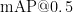
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2025)08-0054-07
Abstract: Gesture recognition is of great significance torealize human-computer interaction.In order torealize highprecisiontarget detection and recognition under dynamicconditions,this paper is based on YOLOv5 target detection firstly and determines the coordinate informationof the target gesture byusing thefeature pyramid structureand multi-scale fusion structuralfeaturesinsidethealgorithm.ThenitusestheMediaPipemodeltodetectthekeypointsofthehand,deterinesthe vectorangleofthehand joints,andanalyzes thefingerbendingsituation,soas tojudge the specific gesture.Using themethods of positiondeterminationand implementationbyusingseparate models foractionclasficationeffectivelyimproves the problem that thereduced recognitionrateof gesturescaused byfactors suchasrotationandoccusionin dynamicconditions.The training samplesare selected fromsixcategories intheopen-source gesturedataset HaGRID.Theexperimentaltestresults demostrate that the mean value of one-hand recognition detection accuracy of the combined algorithm is up to 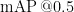 and the detection speed is up to 40 FPS,and the model size is 88.5 MB.
and the detection speed is up to 40 FPS,and the model size is 88.5 MB.
Keywords: gesture recognition; YOLOv5;MediaPipe; hand joint point detection; gesture dataset
0 引言
人机交互是指人与计算机之间通过某种特殊方式实现信息交换的过程,传统人机交互采用穿戴传感器的方式,由于传感器的感知范围有限且信号不具有普适性的问题,无法满足人们日常生活的实际要求。随着视觉设备捕捉速度和识别算法精度的不断提升,手势作为一种直观且高效的肢体语言表达方式,计算机通过提取视频数据中手势动作的特征信息,构建特征信息和手势动作之间的映射关系,按照特征信息的差异性翻译成对应的肢体语言,实现计算机主动理解人类的行为意图[]。当前,手势识别被广泛应用在车载监控、医疗监护、智能家居等领域。考虑到自然状态下,存在环境光照、背景以及手势自身旋转性等因素。本文采用深度学习目标算法作为检测基础,结合MediaPipe手势关键点检测[2]方法,通过确定手势的坐标信息和向量角度,判断手指的弯曲程度,实现最终手势类别的识别,最后在开源数据集HaGRID进行算法模型的训练及验证,证实本实验方法的可行性。
1手势识别神经网络模型
1.1 YOL0v5目标检测
YOLOv5的网络结构可以分成四个部分:输入层(Input)、主干特征提取网络(Backbone)、中间尺度变化网络层(Neck)以及目标检测网络(Head)[3]。输入层采用Mosaic数据增强方式,自适应的图像拼接和锚框计算。主干网络采用 C S P + F o c u s + S P P 等模块组成特征提取网络。Neck中间层采用FPN+PANet用于融合不同阶段输出的特征信息,提高网络的检测精度。Head用于预测目标和类别的输出。
