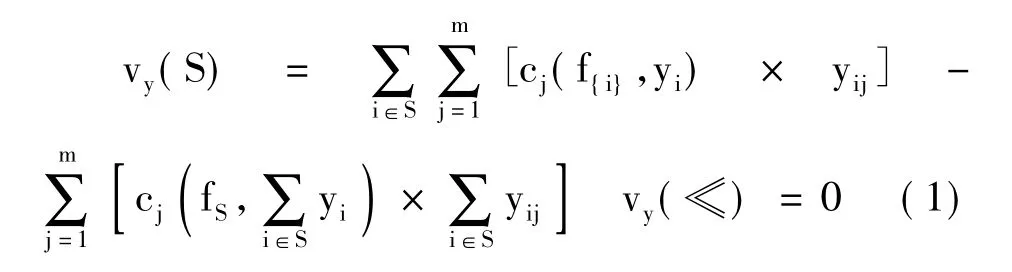中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2025)07-0087-06
Abstract:Lung cancer has become one of the common cancers with high mortality worldwide.Pulmonary nodules are the early manifestationsoflungcancer.Aimingatthediffcultyof pulmonarynoduledetectioninCTimages,apulmonary nodule detection algorithm based on improved YOLOv8s is proposed.The backbone network uses improved YOLOv8s,and uses Space-to-Depth Convolution toreplacethe traditional step-sizeconvolutionand poling layertoavoid thelossoffine-grained information caused by step-size convolution and poling layer when processing low-resolution images or small objects.The coordinateattentionmoduleisaddedtoconsiderteinter-channelrelationshipandpositioninformationofthepulmonarynodule image,othat themodelcanlocateandidentifythetargetareamoreaccurately.FocalLossisusedtoreplacethecros-entropy loss function to solvethe problemofsmallnumberofsample labels inthe dataset.Theadaptive activationfunctioncan not only improve the stabilityofthe network,butalso improve theaccuracyofthe network.The LUNA16datasetisusedtoverifythe performance of the algorithm.The detection accuracy of the improved pulmonary nodule detection algorithm reaches 7 7 . 8 % , which is 3 . 7 % and 8 . 6 % higher than that ofFasterR-CNNand YOLOv8sdetectionalgorithms,respectively.
