中图分类号:TP333;TP301.6 文献标识码:A 文章编号:2096-4706(2025)07-0093-05
Abstract: Inconsumer electronics products based onNAND flash memory,garbage colection significantlyafects device performance,andcold-hot data separation is the keytooptimizing the garbage colection algorithm.This paper proposes an inovative method that uses the K-means clustering algorithm to automaticall determinethedata heat intervals and achieve eficientcold-hotdataseparation.Additionally,anadaptiveifluence factoradjustmentstrategyisdesignedtodyamically balancetheinfuenceofhistoricaldataheatandrecentdataheatOnthisbasis,thegarbagecolectionstrategyisoptimized.The simulationresults showthatcompared withtheexistingalgorithms,this methodhasasignifcant efectonimproving thereadwriteperformanceand achieving wear leveling,which is helpful in prolonging the service lifeoftheequipment and improving the overall performance.
Keywords: flash memory; garbage collection; cold-hot separation; K-means; clustering
0 引言
随着移动设备、嵌入式系统和数据中心的普及,NANDFlash闪存在存储领域的重要性日益凸显。作为一种非易失性存储介质,NANDFlash具有高速、低功耗和高存储密度的优势,广泛应用于各类设备。它由存储单元组成,划分为页和块,块包含多个页。
尽管NANDFlash速度快、寿命长,但存在读写擦除单位不匹配、写前擦除、无法就地更新[和写入耗尽等问题,限制了其性能和寿命。通过合理的垃圾回收算法,可减轻这些问题对系统的影响,延长使用寿命并提升性能。
研究表明,良好的冷热数据分离[2-5]可有效减少写放大,改善磨损均衡。Lee等[评估了二级LRU、多重布隆过滤器和动态数据聚类三种策略,发现动态数据聚类效果最佳。Shafaei等[]利用范围聚类检测热点数据,提升了垃圾回收性能。Yan等[提出了基于页面序列号(PSN)的FaGC+算法,增强了冷热数据分离的稳定性。
