吴碧文,周瑾,施丽霞,孟丽霞
(福州市市场监管监测服务中心,福建 福州 350001)
0 引 言商事制度改革以来,营商环境不断优化,企业注册登记更加高效便捷,市场准入条件放宽,企业登记成本大幅降低,市场主体数量不断增加,创新创业活力得到有效示范,惠及了广大群众。但是在为企业提供这些便捷化服务的同时,也让一些不法分子有机可乘,借机利用虚假身份、虚假地址、隐瞒重要信息等方式骗取企业登记,“被法人”“被地址”“被股东”等也一度成为网络热词。虚假注册问题的存在,直接影响优化营商环境的推进,扰乱经济秩序,严重损害被侵权人合法权益。针对这些问题,各级市场监管部门充分利用各种先进技术,在注册前端采取人脸识别、指纹验证、联网核查、对接标准地址库等技术对注册人、注册地址、代办人等进行核验,及时驳回虚假注册申请,在一定程度上遏制了企业虚假注册行为。但仍不乏一些比较隐蔽的虚假注册行为既成事实而未被及时发现,如注册地址真实存在但过度注册,同一地址多家公司注册、法人身份真实但同时注册多家公司、新设立企业在短时间内法人、高管全部变更等等。笔者在监测工作中发现这些异常情况与企业虚假注册关联度较高,亟须利用大数据思维模式,对企业相关注册登记、投诉举报、监督检查、年报、舆情、医社保缴交等组成的大数据进行充分挖掘,构建企业虚假注册风险预警模型,进一步防范企业虚假注册风险。
1 预警模型总体框架思路基于福州市市场监管预警平台已经收集的企业登记信息、变更信息、年报信息、出资信息、异常名录等数据,结合近年来福州市企业虚假注册案例数据,从注册地址、代理注册、企业主要人员、企业行为四个方面运用聚类分析和关联分析法构建企业虚假注册预警风险预警模型。
从注册地址分析:企业登记秉承“形式审查”原则,对住所登记不断简化,从产权材料齐全到只需提供租赁材料,再到只需提交住所承诺书,再加上国内经营场所的租赁成本又居高不下,部分注册人采用编造假的注册地址、冒用他人地址等方式骗取企业注册登记。导致部分注册地址虚假或是不能真实反映企业实际情况。2019年,福建省某市一洗浴场所营业执照被曝光,经营场所地址为该市某部门的厕所。
