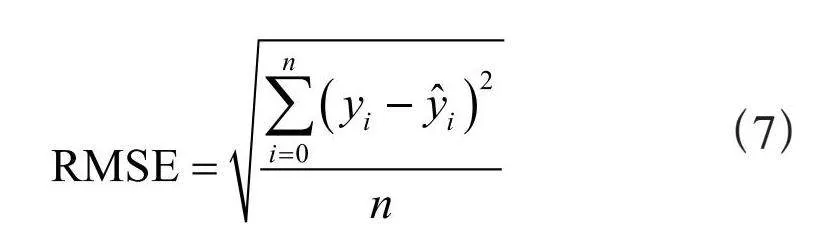
摘 要:针对小样本模型泛化性能不足的问题,引入元学习机制构建强泛化性的数据分析模型。使用BP神经网络建立数据分析模型,并使用模型无关元学习算法MAML对模型进行优化。结果显示,相比于传统模型(如支持向量机和高斯过程方法),文中所建立模型的泛化性能更好;针对MAML训练数据形式,引入数据增强方法增加训练数据数量,文中所建立模型的均方根误差、平均绝对百分比误差和决定系数分别为0.05、0.066和0.85,均优于其他预测模型。
关键词:元学习;优化;小样本模型;泛化性;模型无关元学习算法
中图分类号:TP183 文献标识码:A 文章编号:2096-4706(2024)08-0093-04
DOI:10.19850/j.cnki.2096-4706.2024.08.021
0 引 言
伴随人工智能技术的发展,机器学习数据分析在各行各业得到深入应用,如机械故障诊断[1]、结构健康监测[2]以及化工勘探研发[3]等。
然而在这些领域使用机器学习进行数据分析存在相同的问题:在样本较少的情况下,模型训练能表现出较高的准确率,但模型用作测试时准确率较低。这类问题可以简述为以机器学习方法建立的小样本模型的泛化性能不足。针对泛化性能不足的问题,可以从两个方向来解决:数据层面和模型层面。
从数据层面考虑,可采用数据增强的方法提升训练样本数量。条件生成对抗网络(CTGAN)[4]在生成对抗网络的基础上加入变分高斯混合模型学习数据特征分布,增强模型对数据特点的学习能力。结合有监督学习和无监督学习的小样本深度学习模型[3]能有效捕捉数据的结构特点,并结合数据增强方法改进表现。合成样本过采样技术可用于特征融合和权重结果实现。在实际应用中,监督学习方法[5]通常更容易实现、调整和优化,但过度使用则会导致模型更容易出现过拟合情况。