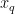
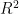
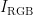
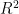
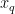
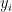
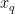
关键词:颜色分布;烟碱预测;回归模型; 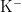 近邻;无损检测中图分类号:TP391.4;TP181 文献标识码:A 文章编号:2096-4706(2025)08-0132-07
近邻;无损检测中图分类号:TP391.4;TP181 文献标识码:A 文章编号:2096-4706(2025)08-0132-07
Abstract: This paper uses optical imaging technology to establish an image dataset of abatch oftobacco leaves with knownnicotinecontent,anduses theneuralnetworkmodelU2-Nettoaccuratelydetecttobaccoleaftargets.Byextractingthe color distributioninformationofthetobaccoleaf targets,four typicalMachineLeamingalgorithmsofRF,XGBoost,MP,and KNNareusedtomaketheregressonpredictionforthenicotinecontentof tobacco leaves,respectively.Theresults indicate that theKNNmodelcanefectivelyutilizecolordistributioninformationtoaccuratelypredictthenicotinecontentoftbaccoleaves. The value of determination coefficient 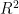 is as high as 9 7 . 4 6 % ,theMSE isaslow as O.020 2,and the MAE is as low as 0.075 6,indicatingasigncantcorelationbetweentobaccoleafcolordistributioniformationandnicotinecontent,andprovidingan effective nondestructive detection method for nicotine.
is as high as 9 7 . 4 6 % ,theMSE isaslow as O.020 2,and the MAE is as low as 0.075 6,indicatingasigncantcorelationbetweentobaccoleafcolordistributioniformationandnicotinecontent,andprovidingan effective nondestructive detection method for nicotine.
Keywords: color distribution; nicotine prediction;regressionmodel; K-Nearest Neighbor;nondestructive testing
0 引言
烟草作为一种重要的农作物,广泛应用于烟草制品的生产,对于全球经济和人们的日常生活有着重要的影响。在烟草生产和加工过程中,由于烟叶颜色影响到烟叶的外观品质和市场价值,颜色性状是烟叶质量评估的重要外在依据。在烟叶质量评估中,内在的化学成分也起着至关重要的作用[。其中,烟碱含量作为烟叶中最重要的化学成分之一,对于烟草制品的口感和质量具有显著影响。