从代理注册分析,商事制度改革让企业注册登记更加便捷,《中华人民共和国市场主体登记管理条例》第十八条规定“申请人可以委托其他自然人或中介机构代其办理市场主体登记”,在全民创业、万众创新的趋势下,不少创业者为了节约时间成本,会选择委托代办人或中介机构注册公司。监测发现代办人或中介机构经常以“无须本人到场、0 资金、无地址、虚拟地址注册公司”等进行宣传,福州市近年来发现的170 家虚假注册企业中就有133 家企业是由代办人或中介机构代理注册的,可见代办企业存在虚假注册风险比较高。
从企业主要人员分析:企业注册登记时,填报企业主要人员一般由法定代表人、股东、监事组成,注册登记时需要提供相关人员的身份证信息。部分企业进行注册登记时借用他人身份证、用捡拾的身份证等虚假身份信息进行企业注册登记,“被法人”“被股东”等虚假注册事件不断发生。
从企业行为分析:企业设立登记后应遵循中华人民共和国相关法律法规合法经营,企业经营过程中涉及一切活动均认定为企业行为,通过对企业行为跟踪与监测,发现企业频繁变更、年报真实性等方面与企业虚假注册关联度较高。监测发现虚假注册公司福建某资本管理有限公司存续期间法人、董事等高管变更次数达10 次。
2 模型构建方法2.1 企业虚假注册数据处理与聚类分析结合监管经验,本文选取的监测指标有:同一住所注册企业数量、企业地址变更次数、企业注册时法定代表人年龄、法定人董事等高管变更次数、法定代表人同时任职福州企业家数、未按规定期限公示年报次数、10 天内集中注册相似企业数量、列入经营异常名录次数以及是否代办人代办企业等。
本文选取的分析数据为2015—2021年立案查处和撤销登记的170 家虚假注册企业信息及本市近37 万家企业基本登记信息、监管信息、年报等数据。如表1所示。