条件生成对抗网络[6]能快速学习数据的分布,生成足够数量的虚拟样本,但生成样本的标签没有很好的判断标准,很容易加入杂质样本,影响模型泛化性能。两种方法各有优点和缺点,因此,本文使用监督学习和CTGAN互相搭配进行数据增强弥补单个方法的缺陷。
从模型层面考虑,可采用神经网络和优化算法进一步提升小样本模型的泛化性能表现。区别传统机器学习手动提取特征进行学习,神经网络通过神经元自动发现特征并进行学习的效率更高。此外,神经网络通过激活函数和多层神经元相连接,通过不同层的激活函数组合,可以更好地模拟非线性函数和复杂数据分布。在小样本模型优化算法中,元学习领域提出了模型无关元学习算法(Model-Agnostic Meta-Learning, MAML)[7],区别于传统的随机梯度下降(SGD)容易导致小样本模型出现过拟合情况,模型无关元学习算法优化数据的学习方式,通过算法内的双重优化提升小样本模型的泛化性能表现。
综上所述,本文以FRP加固混凝土柱为研究对象,提出基于数据增强和元学习机制优化小样本数据模型方法。通过数据增强和模型无关元学习算法改善小样本模型的泛化性能,以期在小样本数据限制下实现对小样本模型泛化性能的提升,为小样本数据的建模预测提供新思路。
1 数据来源
FRP加固混凝土柱数据来源于已有的玻璃纤维增强塑料加固混凝土柱研究[8,9],实验收集了3个数据集,共81组数据。每个数据集采用的柱高度均为500 mm,柱截面直径均为200 mm,试验均采用控制变量法研究了钢比、混凝土强度和玻璃纤维增强塑料厚度对混凝土柱承载力的影响。其中,钢比为混凝土柱中心垂直嵌入的钢筋截面面积占管柱截面面积比例,3个数据集分别采用水平截面不同形状的钢筋,分别为L型钢筋、C型钢筋和I型钢筋。