然而,这些策略依赖人为设定的热度超参数,无法适应所有负载,划分精度不高,导致垃圾回收次数增加,系统性能下降。此外,过度依赖历史热度,无法准确识别数据的当前热度。为此,本文提出了基于K-means的动态聚类垃圾回收算法。该算法动态调整历史数据热度与近期数据热度对热度划分的占比。试验结果表明,提出的算法在垃圾收集开销和磨损均衡方面均优于现有算法。
1 方法解析
1.1基于K-means聚类算法的热度划分策略
传统的冷热分离算法通常依赖于人为设定的热度超参数,通过定义不同的热度区间来划分数据。然而,这种方法的缺点在于,热度超参数的设计取决于系统设计者的经验,固定的参数可能在某些情况下表现良好,但整体性能可能受到限制,导致在某些场景下效果不佳。
鉴于现有的冷热分离算法在热度超参数的确定上存在主观性和不确定性。为了解决这一问题,本文提出了一种基于K-means[9聚类算法的热度划分策略。
首先,计算所有状态为满的块的热值,满块热值计算式为:
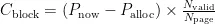
满块热值 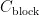 为过去写入数据的热值,
为过去写入数据的热值, 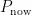 为当前最新的页序号,
为当前最新的页序号, 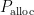 为该块最初被分配时的页序号,
为该块最初被分配时的页序号, 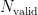 为该块中有效页的数量,
为该块中有效页的数量, 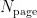 为每个块的页数。
为每个块的页数。
在计算所有满块的热值后,采用K-means聚类算法对其进行聚类,可以得到聚类中心 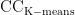 。根据式(1),满块热值越小,数据越热;反之,热值越大,数据越冷。因此,将聚类中心按从小到大排序,反映不同的热度水平,最小的中心值对应最高的热度。这样,无须人为设定超参数,就能基于历史数据热度划分热度区间。
。根据式(1),满块热值越小,数据越热;反之,热值越大,数据越冷。因此,将聚类中心按从小到大排序,反映不同的热度水平,最小的中心值对应最高的热度。这样,无须人为设定超参数,就能基于历史数据热度划分热度区间。
在划分了热度区间之后,需要确定迁移数据应该归属于哪一个热度区间。因此,计算迁移数据的热值,其计算式为:
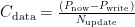
迁移数据热值 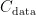 反映了数据的更新频率,其中
反映了数据的更新频率,其中 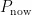 为当前最新的页序号,
为当前最新的页序号, 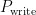 为数据初次写入时的页序号,
为数据初次写入时的页序号, 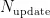 为该数据的更新次数。
为该数据的更新次数。