然而,传统的烟碱含量测量方法是通过常规化学法或高效液相色谱法等[2-3],这些方法虽然准确率较高,但却需要破坏性的化学分析,操作复杂且耗时费力。在近年的研究中,主要利用近红外成像技术来测量烟叶生化成分[4-5],例如潘威等人利用主成分回归法建立了烟草种子淀粉含量的近红外光谱定量分析模型,该模型的决定系数高达 9 9 . 8 0 % ,校正标准差和预测标准差分别低至0.1493和0.1838,误差较小且实验结果可靠[,李阳阳等近红外光谱快速测定卷烟烟气中烟碱,焦油和一氧化碳释放量[],比起传统测量方法有一定优势,但也有许多缺点,比如需要建立复杂的校正模型。近年来的近红外成像技术对样品的预处理和数据分析要求较高,对非烟物质的抗干扰能力较低,无法定量分析单一成分,只能给出整体成分的预测值等。实际生产中,迫切需要一种非破坏性且高效的方法来预测烟叶的烟碱含量,以提高烟叶质量评估的效率。
一些研究者发现农作物的颜色分布信息和成分有关,例如吴雪梅等通过分析嫩芽与老叶的G和G-B分量的颜色信息,利用颜色信息差异来有效区分嫩芽和背景,进而提出了茶叶嫩芽的识别算法[]。中国中医科学院中药研究所基于颜色-特征成分关联分析及网络药理学探讨金银花中潜在的质量标志物,为控制金银花的质量提供了依据[。更重要的是,烟叶的颜色分布特征可以反映烟叶部分化学成分和品质特征[10-12],因此,本文在稳定光源环境下使用电荷耦合器件(CCD)数码相机对一批已知烟碱含量的烟叶进行图像采集,通过分析烟叶图像中的颜色分布模式,分别使用随机森林(RandomForest,RF)、梯度提升(eXtremeGradientBoosting,XGBoost)、多层感知机(Multi-LayerPerceptron,MLP)和K-最近邻(K-NearestNeighbors,KNN)算法对烟叶烟碱含量进行预测[13-17],筛选出精准的预测模型,用于探索烟叶烟碱含量与颜色之间的关联性,为烟叶烟碱含量的无损检测提供了一种新的方法。
材料与方法
1.1 烟叶数据集的构建
本研究使用的烟叶样本源自云南省某烟叶公司,种植产地包括普洱、文山,在色泽程度上分为10个等级,在品质上分为6个等级,为了获得这些烟草样本的烟碱真实含量,实验室采用传统的气相色谱(GC)分析方法测定其烟碱成分百分比值[18],其步骤包括:从烟草样品中提取烟碱组分;采用有机溶剂甲醇对烟草样品进行浸提,得到含有烟碱的粗提取物;为了提高分析的准确性和重复性,采用固相萃取方法对提取物进行必要的纯化和浓缩;借助色谱柱对烟碱成分进行分离;借助氮磷检测器(NPD)对分离出的烟碱进行定量分析;根据预先建立的标准曲线,将检测到的烟碱峰面积或峰高与浓度进行对应,从而计算出样品中烟碱的含量百分比。最终得的烟碱含量数据如表1所示,表1中不同产地,不同等级的烟叶烟碱含量不同。
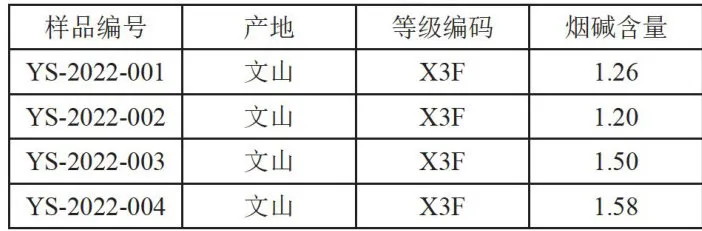 表1烟叶样品烟碱含量对应表
表1烟叶样品烟碱含量对应表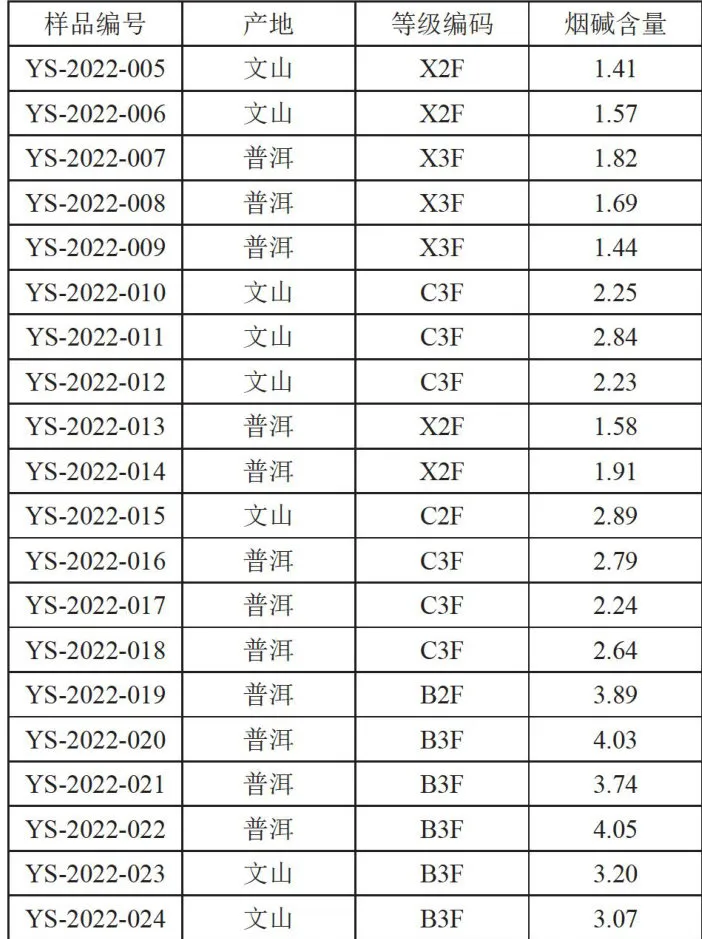 (续表)
(续表)鉴于在烟叶图像采集过程中,现场光照条件、灰尘等因素可能对图像质量产生不利影响,专门设计了一套拍摄灯箱系统,使用CanonEOS80D数码相机进行烟叶图像数据采集。为了保证图像数据的稳定性、可靠性和可辨识性,相机的参数手动固定设置如表2所示。
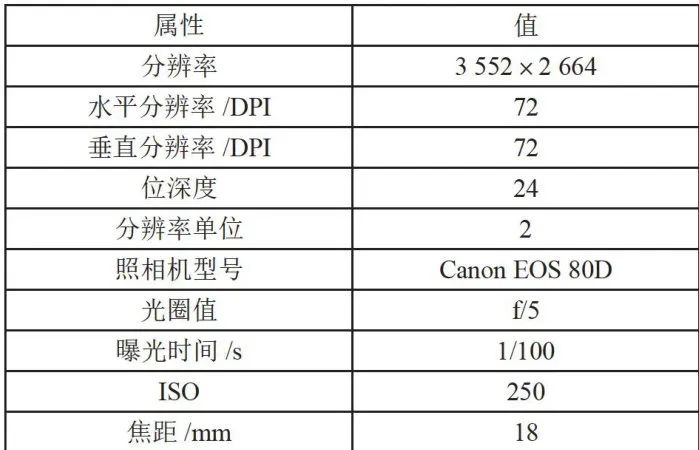 表2相机的参数
表2相机的参数将每片烟叶单独平铺放置于平台上,从三个角度和正反方向进行拍摄,对24种不同烟碱含量的烟叶样品采集了1728幅图像,构建了一个包含烟碱含量标签的“烟叶图像数据集”(下载地址:https://github.com/Ikaros-sc/tobacco-leaf),如图1所示。
 图1不同角度和方向的烟叶样品
图1不同角度和方向的烟叶样品1.2烟叶颜色分布信息提取
烟叶颜色分布信息的提取分为四个步骤:
1)对采集到的烟叶图像 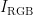 的3个 R , G , B 通道分别使用 1 1 × 1 1 中值滤波模板进行降噪处理。
