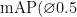
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)07-0071-06
Abstract: This paper proposes an abnormal behavior detection algorithm based on the improved YOLOv5-pose in complexscenes.ItusesFPTtoreplacetheFPN+PANmodule,enablingthefeaturemapstoachieve globalandlocalinteraction acrossscales and spaces,and improving the accuracyofjoint point detection.Inthe Neck module,askipconnection structure is employedto efectively fusethe information ofthe input featuresand the multi-scale features output through the network, improvingtheabilitytocapturedetailed informationandenancing theauracyofdetectingoluded jointpoints.Experimental results show that the improved algorithm achieves an average accuracy of 9 9 . 5 % on the CrowdPose dataset,which is 2 . 4 % higher thanthatoftheoriginalmodel.Theimprovedmodelnotonlyhashigherdetectionaccuracybutalsosignificantlyimprovesthe recognition performance of small targets.
Keywords: YOLOv5-pose; behavior recognition; joint point detection; FPT; skip connection
0 引言
在城市人员复杂、社会安全风险高的重点场所,极易发生群体冲突、极端暴力等社会安全突发事件,加剧民众的心理恐慌,严重影响到社会稳定。传统的异常行为检测方法主要依赖人工监控或构建人体模型来检测。这些方法由于需要大量的计算和人工干预,暴露出明显的局限性。随着神经网络与深度学习的不断技术的发展,基于卷积神经网络(CNN)的方法逐渐成为异常行为检测的主流技术。2019年,黄泽等人[1]针对多目标人体的定位精度不够精确该问题,采用SSD算法进行关节点检测,并引入强化学习马尔科夫决策模型对九种人体行为进行训练,最后使得检测框更能达到贴近人体的效果。Cheng等人[2针对小尺度行为检测困难问题,提出了一种高分辨率特征金字塔学习尺度感知模型,实现了在处理小个体行为检测时更精确的关键点定位。2021年,石跃祥等人[针对图像中由于人数不确定对处理速度的影响问题,提出一种改进的DenseNet算法模型用于人体行为估计.该模型利用自底向上的方式对人体行为特征进行提取,从而提高多人行为估计的网络速度。2022年,Ke等人[提出一种端到端的多人检测和行为估计框架,该模型使用多尺度监督和多尺度回归来同时加强上下文特征的学习,并运用结构感知损失和关键点掩蔽来进一步提高行为细化的鲁棒性。