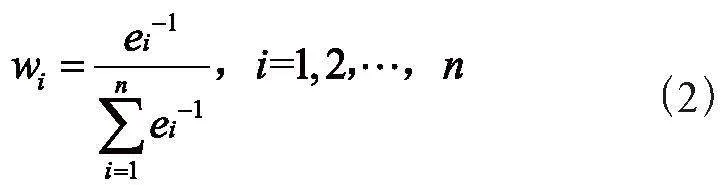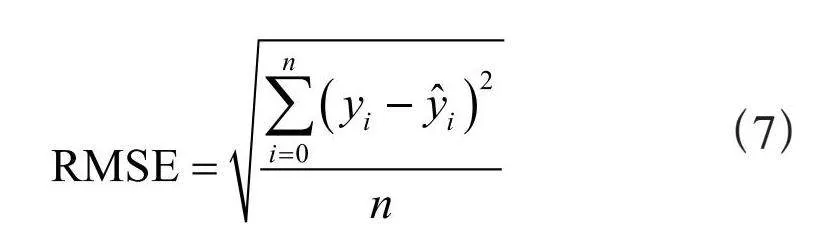

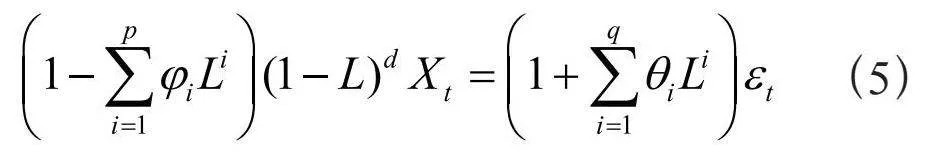
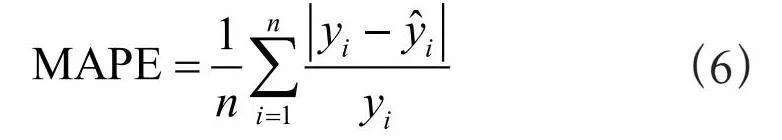
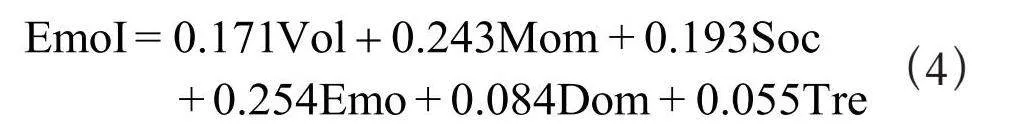
摘" "要:相较于传统金融产品,比特币价格更容易受到情绪的影响而展现出更高的波动性,为此价格预测具有极高的研究价值。为提高比特币价格预测的精准度,文章在预测模型中引入情绪指标,构建融合情绪分析和Informer-ARIMA模型的预测方法。从多维度分析价格时间序列的随机波动、循环变化、周期变化等变化规律,对比特币的价格进行有效预测。测试结果表明,融合情绪分析的Informer-ARIMA模型性能更优,验证了所提方法的可行性和有效性。
关键词:Informer-ARIMA模型;情绪分析;长时序预测;比特币价格预测
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)09-0131-05
A Bitcoin Price Prediction Method Integrating Emotional Analysis and
Informer-ARIMA Model
ZHANG Yabo, CHEN Chunhui
(Fujian University of Technology, Fuzhou" 350118, China)
Abstract: Compared to traditional financial products, the price of Bitcoin are more susceptible to emotional influence and has higher volatility, making price prediction has highly research value. To improve the accuracy of Bitcoin price prediction, this paper introduces emotional indicators into the prediction model and constructs a prediction method that integrates emotional analysis and Informer-ARIMA model. Analyze the random fluctuations, cyclic changes, and periodic changes of price time series from multiple dimensions, and make effective predictions on the Bitcoin price. The test results indicate that the Informer-ARIMA model, which integrates emotional analysis, performs better, verifying the feasibility and effectiveness of the proposed method.
Keywords: Informer-ARIMA model; emotional analysis; long time series forecasting; Bitcoin price prediction
0" 引" 言
