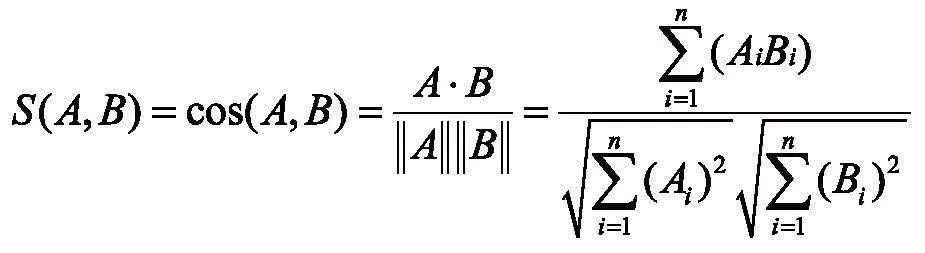中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2025)08-0146-07
Abstract:China isoneofthecountries withthe mostserious naturaldisasters inthe world.Typhoons,arthquakesfoods and ther disasters ocur frequently,posing a huge threat tothesafetyof peopleslives and property.Facing thecomplexityand urgency ofdisasteremergencymanagement,Knowledge Graphtechnology has graduallybecomearesearch hotspot inthis field byvirtueofitsadvantagesiniformationintegration,elationsipingandknowledgereasonig.However,theeterogeity andqualityofisasterdataarenotufor,hichliitstheabilityoftraditioalNaturalLanguageProcessngmethodstotract Knowledge Graph information.Therefore,this paper proposes aLarge Language Model knowledge extraction method based on distributedpromptstrategy.Troughrequirementhints,domainknowledgehintsandfew-shothints,theLargeLanguageModel can automatically extract entitiesand relationships from unstructured data, which improves the automation and accuracy of KnowledgeGraphconstruction.InordertoverifytheefectofKnowledgeGraphbasedonLargeLanguageModelinpractical application,thispapertakes thetyphoondisasteremergencyplanasanexampletocostruct thecoresponding Knowledge Graph and its intelligent question and answer system.
Keywords:Knowledge Graph;Large Language Model; knowledge extraction; inteligent questionandanswer
0 引言
灾减灾要求。
随着气候变化的影响日益显著,极端天气事件如暴雨、洪水、台风等变得更加频繁且剧烈。这不仅增加了灾害发生的可能性,对人民生命财产造成了极大威胁,而且自然灾害种类多且在中国不少地区发生频率很高,加大了灾害管理的复杂性和挑战性。因此,迫切需要提升我国自然灾害应急管理和综合减灾的能力,从而最大程度减少自然灾害给中国经济和社会造成的损失,实现“两个坚持、三个转变”的新时期防
