区,这意味着年龄较小的个体肥胖风险相对较低。“两餐间食物摄入量”较高与较大的正SHAP值相关,说明频繁进食可能增加肥胖风险。相反,“蔬菜摄入频率”对肥胖的影响显示出负相关的趋势,摄入频率越高,SHAP值越趋向负值,表明蔬菜摄入有助于降低肥胖风险。“性别”这一特征中,男性的特征值1对应的SHAP值较高,表明男性肥胖的风险更大。同理,其他特征对SHAP值均有相应的影响,但影响没有上述特征大。
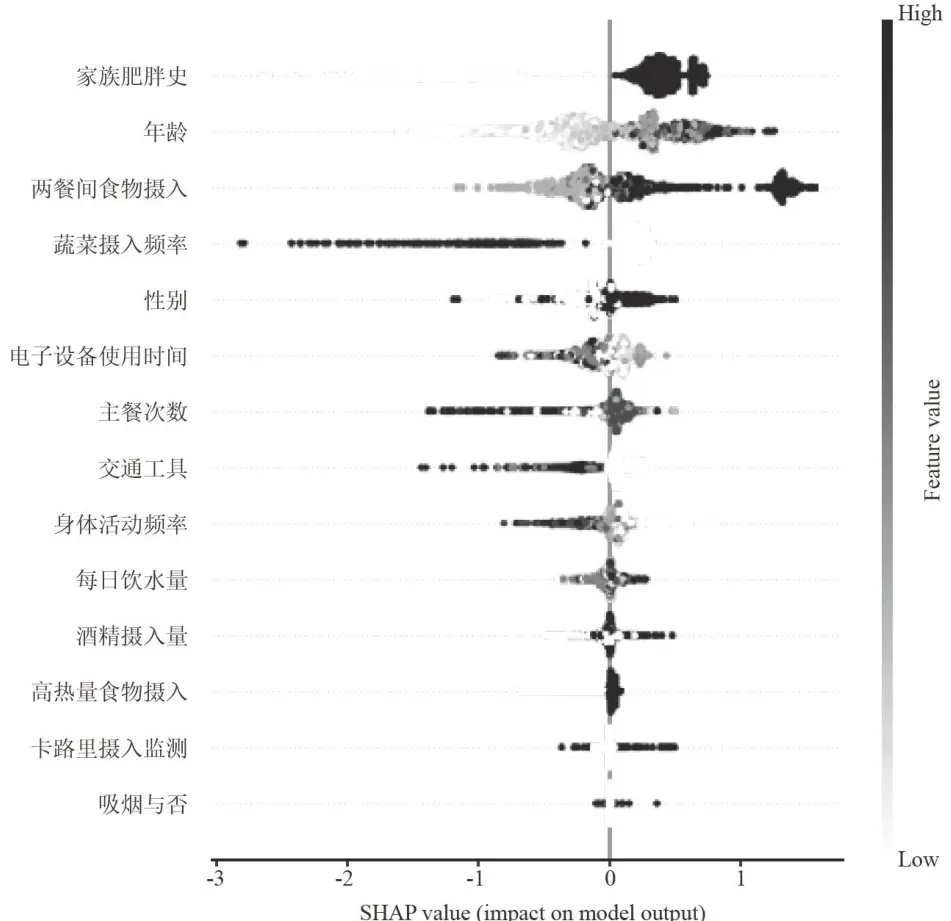 图4SHAP总结图
图4SHAP总结图5.2.3 单样本特征分析一个性化方案
单个样本解释图对制定个性化方案具有重要意义,因为它能够展示每个特征对模型预测结果的具体贡献,帮助理解模型对某一特定个体或情境的决策过程。通过这种可解释性分析,可以看到哪些因素在推动预测结果的变化,哪些因素则在抑制变化,从而在制定个性化方案时可以有的放矢。SHAP图清晰地将特征按其对结果的影响大小进行排序,并区分了正向和负向的影响。在设计个性化方案时,可以依赖这种解释来确定需要干预的重点因素,避免“一刀切”的通用方案,实现更精确、更有针对性的方案设计[1]图5是分类为肥胖III的单个样本解释图。
 图5肥胖Ⅲ单样本特征分析图
图5肥胖Ⅲ单样本特征分析图从这个SHAP单样本解释图来看,该个体的肥胖风险受到多个因素的影响,主要推动肥胖风险上升的因素依次为两餐间食物摄入量为2、家庭肥胖史为1、年龄为25、蔬菜摄入频率为1、交通工具为0、电子设备使用时间为1以及身体活动频率为2。两餐间食物摄入量为2则反映出该个体在两餐之间的食物摄入量较大,可能进一步增加每日的总热量摄入,推动肥胖风险上升。家庭肥胖史为1表明该个体有遗传性肥胖的风险,这在一定程度上增加了肥胖的可能性。蔬菜摄入频率为1意味着该个体的蔬菜摄入相对较少,可能导致膳食纤维摄入不足,影响体重管理。交通工具为0表示该个体不通过步行等方式进行日常出行,这表明日常活动水平较低,进一步推高了肥胖风险。电子设备使用时间为1意味着该个体存在久坐的行为,因此增加了肥胖风险。身体活动频率为2表明该个体每天身体活动较多,但可能对该个体来说依然达不到消耗热量的水平,小程度推动肥胖风险上升。
基于以上分析,个性化健康管理建议包括优化进餐次数、增加日常身体活动、提高蔬菜摄入频率、控制两餐间食物摄入以及管理家族遗传风险。首先应考虑调整每日的进餐次数,减少过多的热量摄入,同时确保每餐均衡搭配。其次,增加日常的身体活动,如通过步行、骑自行车等替代现有的出行方式,尽量减少久坐时间。建议逐渐增加蔬菜的摄入,以补充膳食纤维并控制总热量。对于两餐之间的食物摄入,可以选择更健康、低热量的食物如水果和坚果,避免高脂、高糖零食。虽然遗传因素不可改变,但通过改善饮食和增加运动,仍能有效控制体重并减少肥胖风险。通过这些个性化的干预措施,可以帮助该个体更好地管理肥胖风险,减少与之相关的健康问题。
6结论
本文通过对肥胖水平的分析,结合不同特征对肥胖风险的影响,利用机器学习模型进行预测,并通过SHAP可解释性分析解释各个特征对预测结果的贡献。本文的研究重点在于使用XGBoost模型进行肥胖分类预测,并结合SHAP提供的特征重要性分析,探索了家族肥胖史、年龄、饮食习惯、身体活动频率等因素对肥胖的影响,从而揭示了影响肥胖水平的关键因素。