该模型可以提高大多数现有的自上而下的行为估计方法的精度。2023年,朱丽萍等人[5针对运动场景下人体行为估计问题做出研究,并结合注意力机制和多尺度模型提出了一种多目标行为估计算法。2024年,Chen等人[将目前最先进的关节点检测算法Openpose与深度学习技术相结合,利用Openpose提供的关节点热力图与匈牙利算法进行目标匹配,最终能够更加精确的检测出目标的行为。但该模型实时性不高。侯裕迪等人[7提出了一种基于改进的YOLOv5s算法打斗行为检测模型,该算法使用MobileNetv3来代替YOLOv5s模型的骨干网络,使网络更加轻量化,减少了YOLOv5s计算量,从而提高模型检测速度,但这种检测算法在人员密集的场所,很难正确匹配到关节点。并且由于特征层数提取较浅所以对小关节点检测的准确率不高。针对以上问题,本文提出了一种基于复杂场景下改进的YOLOv5-pose人体异常行为检测模型。
1 Y0L0v5-pose
1. 1 YOL0v5-pose
YOLOv5-pose是一种无Heatmap联合检测模型,该模型是基于YOLOv5关节点检测框架进行关节检测和图像中的2D多人行为估计。相比于传统基于Heatmap 的二阶段关节点检测模型,YOLOv5-pose模型的优势在于能够端到端训练,并可以直接优化OKS指标。该模型可以在一次前向传播过程中同时检测多个目标的边界框和对应的2D行为,从而结合了自上而下和自下而上的方法的优点,达到最佳的检测效果。
YOLOv5-pose网络结构如图1所示,该模型主要由:输入端网络(input)、主干网络(Backbone)、颈部网络(Neck)、和预测网络(Prediction)四大部分所组成。input负责图像的输入;Backone部分主要由Focus模块、CSP模块、SPP模块组成,负责将输入的图像进行特征提取;Neck部分由FPN和PAN两个模块组成,负责特征融合;Prediction部分负责人体和关节点的预测。
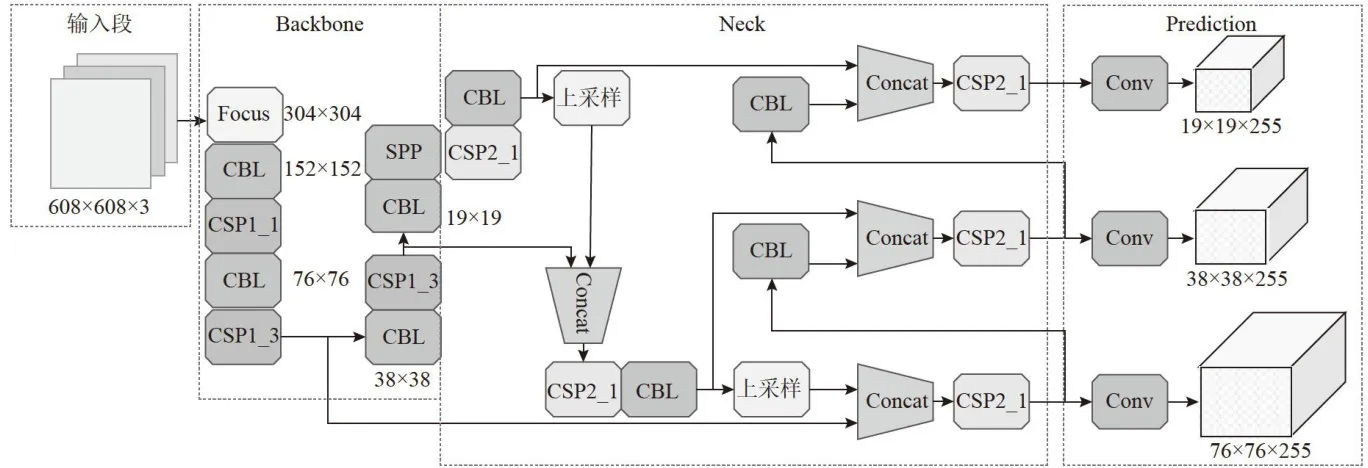 图1YOL0v5-pose网络结构
图1YOL0v5-pose网络结构1.2 F P N + P A N 模块
FPN模块又称特征金字塔模块,该结构通过自顶向下的下采样方式传递高层语义特征,在使用横向连接和自顶向下连接,有效的提取输入图像中的多维特征,从而增强网络的语义信息。PAN模块又名路径聚合模块,该模块是FPN之后的又一种由底往上的特征金字塔,可以用来把FPN系统所提供的特征图像定向传输,得到不同维度的特征图像,从而增强了系统获取的定位信息,缩短底层的特征信息与高层的特征信息之间的关联路径。在Neck中,FPN+PAN模块将原本在PANet中使用的加法操作连接替换为拼接操作连接,提升网络特征融合的能力。FPN+PAN模块结构如图2所示。
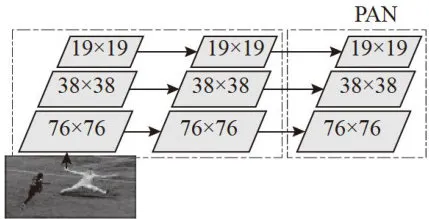 图2FPN+PAN结构
图2FPN+PAN结构2 改进的YOL0v5-pose模型
2.1 改进的FPT模块
F P N + P A N 模块能够结合不同尺度的语义特征和位置信息提升网络的特征融合的能力,但在复杂场景下、多人时,人体关节点局部被遮挡无法精确检测,因此本文将FPN+PAN模块替换为检测效果更好的FPT模块,该模块引入了自注意力机制的思想,利用Non-local结构和自注意力机制,使得特征图能够在跨空间和跨尺度上进行相比于FPN+PAN模块更有效的非局部交互,提高检测准确率。