为了有效应对灾害管理带来的挑战,中国各地区都制定了详尽的自然灾害应急预案。这些预案通常包括灾害预警系统的建立与完善、应急响应机制的构建、救援队伍的培训与装备配备、疏散路线的规划以及灾后重建计划等多个方面。此外,随着科技进步和社会发展,灾害应急预案也需要不断地更新和调整,以适应新的形势和技术要求。然而,随着互联网领域的发展,各种数据来源不断涌现,数据量呈指数级增长,自然灾害相关数据在种类和数量上也随之增多,这对数据整合、处理和分析的能力提出了更高要求。因此,从海量数据中获取有效数据,并利用这些数据为人们提供智能化服务,成为当今时代研究的一项重要课题。
知识图谱是一种结构化的语义知识库,能够将复杂的知识以可视化和结构化的方式组织起来,建立起实体、关系和属性之间的关联网络,更加直观、方便地存储和检索信息。依托知识图谱在领域知识学习、组织和推理追溯方面的优势,通过知识图谱技术从文本数据中获取自然灾害应急领域关键知识,完成“数据一信息一知识”的转变,从而提高自然灾害应对效率,促进应急预案电子化、结构化、数字化、智能化发展,提升整体灾害应对能力。在自然灾害应急领域,知识图谱的构建需要提取实体、属性、实体信息等关键信息,通过相互关联的信息形成网状结构。然而,在实际的灾害应急应用中,数据来源多、数据领域受限、数据质量不统一,限制了传统自然语言处理方法对实体、属性及关系的提取,从而制约了知识图谱的应用。
大语言模型是一种基于深度学习的人工智能模型,专门设计用于处理和生成自然语言。这类模型通常是基于Transformer架构,经过在大量的文本数据上进行训练,能够理解、生成、翻译和总结文本,还可以进行对话、回答问题以及执行各种自然语言处理任务。因此,大语言模型在信息抽取方面展现出强大的理解、学习和表达能力,优秀的学习能力使得大语言模型可以通过少量的示例学习新任务,快速适应不同的信息抽取任务,而不需要大量的特定任务的数据集。
本文提出基于大语言模型的自然灾害应急知识图谱的构建方法和应用研究。利用大语言模型等技术可提取海量数据中的关键信息,为知识抽取阶段提供了极大的便利,从而能更好更快地构建自然灾害应急知识图谱。
1研究背景
知识图谱的构建通常包括知识获取、知识表示、知识融合和知识推理等过程。在知识获取方面,研究者们采用自然语言处理、信息抽取等技术,从文本、数据库、传感器数据等多种数据源中获取灾害相关信息,并将其转化为结构化的知识表示。贺海霞等人通过提取关键词,分析建立关键词之间的联系以发现灾害应急相关知识[。在知识表示方面,图谱中的知识通常以节点(实体)和边(关系)的形式表示。为了提升灾害领域知识图谱的表示能力,研究者李泽荃等人从致灾因子、承灾体、孕灾环境等角度分解识别复杂的灾害场景,从而提升对灾害事件的场景感知能力[2];Yan等人提出了动态知识图谱的概念,即能够随着时间和事件的发展动态更新图谱中的知识[3]。
随着自然语言处理技术的迅猛发展,大语言模型在知识图谱构建中的应用逐渐成为研究热点。大语言模型通过海量文本数据的预训练,具备了强大的语义理解和生成能力,能够有效地从非结构化数据中提取实体和关系[4。与传统的信息抽取方法相比,大语言模型可以更准确地处理复杂语境下的语言表达,减少了人工标注的需求,提升了知识图谱构建的自动化程度[5]。近年来,研究者们开始探索利用大语言模型进行知识图谱的自动构建。Brown等人提出了利用GPT-3模型生成领域特定知识图谱的框架,能够从文本中自动提取和链接实体,显著提升了知识图谱构建的效率[。此外,Zhang 等人也对基于BERT模型的实体对齐方法展开了研究,通过上下文理解,解决了异构数据源之间的实体识别和对齐问题,为知识图谱的跨领域融合提供了新的思路[]。
在灾害应急领域,大语言模型通过分析多源文本数据,快速提取实体和关系,生成包含灾害信息的知识图谱,实现对灾害的实时监测和预警[8。Liu等人利用BERT模型自动提取地震相关事件,并构建了动态更新的地震知识图谱,用于实时监测和分析[。在应急响应和决策支持方面,知识图谱结合大语言模型的推理能力,能够提供更加智能化的决策支持。通过对历史灾害数据和当前态势的综合分析,系统能够预测灾害的发展趋势,并生成相应的应急措施。例如,王喆等人开发了一套基于GPT-3的应急响应系统,该系统能够通过自然语言与决策者进行交互,自动生成针对不同灾害场景的应急预案[0]。