主干网络主要用于目标特征的提取,如图1所示,YOLOV5的主干网络由CSP和Focus模块组成。CSP网络设计包含CSP1 N 和CSP2 N 两种,采用跨层次的方式进行结构合并,从而丰富了特征梯度的组合信息CSP1 N 前设置一个卷积层,卷积核大小为3 × 3 ,Stride大小为2,作为Backbone主干特征提取网络实现特征降采样。CSP2_ N 结构则作用于Neck网络中,由 2 N 个CBL与卷积层组成,从而实现加强网络特征融合的作用,Concat主要负责浅层和深层特征的通道信息融合[4]。
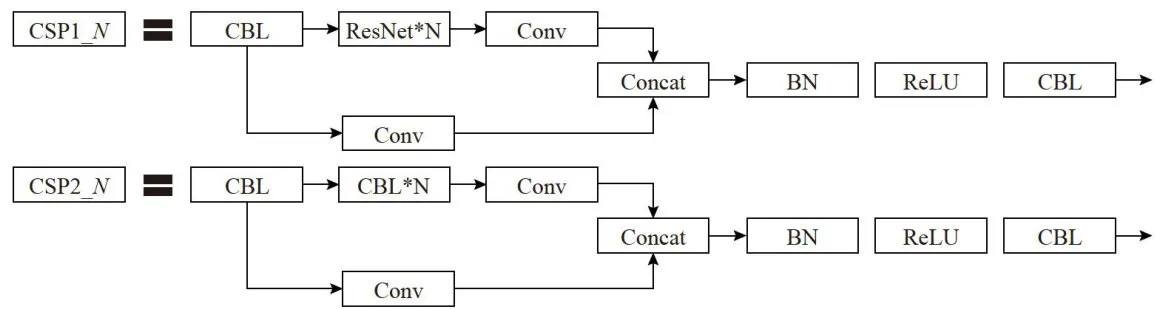 图1CSP模块组成部分
图1CSP模块组成部分如图2所示,Focus网络结构由4个切片和CBL构成,CBL包含卷积层(Conv)、批量归一化层(BN)以及激活函数三个部分。当卷积核的数量越多,所得到的特征宽度越厚,网络的学习能力也越强[5]。将输入图像尺寸大小为 6 4 0 × 6 4 0 × 3 的彩色图像直接进行通道互换,得到 3 2 0 × 3 2 0 × 1 2 的尺寸大小,通过以上计算可以看出Focus网络将输入的数据进行切片为原图的一半,在不丢失特征信息的同时实现图像降维的目的。
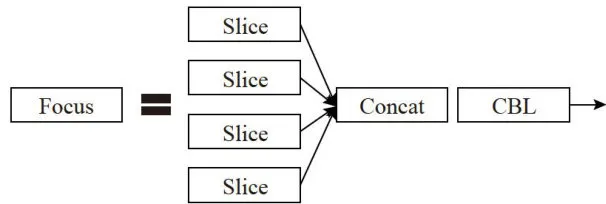 图2Focus网络结构
图2Focus网络结构Neck主要位于特征提取层和分类器之间,用于特征提取的压缩,该模块主要由SPP和 F P N + P A N 两部分组成。其中,SPP用于扩大感受野,实现预测框与特征图的对齐。如图3所示,SPP网络包含四个分支结构,使用不同尺寸池化核,将特征划分成1 × 1 、 5 × 5 , 9 × 9 、 1 3 × 1 3 四种尺寸。采用边缘填充的方式保证输出特征矩阵长度的一致性,最后将四个分支获得特征矩阵进行融合输出,使得全局特征与局部特征有效融合,提高模型特征的语义性和特征表达能力。
如图4所示, F P N + P A N 是一种图像金字塔结构,结合上采样和下采样,提高小目标对象的检测效果,具有尺度不变性。FPN采用自上而下的方式,将特征图进行下采样。与FPN相反,PAN金字塔结构采用从下到上,将语义信息表征信息进行维度的获取,实现高维表征与低维特征的融合工作。FPN网络采用自下而上的路径聚合输出方式,将低维特征信息通过下采样的方式与高特征维度进行融合,提高小尺寸自标的检测效果,从而得到输出特征矩阵。PAN自适应特征池化结构则采用自顶向下的传输方式,将低维特征信息采用上采样的方式,通过浅层特征的分割得到边缘等特征,提高物体大目标对象的检测。