FPT模块由ST、GT、RT三个部分组成,并通过Non-local结构[1]把这三部分连接起来。Non-local结构的网络运作原理就是把输入的特征图先经过三个 1 × 1 × 1 的卷积网络进行降维,此时特征图的尺度减小为原来的一半,接着将特征矩阵逐级与 1 × 1 × 1 的卷积网络进行拼接操作,又得到与原来尺度一致的特征图,最后将该特征图与输入时的特征图进行加法操作,得到完整的特征图输出。Non-local结构如图3所示。ST模块是用来捕获特征图上共现的目标特征,该模块通过相似度和归一化计算来分配每个像素块的权重值,权重越大代表该像素块的值越接近目标特征。GT模块是自上而下的跨尺度特征交互模块,该模块通过欧氏距离相似度计算,将局部与大尺度像似小尺度的特征图的语义信息与大尺度的特征图的语义信息相融合,实现跨尺度信息交互;RT模块刚好相反是自下而上特征交互模块,该模块运用全局平均池化计算,将大尺度的特征信息传递给小尺度并通过加法操作将特征融合到一起,从而得到最终的特征图。
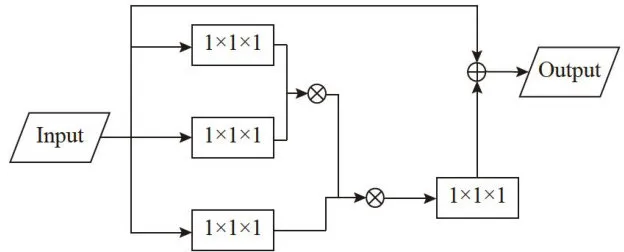 图3Non-local结构
图3Non-local结构2.2 跳跃连接结构
跳跃连接结构[又称为残差连接,其是神经网络重要的组成结构之一。它的基本思想是在网络连接中,可以将输入和输出直接通过加法操作连接起来,并允许在不同层次间进行有间隔的连接。这种连接可以有效解决由于网络层数增加而梯度消失导致训练困难的问题。
本文在Neck模块中结合跳跃连接结构,将Neck结构的输入端与输出端直接通过加法操作进行连接,实现将通过FPT结构、卷积网络和Up-sample处理后的多尺度特征信息与输入特征信息相结合。从而能够更好地关注到底层特征的信息表达,增加对特征细节的描述,提高对遮挡目标或小关节点检测的准确性。结合跳跃连接结构的Neck模块如图4所示。
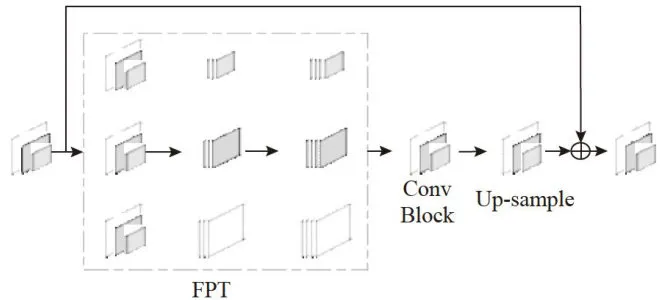 图4结合跳跃连接结构后的Neck模块
图4结合跳跃连接结构后的Neck模块2.3改进的Y0L0v5-pose模型总体结构
改进后的YOLOv5-pose模型的总体网络结构如图5所示,其中双箭头代表跳跃连接结构。本文将原YOLOv5-pose网络中的FPN+PAN模型替换为FPT模型,并在Neck中添加了跳跃连接结构。改进后的YOLOv5-pose模型通过使用标记好的数据进行训练和测试,在检测过程中,输入图像经过网络处理后会输出三种不同尺度的特征图,再经过卷积和后处理生成最终的检测结果。实验结果表明,改进后的YOLOv5-pose 模型相比于原YOLOv5-pose模型在复杂场景下有效地提高行为估计的精确率。
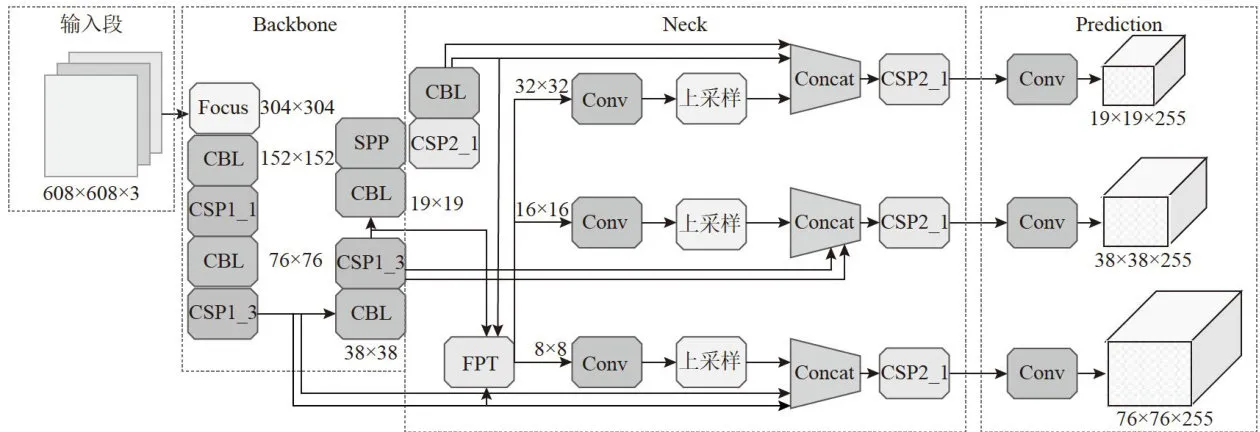 图5改进后的YOL0v5-pose模型的总体网络结构
图5改进后的YOL0v5-pose模型的总体网络结构3 实验与分析
3.1 实验数据与环境
本文数据集CrowdPose[12]是一个用于多人行为估计的数据集,专门用于处理拥挤场景下的行为估计问题。该数据集包含了在各种复杂场景中拍摄的图片,其中多人重叠、遮挡等现象非常普遍。数据集包含大约8000张图片。这些图片中共标注了大约200000个关键点,涵盖了多种行为和场景。每张图片中的人物都进行了详细的关键点标注。除了关键点标注,每张图片还提供了边界框(boundingbox)来标定每个人的大致位置。该数据集可以用于训练和评估基于深度学习的行为估计模型,帮助模型更好地处理复杂场景下的遮挡问题。