根据已有文献研究,将钢比、混凝土强度和径厚比作为输入变量,混凝土柱承载力作为输出变量进行建模,使用模型无关元学习算法进行优化处理。在元学习算法优化处理过程中,在单独一种形状的钢筋数据中,选择3组数据作为测试数据,余下24组数据作为训练数据。总的训练数据共72组,测试数据共9组。
2 BP神经网络基本原理及参数选择
BP神经网络是一种常见的反向传播神经网络,可以用于分类、回归和函数逼近等任务。它由一个输入层、若干个隐藏层和一个输出层组成,在训练过程中通过反向传播算法来调整网络权值,使得网络的输出结果与标准答案之间的误差最小化。
根据实验测得,BP神经网络的隐藏层神经元个数为5~20个,迭代次数为50~150次,学习率为0.001~0.010,BP神经网络的隐藏层输出激活使用Sigmoid函数,并使用L2损失函数防止网络过拟合。
3 模型无关元学习算法MAML
在元学习中,数据集划分为元训练集和元测试集。在元训练集中采样少样本量数据组成一个任务,MAML训练前需要采样若干个任务。一个任务中包含支持集和查询集,支持集用于MAML内循环优化,查询集用于MAML外循环优化。区别于传统学习,元学习的目标是在小样本上快速有效。针对训练的对象不是整个训练数据,元学习训练的是训练数据中的小样本量的任务。
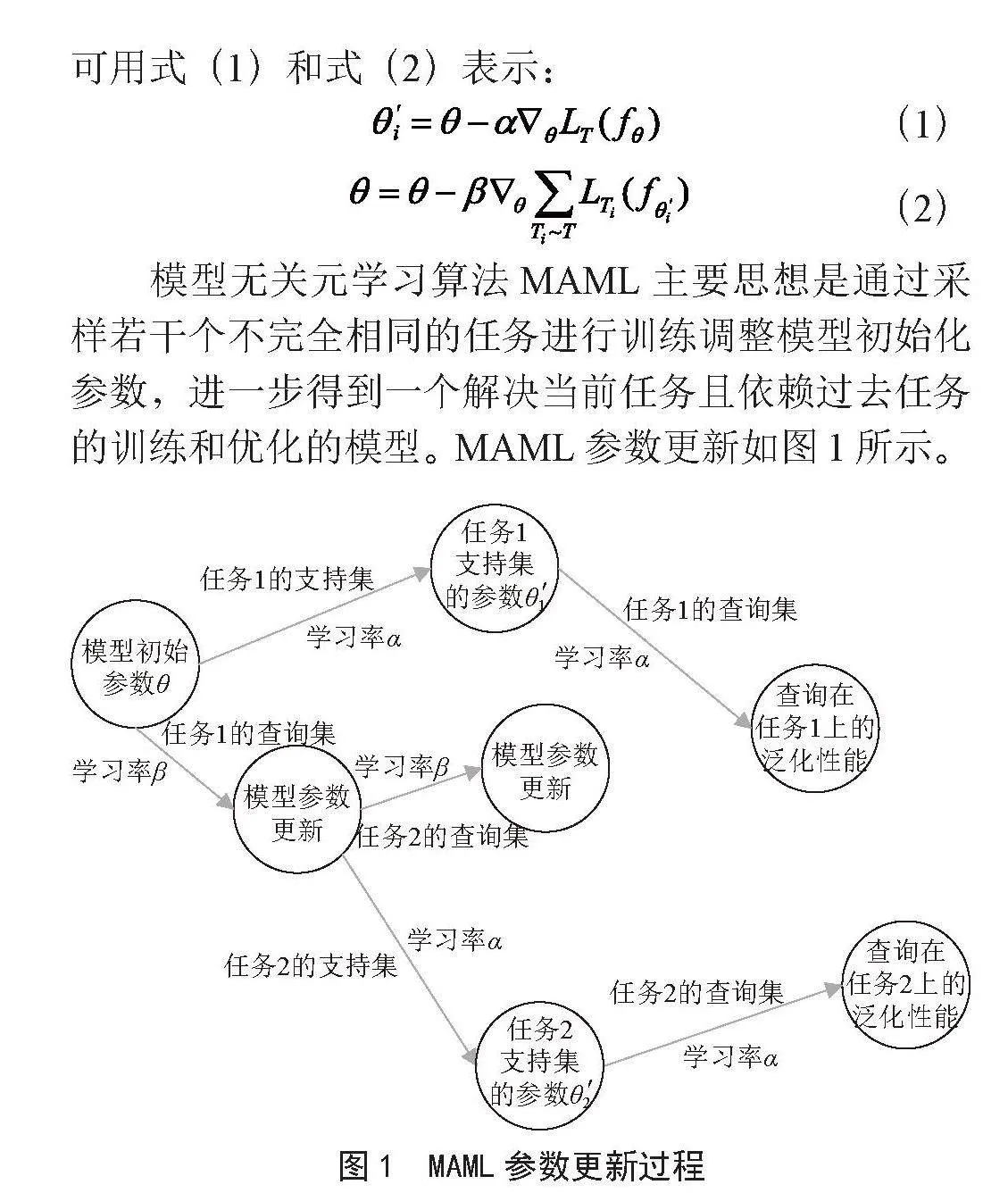
MAML训练过程包括内循环优化和外循环优化,可用式(1)和式(2)表示:
(1)
(2)
模型无关元学习算法MAML主要思想是通过采样若干个不完全相同的任务进行训练调整模型初始化参数,进一步得到一个解决当前任务且依赖过去任务的训练和优化的模型。MAML参数更新如图1所示。