2自然灾害应急知识图谱构建
2.1知识图谱构建流程
知识图谱构建采用自顶向下与自底向上相结合的构建方法。从本体构建出发,进而确定各本体之间的关系,最后确定各本体与属性的关联关系,实现自顶向下构建知识图谱模式层。由于自然灾害应急领域文本数据源多为非结构化数据,传统自然语言处理方法进行知识抽取处理难度较大,本文采用基于GPT-4的方法对关键实体属性信息进行知识抽取,随后进行知识融合,将相似度较高的实体属性信息归一化处理,并设计知识图谱底层存储方式,实现自底向上构建知识图谱数据层。最后进行模式层到数据层的映射,完成知识图谱的构建。
2.2 模式层构建
知识图谱本体是对领域内概念及其关系的一种形式化、规范化的描述,可以为数据层中的要素、属性分解提供理论框架基础。知识图谱模式层主要由实体、关系、属性等知识类的层次结构和层级关系组成,用来对数据层的具体知识形式进行约束。本文从自然灾害应急领域出发,构建自然灾害事件、灾害应急任务、灾害数据、模型方法4类核心要素的自然灾害应急领域本体,并确立各实体间、实体与属性间的关系,表1为本体及本体属性,图1为自然灾害应急领域本体间关联关系。
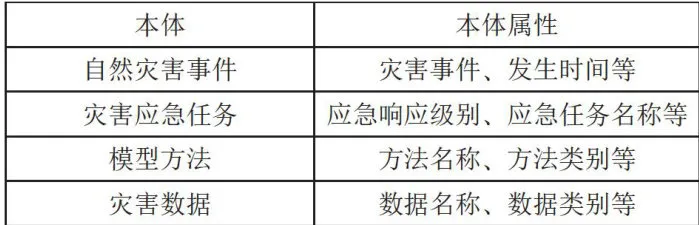 "表1本体及本体属性
"表1本体及本体属性2.3基于大语言模型的数据层构建
知识图谱的数据层以事实三元组为基本单位,是知识图谱体系结构中的核心部分,负责存储和管理实际数据实体及其关系,构成了知识图谱的基础,支撑着整个知识图谱的构建与应用。
自然灾害领域文本数据源多为非结构化数据,这限制了传统自然语言处理方法对知识的有效抽取。基于此,本文提出了基于大语言模型的知识抽取模型,该模型通过大语言模型的提示工程和少样本学习能力,将知识抽取的序列标记任务转化为大语言模型的文本生成任务。与传统的非结构化数据知识抽取方法相比,此方案无须大量数据标注和模型训练。利用大语言模型自身的语义理解能力,结合少量的数据样例和提示工程,模型可学习到文本的语义表示,并可以通过不断微调来提高在特定任务上的表现。
本文以GPT-4作为基础模型[],进行关键实体属性信息的知识抽取。首先,将源文本按照段落进行截断,并设计了多种提示(prompt)以提高信息提取的准确性。在提示设计中,采用了分布提示的策略,包括需求提示、领域知识提示和少样本提示。
需求提示:明确模型的任务角色,清晰传达用户的目标和期望。通过罗列具体细节,使模型理解并聚焦于用户所需的信息,从而确保信息抽取的精确度。
领域知识提示:通过提供与任务相关的背景信息和标注语料,帮助模型理解领域特征和数据特点。此提示增强了模型对特定领域的感知能力,提高了抽取结果的专业性和可靠性。
少样本提示:通过提供具体示例,指导模型逐步掌握每个操作步骤。这不仅有助于模型更好地理解任务,还显著提升了模型在分析与执行中的表现,降低了生成错误的发生率。
这些提示的综合应用,显著提升了模型在知识抽取任务中的表现,并提高了任务完成的质量和效率。以下是基于GPT-4进行自然灾害信息抽取的部分示例。
2.3.1实体信息抽取提示示例
{需求提示}你是一名自然灾害领域的信息抽取专家,任务是从以下文本中提取关键实体及其相关属性。具体需要提取的实体包括:灾害类型、发生时间、发生地点、灾害影响、救援措施、负责机构等。请为每个实体提取其相关的属性信息,并输出格式为:“实体:属性”。
{领域知识提示}以下文本涉及自然灾害事件的报道或研究,重点在于描述灾害的基本信息及其影响。需要提取的实体和属性包括但不限于:灾害类型(如地震、飓风)、灾害名称、发生时间(具体日期或时间段)、发生地点(城市、国家或区域)、灾害影响(引发次生灾害、直接受影响或被疏散的人数、死亡人数、经济损失等),以及救援措施(如政府或组织采取的行动)和负责机构。请注意,某些术语在灾害领域有特定含义,如“风速”常与台风、飓风相关联,“风眼”指台风的中心区域等。
{少样本提示}文本:“2023年7月,京津冀首都圈海河流域发生特大暴雨,引发严重的洪涝和地质灾害,造成550万余人受灾,上百人遇难失踪,直接经济损失超过1600亿元。