本文的实验以Windows11操作系统为实验环境,配备了IntelCorei5-13400FCPU,并采用NVIDIA
GTX4060Ti显卡进行高性能运算。开发环境的具体配置包括CUDA版本12.0,PyTorch版本2.1.1,以及Python语言环境3.8.7。为了确保模型训练的有效性,初始学习率被设置为0.01,并且整个训练过程将进行200轮迭代。
3.2 评价指标
为了评估本文提出的改进的YOLOv5-pose模型在复杂场景下估计人体行为的有效性,本文采用以下指标衡量模型性能:
1)准确率 ( P ) 。准确率(Precision)是评估分类模型性能的关键指标之一,用于衡量模型正确预测的样本数量占总样本数量的比例。准确率的计算公式为:
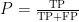
其中:TP(TruePositives)表示真正例的数量,即实际为正类且被模型正确预测为正类的样本数;FP(FalsePositives)表示假正例的数量,即实际为负类但被模型错误地预测为正类的样本数。
2)召回率 ( R ) 。召回率(Recall)也是评估分类模型性能的关键指标之一。它衡量了实际为正例的样本中,被正确预测为正例的比例。召回率的计算公式为:
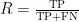
其中:FN(FalseNegatives)表示假负例的数量,即实际为正类但被模型错误地预测为负类的样本数。
3) mAP@0.5。 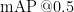 全称为 mean AveragePrecision at
全称为 mean AveragePrecision at 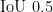 ,即在交并比(Intersection overUnion,IoU)为0.5时的平均精度。
,即在交并比(Intersection overUnion,IoU)为0.5时的平均精度。
4)GFLOPs。GFLOPs用来衡量神经网络模型的计算速度和能力。较高的GFLOPs值通常意味着模型能够更快地处理数据,在训练和推理任务中更高效。
3.3 实验结果与分析
3.3.1 消融实验
为了验证本文所提出的一种基于复杂环境下改进的YOLOv5-pose模型的有效性,本文对模型进行消融实验。以YOLOv5-pose作为基线模型,在分别只改变一个变量的情况下分别作出对比,消融实验对比结果如表1所示。其中,FTP和跳跃连接分别表示本文提出的两种改进方法(“x”表示未采用该改进方法,“√”表示采用该改进方法)。
 表1消融实验
表1消融实验
通过表1可以看出,改进后的YOLOv5-pose模型准去率、召回率、 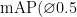 、GFLOPs分别达到了 9 8 . 6 % 、 9 9 . 5 % 、 9 9 . 5 % 、15.8,相比于原模型分别提升了 2 . 5 % 、 1 . 0 % 、 2 . 4 % 、1.2。但参数量只有3.62MB,相对于原模型增加 0 . 1 M B ,这说明改进后的YOLOv5-pose模型在只增加少量网络参数的情况下,能够有效提高网络的检测精确度。模型2中,使用FTP代替原网络中的FPN+PAN模块,此时准确率达到了 9 7 . 4 % 、召回率达到了 9 9 . 0 % ,