的3个 R , G , B 通道分别使用 1 1 × 1 1 中值滤波模板进行降噪处理。
2)使用 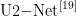 去除
去除 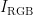 的背景,如图2(b)所示,获得烟叶目标图像。
的背景,如图2(b)所示,获得烟叶目标图像。
 图2盐业图像处理前后对比
图2盐业图像处理前后对比
3)为更好地捕捉烟叶色彩特征与烟碱含量之间的关系,需要将图像 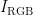 从RGB颜色空间转换到CIELAB颜色空间,得到
从RGB颜色空间转换到CIELAB颜色空间,得到 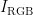 ,公式如下:
,公式如下:
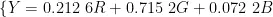
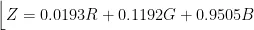
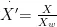
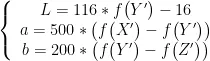
式中, R 、 G , B 为相机红、绿、蓝三通的响应归一化值; X , Y、 Z 为CIE三刺激值; 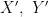
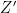 为对 X Y Z 值进行标准化和参考白点调整后的值;
为对 X Y Z 值进行标准化和参考白点调整后的值;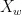 、
、 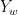 ,
, 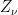 为D65标准观察条件下的白点的三刺激值; L 、a、 b 分别表示CIELAB颜色空间下的亮度、绿-红轴和蓝-黄轴的值,当
为D65标准观察条件下的白点的三刺激值; L 、a、 b 分别表示CIELAB颜色空间下的亮度、绿-红轴和蓝-黄轴的值,当 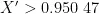 时,
时, 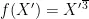 ,否则,
,否则, 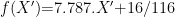 ,当
,当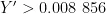 时,
时, 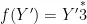 ,否则,
,否则, 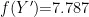 1
1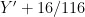 ,当
,当 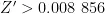 时,
时, 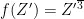 否则,
否则,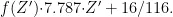 。CIELAB颜色空间是一种建立在非线性压缩坐标(如CIEXYZ色彩空间)和生理特性基础上的、与设备无关并且基于颜色对立的色彩系统,它能够运用数字化的方法描绘人类的视觉感知,并保证颜色计算的准确性。CIELAB因其出色的颜色恒定性可将光照条件的影响降到最低,是科学和工程领域最广泛使用的色彩系统。
。CIELAB颜色空间是一种建立在非线性压缩坐标(如CIEXYZ色彩空间)和生理特性基础上的、与设备无关并且基于颜色对立的色彩系统,它能够运用数字化的方法描绘人类的视觉感知,并保证颜色计算的准确性。CIELAB因其出色的颜色恒定性可将光照条件的影响降到最低,是科学和工程领域最广泛使用的色彩系统。
4)计算烟叶目标L,a, b 的直方图作为烟叶颜色分布信息:
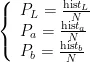
式中, 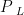 ,