总结来看,机器学习技术为肥胖分类预测提供了有效的工具,而SHAP的引入为模型结果的解释性提供了支持。这不仅帮助更深入理解肥胖的成因,还能够为个体提供个性化的健康管理建议。通过对肥胖影响因素的挖掘与分析,可以为预防肥胖、改善生活方式提供科学依据,具有重要的公共卫生应用价值。
参考文献:
[1]DuganTM,MukhopadhyayS,CarrollA,etal.Machine Learning Techniques for Prediction ofEarly ChildhoodObesity[J].Applied Clinical Informatics,2015,6(3):506-520.
[2]DirikM.Application of machine learning techniques forobesityprediction:acomparative study[J].Journal ofComplexityinHealthSciences,2023,6(2):16-34.
[3]PalmieriF,AkhtarNF,PanéA,etal.Machine learningallowsrobustclassificationofvisceral fatinwomen with obesity using common laboratory metrics [J/OL].Scientific Reports,2024,14(1):17263[2024-08-20].https://www. nature.com/articles/s41598-024-68269-y.
[4]黎子豪,蒋恕.基于机器学习和SHAP算法的声波测井曲线重构及可解释性分析[J].地质科技通报,2025,44(1):321-331.
[5]吕慧敏,刘明锋,靳茜茜,等.SHAP分析指导的早期损伤时间可解释推断模型构建[J].中国法医学杂志,2024,39(3):320-326.
[6]UCI Machine Learning Repository. Estimation of Obesity Levels Based on Eating Habits and Physical Condition[R/OL]. (n.d.)[2024-11-04]. https://archive.ics.uci.edu/dataset/544/estim ation+of+obesity+levels+based+on+eating+habits+and+physical+ condition.
[7]刘冬,刘瑞丽,翁海光.基于SHAP解释工具的网络欺凌文本检测模型研究[J].中国人民公安大学学报:自然科学版,2024,30(3):59-69.
[8]韦红亮,章霞,吴培佳,等.基于SHAP分析的施工作业区通行能力影响要素研究[J].交通工程,2024,24(8):23-30+37.
[9]张潇涵,朱翰林,韩志江,等.SHAP值在XGBoostMRI模型中鉴别腮腺恶性肿瘤与Warthin瘤的价值[J].中国临床医学影像杂志,2024,35(7):462-466.
[10]伍洁,陈迪芳,李瑞彤,等.基于XGBoost和SHAP方法的个人信贷风险评估研究[J].现代信息科技,2024,8(8):146-150+155.
[11]张泽,褚哲.基于XGBoost的学生成绩预测及SHAP特征分析研究[J].信息化研究,2024,50(3):34-40.
作者简介:黄东升(2003一),男,汉族,安徽毫州人,本科在读,研究方向:应用统计。