、GFLOPs分别达到了 9 8 . 6 % 、 9 9 . 5 % 、 9 9 . 5 % 、15.8,相比于原模型分别提升了 2 . 5 % 、 1 . 0 % 、 2 . 4 % 、1.2。但参数量只有3.62MB,相对于原模型增加 0 . 1 M B ,这说明改进后的YOLOv5-pose模型在只增加少量网络参数的情况下,能够有效提高网络的检测精确度。模型2中,使用FTP代替原网络中的FPN+PAN模块,此时准确率达到了 9 7 . 4 % 、召回率达到了 9 9 . 0 % , 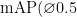 达到了 9 8 . 3 % ,相比于原模型分别提升了 1 . 3 % , 0 . 5 % , 1 . 2 % 这说明FTP模块能够比 F P N + P A N 模块更好地实现特征融合,有效提高关节点的检测精确度。模型3中,在使用跳跃结构连接Nack的输入输出,此时准确率达到了 9 8 . 0 % 、召回率达到了 9 9 . 2 % ,
达到了 9 8 . 3 % ,相比于原模型分别提升了 1 . 3 % , 0 . 5 % , 1 . 2 % 这说明FTP模块能够比 F P N + P A N 模块更好地实现特征融合,有效提高关节点的检测精确度。模型3中,在使用跳跃结构连接Nack的输入输出,此时准确率达到了 9 8 . 0 % 、召回率达到了 9 9 . 2 % , 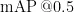 达到了 9 8 . 9 % ,相比于原模型分别提升了 1 . 9 % , 0 . 7 % 、1 . 8 % ,这说明跳跃结构连接,能够更好地关注到底层特征的信息表达,增加对特征细节的描述,提高对关节点检测的准确性。
达到了 9 8 . 9 % ,相比于原模型分别提升了 1 . 9 % , 0 . 7 % 、1 . 8 % ,这说明跳跃结构连接,能够更好地关注到底层特征的信息表达,增加对特征细节的描述,提高对关节点检测的准确性。
3.3.2对比实验结果
分别将改进后YOLOv5-pose模型与原YOLOv5-pose模型在上节所述的数据集上进行训练,并与目前主流的异常行为检测算法进行对比。评价指标选用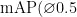 和FPS两个指标,其中mAP评价模型在数据集上检测的精度,FPS评价模型在数据集上检测的速度。FPS值越大,代表模型检测的速度越快。检测结果如表2所示。
和FPS两个指标,其中mAP评价模型在数据集上检测的精度,FPS评价模型在数据集上检测的速度。FPS值越大,代表模型检测的速度越快。检测结果如表2所示。
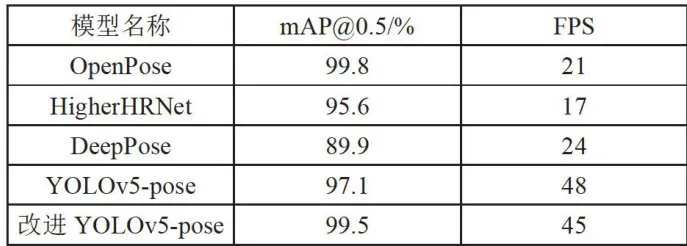 表2不同模型检测结果
表2不同模型检测结果通过表2的数据可以看出本文所提出的一种基于复杂环境下改进的YOLOv5-pose模型,相对于目前主流的Openpose模型虽然平均精度下降了0 . 3 % ,但是FPS提高了23,这说明本文的算法相对于Openpose模型虽然检测的精度略有下降,但是检测的速度大幅度提高,更能达到实际生活中对复杂场景下异常行为检测的实时性的要求。本文所提出的YOLOv5-pose模型相对于HigherHRNet的平均准确度提升了 2 . 9 % ,FPS 提高了 23 % ;相对于Deeppose的平均准确度提升了 9 . 6 % ,FPS提高了 21 % ,这说明本文所提出的模型相对于主流模型,能够有效提高检测精度和检测速度,能够满足现实场景中对模型检测精确度和检测速度的要求。
分别将改进后的YOLOv5-pose模型与原YOLOv5-pose模型在异常行为(摔倒、扭打、追逐)与非异常行为(站立、蹲、坐)六种行为下进行分类测试,测试结果如表3所示。