, 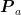 ,
, 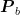 分别为 L , a ! b 在烟叶目标中出现的概率,
分别为 L , a ! b 在烟叶目标中出现的概率, 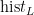 ,
, 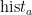 ,
, 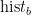 分别为烟叶目标区域 L 、a , b 值出现的次数, N 为烟叶目标区域的像素总量。
分别为烟叶目标区域 L 、a , b 值出现的次数, N 为烟叶目标区域的像素总量。
1.3烟叶烟碱含量预测模型
运用机器学习算法,根据已获取的烟叶样本特征数据作为输入变量,以及相应的烟碱含量数据作为目标变量,建立一个回归模型。在实验过程中,对不同的机器学习算法进行了初步的比较分析。最终,挑选出以下四个与本实验预测任务高度适配的模型,进行深入的训练和结果对比。
RandomForestRegressor,一种基于随机森林算法的回归模型,通过集成多个决策树来达成预测目标。其核心理念在于利用集成学习的方法优化预测性能。每个决策树的构建都基于随机选取的特征子集和样本子集,旨在增强模型的多样性和泛化能力。研究中,输入训练数据集 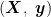 ,其中
,其中 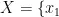 ,
,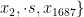 为 1 6 8 7 个烟叶样本的特征向量,
为 1 6 8 7 个烟叶样本的特征向量, 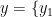
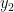 ,…,
,…, 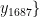 为对应的烟碱含量标签。从训练数据集中随机抽取一部分样本和特征,训练一棵决策树。重复这一过程多次,训练出多棵决策树。对于新的烟叶样本特征向量
为对应的烟碱含量标签。从训练数据集中随机抽取一部分样本和特征,训练一棵决策树。重复这一过程多次,训练出多棵决策树。对于新的烟叶样本特征向量 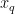 ,将其输入到训练好的多棵决策树中,每棵树都会给出一个预测结果
,将其输入到训练好的多棵决策树中,每棵树都会给出一个预测结果 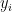 。最终的预测结果
。最终的预测结果 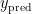 为这些预测结果
为这些预测结果 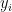 的平均值。
的平均值。
XGBRegressor是基于梯度提升算法的回归模型,它是XGBoost库中的一种实现。梯度提升通过迭代地添加弱学习器,每次迭代都在之前模型的残差上进行学习,逐步减小预测误差。研究中模型训练过程:给定训练数据集 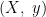 ,其中
,其中 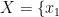
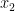 ,…,
,…, 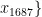 为1687个烟叶样本的特征向量,
为1687个烟叶样本的特征向量,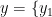 ,
, 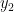 ,…,