结合式(1)(2)和图1,MAML算法优化的目标是,寻找到一组对不同任务最敏感的初始参数。最敏感初始参数在MAML算法中的体现为使用少量梯度下降就可以完成模型的收敛。具体表现在外循环更新模型参数θ时,使用的是内循环中适应任务支持集的参数" 计算任务查询集上损失进行梯度下降更新。区别于直接使用模型参数θ计算损失,得到的是在所有任务上的损失最小,并没有考虑到少量梯度下降过程。
由于本文数据样本量小,属于典型的小样本建模。结合数据特点,FRP加固混凝土柱数据按照钢筋的形状可分为3类任务,按照钢比可细化分为9类任务,相比于使用传统算法需要建立多个模型,MAML算法适用于多任务训练学习,因此FRP加固混凝土数据可以使用MAML算法进行优化学习。
4 基于CTGAN和弱监督学习的数据自增强方法
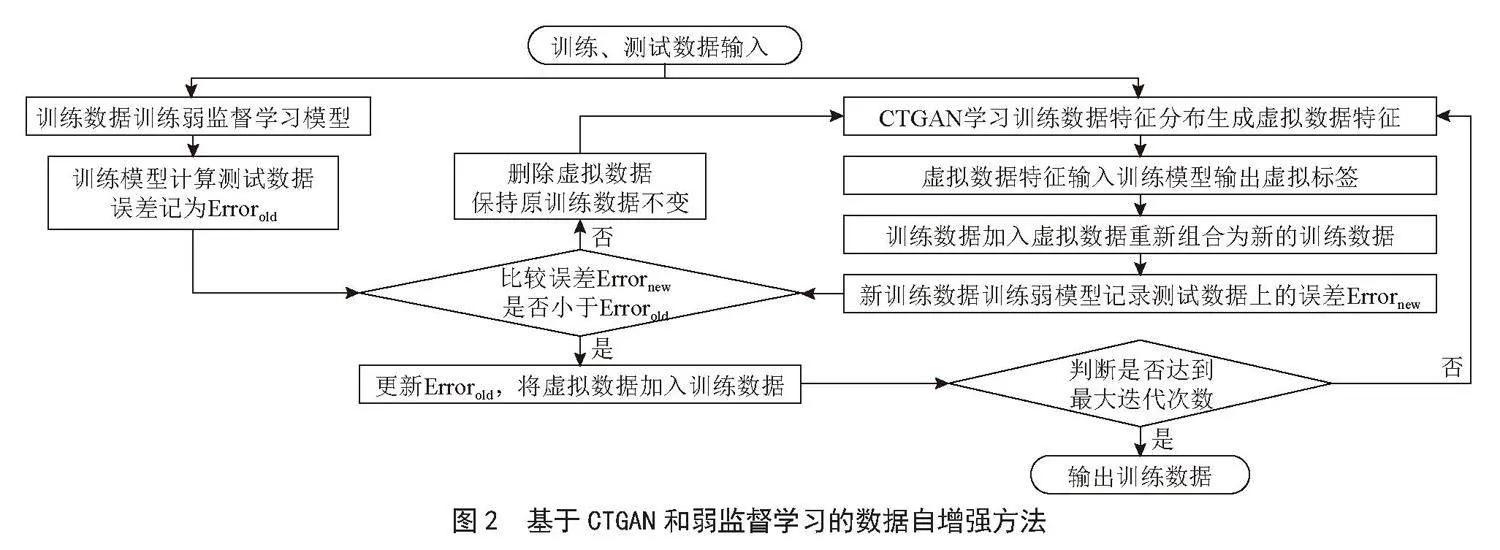
由于MAML算法优化训练的数据单位是任务,有针对性的任务数据增强对模型性能的提升是有效的。考虑集成学习对模型过拟合效果的改良,使用弱监督学习方法拟合FRP加固混凝土柱数据,并根据拟合效果分配模型权重,使用到的监督学习模型包括支持向量机、高斯过程回归。经实验验证,支持向量机和高斯模型的核函数参数均使用径向基核函数,所得虚拟样本效果最佳。基于CTGAN和弱监督学习的数据自增强方法流程图如图2所示。
具体过程如下所述:
1)数据准备:收集实验使用的复合结构数据共72组,按照混凝土柱内内置的增强材料形状划分为3类,每类按照特征值正交方式选取24组样本作为训练样本,每类余下3组样本作为测试样本。
2)监督学习:使用两类机器学习模型(支持向量机、高斯模型)对训练数据建模,并根据训练数据预测误差占比配置两类模型的权重构成组合模型,使用组合预测模型计算测试样本的预测误差,并记录此时的模型误差。
3)虚拟样本生成:使用CTGAN网络学习训练数据的特征分布,并按照任务的需求对特定特征值进行增强,将增强特征值输入组合预测模型得到虚拟样本标签。