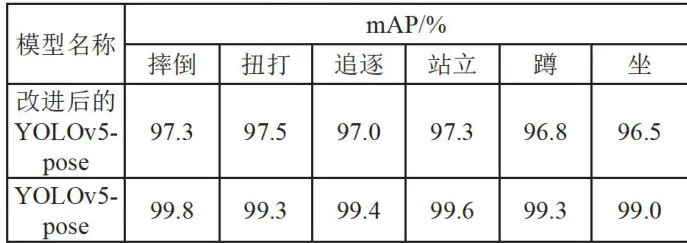 表3分类测试
表3分类测试通过表3的数据可以看出本文所提出的一种基于复杂环境下改进的YOLOv5-pose模型,在摔倒行为下的平均准确率最高能够达到 9 9 . 7 % ,这是因为摔倒行为相比于其他模型特征较为明显,所以检测精确度相比于其他行为检测精度高,在扭打行为下的平均准确率达到 9 9 . 3 % 这是因为扭打行为是两人或多人在一起,所以检测精度略有下降。蹲行为下的平均准确率达到 9 9 . 3 % ,坐行为下的平均准确率达到 9 9 . 0 % 这是因为蹲行为和坐行为的特征较为相像,模型检测时较为难区分;在追逐和站立时的平均准确率分别达到9 9 . 4 % 和 9 9 . 6 % ,检测效果较好。
3.3.3 效果展示
为了验证改进后的模型的可行性,本文对改进的YOLOv5-pose模型分别对复杂公众场景下的异常行为(摔倒、扭打、追逐)与非异常行为(站立、蹲、坐)六种行为进行可行性验证。图6为分别为异常行为(摔倒、扭打、追逐)与非异常行为(站立、蹲、坐)六种行为原始图,图7分别为异常行为(摔倒、扭打、追逐)与非异常行为(站立、蹲、坐)六种行为在经过改进的YOLOv5-pose模型检测过后的图像。其中fall标签表示摔倒、fight标签表示扭打、run标签表示追逐、stand标签表示站立、squat标签表示蹲、sit标签表示坐,边框上的数值表示置信度,表示预测为真的概率。
 图6原始图像
图6原始图像 图7改进后的YOL0v5-pose模型检测后的图像
图7改进后的YOL0v5-pose模型检测后的图像如图7所示,改进后的YOLOv5-pose模型在对复杂公众场景下对摔倒、扭打、追逐站立、蹲、坐六种行为进行检测中,其中对摔倒行为检测的置信度为0.95,对扭打行为检测的置信度为0.92,对追逐行为检测的最高置信度为0.69,对站立行为检测的置信度为0.95,对蹲行为检测的置信度为0.90,对坐行为检测的置信度为0.79;这表示改进后的YOLOv5-pose模型在复杂场景下对行为的检测有较好的检测效果,并且在目标有遮挡的情况下和目标较小的情况下改进后的YOLOv5-pose模型都能精确的检测得到。这表明本文所提出的改进后的YOLOv5-pose模型在复杂公共场景下对异常行为(摔倒、扭打、追逐)与非异常行为(站立、蹲、坐)六种行为检测具有较高的可行性。
4结论
本文提出的基于改进YOLOv5-pose的异常行为检测算法,通过引入FPT模块和跳跃连接结构,显著提升了特征图的跨空间和跨尺度非局部交互能力,以及对细节和遮挡目标的检测精度。实验结果表明,该算法在CrowdPose数据集上的检测精度达到了7 4 . 5 % ,相比原模型提高了 3 . 3 % ,且在小目标识别效果上有显著增强。改进后的网络不仅在检测精度上有所提升,还能更有效地应用于多人人体行为检测,为复杂场景下异常行为的精确检测提供了强有力的技术支持,具有重要的社会安全应用价值。
参考文献:
[1]黄铎,应娜,蔡哲栋.基于强化学习的多人姿态检测算法优化[J].计算机应用与软件,2019,36(4):186-191.
[2]CHENGB,XIAOB,WANGJ,etal.HigherHRNet:Scale-Aware Representation Learning for Bottom-Up Human PoseEstimation[C]//Proceedingsof theIEEE/CVFConferenceonComputer Vision and Pattern Recognition.Seattle:IEEE,2020:5386-5395.