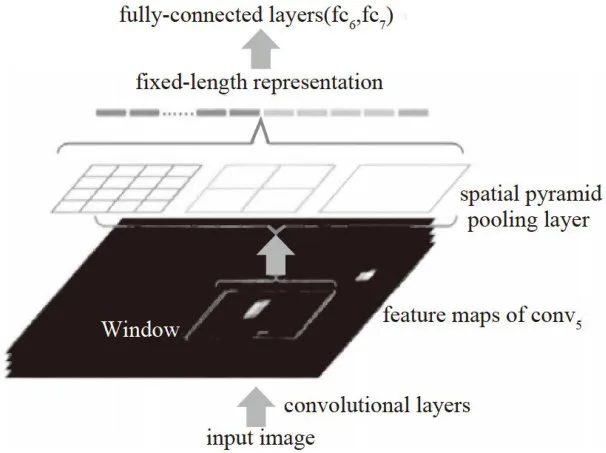 图3SPP实现原理图
图3SPP实现原理图1.2MediaPipe关节点检测
MediaPipe是谷歌公司发布的一款跨平台机器视觉学习框架,内部提供了身体姿势、面部、手部等预训练模型,该模型通过提供开发文档和可视化编程工具,帮助开发者快速构建视觉计算。该模型通过实时检测手部关键点信息,将检测后的手势转化为相应的数字或字符,以满足不同场景下的应用需求。在实时手势追踪的过程中,考虑到由于运动所带来的手势动作形变等问题,为降低目标检测过程中数据增强的需求。MediaPipe框架将上一帧边界框的信息作为当前帧的输入,只有在开始帧或者检测器丢失手部信息时,才会启动检测器,该方法可以有效地减少手部检测模型的计算量,避免训练过程中的过拟合情况。
MediaPipe检测流程如图5所示,图像采集器通过捕捉RGB-D视频得到每帧图像的R、G、B颜色和深度信息。利用手部检测器模型实现手部位置的快速定位,考虑到手部形变和遮挡问题,模型不直接进行手指或关节的检测,而是估算手掌和拳头的位置实现手部位置定位。检测器通过检测手部关节锚点模拟手掌骨架,采用编码-解码的方式扩大感知背景,忽略手掌的长宽比,降低锚点检测数量,实现高缩放情况下的手部关节锚点检测。
手部关节点检测如图6所示,在对每帧数据进行图像裁剪、归一化之后,通过手掌检测器将图像的空间坐标系中2D点坐标转化为实际下的像素坐标,获得关键点的深度信息范围为 0 ~ 1 。将2D坐标点与深度信息进行融合,将特征提取之后,生成手部3D坐标维度为 2 1 × 3 关键点信息[8。当未检测到当前帧手部关键点信息时,多余部分的特征信息全部记为0,当检测到手部关节信息时,根据当前关节点信息预测下一帧手掌可能出现的区域。
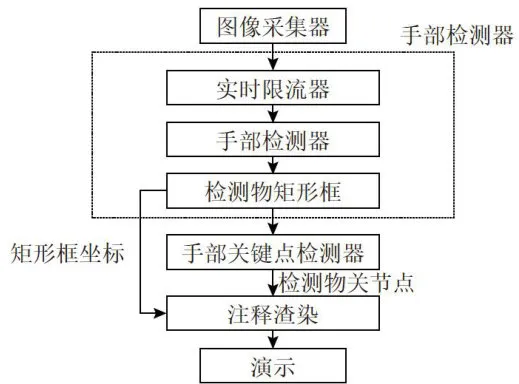 图5MediaPipe检测流程
图5MediaPipe检测流程
图7为手势关节点标注信息,通过分析指间关节各夹角之间的大小 ⋅ θ 和各方位的运动向量 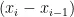 、
、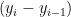 、
、 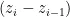 [],计算手部关节点之间的欧式运动距离和向量角度,判断手指的弯曲程度,关键点之间对应距离变化量计算式如(1)所示,向量之间的夹角计算式如(2)所示。