Keywords: pulmonary nodule detection;YOLOv8s;no more strided convolution;adaptiveactivation function; spatial attentionmechanism
0 引言
肺癌已成为全球常见癌症中死亡率最高的疾病[]。肺癌的最初症状是肺部细胞异常生长,形成小的圆形或椭圆形肺结节。在临床医学中,利用肺部影像进行肺结节的检测是肺癌筛查的第一步。在肺癌发展的早期及时进行相关治疗,可有效降低死亡率[2]。传统的肺结节检查依靠医生通过肉眼观察肺部医疗影像,判断影像中是否有肺结节,如有还需要进行性质分类。针对不同性质的肺结节,再进一步诊治。常见的肺部检查手段包括X光、CT、核磁等,其中使用
CT扫描技术来分析肺结节的形态具有效率高、成本相对较低的优势。因此,CT已经成为肺结节筛查、诊断和评估最有效和可靠的手段。
目前主流的目标检测算法包括两阶段的RCNN[3]、FastRCNN[4],一阶段的SSD[5]、YOLO算法,以及基于Transformer的目标检测算法DETR[7]。两阶段指的是检测过程涉及两个主要步骤:首先生成候选框,然后对网络提取的特征进行目标回归。这类算法通常能达到较高的检测精度,但由于需要先进行候选框筛选,因此会损失一部分速度。单阶段目标检测算法不需要生成候选区域,只需一次检测即可获得检测物体的类别概率和位置,因此速度更快,但精度稍低。
模型的检测精度、实时性和轻量化直接关系到医疗设备在医学图像中检测肺结节的准确性和效率。因此,选择了单阶段检测算法中的YOLOv8s模型进行改进。通过引入深度可分离卷积、坐标注意力机制、自适应激活函数、替换损失函数来提高检测模型的检测精度和检测速度。
1 YOL0v8s原模型
YOLOv8[8和YOLOv5网络结构类似,在Back-bone和neck部分,两者都使用了CSP骨干网络梯度分流的思想。YOLOv8使用了梯度流更丰富的C2f结构。在Head部分,将之前的耦合头结构换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。YOLOv8有 n , s , m 、1、 x 五种适用于不同大小检测任务的模型。本文选择YOLOv8s作为基准模型,其网络结构如图1所示。
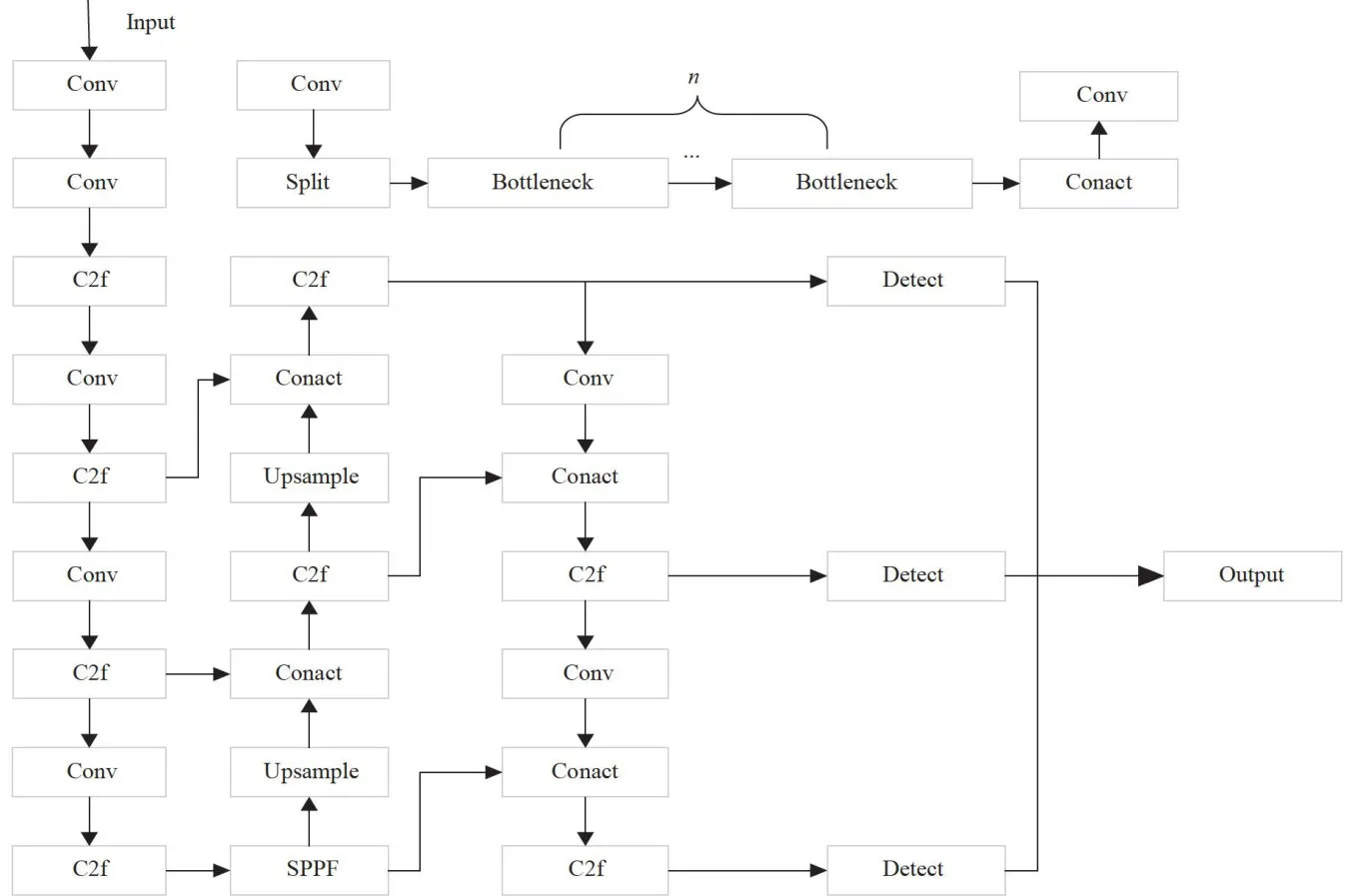 图1YOL0v8s 网络结构图
图1YOL0v8s 网络结构图2 YOL0v8s模型的改进与优化
2.1空间深度转换卷积
卷积神经网络(ConvolutionalNeuralNetwork,CNN)已经成为深度学习中使用最广泛的模块,计算机视觉任务也大量使用了CNN网络。然而,在处理低分辨率图像或小物体时,CNN的性能往往会有所下降。这主要是因为在现有的下采样网络中,普遍采用了跨步卷积或池化层,这些设计导致图像细小特征的丢失。为了改善这一状况,特别是在肺结节检测等小目标检测任务中,我们在YOLOv8s模型的骨干特征提取网络和neck网络中引入了空间深度转换卷积(Space-to-Depth,SPD)模块,其示意图如图2所示。