,…, 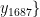 为对应的烟碱含量标签。XGBRegressor算法会通过以下步骤进行模型训练:初始化一棵决策树作为基模型;计算当前模型的预测误差,并使用梯度下降法优化模型参数,以最小化预测误差;重复上一步骤,添加新的决策树基模型,直到达到预设的迭代次数或性能指标收敛。经过这个训练过程,算法会学习到一个由多棵决策树组成的集成模型,用于捕捉输入特征与目标变量之间的复杂非线性关系。后期的回归过程:给定一个新的烟叶样本特征向量
为对应的烟碱含量标签。XGBRegressor算法会通过以下步骤进行模型训练:初始化一棵决策树作为基模型;计算当前模型的预测误差,并使用梯度下降法优化模型参数,以最小化预测误差;重复上一步骤,添加新的决策树基模型,直到达到预设的迭代次数或性能指标收敛。经过这个训练过程,算法会学习到一个由多棵决策树组成的集成模型,用于捕捉输入特征与目标变量之间的复杂非线性关系。后期的回归过程:给定一个新的烟叶样本特征向量 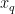 ,输入到训练好的XGBRegressor模型中。
,输入到训练好的XGBRegressor模型中。
模型会通过之前学习到的多棵决策树进行前向传播计算,得到最终的烟碱含量预测值ypredo
MLP是一种前馈神经网络模型,也是最早和最基本的人工神经网络架构之一。核心思想是通过构建具有多个隐藏层的神经网络模型,利用反向传播算法自动学习输入特征与目标变量之间的复杂映射关系,从而实现对新样本的准确预测。研究中的模型训练:输入数据集 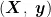 ,其中
,其中 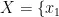 ,
, 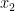 , ⋅ s ,
, ⋅ s , 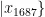 为1687个烟叶样本的特征向量,
为1687个烟叶样本的特征向量, 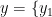 ,
, 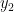 ,…,
,…,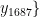 为对应的烟碱含量标签。将输入特征 X 和目标变量y划分为训练集和验证集。定义MLP模型结构,包括输入层、隐藏层和输出层。隐藏层可以使用多个全连接层,采用ReLU激活函数。输出层使用单个线性节点来预测烟碱含量。使用梯度下降法优化MLP模型参数,目标是最小化训练集上的均方误差损失函数。使用验证集评估模型性能,并根据验证集误差调整MLP的超参数以提高模型泛化能力。后期的回归过程:将新的烟叶样本特征向量
为对应的烟碱含量标签。将输入特征 X 和目标变量y划分为训练集和验证集。定义MLP模型结构,包括输入层、隐藏层和输出层。隐藏层可以使用多个全连接层,采用ReLU激活函数。输出层使用单个线性节点来预测烟碱含量。使用梯度下降法优化MLP模型参数,目标是最小化训练集上的均方误差损失函数。使用验证集评估模型性能,并根据验证集误差调整MLP的超参数以提高模型泛化能力。后期的回归过程:将新的烟叶样本特征向量 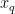 送入训练好的MLP模型的输入层,即输入层的输出
送入训练好的MLP模型的输入层,即输入层的输出 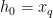 ,再通过MLP模型的前向传播计算,依次得到每个隐藏层的输出,公式如下:
,再通过MLP模型的前向传播计算,依次得到每个隐藏层的输出,公式如下:
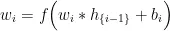
其中, 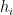 为第 i 个隐藏层的输出,
为第 i 个隐藏层的输出, 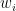 和
和 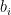 分别为第 i 个隐藏层的权重矩阵和偏置向量, f ( ) 为激活函数。最后,将最后一个隐藏层的输出