[],计算手部关节点之间的欧式运动距离和向量角度,判断手指的弯曲程度,关键点之间对应距离变化量计算式如(1)所示,向量之间的夹角计算式如(2)所示。
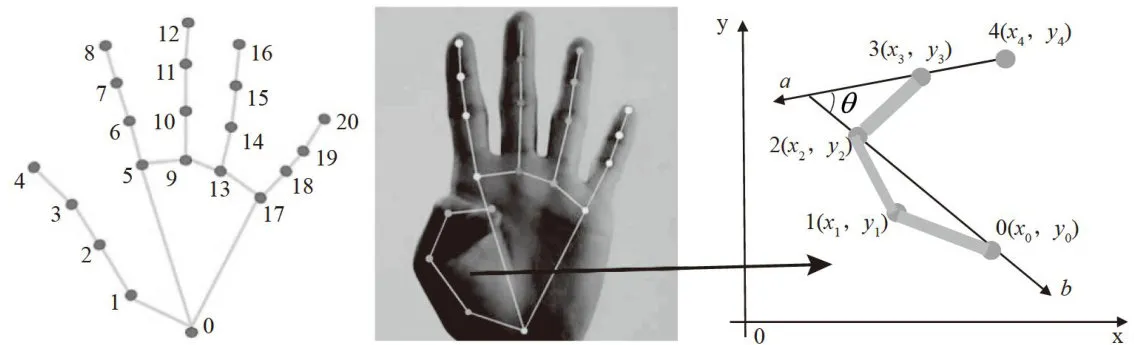 图7手部关节点检测模型架构
图7手部关节点检测模型架构
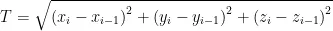
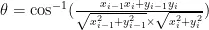
2实验环境及数据预处理
2.1 HaGRID数据集
HaGRID数据集是广泛应用于手势识别研究的开源数据集,该数据集在不同场景下进行采样,每位受试者需在距相机 0 . 5 ~ 4 . 0 米之间距离处,完成手势动作的采样。数据集共包含超过50万张 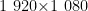 分辨率的RGB图像,采样不同人类手部动作图像样本,共涵盖18个手势类别,且每个样本都包含一张彩色图像和相应手势标签[10]。考虑到原数据集数据总量较大,本实验对HaGRID数据集进行精简,只选择了call、four、ok、one、palm、three六种类别作为样本,HaGRID数据集部分样本如图8所示,每个类别约7000张图像。
分辨率的RGB图像,采样不同人类手部动作图像样本,共涵盖18个手势类别,且每个样本都包含一张彩色图像和相应手势标签[10]。考虑到原数据集数据总量较大,本实验对HaGRID数据集进行精简,只选择了call、four、ok、one、palm、three六种类别作为样本,HaGRID数据集部分样本如图8所示,每个类别约7000张图像。
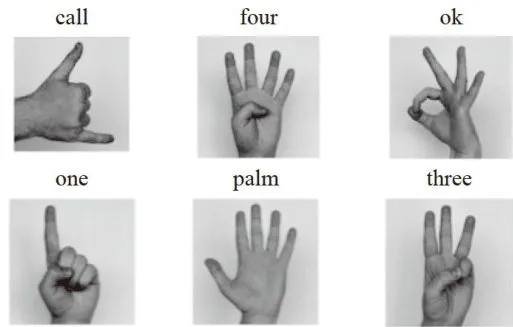 图8HaGRID数据集部分样本
图8HaGRID数据集部分样本2.2实验环境与网络超参数
网络模型的训练与测试需要在硬件平台上进行,本文进行程序设计与调试所用的操作系统为Windows10,GPU 为NvidiaGeForceRTX2080Ti,显存为 1 6 G B 。编程语言采用Python3.9,深度学习框架为PyTorch1.7。