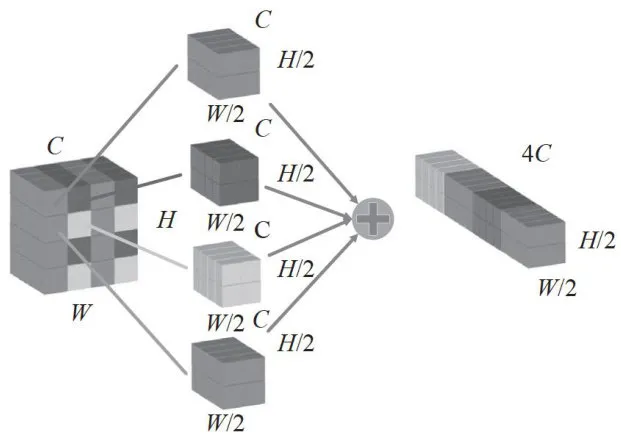 图2SPD模块示意图
图2SPD模块示意图
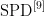 不同于传统的下采样模块,SPD模块在下采样过程中将传统下采样卷积会丢失的特征信息整合到通道维度。对于输入的特征图,SPD模块按照每行每列隔一个像素进行采样,从而生成四个大小均为W / 2 × H / 2 × C 的子特征图。随后,这些子特征图被拼接在一起,形成一个通道数为原来四倍的特征图,大小为 W / 2 × H / 2 × 4 C 。这种设计实现了无信息损失的二倍下采样。
不同于传统的下采样模块,SPD模块在下采样过程中将传统下采样卷积会丢失的特征信息整合到通道维度。对于输入的特征图,SPD模块按照每行每列隔一个像素进行采样,从而生成四个大小均为W / 2 × H / 2 × C 的子特征图。随后,这些子特征图被拼接在一起,形成一个通道数为原来四倍的特征图,大小为 W / 2 × H / 2 × 4 C 。这种设计实现了无信息损失的二倍下采样。
2.2 坐标注意力机制
坐标注意力[io](CoordinateAttention,CA)机制是一种模拟人类视觉系统注意力机制的深度学习技术。它能够在卷积神经网络中有效地分配计算资源,重点关注图像中的重要区域,同时忽略不重要的信息。该模块在原始特征图的水平和垂直方向上应用注意力,得到两个注意力向量,表示包含重要信息的目标区域,从而提高模型的检测精度。
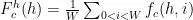

对于输入特征图  和
和 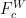 ,输出分别对应式(3)和式(4),然后将两式输出合并为最终的权重矩阵,计算过程对应式(5):
,输出分别对应式(3)和式(4),然后将两式输出合并为最终的权重矩阵,计算过程对应式(5):
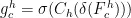
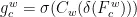
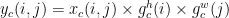
2.3 损失函数
在肺结节影像中,肺结节(正类)只占整个区域的极小部分,过多的背景(负类)会影响检测精度。FocalLoss[1]是一种用于解决类别不平衡问题的损失函数。在模型训练过程中,它会更加关注那些难以分类的肺结节样本,而不是仅仅预测为背景。FocalLoss通过降低容易分类的背景样本的损失权重,同时提高难以分类的肺结节样本的损失权重,使模型能够更好地学习到肺结节的特征,从而提高检测的准确性和召回率。