输出示例:
-灾害类型:暴雨-发生时间:2023年7月-发生地点:京津冀首都圈海河流域
-灾害影响:洪涝、地质灾害,550万余人受灾,上百人遇难或失踪,经济损失超过1600亿元
{输入文本}请按照上述示例,从以下文本中提取关键实体及其属性信息,并按示例格式输出。{INPUT_TEXT}
2.3.2 关系信息抽取的提示示例
{需求提示}你是一名自然灾害信息抽取专家,现提供文本及其对应实体,你的任务是依据文本提取出实体关系。给定的实体包括:灾害类型、发生时间、发生地点、灾害影响、救援措施、负责机构等。请输出实体之间的关系,如“灾害类型-发生时间”“灾害类型-发生地点”“灾害类型-灾害影响”“灾害类型-救援措施”“负责机构-救援措施”等。输出格式为:“关系类型:实体1-实体2”。
{领域知识提示}以下文本涉及自然灾害事件的报道或研究,重点在于描述灾害的基本信息及其影响。需要提取的实体和属性包括但不限于:灾害类型(如地震、飓风)、灾害名称、发生时间(具体日期或时间段)、发生地点(城市、国家或区域)、灾害影响(引发次生灾害、直接受影响或被疏散的人数、死亡人数、经济损失等),以及救援措施(如政府或组织采取的行动)和负责机构。请注意,某些术语在灾害领域有特定含义,如“风速”常与台风、飓风相关联,“风眼”指台风的中心区域等。
{少样本提示}文本:“2023年7月,京津冀首都圈海河流域发生特大暴雨,引发严重的洪涝和地质灾害,造成550万余人受灾,上百人遇难失踪,直接经济损失超过1600亿元。\"
输出示例:
-灾害类型:暴雨-发生时间:2023年7月-发生地点:京津冀首都圈海河流域-灾害影响:洪涝、地质灾害,550万余人受灾,上百人遇难失踪,经济损失超过1600亿元{输入文本}请按照上述示例,从以下文本中提取关键实体及其属性信息,并按示例格式输出。{INPUT_TEXT}
2.4知识融合与知识加工
知识融合与知识加工是指在知识图谱构建过程中,对新获取的知识进行整合,以消除矛盾和歧义的过程。本文通过对所提取的相同类别实体和对应的实体属性数据进行相似度计算,再通过调整语义相似度阈值,实现对实体间语义相似度低于阈值的实体,及其属性数据进行标准语义替换,完成知识融合。最后,利用文本匹配进行知识加工,从而形成大规模的知识体系。
依靠模式层框架,经过知识融合和加工后的实体及其实体属性数据与概念层中的实体和实体属性一一对应,完成实体与属性的匹配,最终形成完整的知识图谱。
3 台风灾害应急预警实例分析
3.1 台风灾害应急图谱构建
在台风灾害管理过程中,知识图谱的典型应用包括面向台风路径预测、灾害影响范围与强度分析、应急资源调配等应急任务。通过整合历史台风数据、气象观测数据和地理信息,台风灾害应急知识图谱能够有效支持台风路径的预测和模拟,帮助识别可能受灾的地区,并评估台风可能造成的破坏程度。此外,台风灾害应急知识图谱还能够辅助应急管理部门快速调配救援物资和人员,优化应急响应决策,提高应对台风灾害的效率和准确性。
按本文所述的知识图谱构建方法,首先需构建台风灾害应急知识图谱的模式层,确立台风灾害事件、灾害应急任务、灾害数据、模型方法这四类本体,并对本体概念层次关系、本体属性关系以及概念间的语义关系进行定义。模式层的构建情况如图2所示。
随后进行台风灾害知识图谱数据层构建,在模式层的指导下,从台风灾害相关文本数据中,利用经过台风灾害知识样本学习后的大语言模型GPT-4,以输入提示句的方式将台风灾害相关实体及关系进行抽取。知识抽取完成后,从这些台风灾害文本数据中获取到6个台风灾害评估模型、灾害数据实体50个、模型方法实体共3568个,经知识融合后所得实体共2520个,台风灾害知识图谱节点及关系的数量统计如表2所示,构建好的部分台风灾害应急知识图谱数据层如图3所示。
 表2台风灾害知识图谱节点及关系的数量统计表
表2台风灾害知识图谱节点及关系的数量统计表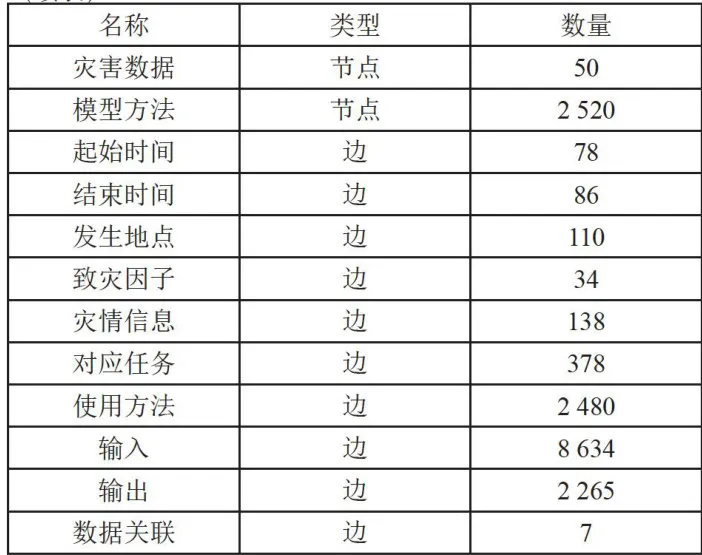 (续表)