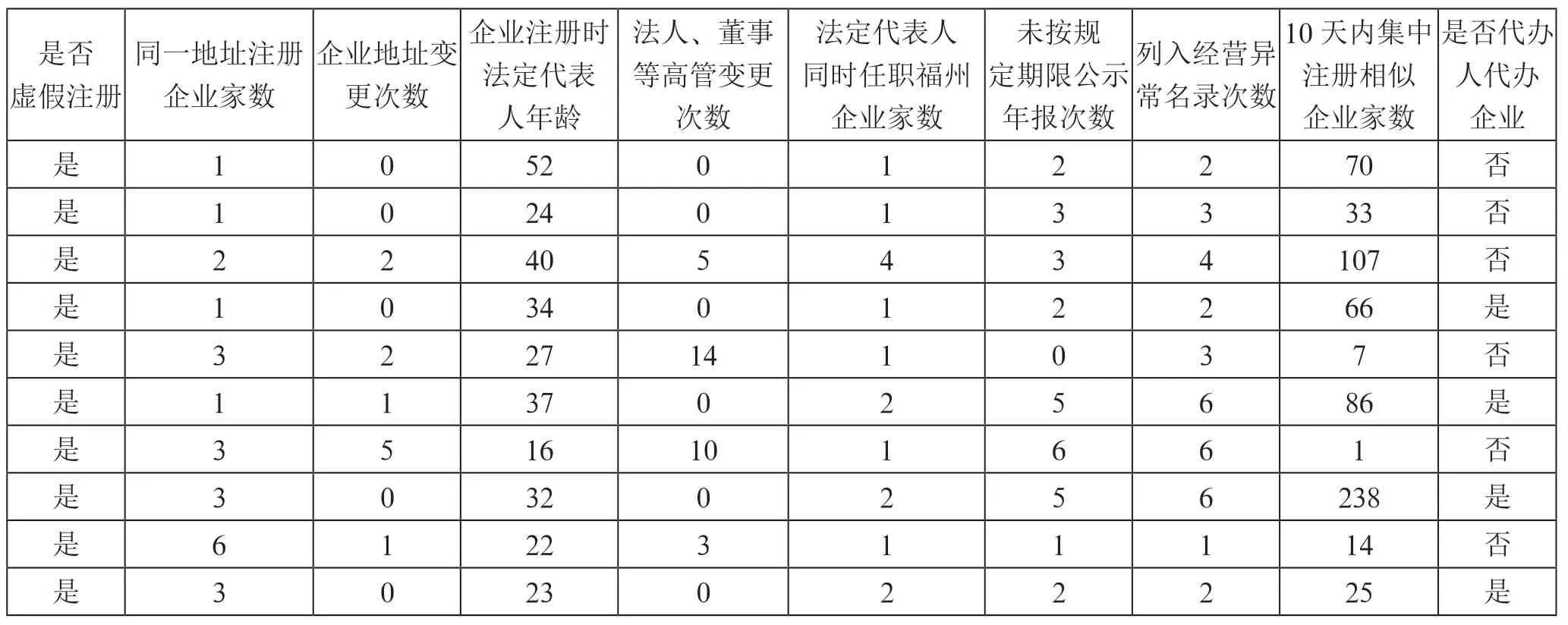
表1 部分虚假注册企业指标数据
2.1.1 数据标准化处理
z-score 方法是一种常见的将数据标准化处理的方法,处理后的数据处在同一数量级,数据之间具备可比性且符合正态分布,故本文采用此法:
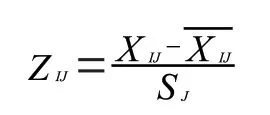
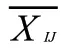
2.1.2 K 均值聚类
(1)聚类算法。聚类分析常用聚类方法有:层次聚类法、K-Means 聚类法等。当我们有足够的信息能够定义聚类的初始值,即能够指定合适的起始聚类时,适用于使用K-Means 聚类将观测值按照相同的特征进行分组。本项目选用K-Means 聚类法,使用Minitab 软件进行评估分析,在多个虚假注册企业的各项指标中选出能够代表企业虚假注册普遍性的特征变量。
(2)算法的数学形式。聚类分析算法是按照各变量之间存在的差异性进行分析的,而变量间的差异性通过距离进行反映,距离越近,则表示相似性越明显。距离量度方式有多种,本文选用欧式距离作为样本之间距离的度量,数学定义为:
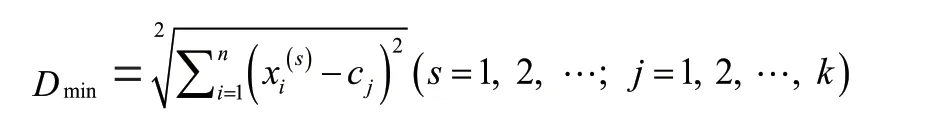
式中的x为样本的特征项,c为样本初始化的聚类中心,代表了样本的数量。
(3)虚假注册聚类分析。K-Means 聚类使用的是非分层过程对虚假注册指标进行分组。因此,在聚类过程中,最初合并在一起的两个观测值还是可能被分割到不同的聚类去。为了使聚类结果更加准确,根据经验选定K-Means 聚类过程最适合聚类的有效起始点后,需要对所有观测值进行多次聚类。依次选择聚为3 类、4 类、5 类、6 类,对聚类结果进行比较,发现聚为3 类时,聚类效果最好。选择聚类个数为3 个分类后,对标准化处理后的数据进行聚类分析,得到结果如表2所示。