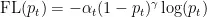
其中, 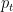 为模型预测样本为正类的概率;
为模型预测样本为正类的概率; 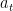 为调整样本之间的权重的平衡因子, γ 为聚焦参数,用于调整难易样本之间的权重。通过这种方式,FocalLoss有效地提升了模型在类别不平衡场景下的性能。
为调整样本之间的权重的平衡因子, γ 为聚焦参数,用于调整难易样本之间的权重。通过这种方式,FocalLoss有效地提升了模型在类别不平衡场景下的性能。
2.4 自适应函数
自适应激活函数[12](Activate Or Not,ACON)是一种新型的激活函数,旨在提高神经网络的性能和泛化能力。ACON激活函数的核心思想是通过引入一个连续的非线性变换,使得激活函数在不同输入范围内表现出不同的非线性特性。
在神经网络中,许多常见的激活函数都是 函数的形式。其中ReLU和Sigmoid为线性函数,其平滑可微近似如下:
函数的形式。其中ReLU和Sigmoid为线性函数,其平滑可微近似如下:

当 n = 2 时,可表示为:

根据式中 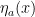 和
和  为的线性函数的不同组合,ACON激活函数有三种,如表1所示,本文选择了ACON-C这种激活函数。
为的线性函数的不同组合,ACON激活函数有三种,如表1所示,本文选择了ACON-C这种激活函数。
 表1ACON函数族
表1ACON函数族2.5 改进后的网络结构
改进后的网络结构如图3所示。使用SPD-Conv模块替换原YOLOv8s网络中的Conv模块,在骨干网络的C2f模块后增加CA注意力模块,使用ACON激活函数替换原网络中的激活函数,并使用FocalLoss损失函数作为新的损失函数。
3 实验结果与分析
3.1 实验环境
LUNA16数据集包括888例肺部CT影像和标注文件,共1186个阳性结节,其中 3 ~ 5 m m 结节272个, 5 ~ 1 0 m m 结节633个,大于 1 0 m m 结节281个。将结节影像按6:2:2划分为训练集、验证集和测试集。
实验使用的训练平台为OpenI启智平台,使用一张NVIDIARTXA10040GB独立显卡,操作系统为Ubuntu18.04,环境为Python3.8和PyTorch1.12.1框架进行训练。初始学习率为0.0001,使用Adam优化器,批次大小为32,迭代次数为200。改进后的模型训练曲线图如图4所示。。由训练曲线图可知,改进后的模型各项损失函数均能较快收敛,在验证集和训练集的损失函数曲线基本一致,表明模型并未出现过拟合的现象。
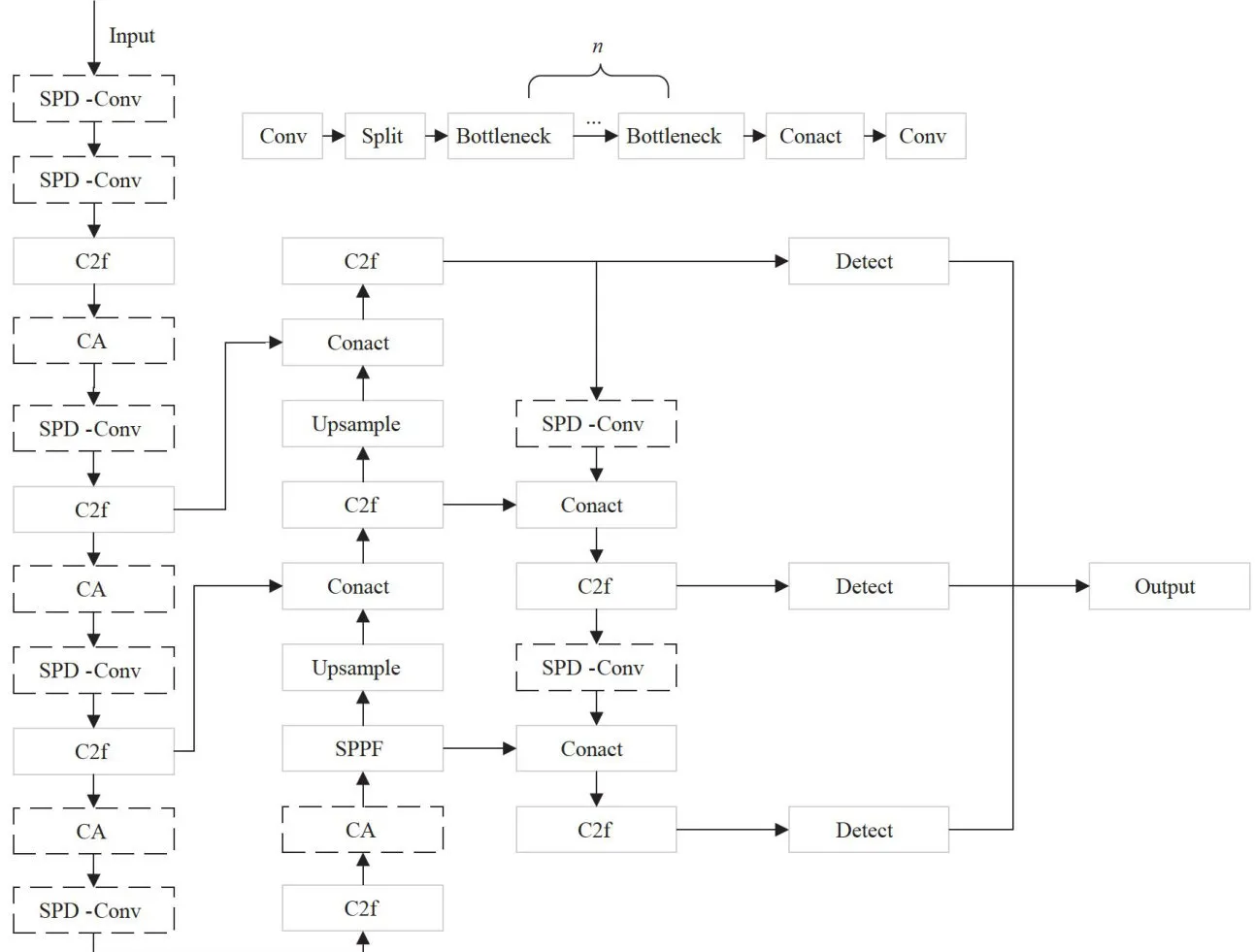 图3改进后的网络结构
图3改进后的网络结构3.2 评价指标