4)样本合并训练:虚拟样本加入训练样本,组成新的训练样本训练,将新模型应用于测试样本计算测试样本误差,并记录此时的模型误差。
5)比较误差:若监督学习记录误差大于样本合并训练记录误差,则将监督学习记录的误差更新为样本合并训练记录的误差,并保存样本合并训练中的新的训练样本;否则删除虚拟样本生成的样本,重新执行虚拟样本生成。
重复迭代上述过程直至循环满足设置的迭代次数,退出循环,输出虚拟样本和原训练数据叠加的最终训练数据。
5 模型结果和分析
基于元学习机制优化小样本模型使用Scikit-Learn [10]中的Numpy库、Matplotlib库、Pandas库以及深度学习框架TensorFlow实现。第一组实验比较MAML算法、支持向量机算法与高斯过程回归算法对FRP加固混凝土柱数据的建模表现。在第一组实验完成后,使用TensorFlow中的模型保存函数保存训练完成的模型参数,方便下一组实验直接使用。第二组实验加入数据增强方法,比较数据增强前后3种算法的模型泛化性能变化。
FRP加固混凝土柱数据是多输入单输出数据集,为了避免输入特征量纲不统一对模型性能造成影响,对数据做归一化处理,使用Scikit-Learn中的输入特征处理Preprocessing库进行归一化处理。由于使用的FRP加固混凝土数据特征分布稀疏,Preprocessing库故使用MaxAbsCaler函数进行归一化处理。
使用3个不同的指标评估模型的性能:均方根误差(RMSE)、平均绝对百分比误差(MAPE)、决定系数(R2)。RMSE和MAPE解释了模型的准确性。R2分数使用模型测量了给定数据样本的解释变化。所有评估指标都使用Scikit-Learn来实现。
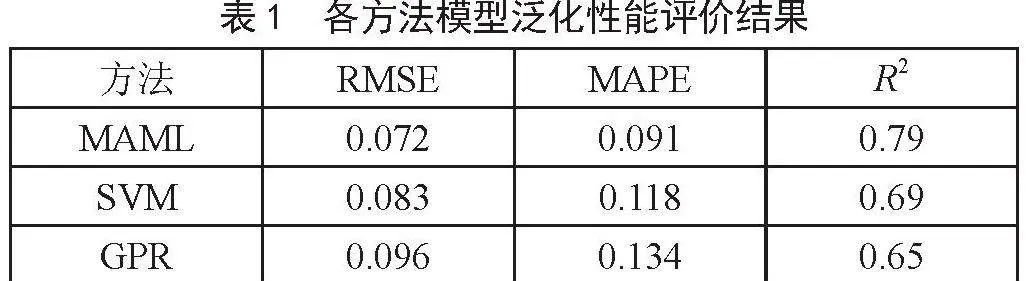