由Minitab 软件生成的K-Means 分类结果表2可知,企业注册分析分为3 类,其中第一类企业注册风险的总数为54,占总样本空间的31.7%;第二类企业注册风险用户的总数为27,占总样本空间的15.8%;第三类用户的总数为89,占总样本空间的52.3%。第三类注册企业的占比最高,根据初始值聚类分类结果得出当年注册地址超过3 家企业注册的企业数量,是否代办人代办企业,10 个工作日内集中登记的相似企业数量,法人董事等高管变更3 次以上的企业数量,未报送企业年报的新设企业数量对聚类的结果影响比较大,说明这五个指标与虚假注册企业的相关性强,是企业虚假注册的普遍性特征。
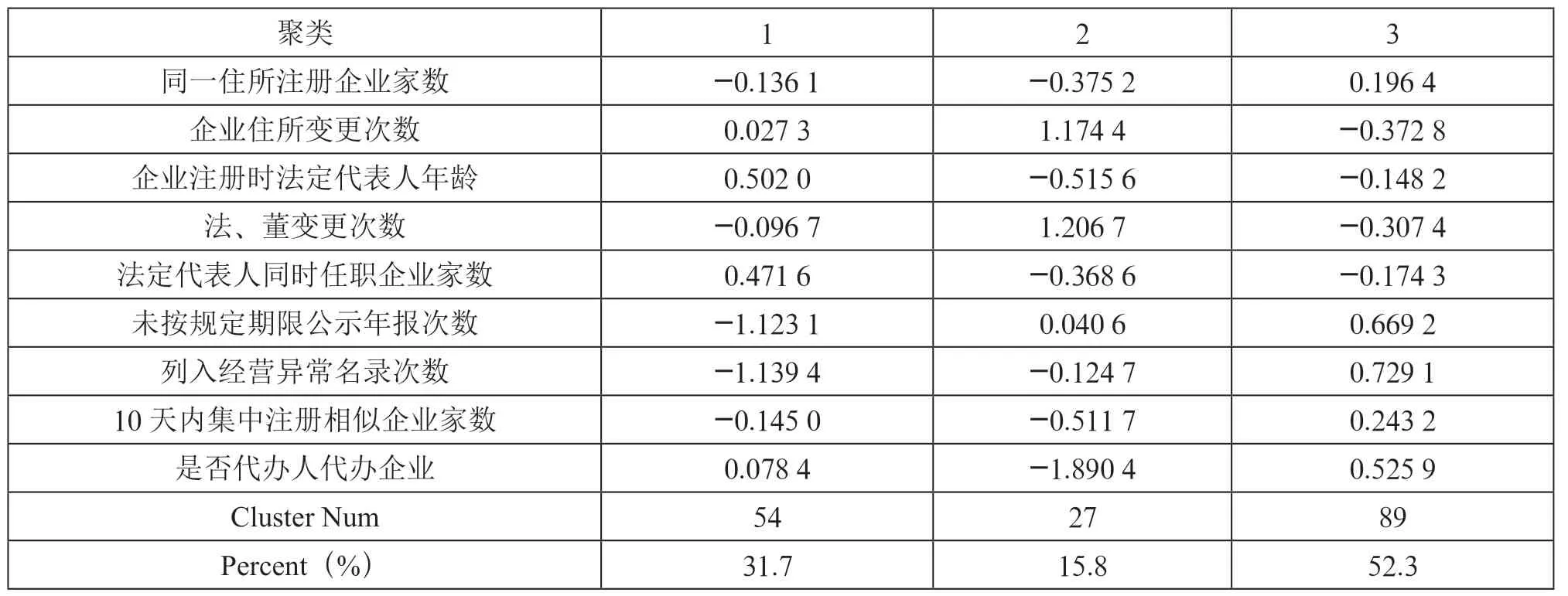
表2 K-Means 分类结果
2.2 构建企业虚假注册多元线性回归模型为了更好地描述虚假注册企业指标间的关系,采用多元线性回归方程验证的形式。基于聚类分析的结果,以“虚假注册企业数量”作为被解释变量,提炼各要素中的关键指标作为解释变量,构建多元线性回归模型,分析验证企业虚假注册行为与各指标存在的联系,进而实现对虚假注册企业及数量的预测分析。
2.2.1 模型构建
(1)变量定义。被解释变量:虚假注册企业数量。
解释变量:当年所有企业中注册地址超过3 家企业注册的企业数量,代办人代办企业数量,10 个工作日内集中登记的相似企业数量,法人、董事等高管变更3 次以上的企业数量,未报送企业年报的新设企业数量。如表3所示。
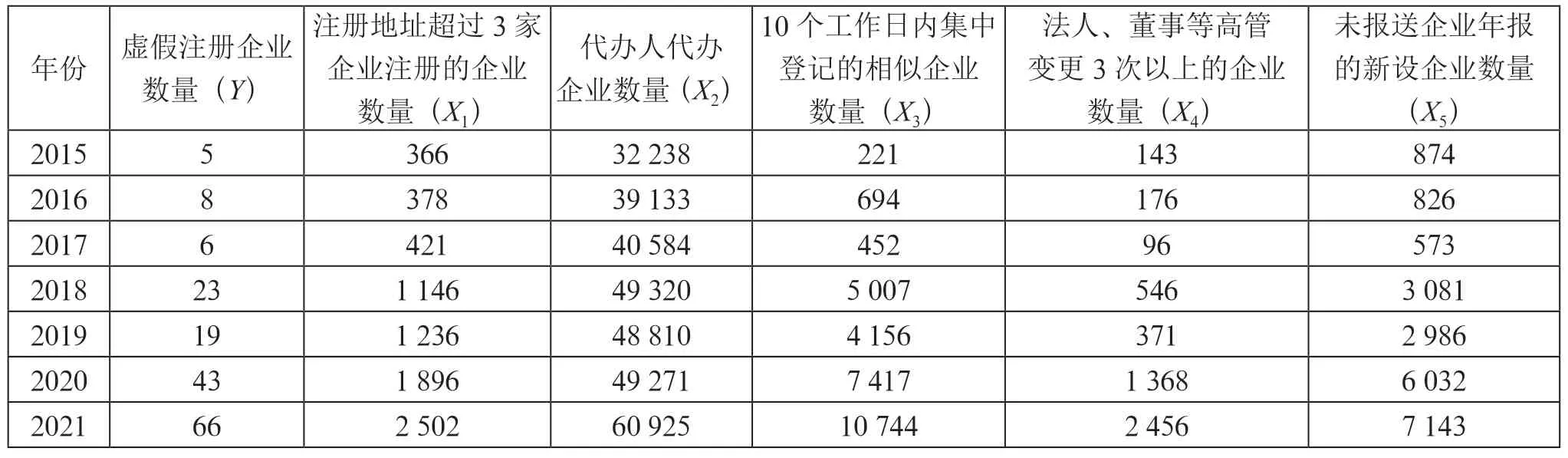
表3 企业虚假注册相关数据(2015—2021年)
(2)模型的数学形式。设定虚假注册企业与5 个解释变量相关关系模型,样本回归模型为:
Y=++++++∈
3)模型运算。应用Minitab 对模型进行估算,估算结果为:
首先对模型进行方差分析,结果如表4至表6所示。
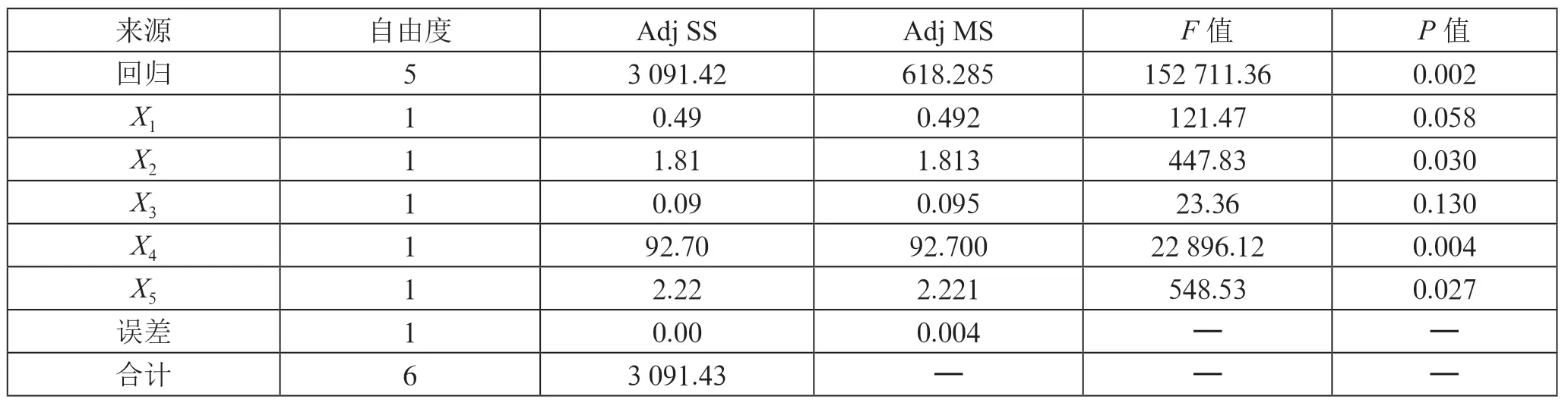