选取目标检测算法常用的评价指标平均精度(AveragePrecision,AP)。AP的计算是由精确率(Precision)和敏感度(Recall)组成。Precision和
Recall的计算公式分别如式(9)和式(10)所示。在速度方面,每秒处理图像数量(FPS)是评估模型实时性和响应速度的重要指标。
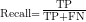
其中TP为正确分类的阳性样本数量,FP为错误分类为阳性样本的阴性样本数量,FN为错误分类为阴性样本的阳性样本数量。AP为类别精度,为精度-召回率曲线下的面积,其计算式为:
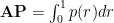
3.3 结果分析
3.3.1 消融实验
为了验证每个添加的模块和改进方法对原始YOLOv8s模型的有效性,在LUNA16数据集上进行了各个模块的消融实验,如表2所示:
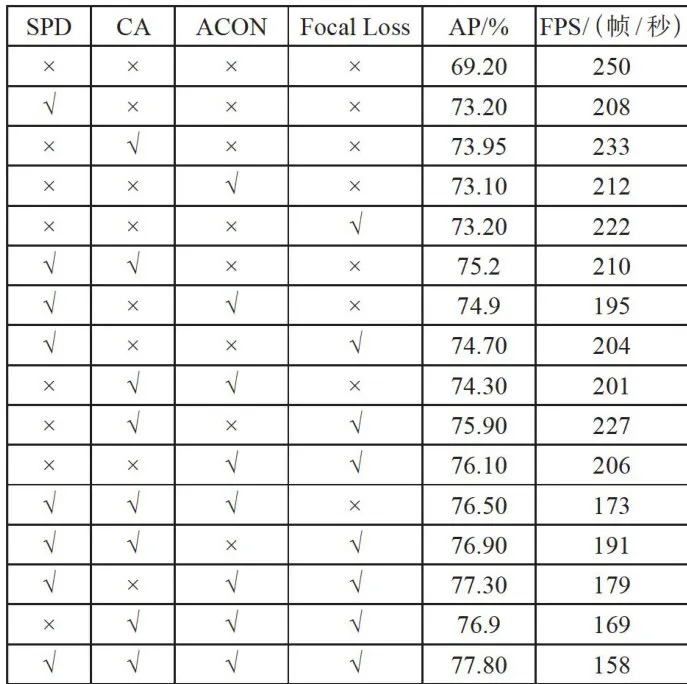 表2消融实验结果对比
表2消融实验结果对比注:“”表示使用了对应的方法,“ × ”表示未使用对应的方法。
由消融实验可知,使用了SPD-Conv、CA、ACON和FocalLoss后,YOLOv8s算法在不同指标mAP和F1分数上都有不同程度的提升。其中,CA注意力模块的提升效果最好,同时FPS也最快,说明融合位置、方向和跨通道信息的方法对于肺结节检测任务十分有效。SPD模块可以在小目标检测任务中进行下采样时,保留更多特征信息,但同时也增加了一定程度的计算量。FocalLoss损失函数比原损失函数更适合肺结节检测任务。ACON激活函数是一种自适应激活方法,可以在保持网络稳定的情况下,更好地提取特征。相对于其他自适应激活算法,其计算量更小。
3.3.2 对比实验
消融实验的结果证明添加的几种模块是有效的。
为了证明修改后的网络在肺结节检测任务中具有更优性能,选择了近几年的主流目标检测算法在LUNA16数据集上进行了性能测试,其各项指标如表3所示。
 表3不同网络模型检测性能对比
表3不同网络模型检测性能对比对比实验结果,FasterRCNN网络模型检测的AP和FPS值分别为 7 4 . 1 % 、16.4帧/秒,检测精度优于YOLO系列,但检测速度较低;YOLO系列算法性能随版本不断提升,在保持高检测速度的前提下,精度也达到了 6 9 . 2 % ,仅比FasterRCNN低 3 . 9 % ,但FPS是其近15倍。本文使用的算法在YOLOv8s的基础上进行了改进,精度提升了 8 . 6 % ,FPS为158帧/秒。
为了能够更加直观地了解改进前后算法的检测效果,使用LUNA16数据集对改进前后的YOLOv8s算法进行检测,得出的检测效果如图5所示。图5中,(a)组图片为结节和正常组织粘连的情况,原始YOLOv8s算法未检测到该结节,改进后的算法能够正确检测到该位置的结节;(b)组图片为微小结节,原始YOLOv8s算法在识别此类结节上有较大难度,且容易将正常组织误识别为结节;(c)组图片因拍摄参数、设备不同导致影像间存在差异,从结果可以看出改进后的算法具有更好的泛化能力。