第一次实验使用钢比、混凝土强度、径厚比作为输入变量建立FRP加固混凝土柱承载力预测模型,与支持向量机模型和高斯过程回归模型进行对比,验证MAML算法在小样本模型上的优化效果,模型预测结果如表1所示。
如表1所示,本文模型在少量数据的训练下,使用元学习机制优化小样本模型泛化性能,RMSE和MAPE有所下降,复合柱承载力预测的准确度提高。相比于使用SVM和GPR建模分析,使用MAML算法优化的模型在均方根误差上分别降低了13.3%和25%,在平均百分比误差上分别降低了22.9%和32.1%。表明使用MAML算法在多任务上的优化效果要优于使用传统小样本建模算法SVM和GPR。
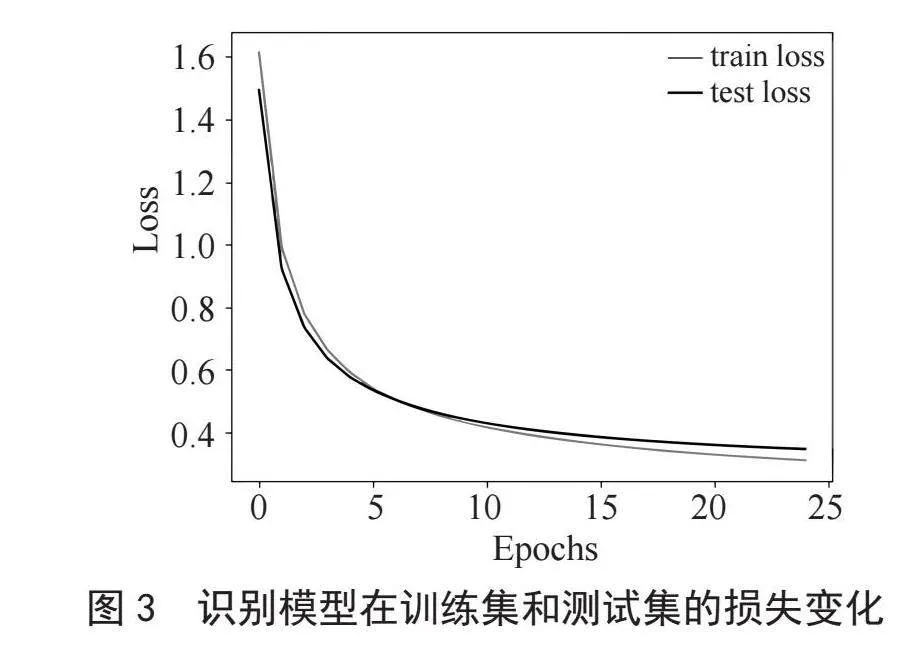
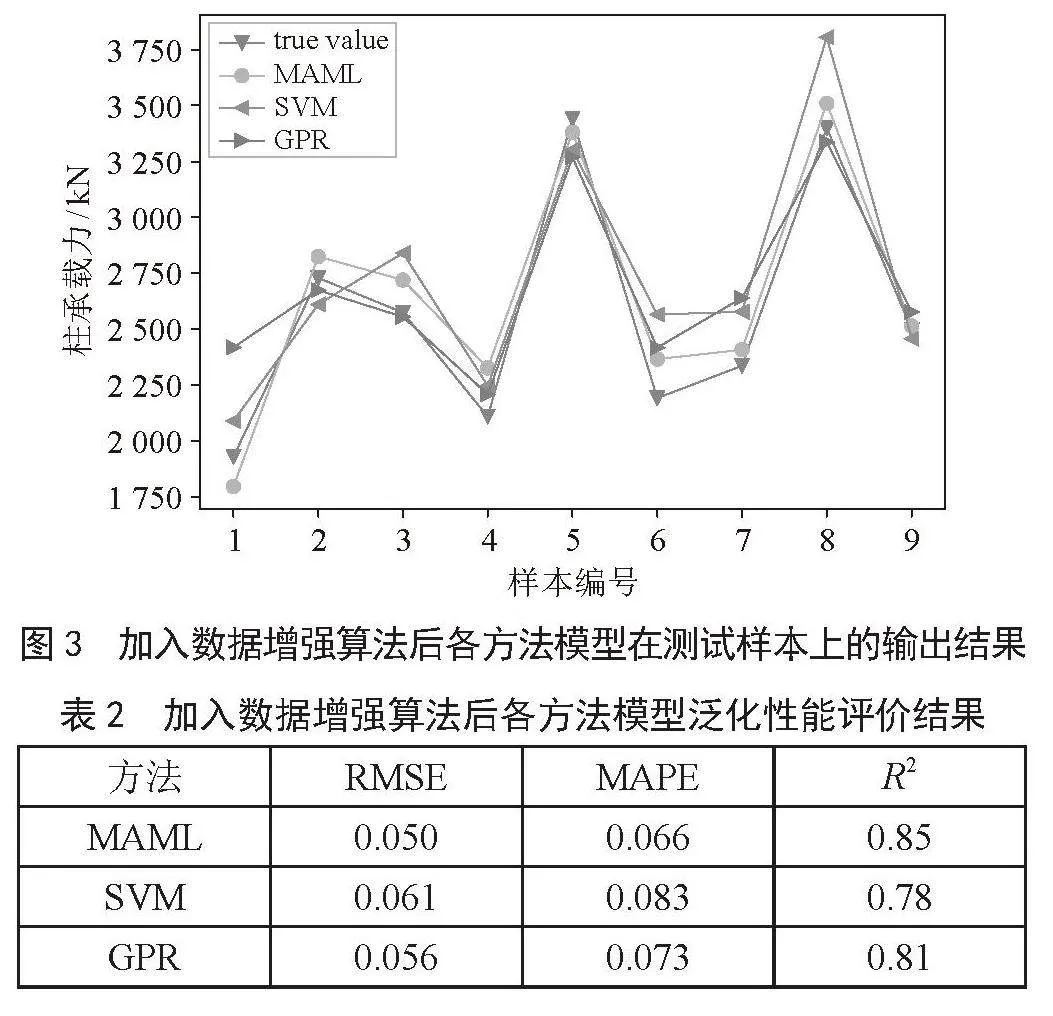
第二次实验加入数据增强算法,比较使用数据增强算法后,3种模型的性能表现,结果如图3和表2所示。
如表2所示,在加入数据增强算法后,基于3种方法的模型泛化性能均得到提升,其中加入数据增强算法后MAML算法优化的模型性能最佳,相比于未加入数据增强算法前,模型的均方根误差下降30.6%,平均百分比误差下降27.5%。
6 结 论
由于小样本模型泛化性能不足,且小样本模型预测准确度要求严格。因此本文提出了基于元学习机制的小样本预测模型,相比于使用支持向量机和高斯过程回归等优秀的小样本模型,本文提出的模型泛化性能高于另外两种模型。在加入数据增强算法后,本文提出的模型的泛化性能仍为最佳。然而不足的是,本文所提模型的泛化性能和模型结构优化仍是可以进一步提升的。下一步课题研究的方向将针对单类别小样本进行模型结构的探索和模型泛化性能的优化。
参考文献:
[1] 李阳涛,吴学勇,王彪.基于机器学习的轴承故障诊断研究 [J].机械管理开发,2023,38(2):53-54+57.