超参数是指模型训练开始之前需要提前设置的参数,良好的超参数设置可以控制模型的复杂程度及防止过拟合。实验将数据集划分为训练集与测试集划分比例为9:1,Batchsize为16,初始学习率为0.01,动量为0.937,采用Warmup预热学习率策略,在模型稳定时,通过余弦退火算法动态调节学习率大小,防止过拟合的同时加速模型的收敛速度[],详细超参数设置如表1所示。
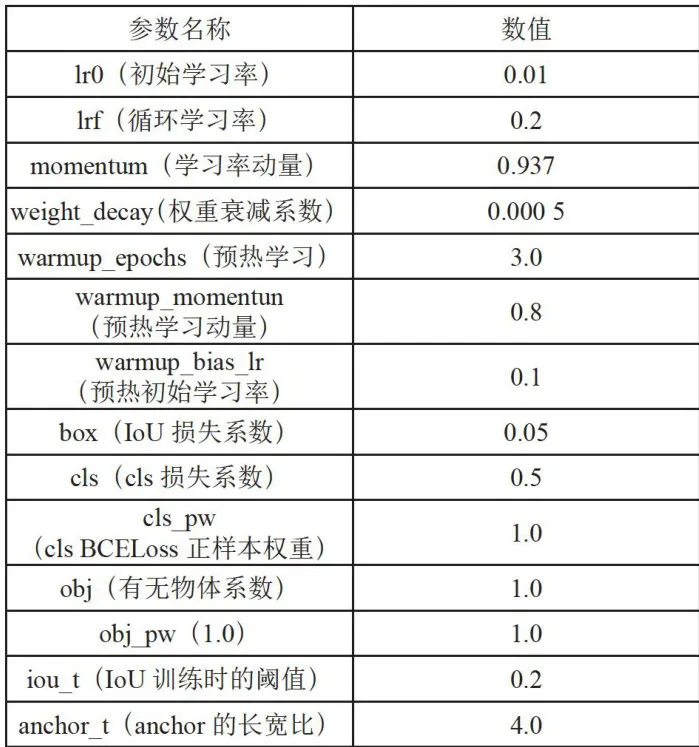 表1超参数设置数据增强参数详细设置如表2所示,包括颜色空间和图片空间。
表1超参数设置数据增强参数详细设置如表2所示,包括颜色空间和图片空间。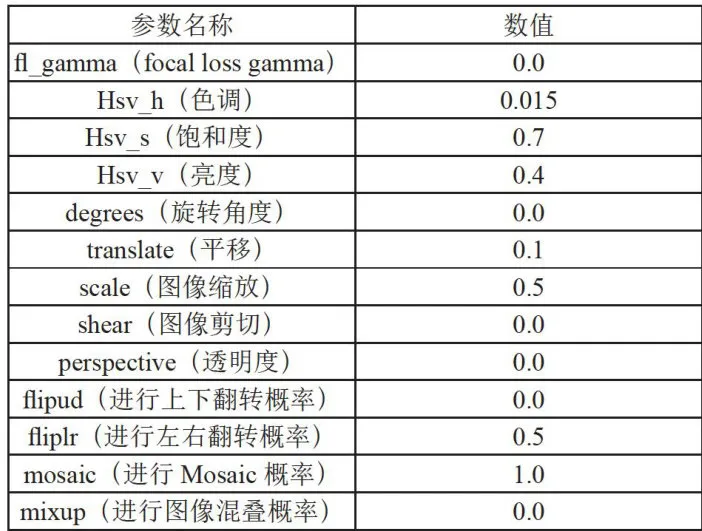 表2数据增强参数设置
表2数据增强参数设置3 实验结果和分析
3.1 性能评估
在目标检测中为了定量的评价实验结果,常使用召回率(Recall)和精度均值(mAP)衡量模型的准确性。Recal1用于衡量实际为正样本中被检测正确的概率,如式(3)所示,mAP用于综合评估准确性与召回率,有效衡量模型的检测精度和泛化能力[12],如式(4)所示,FPS(FramesPerSecond)用于评定模型的检测速度。
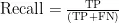
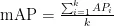
实验以HaGRID数据集作为训练数据,在训练过程中不断的优化和调整超参数,保证网络精度的前提下提高网络运行效率。训练过程中,每50个Epoch计算一下mAP的值,训练过程中mAP曲线变化情况如图9所示,从图中可以看出,模型训练起始阶段曲线的收敛速度较快,且出现了部分震荡的现象,随着训练的不断迭代和学习率的变化,当网络曲线基本趋于平稳,模型权重逐渐趋于最优解。最后,当训练迭代次数达到大概步数时,曲线下降趋势基本趋于平稳,模型学习效率[13]趋于饱和,此时模型的损失值保持在0.5至0.9附近。
对于 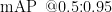 ,由于没有提供具体的数字,所以无法根据曲线的变化确定训练是否发生过拟合,此时需要综合训练日志、损失函数变化、召回率等进行综合考虑。图10中Box表示所有边界框的数量、Objectness表示边界框是否包含目标物的概率,即目标得分、Classification表示边界框包含物体类别的概率,即类别得分。Val表示验证集上各项指标的值,该值越小表示模型鲁棒性越稳定[14]。