采取不同的热值计算公式的原因在于综合考虑了数据热值与满块热值的特性差异。因此,本文引入调节因子AF(AdjustmentFactor),对聚类中心进行动态的归一化,具体计算式为:
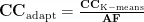
其中 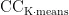 为原本基于 Δ K -means算法算出的各个热度的聚类中心,AF为调节因子,
为原本基于 Δ K -means算法算出的各个热度的聚类中心,AF为调节因子, 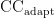 为经过聚类系数归一化后新的聚类中心。
为经过聚类系数归一化后新的聚类中心。
经过归一化处理后, 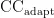 与
与 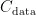 的值处于相似的数量级,使得历史热度能够成为冷热数据划分的评判标准。每个热度区间会分配一个空闲块用于写入数据。在数据迁移时,根据数据热值与聚类中心的距离,选择距离最近的聚类中心作为对应的热度区间,并将数据写入相应的空闲块。两者距离的计算采用了一维空间下的欧氏距离,具体计算式为:
的值处于相似的数量级,使得历史热度能够成为冷热数据划分的评判标准。每个热度区间会分配一个空闲块用于写入数据。在数据迁移时,根据数据热值与聚类中心的距离,选择距离最近的聚类中心作为对应的热度区间,并将数据写入相应的空闲块。两者距离的计算采用了一维空间下的欧氏距离,具体计算式为:
通过以上方法,热度区间的划分无须人为设定超参数,基于K-means算法和历史数据热度即可完成对迁移数据的冷热分离。关于调节因子的调整方法,将
在1.2节中详细介绍。
1.2自适应调节策略
根据前文所述,调节因子对热度划分策略具有重要影响。本文引入马尔科夫链(见图1)[10],对聚类系数的调整策略进行了分析。
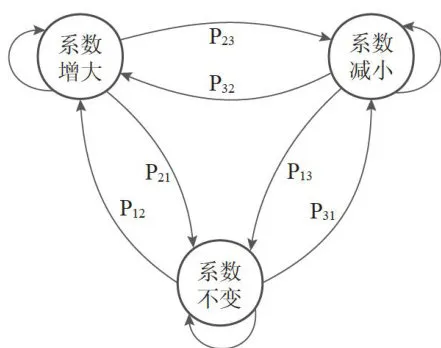 图1自适应调节因子马尔科夫链
图1自适应调节因子马尔科夫链马尔科夫链的特性在于未来状态仅与当前状态相关,而与过去状态无关。经分析可知,调节因子的下一时刻状态可分为系数增加、系数减小、系数不变三种情况,因此可以得到状态转移矩阵。
由于固定的状态转移矩阵在满足特定条件时,马尔科夫链会趋向于稳定的状态分布。为避免调节因子在多次状态转移后固定不变,需要使状态转移矩阵的系数动态变化。
为此,我们引入了GRU[来调整状态转移矩阵的系数。在机器学习中,门控策略可以灵活地遗忘或放大输入信息的影响。在本文中,状态转移矩阵的系数代表调节因子变化的概率。如果当前无法有效分离冷热数据,说明调节因子的值不适应当前负载,此时启用更新门,增加调节因子变化的概率;反之,若冷热分离效果理想,则启用遗忘门,降低调节因子变化的概率。当调节因子下一时刻的状态进入系数增加或减少时,启用重置门重新初始化状态转移矩阵。
调节因子变化的概率是基于当前状态下历史热度和调节因子归一化后的划分效果评估的,它调控了历史热度和近期数据热度的影响。然而,如何评估冷热分离效果仍需解决。为此,我们引入了集中度的概念。