分别为第 i 个隐藏层的权重矩阵和偏置向量, f ( ) 为激活函数。最后,将最后一个隐藏层的输出 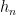 送入输出层,得到最终的烟碱含量预测值
送入输出层,得到最终的烟碱含量预测值 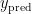 ,公式如下:
,公式如下:
其中, 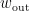 和
和 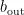 分别为输出层的权重向量和偏置标量。
分别为输出层的权重向量和偏置标量。
KNN算法的核心思想是:如果一个样本在特征空间中的 K 个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。其核心在于距离度量,它决定了样本之间的相似度。通过选择合适的距离度量方法,KNN算法能够准确地找出与待分类样本最相似的邻居,通过计算邻居的加权平均值来预测待分类样本的具体数值。在研究中,开始的模型训练:输入训练数据集 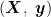 ,其中
,其中 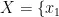
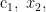 …,
…, 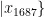 为1687个烟叶样本的特征向量,y={y,y,…,
为1687个烟叶样本的特征向量,y={y,y,…,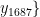 是对应的烟碱含量标签。不需要构建任何模型数,KNN算法直接利用训练数据集作为模型的知识库。训练过程仅涉及存储训练数据集中的样本特征和标签信息,为后续的近邻搜索和标签预测做准备。后期的回归:输入新的烟叶样本特征向量
是对应的烟碱含量标签。不需要构建任何模型数,KNN算法直接利用训练数据集作为模型的知识库。训练过程仅涉及存储训练数据集中的样本特征和标签信息,为后续的近邻搜索和标签预测做准备。后期的回归:输入新的烟叶样本特征向量 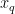 ,使用欧氏距离来计算
,使用欧氏距离来计算 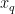 与训练集中所有样本
与训练集中所有样本 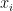 之间的距离
之间的距离 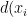
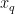 ),其欧氏距离可以通过下面公式计算:
),其欧氏距离可以通过下面公式计算:
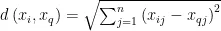
找出训练集中与 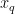 距离最近的 k ( ( k ∈ R ) 个最近邻训练样本,输入新的烟叶样本特征向量
距离最近的 k ( ( k ∈ R ) 个最近邻训练样本,输入新的烟叶样本特征向量 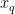 与这 k 个样本欧式距离记为
与这 k 个样本欧式距离记为 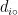 确定算法中的 k 值的最佳方法是使用交叉验证将原始数据集划分为训练集和验证集。从如 k = 2 开始,然后逐步增大,计算每个 k 值下模型在验证集上的分类准确率,模型结果如表3所示,在 k = 5 的时候,模型的性能表现较好。因此,研究中选择在验证集上取得最高分类准确率的5作为最优 k 值。
确定算法中的 k 值的最佳方法是使用交叉验证将原始数据集划分为训练集和验证集。从如 k = 2 开始,然后逐步增大,计算每个 k 值下模型在验证集上的分类准确率,模型结果如表3所示,在 k = 5 的时候,模型的性能表现较好。因此,研究中选择在验证集上取得最高分类准确率的5作为最优 k 值。