(续表)3.2 知识图谱可视化应用
3.2.1 可视化分析
本文结合相关应急预案及各种数据,采用基于正则匹配、基于分布提示的大语言模型等多种方式进行知识抽取,再通过知识融合与加工构建出关于自然灾害应急的知识图谱。并将此知识图谱存入Neo4j图数据库中,从而能够更加直观地看到各种数据之间的关系。
3.2.2 数据查询
Python中存在Py2neo库,可实现利用Python对Neo4j图数据库进行操控。由于Python语言简单易学,使得不熟悉Cypher查询语言的人也能熟练操纵图数据库。因此,本文在图数据库中进行数据查询时,利用Py2neo库事先将数据查询通用模板语句写好,随后通过输入所需关键字,实现在Neo4j中进行数据查询。
3.2.3 应急预案智能问答
在自然灾害应急预案问答系统中,基于构建好的知识图谱模型,设计问答系统的模型,包括自然语言理解模块、问题匹配模块、知识检索模块、答案生成模块以及问答历史查询模块等。其中,自然语言理解模块用于将用户提出的自然语言问题转换成可理解的结构化查询语言;问题匹配模块用于将用户问题与知识图谱中的问题进行匹配,找到相关知识;知识检索模块用于从知识图谱中检索出与问题相关的知识;答案生成模块用于根据检索到的知识生成回答;问答历史查询模块方便用户翻看历史查询记录,并根据用户查询关键字生成问答标签库。
本文采用自然语义处理包(NLTK)、深度学习框架(PyTorch)实现智能问答模块设计。考虑到Python具有丰富的第三方库,能更容易实现智能问答,并且Python的Web框架Django提供了丰富的内置功能,能高效实现数据管理、用户请求处理等功能,故采用Python的Web框架Django作为后端服务,处理业务逻辑,负责自然语言理解、知识检索、答案生成等功能。其中,自然语言理解是基于语言模型处理用户的自然语言输入,将用户的问题解析为知识图谱中的实体和关系,系统在知识图谱中找到与用户问题相关的节点和关系,使用相似度计算等技术匹配用户问题与知识图谱中的预案信息,使系统能够自动识别用户的问答意图;知识检索是Django后端调用图数据库获取与用户问题相关的知识节点实现的;答案生成是在检索到相关知识后,系统将数据转化为自然语言回答。对于简单的问答,系统直接从知识图谱提取相关信息;对于复杂的问答需求,可以使用语言模型进一步优化答案生成,使回答更加连贯自然。
在问答页面设计方面,为满足一次开发、多端部署,支持微信小程序、H5、安卓和iOS等多平台,并能与后端的API无缝对接,快速获取和展示Django后端的数据的需求,采用uni-APP框架实现问答界面设计,负责与用户交互,实现问题输入、答案展示和问答历史管理。其中,在问题输入与答案展示方面,uni-APP提供的用户输入界面支持多种输入方式,如语音、文字等,让用户能够方便地提出问题;回答展示界面则根据问题类别动态调整展示形式,如文字展示、图片展示等。问答历史查询与管理通过每次用户的问答请求与响应结果都存储在后端数据库中,用户可通过前端查着并检索历史记录来实现。智能问答系统流程图如图4所示。
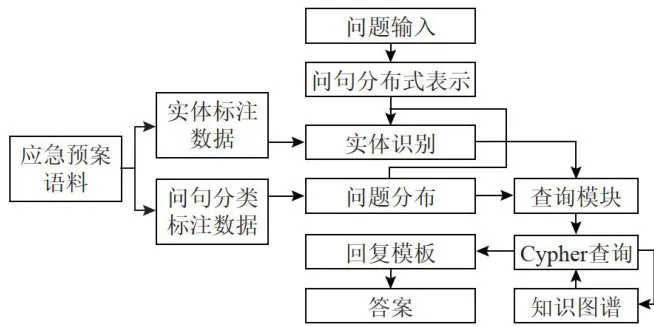 图4智能问答系统流程图
图4智能问答系统流程图4结论
为解决自然灾害应急领域中数据庞杂、关键知识匮乏的现状,同时为解决传统人工标注和深度学习方式进行知识抽取需要具备广泛的领域知识和信息处理能力,且数据标注工作烦琐这一构建过程中的难题,本文构建了基于大语言模型的自然灾害应急预案知识图谱,并利用上述知识图谱、Django框架和uni-APP框架构建出一套基于知识图谱的应急预案问答系统,实现了自然语言理解、问题匹配、知识检索、答案生成、问答历史查询等功能。
本文在知识图谱概念层设计上较为简易,后续将对概念层进行进一步细分,进而使数据展示显得更加直观。在数据方面,由于目前尚处于初步探索阶段,所收集的数据量终究有限,后续也将进一步寻找更多数据,对知识图谱做进一步完善。随着大语言模型的兴起,将大语言模型与知识图谱相结合也将成为未来研究的一个崭新方向。