,由于没有提供具体的数字,所以无法根据曲线的变化确定训练是否发生过拟合,此时需要综合训练日志、损失函数变化、召回率等进行综合考虑。图10中Box表示所有边界框的数量、Objectness表示边界框是否包含目标物的概率,即目标得分、Classification表示边界框包含物体类别的概率,即类别得分。Val表示验证集上各项指标的值,该值越小表示模型鲁棒性越稳定[14]。
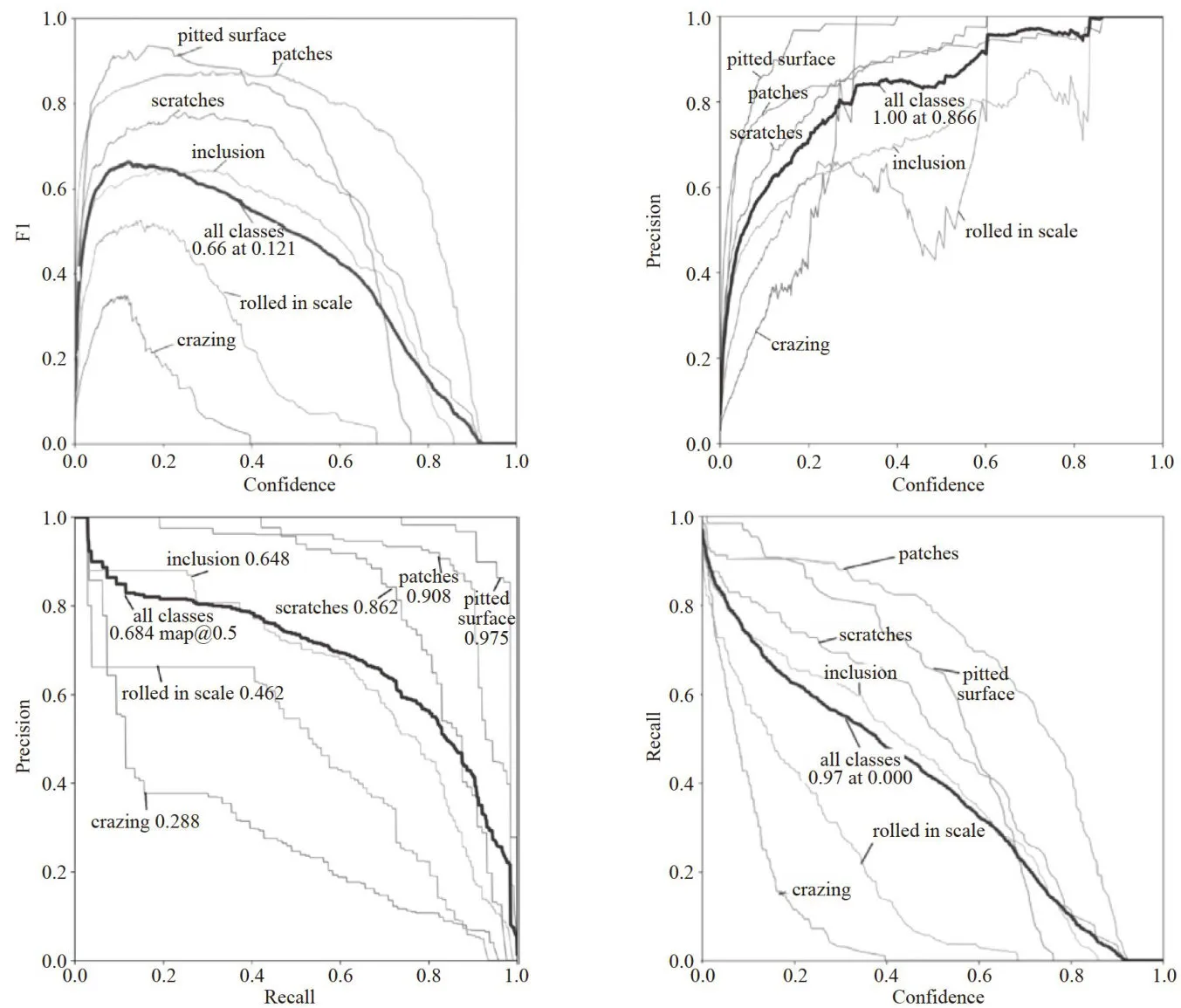 图9mAP曲线变化
图9mAP曲线变化3.2 实验与结果分析
为了验证算法模型的准确度,对6种手势类别绘制分类结果的混淆矩阵,各手势动作在验证集上识别准确率如图11所示,横坐标为动作类别,纵坐标为真实动作的类别,正方形框中为各类手势动作的准确度,通过图示可见,所有动作在准确度上都表现较好[15]。其中,palm类别由于关节点不存在遮挡,模型捕捉到的有效信息更多,所以识别精度最高。对于未分类的动作,设置NoGesture标签,此时需要采用人工补充的方式对动作进行补充。
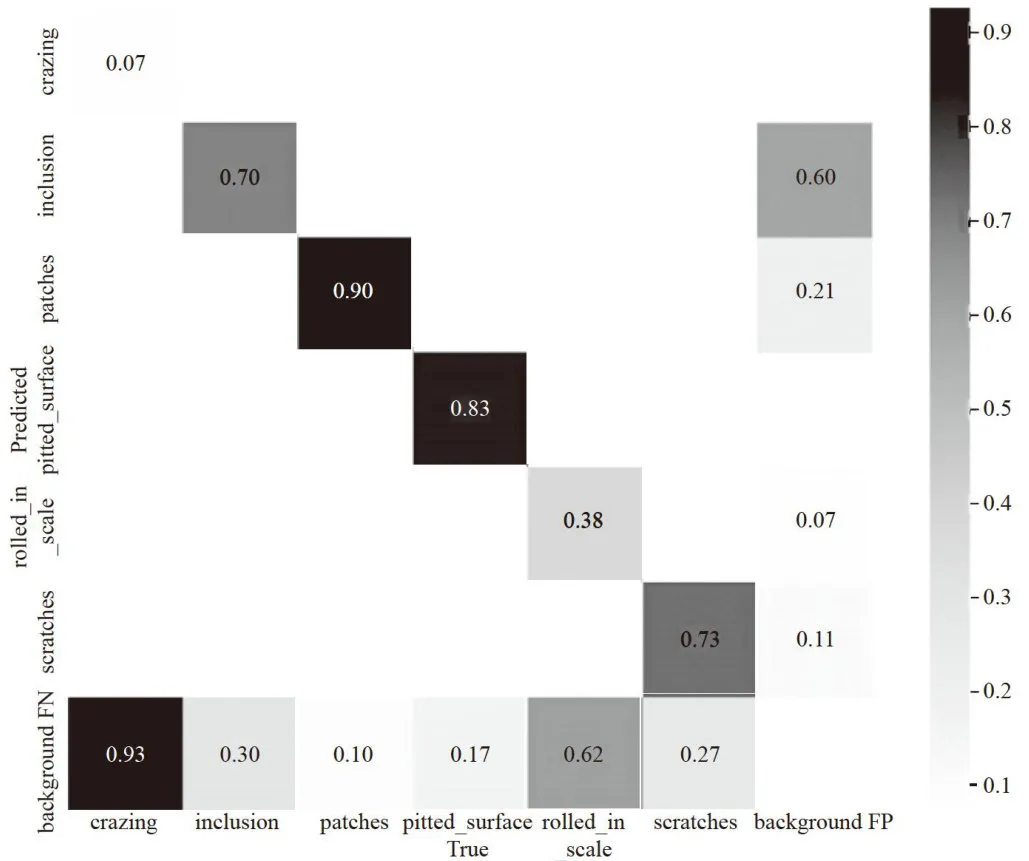 图11手势分类准确率的混淆矩阵
图11手势分类准确率的混淆矩阵调用MediaPipe模型中的MediaPipeHand、DisplayHand两个类用于手势关节点提取和关节点可视化[1]。实验运行过程中,提取并保存21个手势关键点,并通过连接线连接起来绘制出手势骨架。如图12所示,所有检测结果都通过预测框的方式进行标注,每一种手势都可以清晰的描述关节信息。
 图12手势关节点检测
图12手势关节点检测如图13所示,改进后的算法检测速度FPS在40帧/秒左右,同时附带置信度分数[17]。其中,置信度分数为介于 0 ~ 1 之间的浮点数,其值越接近1表明识别的手势类别越准确。
4结论
本文采用深度学习目标检测算法实现动态手势识别,通过目标检测算法确定手势的坐标信息之后,利用MediaPipe模型确定向量角度,判断手指的弯曲程度实现手势的识别。算法训练与测试过程,在性能优良的服务器上实现,但深度学习模型在运算过程中往往需要大量的算力推理计算,后期在模型迁移上,有待进一步对模型进行剪枝和推理加速的研究。
参考文献:
[1]陈睿智,谢晓雨,罗莹.科学教育测评中人机交互试题的发展、特征与启示[J].中国考试,2024(8):79-88.
[2]高加瑞,杜洪波,蔡锦,等.基于MediaPipe的手势识别算法研究与应用[J].智能计算机与应用,2024,14(4):157-161.