接下来介绍本文的回收块选择策略,我们选取价值最大的块作为回收块,其计算式为:
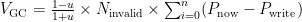
其中, 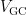 为垃圾回收的价值,其值越大,则代表垃圾回收的收益越高。其中 u 为回收块中有效页的比例,
为垃圾回收的价值,其值越大,则代表垃圾回收的收益越高。其中 u 为回收块中有效页的比例, 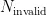 为块 j 中的无效页数,在块 j 被回收后初始化为零。
为块 j 中的无效页数,在块 j 被回收后初始化为零。 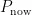 为当前最新的页序号,
为当前最新的页序号, 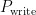 为数据初次写入时的页序号。
为数据初次写入时的页序号。
分析式(5)可知, u 和 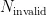 与贪心算法相似,综合考虑了有效页数量与无效页数量的收益;
与贪心算法相似,综合考虑了有效页数量与无效页数量的收益; 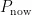 和
和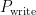 与CB算法相似,综合考虑了年龄和有效页数量。因此,两类块易被选为回收块:有效页较少且包含大量热数据的块;年龄较大且包含大量冷数据的块。
与CB算法相似,综合考虑了年龄和有效页数量。因此,两类块易被选为回收块:有效页较少且包含大量热数据的块;年龄较大且包含大量冷数据的块。
集中度表示在一定数据迁移次数中,冷数据或热数据的比例。当某一比例较高,说明其集中度高,另一则较低。通过判断集中度是否在理想阈值内,可评估当前冷热数据分离效果。对于理想集中度,采用自适应学习算法。由于数据写入具有一定的规律性,当近期迁移的数据集中度偏离理想值,说明存在趋势。我们据此预测下次迁移的数据集中度会保持相似水平,因而相应地调整理想集中度。
1.3动态聚类垃圾回收算法
采用了式(5)的回收块选择策略。选定回收块后,系统复制有效数据,进行冷热数据分离。
冷热数据分离的核心是将寿命相近的数据存放在同一块中。以历史数据热度为判断标准,首先计算满块的热值,利用K-means聚类算法进行聚类。然后,计算回收块中有效数据的热值,求其与聚类中心的距离,确定所属热度区间,并将相似寿命的数据归入同一块。
在空闲块分配策略上,为每个热度区间分配一个块,将数据划分为冷、次冷、次热、热四个区间。增加分类数量使单个块中的数据热度更接近,更可能同时变为无效页,从而提高垃圾回收效率。具体策略
如下:
1)热数据存储在擦除次数最少的空闲块中,因其更新频繁,可快速增加擦除次数。2)次热数据存放在擦除次数第二少的空闲块中,以平衡物理块的擦除次数。3)次冷数据写入擦除次数第二多的空闲块,以平衡这类数据的擦除操作。4)冷数据写入擦除次数最多的块,因其不太可能被更新,存放在擦除次数多的块中可降低其被垃圾回收选中的可能性,从而优化磨损均衡。