[3]石跃祥,许湘麒.基于改进DenseNet网络的人体姿态估计[J].控制与决策,2021,36(5):1206-1212.
[4]KEL,CHANGMC,QIH,etal.DetPoseNet:Improving Multi-Person Pose Estimation via Coarse-Pose Filtering[J].IEEE Transactions on Image Processing,2022,31:2782-2795.
[5]朱丽萍,唐亮,朱凯杰,等.运动场景下的多目标人体行为估计[J].计算机工程与设计,2023,44(7):2156-2162.
[6]CHENY,ZHANGJ,WANGY.Human ActionRecognition and Analysis Methods Based on OpenPose and DeepLearning[C]//2024 International Conference on Integrated Circuitsand Communication Systems (ICICACS).Raichur:IEEE,2024:1-5.
[7]侯裕迪,杨洪臣,蔡能斌基干改讲YOIOv5s的视频中打斗行为检测模型[J/OL].刑事技术,2024:1-7[2024-10-26].https://doi.0rg/10.16467/j.1008-3650.2024.0043.
[8]MAJID,NAGORIS,MATHEWM,etal.YOLOPose:Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss [C]//Proceedings of the IEEE/ CVF Conference on Computer Vision and Pattern Recognition. NewOrleans:IEEE,2022:2637-2646.
[9]ZHANGD,ZHANGHW,TANGJH,etal.FeaturePyramidTransformer[C]//Proceedingsof theEuropeanConferenceonComputerVision.Glasgow:Springer,2020:323-339.
[10]WANGXL,GIRSHICKR,GUPTAA,etal.NonLocalNeuralNetworks[C]//2018IEEE/CVFConferenceon Computer Vision and Pattern Recognition.Salt Lake City: IEEE,2018:7794-7803.
[11]王林,李聪会.基于多级注意力跳跃连接网络的行人属性识别[J].计算机工程,2021,47(2):314-320.
[12]LIJF,WANGC,ZHUH,etal.CrowdPose: EfficientCrowdedScenesPoseEstimationandaNewBenchmark [C]/Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019: 10863-10872.
作者简介:崔悦(1998一),女,满族,辽宁本溪人,助教,硕士,研究方向:图像处理、大数据与智能信息处理;杨旺(1995一),男,汉族,甘肃武威人,助教,硕士,研究方向:计算机视觉、智能机械与机器人。