[2] 钟玉琪,张红,张舸,等.基于组合荷载响应特征融合的桥梁结构智能损伤识别方法 [J].实验力学,2023,38(2):151-164.
[3] ZHU L Q,ZHANG C,ZHANG C M,et al. Forming a New Small Sample Deep Learning Model to Predict Total Organic Carbon Content by Combining Unsupervised Learning with Semisupervised Learning [J/OL].Applied Soft Computing,2019,83:105596[2023-09-10].https://doi.org/10.1016/j.asoc.2019.105596.
[4] ZHAN W H,CHEN B W,WU X L,et al. Wood Identification of Cyclobalanopsis (Endl.) Oerst Based on Microscopic Features and CTGAN-Enhanced Explainable Machine Learning Models [J/OL].Frontiers in Plant Science,2023,14:1-19[2023-09-12].https://doi.org/10.3389/fpls.2023.1203836.
[5] 李萌,武海军,董恒,等.基于机器学习的混凝土侵彻深度预测模型 [J].兵工学报,2023,44(12):3771-3782.
[6] 刘言林.基于条件生成对抗网络的小样本机器学习数据处理算法研究 [J].宁夏师范学院学报,2021,42(10):66-73.
[7] 李凡长,刘洋,吴鹏翔,等.元学习研究综述 [J].计算机学报,2021,44(2):422-446.
[8] HE K,CHEN Y,XIE W T. Test on axial compression performance of nano-silica concrete-filled angle steel reinforced GFRP tubular column [J].Nanotechnology Reviews,2019,8(1):523-538.
[9] HE K,CHEN Y. Experimental evaluation of built-in channel steel concrete-filled GFRP tubular stub columns under axial compression [J].Composite Structures.2019,219:51-68.
[10] PEDREGOSA F,VAROQUAUX G,Gramfort A,et al. Scikit-learn: Machine Learning in Python [J].The Journal of Machine Learning Research,2011,12:2825-2830.
作者简介:邓天翊(1999—),男,汉族,湖北荆州人,硕士在读,研究方向:机器学习;张耕培(1984—),男,汉族,湖北荆州人,讲师,博士,研究方向:机器学习和深度学习。
收稿日期:2023-10-10
Research on Small-sample Model Generalization Performance Optimization
Based on Meta-Learning and Data Enhancement
DENG Tianyi, ZHANG Gengpei
(School of Electronic Information and Electrical Engineering, Yangtze University, Jingzhou 434023, China)
Abstract: To address the issue of insufficient generalization performance in small sample models, a Meta-Learning mechanism is introduced to construct a data analysis model with strong generalization. A BP neural network is used to establish a data analysis model, and Model-Agnostic Meta-Learning Algorithm (MAML) is used to optimize the model. The results show that compared to traditional models such as Support Vector Machine and Gaussian process methods, the model established in this paper has better generalization performance. Regarding the training data format of MAML, a data augmentation method is introduced to increase the amount of training data. The root mean square error, average absolute percentage error, and deciding coefficient of the model established in the paper are 0.05, 0.066, and 0.85, respectively, which are superior to other prediction models.
Keywords: Meta-Learning; optimization; small sample model; generalization; MAML