4结论
肺结节是很多严重肺部病变的早期表现,但如果人工阅读影像不仅工作量大,而且识别结果也受医生水平影响,较小的结节很容易漏检。为了解决医疗资源分布不均衡、微小肺结节病变在CT影像中难以识别的问题,研究通过深度学习网络进行肺结节检测。考虑到实际应用不仅要求检测精度,对检测的FPS也有要求,因此选择在YOLOv8s模型的基础上进行改进。引入了SPD模块、CA注意力模块、ACON激活函数,并更换损失函数为FocalLoss。该方法在LUNA16数据集上相较于其他算法表现更优,验证了改进的有效性。
该方法在提供较高检测准确率的前提下,还保证了较高的FPS,可应用于实际检测场景。CT设备拍摄出影像后,利用该模型可以快速反馈影像结节检测结果供医生参考,实现了肺结节检测的智能化,降低了影像科医生的工作量。
参考文献:
[1]SHARMAP,MEHTAM,DHANJALDS,etal. Emerging Trends in the Novel Drug Delivery Approaches for theTreatmentofLungCancer[J/OL].Chemico-Biological Interactions,2019,309:108720[2024-10-03].https://doi. org/10.1016/j.cbi.2019.06.033. [2]SCHABATHMB,COTEML.CancerProgressand Priorities:Lung Cancer[J].CancerEpidemiology,Biomarkersamp; Prevention,2019,28(10):1563-1579.
[3]GIRSHICKR,DONAHUEJ,DARRELLT,et al.RichFeatureHierarchiesforAccurateObjectDetectionand Semantic Segmentation[C]//2014 IEEE Conferenceon Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580- 587.
[4]GIRSHICKR.FastR-CNN[C]//2015IEEE Intermational Conference on Computer Vision (ICCV).Santiago:IEEE, 2015:1440-448.
[5]LIUW,ANGUELOVD,ERHAND,etal.SSD:Single Shot MultiBox Detector[C]//ComputerVision-ECCV2016.Amsterdam:Springer,2016:21-37.