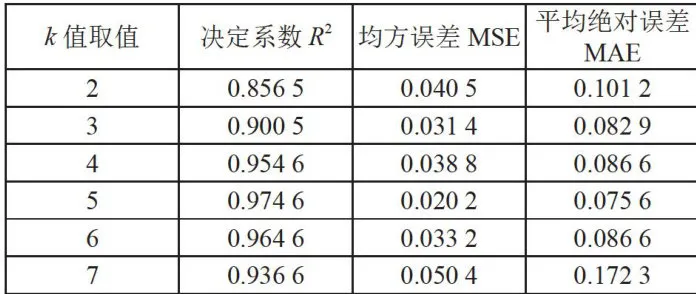 表3各 k 值的KNN模型评估结果数值的对比表
表3各 k 值的KNN模型评估结果数值的对比表
最后,计算这5个最近邻训练样本的目标变量值的加权平均值 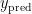 ,也就是新的烟叶样本烟碱含量,公式如下:
,也就是新的烟叶样本烟碱含量,公式如下:
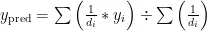
其中, 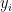 为第 i 个最近邻训练样本的目标变量值,
为第 i 个最近邻训练样本的目标变量值,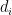 为第 i 个最近邻训练样本的距离。
为第 i 个最近邻训练样本的距离。
1.4 实验环境
在表4所列出的环境配置和硬件支持下,对基于颜色分布信息的烟叶烟碱含量预测展开了系统而全面的研究。
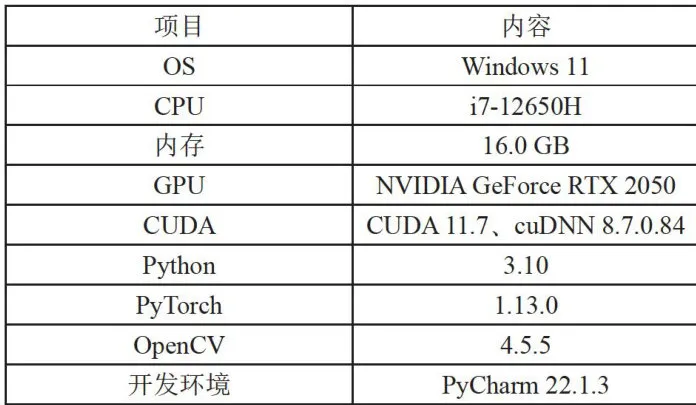 表4实验配置
表4实验配置2 结果与讨论
2.1 结果分析
实验中,通过对四个不同模型的预测结果进行对比分析,绘制出了相应的散点图,如图3所示。这些散点图清晰地展示了各模型预测值与实际值之间的分布情况,为评估模型性能提供了重要依据。通过观察散点的密集程度和分布趋势,可以初步判断各模型在预测任务上的准确性和稳定性。
经过对四个模型的散点图进行细致的对比分析,观察到KNN模型的散点图中Predicted值与Actual值之间的接近程度显著优于其他模型。为了更全面地评估各模型的性能,本研究使用决定系数(Coefficient ofDetermination, 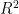 ),均方误差(MeanSquaredError,MSE)和平均绝对误差(MeanAbsoluteError,MAE)三个指标对预测结果进行了评估,如表5所示。
),均方误差(MeanSquaredError,MSE)和平均绝对误差(MeanAbsoluteError,MAE)三个指标对预测结果进行了评估,如表5所示。
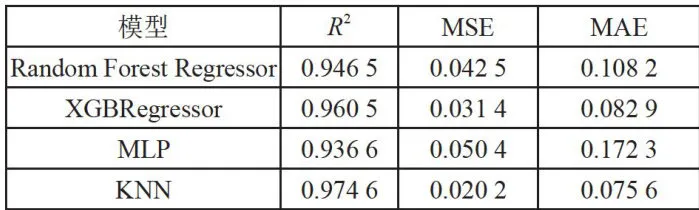 表5模型评估结果指标对比
表5模型评估结果指标对比
经过对比分析四个模型的实验结果,以及基于决定系数 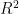 、均方误差(MSE)和平均绝对误差(MAE)三个评估指标的数据,我们发现KNN模型在预测任务中展现出了较好的性能。具体而言,KNN模型在分类任务中取得了高达0.9746的
、均方误差(MSE)和平均绝对误差(MAE)三个评估指标的数据,我们发现KNN模型在预测任务中展现出了较好的性能。具体而言,KNN模型在分类任务中取得了高达0.9746的 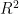 值,表明该模型能够精准地拟合数据,其正确预测的样本比例达到了约 9 7 . 4 6 % 。在回归任务方面,KNN模型同样表现出色,均方误差仅为0.0202,显示出模型预测值与真实值之间的平均差的平方非常小。此外,平均绝对误差也相对较低,为
值,表明该模型能够精准地拟合数据,其正确预测的样本比例达到了约 9 7 . 4 6 % 。在回归任务方面,KNN模型同样表现出色,均方误差仅为0.0202,显示出模型预测值与真实值之间的平均差的平方非常小。此外,平均绝对误差也相对较低,为 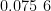 ,这进一步证明了模型预测值与真实值之间的平均绝对差较小。
,这进一步证明了模型预测值与真实值之间的平均绝对差较小。
2.2 研究讨论
本研究创新性地将烟叶颜色分布信息应用于预测烟叶烟碱含量,不仅具有理论价值,而且在实际应用中展现出独特的优势。具体而言,近年来在烟碱的预测方面,虽然已有使用近红外光谱分析、高光谱成像以及深度学习等技术,但这些技术在实际应用中成本较高,对技术人员的技术要求也较高,这无疑增加了技术推广的难度。相比之下,利用颜色的空间分布信息和机器学习方法的技术难度较低,对技术人员的要求相对较低,所需的相关系统搭建也更加方便简单、成本低,更便于实际应用。因此,颜色的空间分布信息和机器学习方法在实际应用中具有独特的优势。