表4 方差分析
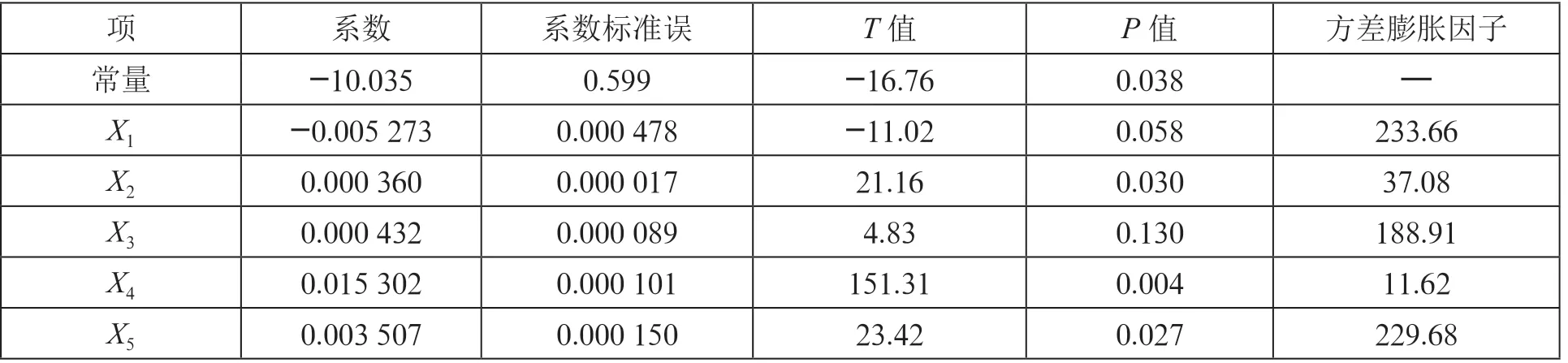
表6 系数
根据回归结果表中的数据,模型估计的结果为:

表5 模型汇总
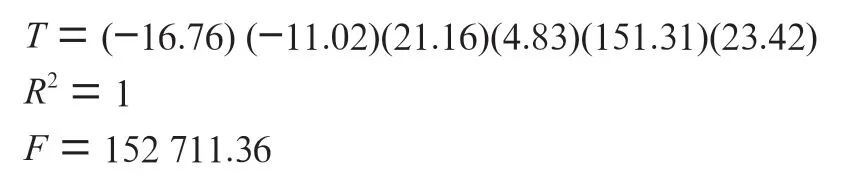
虚假注册企业数量的残差分析图如图1至图4所示。
图1 正态概率图
图2 拟合值
图3 直方图
图4 观测值顺序
2.2.2 模型检验
(1)经济意义检验:模型估计结果说明,在假定其他变量不变的情况下,当年注册地址超过3 家企业注册的企业数量每增长1 个,虚假注册企业数量就会增加0.005 273 家;在假定其他变量不变的情况下,代办人代办企业数量每增长1 个,虚假注册企业数量就会增加0.000 360 家;在假定其他变量不变的情况下,10 个工作日内集中登记的相似企业数量每增长1 个,虚假注册企业数量就会增加0.000 432 家;在假定其他变量不变的情况下,法人董事等高管变更3 次以上的企业数量每增长1 个,虚假注册企业数量就会增加0.015 302家;在假定其他变量不变的情况下,未报送企业年报的新设企业数量每增长1 个,虚假注册企业数量就会增加0.003 507 家。
(2)统计检验:
1)拟合优度检验:由回归结果得到=1,修正的可决系数为1,这说明模型对样本的拟合很好。
2)检验:针对:=====0,给定显著性水平=0.05,在分布表中查出自由度为-1=5 和--1 =1 的临界值F(5,1)=57.240,得=152 711.36 >F(5,1),所以拒绝原假设:======0,说明回归方程显著,即“注册地址超过3家企业注册的企业数量”“代办人代办企业数量”“10个工作日内集中登记的相似企业数量”“法人董事等高管变更3 次以上的企业数量”“未报送企业年报的新设企业数量”对“虚假注册企业数量”有显著影响。