参考文献:
[1]贺海霞,刘涛,杜萍.地震灾害应急管理知识图谱构建研究[J].兰州交通大学学报,2023,42(3):113-123.
[2]李泽荃,徐淑华,李碧霄,等.基于知识图谱的灾害场景信息融合技术[J].华北科技学院学报,2019,16(2):1-5.
[3]YANYC,LIULH,BANYK,etal.DynamicKnowledge Graph Alignment [EB/OL].[2024-09-2].file:///C:/Users/wy/Downloads/16585-Article%20Text-20079-1-2-20210518.pdf.
[4]ZHUYQ,WANGXH,CHENJ,etal.LlmsforKnowledge Graph Constructionand Reasoning:RecentCapabilities and Future Opportunities[J].World Wide Web,2024,27(5):58-58.
[5]ZHANGBW,SOHH.Extract,Define,Canonicalize:AnLLm-Based Framework forKnowledge Graph Construction[JOL].arXiv:2404.03868v1 [cs.CL].[2024-09-28].https://arxiv.org/html/2404.03868v1.
[6]BROWNTB,MANNB,RYDERN,et al.LanguageModelsare Few-ShotLearners[J/OL].arXiv:2005.14165[cs.CL].[2024-09-28].https://arxiv.org/abs/2005.14165?context=cs.
[7]ZHANGJY,ZHANGZX,ZHANGHH,etal.FromElectronic HealthRecordsto TerminologyBase:ANovelKnowledge Base EnrichmentApproach[J].Journal of BiomedicalInformatics,2021,113:103628.
[8] ZIAULLAH AW,OFLIF,IMRAN M.MonitoringCritical Infrastructure Facilities During DisastersUsing Large LanguageModels[J/OL].arXiv:2404.14432[cs.SI].[2024-09-28]. https://arxiv.org/abs/2404.14432?context=cs.CL.
[9]LIUYC,KUO CL.Constructing Spatio-temporal DisasterKnowledge Graph from Social Media[J].AGILE: GIScienceSeries,2024,5:37.
[10]王喆,陆俊燃,杨栋梁,等.融合GPT和知识图谱的洪涝应急决策智能问答系统研究[J].中国安全生产科学技术,2024,20(4):5-11.
[11]OPENAI,ACHIAMJ,ADLERS,etal.Gpt-4 TechnicalReport [J/OL].arXiv:2303.08774[cs.CL].[2024-09-28]. https://arxiv.org/abs/2303.08774?utm_source=chatgpt.com.
作者简介:徐欢(2004—),男,汉族,浙江杭州人,本科在读,研究方向:大语言模型的知识图谱构建与增强技术;吴梦飞(1995一),女,汉族,浙江湖州人,讲师,工学硕士,研究方向:自然语言处理;孙文学(1989一),男,汉族,山东济宁人,讲师,工学硕士,研究方向:智能计算、深度学习。