基于空闲块分配策略,K-means算法设置了相应参数,并引入调节因子对聚类结果进行归一化,动态调整历史和近期数据热度的影响。我们引入了集中度的概念,用于评估冷热分离效果。通过统计一定次数内冷热分离中冷或热数据的比例,与理想集中度进行比较,预测并调整下一时刻的理想集中度,采用不同的门控单元调整马尔可夫状态转移矩阵的系数。然后,根据状态转移矩阵确定下一时刻调节因子的状态,实现对调节因子的实时控制,动态平衡历史和近期数据热度。
完成有效数据复制后,回收块被擦除,转为空闲块,加入空闲块池。空闲块可能被上述策略选中,用于存储冷热分离后的数据。被分配的块写满后,进入满块池,供垃圾回收使用,从而实现块状态的完整转换流程。动态聚类垃圾回收算法的总体框架图如图2所示。
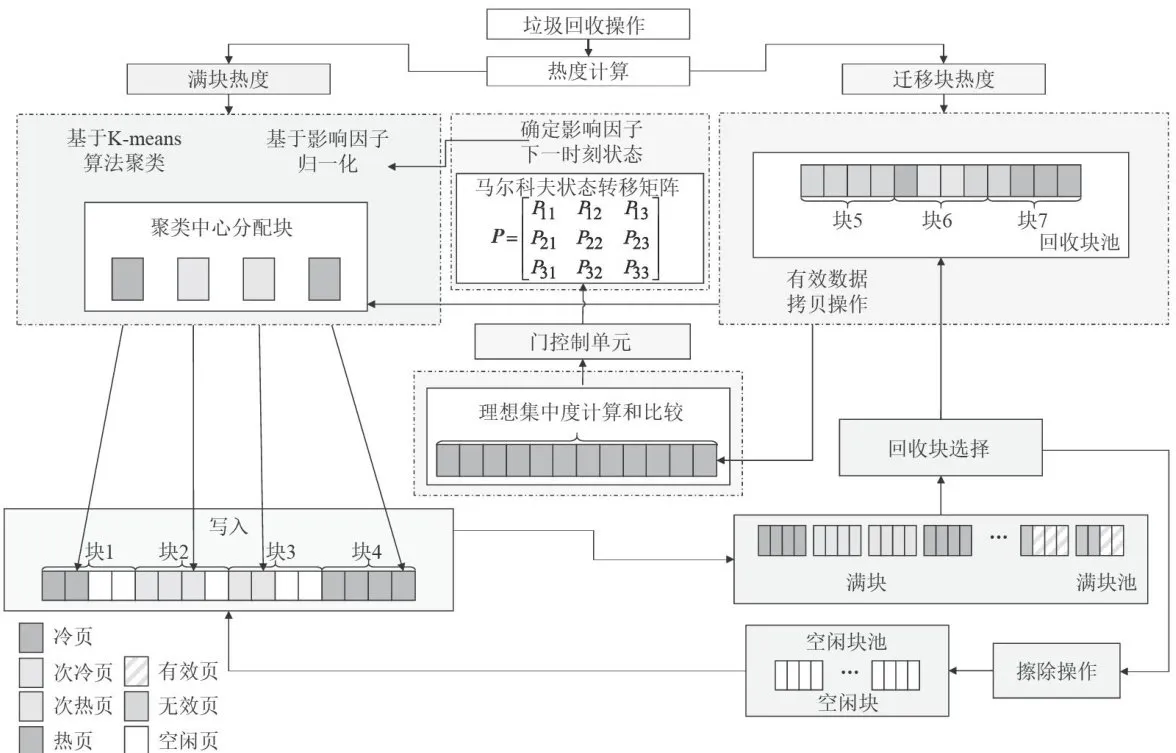 图2动态聚类垃圾回收算法总体框架图
图2动态聚类垃圾回收算法总体框架图2 实验分析
2. 1 实验配置
本研究使用了修改后的Yaffs2文件系统,在基于Linux环境的QEMU嵌入式仿真板上,利用NANDsim模拟了NAND闪存的消费电子产品。实验中,Flash的页大小设定为 2 K B 。对于模拟的NAND闪存设备,读、写和擦除操作的延迟分别为 1 0 μ s 、2 0 0 μ s 和 2 0 0 0 μ s 。
测试文件由测试代码生成,大小从 1 6 K B 到1 0 2 4 K B ,总量占闪存容量的 90 % 。这些文件按照齐夫分布[12]、随机分布、顺序分布以及三种策略的混合分布进行更新。其中,齐夫分布、顺序分布和混合分布各更新了 1 5 % 的文件,而随机分布则更新了60 % 的文件。为公平比较不同垃圾回收算法的性能,实验中禁用了Yaffs2文件系统的缓存和后台垃圾回收,并将模式设置为激进。
实验中所提出算法的初始化参数如表1所示。其中, 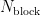 为闪存中的块总数,
为闪存中的块总数, 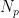 为每个块中的页总数,K 为K-means算法的聚类数,
为每个块中的页总数,K 为K-means算法的聚类数, 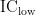 为初始理想集中度下限,
为初始理想集中度下限, 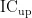 为初始理想集中度上限, P 为初始马尔科夫状态转移矩阵。
为初始理想集中度上限, P 为初始马尔科夫状态转移矩阵。
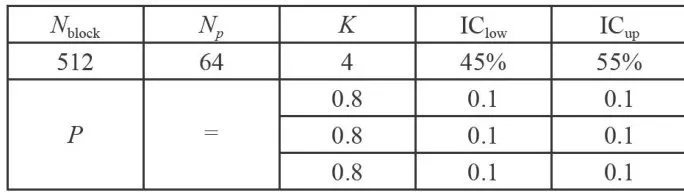 表1实验参数
表1实验参数2.2 性能比较
为了评估NANDFlash中各种算法的性能,将提出的算法与经典和最新的垃圾回收算法(GR、CB、CAT、FaGC、FaGC+)进行比较。性能指标包括垃圾回收开销和磨损均衡水平。垃圾回收开销通过考量所有块的擦除和复制操作次数来衡量。而磨损均衡水平则是通过擦除次数的标准差和每个块的擦除分布来衡量。擦除次数的标准差的计算如下:
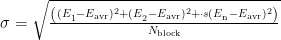
其中, σ 为擦除次数的标准差, 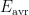 为所有块的擦除次数的平均值,