3)检验:分别针对:β=0(=0,1,2,3,4,5),给定显著性水平=0.05,查分布表得自由度为=2 临界值t(-)=4.303。由回归结果的表可得,与、、、、、对应的统计量分别为-16.76、-11.02、21.16、4.83、151.31、23.42,其绝对值均大于t(),这说明分别都应该拒绝:β=0(=0,1,2,3,4,5),也就是说,当在其他解释变量不变的情况下,解释变量“年注册地址超过3 家企业注册的企业数量”“代办人代办企业数量”“10个工作日内集中登记的相似企业数量”“法人董事等高管变更3 次以上的企业数量”“未报送企业年报的新设企业数量”对“虚假注册企业数量”有显著影响。
2.2.3 结果分析
根据多元线性回归的基本方法,通过对初始线性回归模型的验证和分析,发现各变量与虚假注册企业数量具有显著关系。经企业虚假注册多元线性回归模型的计算结果得到各指标的权值结果如表7所示。

表7 指标权值
依据上述企业虚假注册风险预警模型指标与权值,对2022年全市所有注册企业进行评分,得到80 分以上的企业数量为0 家,60 分到80 分的企业为172 家,60 分以下的企业为67 378 家。依据评分结果,监管部门可对企业实施分类监管,并对172 家“疑似虚假注册企业”进行重点检查,提高监管靶向性和有效性。
3 结 论本文基于福州市市场监管预警平台归集整合的企业相关数据,初步构建了企业虚假注册风险预警模型,对虚假注册风险企业进行预警,为市场监管提供参考,有利于提高监管效率,取得良好成效。但在实际应用中,反映企业虚假注册的因素还有很多,如税务缴交、员工医社保缴交情况等,但囿于目前单位的数据协调与对接存在一定难度,未进行更深入的关联分析。同时,虚假注册样本量也比较有限,预警模型指标还有待进一步提升。下一步,我中心将基于福州市市场监管预警平台二期建设,进一步做好相关数据归集整合分析,并结合“疑似虚假注册企业”的检查结果,对指标模型进行不断修正和完善,提高企业虚假注册风险预警模型的准确性。