[6] TERVENJ,CORDOVA-ESPARZAD M,ROMEROGONZALEZ JA.A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS [J].Machine Learning amp; Knowledge Extraction, 2023,5(4):1680-1716. [7]ZHUXZ,SUWJ,LULW,et al.DeformableDETR: Deformable Transformers for End-to-End Object Detection [J/OL]. arXiv:2010.04159 [cs.CV].[2024-09-22].https://doi.0rg/10.48550/ arXiv.2010.04159. [8]VARGHESER,SAMBATH M.YOLOv8:A Novel Object Detection Algorithm with Enhanced Performance and Robustness [C]//2o24 International Conference on Advancesin Data Engineering and Intelligent Computing Systems (ADICS). Chennai:IEEE,2024:1-6. [9] SUNKARAR,LUO T. No More Strided Convolutions orPooling:ANewCNNBuildingBlock forLow-Resolution Images and Small Objects [C]//Machine Learning and Knowledge Discovery in Databases.Grenoble:Springer, 2022:443-459. [10]HOUQB,ZHOUDQ,FENGJS.Coordinate AttentionforEfficientMobileNetworkDesign[C]//2021 IEEE/ CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:13713-13722.
[11] ROSS TY,DOLLAR G. Focal Loss for Dense Object Detection[C]//IEEE TransactionsonPatternAnalysisandMachine Intelligence,2017,4(2):2980-2988.
[12]MANN,ZHANGXY,LIUM,etal.Activate orNot:LearningCustomizedActivation[C]//2021IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville:2021:8032-8042.
作者简介:郭相均(1997—),男,汉族,重庆开州人,硕士在读,研究方向:计算机视觉;通信作者:蒋朝根(1960一),男,汉族,浙江金华人,教授,硕士,研究方向:嵌入式系统及其应用、无线传感器网路。