在研究后期阶段,深入对比了所提的四类经典机器学习方法,旨在确保结果的严谨性与可靠性。所有相关实验均基于统一的数据集和平台,并运用MSE、MAE及 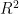 作为评价标准。图4直观展示了这四种模型在预测烟草样本烟碱含量时的性能差异。具体地,图中的每一个散点均代表了实际测量值与模型预测值之间的对应关系,其中横坐标代表真实值,而纵坐标则代表预测值。值得注意的是,图中均有一条y = x 的红色虚线作为参照,若模型预测值与真实值完全一致,则所有散点应紧密围绕此线分布。观察结果显示,在RandomForestRegressor与XGBRegressor模型中,散点分布相对分散,尤其在对角线两侧,表明这两类模型的预测值与真实值之间存在明显偏差。相较之下,KNN与MLP模型表现相对更佳。然而,MLP模型在烟碱含量较低时,其预测值往往偏高,这从散点分布在对角线上方的情况可以得到验证。而在KNN模型中,烟碱百分比位于 0 . 5 % ~ 3 % 这一范围内时,其预测值的准确性显著提升,表现为散点在对角线附近紧密分布。
作为评价标准。图4直观展示了这四种模型在预测烟草样本烟碱含量时的性能差异。具体地,图中的每一个散点均代表了实际测量值与模型预测值之间的对应关系,其中横坐标代表真实值,而纵坐标则代表预测值。值得注意的是,图中均有一条y = x 的红色虚线作为参照,若模型预测值与真实值完全一致,则所有散点应紧密围绕此线分布。观察结果显示,在RandomForestRegressor与XGBRegressor模型中,散点分布相对分散,尤其在对角线两侧,表明这两类模型的预测值与真实值之间存在明显偏差。相较之下,KNN与MLP模型表现相对更佳。然而,MLP模型在烟碱含量较低时,其预测值往往偏高,这从散点分布在对角线上方的情况可以得到验证。而在KNN模型中,烟碱百分比位于 0 . 5 % ~ 3 % 这一范围内时,其预测值的准确性显著提升,表现为散点在对角线附近紧密分布。
3结论
本研究通过分析烟叶的颜色分布信息建立了对烟叶烟碱含量检测的多个定量模型,通过评估指标进行了综合比较,结果表明该方法测得的值与实际值接近,其中K-NearestNeighbors(KNN)且 k 值取为5的时候模型表现最优异,达到了预计效果,其精度完全满足对于快速预测烟叶烟碱含量的要求。
后续会对总糖、总氮等其他相关常规化学指标进行建模,希望本研究能够为烟叶质控以及烟叶的分级,提供切实、可行的指导和借鉴。
参考文献:
[1]蒋薇,汤亮,薛博文,等.基于连续小波变换的烤烟叶片总氮和烟碱含量高光谱监测预测研究[J].中国烟草学报,2023,29(4):33-43.
[2]王玉华,杜传印,王先伟,等.箱式烘烤对烤后烟叶品质的影响[J].安徽农业科学,2024,52(1):172-177
[3]朱贝贝,何声宝,安泓汐,等.不同用途雪茄烟叶化学成分分析及其对感官质量的影响[J].安徽农业科学,2023,51(23):181-184.
[4]冷红琼,郭亚东,刘巍,等.FT-NIR光谱法测定烟草中绿原酸、芸香苷、茛蓉亭及总多酚含量[J].光谱学与光谱分析,2013,33(7):1801-1804.
[5]葛炯,王维妙,张建平.近红外光谱技术对烟草pH值的快速测定[J].分析测试学报,2009,28(6):742-745.
[6]潘威,马文广,郑昀晔,等.用近红外光谱无损测定烟草种子淀粉含量[J].烟草科技,2017,50(2):15-21.
[7]李阳阳,张辞海,彭黔荣,等.近红外光谱快速测定卷烟烟气中烟碱·焦油和一氧化碳释放量[J].安徽农业科学,2022,50(17):175-178.
[8]吴雪梅,张富贵,吕敬堂.基于图像颜色信息的茶叶嫩叶识别方法研究[J].茶叶科学,2013,33(6):584-589.
[9]刘艳萍,王云,贾哲,等.基于颜色-特征成分关联分析及网络药理学的金银花质量标志物(Q-Marker)研究[J].中草药,2024,55(14):4882-4896.
[10]梁洪波,李念胜,元建,等.烤烟烟叶颜色与内在品质的关系[J].中国烟草科学,2002(1):9-11.