为所有块的擦除次数的平均值, 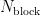 为块的数量。
为块的数量。
图3展示了自适应调节算法对冷热数据分离的影响。未采用该算法时,仅依赖历史数据热度,导致热数据过于集中,聚类中心值过大,没有数据被归为冷数据。引入自适应调节策略后,热数据和次热数据的比例下降,系统成功地将数据划分为冷、次冷、次热和热四类。
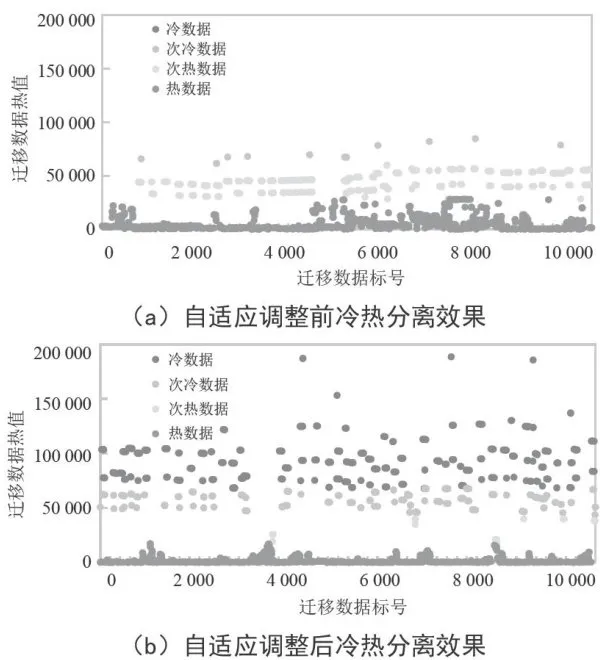
图4展示了垃圾回收算法在闪存擦除次数和数据迁移量上的表现,这直接影响闪存的寿命和性能。我们提出的算法在擦除次数和数据拷贝次数上明显优于以往算法,因为我们精准划分了冷热数据,让寿命相近的数据存放在同一块中,减少了回收块中的有效数据量,释放了更多空间,从而降低了擦除和拷贝次数。其他在齐夫分布策略下表现好的算法,往往在其他更新策略下波动较大。而K-means算法由于其自适应特性,在擦除次数和数据迁移量方面始终表现出色。
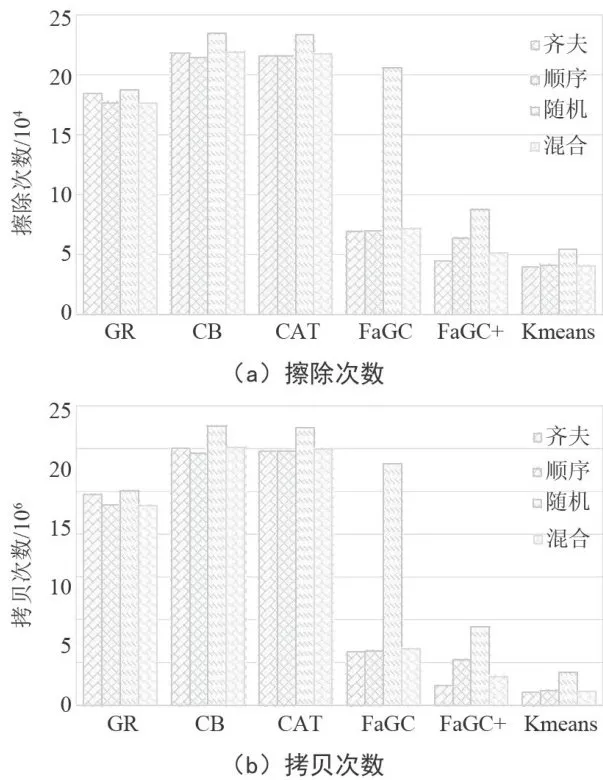 图4所有块的擦除和拷贝次数
图4所有块的擦除和拷贝次数图5展示了垃圾回收算法在磨损均衡方面的表现,具体为擦除次数的标准差。我们的算法在选择要回收的块时,综合考虑了无效页数量和块的年龄,使得热块和冷块都有机会被回收。结合自适应调节算法,动态调整冷热回收块的比例,进一步平衡每个块被回收的可能性。因此,我们的算法实现了更好的磨损均衡,相比其他垃圾回收算法,能有效延长消费电子产品的使用寿命。图中显示,我们的算法在标准差和最大擦除次数方面都优于其他算法。
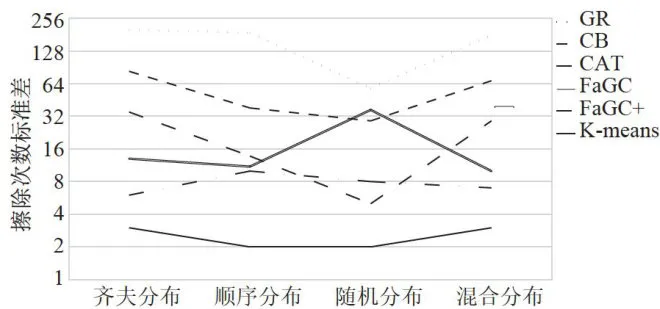 图5所有块的擦除次数标准差
图5所有块的擦除次数标准差综合比较各种NANDFlash垃圾回收算法后,我们得出结论:传统算法通常使用固定的划分标准,而我们的自适应调节算法能够持续调整历史热度和近期热度的平衡,并根据冷热数据分离效果进行优化。这种适应性使得算法在处理大量写入数据时表现出色,性能优于其他算法。
3结论
垃圾回收的不良影响会严重影响消费电子产品的性能和寿命。为了解决这个问题,提出了一种新的垃圾回收算法,利用K-means聚类实现冷热数据的自动划分。该算法结合了历史数据和迁移数据的热度计算,精确区分冷热数据。它还采用了自适应的影响因子调节策略,灵活平衡历史和近期数据的热度影响。此外,分析了马尔可夫链在影响因子状态中的作用,并通过门控策略灵活调整状态转移矩阵的系数,防止其收敛到固定数值。同时,引入了集中度概念来评估冷热数据分离的效果,并使用近期负载学习技术预测未来理想的冷热数据分离状态。通过对NANDFlash消费电子产品的仿真和评估,实验结果显示,所提出的算法在读写性能和磨损均衡方面都有显著的提升。
参考文献:
[1] CHANG L P,KUO TW.Efficient Management forLarge-scale Flashmemory Storage Systemswith ResourceConservation[J].ACMTransactions on Storage,20o5,1(4):381-418.