[3]袁荫,杨苏朋,陈孟元.动态场景下基于YOLOv5的SLAM算法[J/OL].重庆工商大学学报:自然科学版,2024:1-9[2024-08-23].http:/kns.cnki.net/kcms/detail/50.1155.N.20240816.0914.002.html.
[4]文硕怡.基于深度学习的手势序列识别研究[D].天津:天津职业技术师范大学,2024.
[5]周楠.基于卷积神经网络的手势识别算法研究[D].桂林:桂林理工大学,2022.
[6]BAIL,DINGXW,LIUY,etal.Multi-scaleFeatureFusion Optical Remote Sensing Target Detection Method [J].OptoelectronicsLetters,2025,21 (4):226-233.
[7]ABONDIO P,BRUNO F. Single-cell Pan-omics,Environmental Neurology,and Artificial Intelligence:The TimeforHolistic Brain Health Research [J].Neural RregenerationRresearch,2025,20(6):1703-1704.
[8]罗怡.基于深度学习的手部姿态估计研究[D].贵阳:贵州大学,2023.
[9]刘晓克.基于深度学习的人体关节点检测算法研究[D].秦皇岛:燕山大学,2019.
[10]蔡宇.基于深度学习的手势识别算法研究[D].呼和浩特:内蒙古大学,2023.
[11]邱锋.基于深度学习的实时动态手势识别[D].杭州:浙江大学,2020.
[12]陈睿敏.手势识别关键技术及其在智能实验室中的应用研究[D].中国科学院大学(中国科学院上海技术物理研究所),2017.
[13]杨文姬.面向家庭服务机器人的手势交互技术研究[D].秦皇岛:燕山大学,2015.
[14]王凤艳.基于多模态输入的手势识别算法研究[D].合肥:中国科学技术大学,2017.
[15]尹康.基于多特征融合网络的手势轨迹识别研究[D].成都:电子科技大学,2019
[16]白云超.手势行为的识别及语义表征技术[D].南京:南京大学,2020.
[17]王强宇.基于深度神经网络的动态手势识别技术研究[D].北京:中国矿业大学(北京),2019.
作者简介,陈吴东(2003一),男.汉族,湖北荆州人.本科在读,研究方向:嵌入式系统。