[2]XIEW,CHENY.AnAdaptiveSeparation-AwareFTI forImproving the Efficiency ofGarbageCollection in SSDs [C]//2014 14th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing.Chicago:IEEE,2014:552-553.
[3]GUJQ,WUCT,LIJ.HOTIS:AHotDataIdentification Scheme to Optimize Garbage Collection ofSSDs [C]//2017 IEEE International Symposium on Paralleland Distributed Processing with Applications and 2017 IEEEInternational Conference on Ubiquitous Computing andCommunications (ISPA/IUCC).Guangzhou:IEEE,2017:331-337.
[4] YANG J,PEI S Y.Thermo-GC:Reducing WriteAmplification by Tagging Migrated Pages during GarbageCollection [C]//2019 IEEE International Conference onNetworking, Architecture and Storage (NAS).EnShi: IEEE,2019:1-8.
[5] LUO Q W,FANG X X, SUN Y C,et al. Self-LearningHotData Prediction:Where Echo State Network Meets NANDFlash Memories [J].IEEE Transactions on Circuits and Systems I:Regular Papers,2020,67(3):939-950.
[6] LEE J,KIMJ S.An empirical study of hot/cold dataseparation policies in solid state drives (SSDs) [C]//Proceedingsof the 6th International Systems and Storage Conference.Haifa:ACM,2013:1-6.
[7] SHAFAEI M,DESNOYERS P,FITZPATRICK J.Write Amplification Reduction in Flash-Based SSDs ThroughExtent-Based Temperature Identification [C]//Proceedings ofthe 8th USENIX Conference on Hot Topics in Storage and FileSystems.Denver:USENIXAssociation,2016:106-110.
[8] YAN H,HUANG Y,ZHOU X Z,et al.An Efficientand Non-Time-Sensitive File-Aware Garbage CollectionAlgorithmforNANDFlash-BasedConsumerElectronics[J].IEEETransactionson ConsumerElectronics,2018,65(1):73-79.
[9]MACQUEEN J. Some Methods for Classification andAnalysisofMultivariate Observations [C]//Proceedings of the fifthBerkeley Symposium on Mathematical Statistics and Probability.California:University ofCalifornia Press,1967:281-297.
[10]GAGNIUCPA.Markov Chains:From Theory toImplementation and Experimentation [M].Germany: Wiley,2017.
[11] CHUNG JY,GULCEHRE C,CHO K H,et al.Empirical Evaluation of Gated Recurrent Neural Networks onSequence Modeling [J/OL].arXiv:1412.3555 [cs.NE].[2024-10-03].https://doi.org/10.48550/arXiv.1412.3555.
[12] LIN MW,CHEN S Y.Efficient and Intelligent GarbageCollection Policy for NAND Flash-based Consumer Electronics [J].IEEE Transactions on Consumer Electronics,2013,59(3):538-543.
作者简介:傅宬或(1999一),男,回族,天津人,硕士研究生在读研穷方向·NandFlash垃圾回收算法:通
信作者:严华(1971一),男,汉族,四川渠县人,教授,博士,研究方向:智能信息系统。