比特币是一种基于点对点(Peer To Peer, P2P)形式的去中心化加密货币,其独特的生成与交易机制导致其价格表现出极端的波动性。这吸引了无数投资者,探寻预测其价格变化趋势的方法也成为学者们的研究目标。
在量化投资预测领域,机器学习和深度学习等技术也被引入并应用于多项任务证明这一研究方向的可行性。诸多学者将统计学模型和机器学习模型运用于加密货币价格预测问题并进行有效尝试。张宁在长短期记忆网络(Long Short-Term Memory, LSTM)模型的基础上构建了四种混合模型,使用小波变换和自适应噪声的模态分解方法分解重构了时间序列数据,并引入样本熵重构优化使得预测误差降低[1]。莫世冰将Transformer算法引入加密货币价格预测领域,并建立基于小波分析的ARIMA-Transformer组合模型。对比特币的价格进行时间窗口滚动式预测,取得与实际价格走势相近的结果,证明这一研究思路的可行性[2]。
但是仍存在一个问题,即在输入序列超过一定长度时,模型预测效果会急剧衰退,难以获得准确的效果。Zhou提出基于Transformer结构的Informer模型,为长序列预测问题提供新的解决方案。经过改良的Informer模型对比Transformer模型具有更低的时间和空间复杂度、更高的输出速度和更高的准确度[3]。
本文将Informer模型改良应用于比特币的价格预测问题上,引入情绪指标构建Informer-ARIMA模型,使得其在这一问题表现出超出其他同类预测模型的效果[4,5]。
1" 方法描述与构建
1.1" 理论基础
本文在方法的构建过程中引入了基于Transformer结构的Informer模型。
1.1.1" Transformer结构
Informer模型是基于Transformer结构改进的高效的长时间序列预测模型。常规的Transformer模型多应用于自然语言处理(Natural Language Processing, NLP)领域,其自注意力机制处理大量信息时更加关注局部信息而不是全局信息[6]。Transformer在NLP和计算机视觉(Computational Vision, CV)领域相较于经典的CNN和RNN模型都表现地更为出色。Transformer相较于经典模型的优势在于序列中点与点之间的最大路径是最短的,无须考虑它们在序列中的距离就可以对输入输出序列的依赖项进行建模。Transformer模型计算两点之间的关系所需要的操作次数不随距离增长,并突破RNN模型不能并行计算的限制[7]。
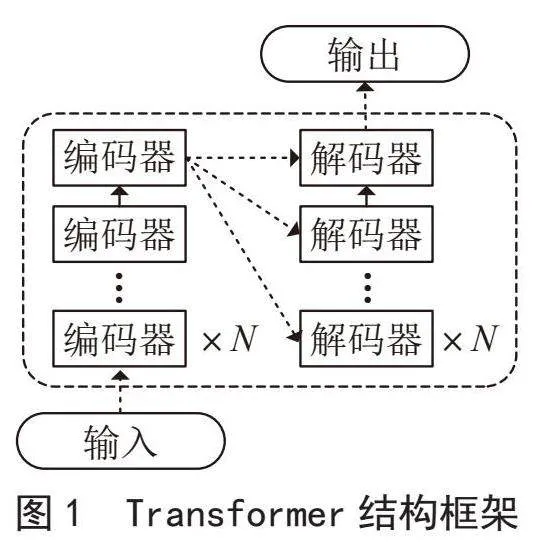
Transformer结构主要由一堆编码器(Encoder)和解码器(Decoder)构成。如图1所示,模型分为输入、编码器、解码器和输出四个部分,在输入模块输入一个序列A = [a1,a2,…,an],编码器、解码器利用输入序列A = [a1,a2,…,an]进行线性变换,Softmax函数向输出模块提供一个状态集B = [b1,b2,…,bn]。
1.1.2" Informer模型的编解码结构
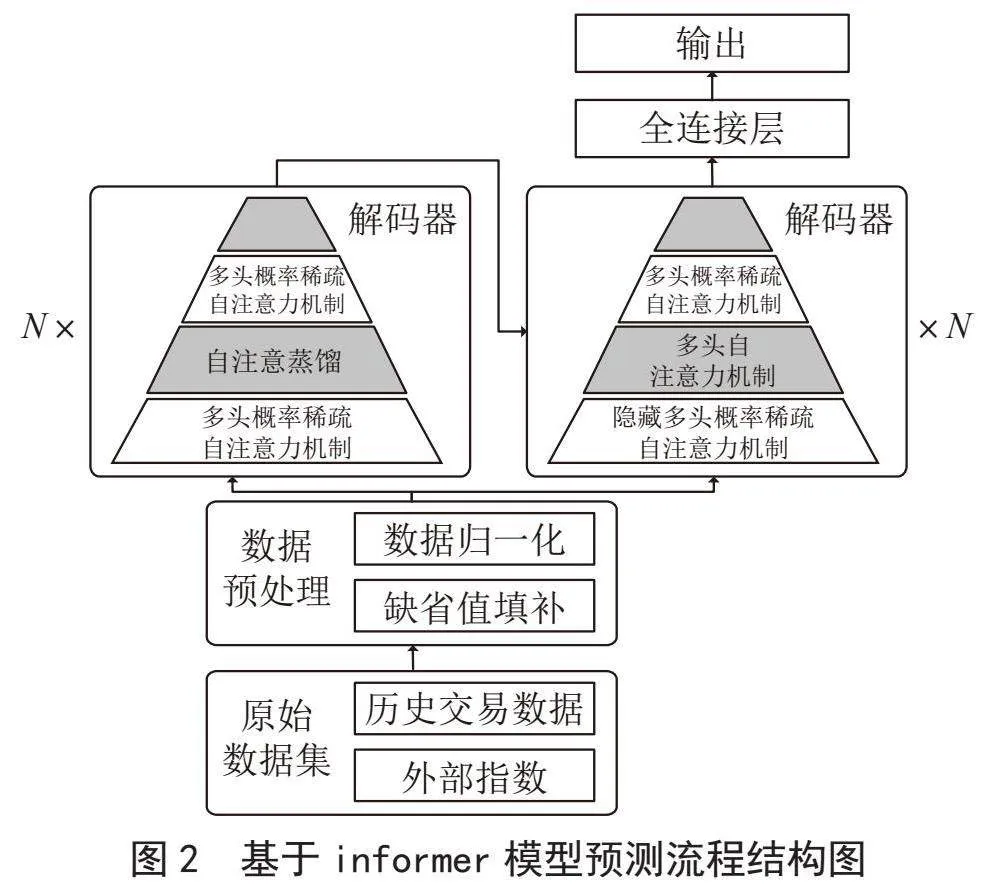
Informer是基于注意力机制的监督学习模型,其核心是Informer基于注意力机制的监督学习模型。每一层的编码器中都由有多头概率稀疏自注意力机制和自注意蒸馏两个子层构成,每一层解码器都由包含掩码多头概率稀疏自注意力机制和多头自注意力机制两个子层构成[3]。
编码器提取了输入数据中的隐含的长期依赖关系,其核心是概率稀疏自注意力机制。这一机制对主要注意有重大贡献的查询矩阵进行筛选并赋予其更高的权重,使模型更加关注重要信息。多头自注意力机制不仅可以在单一表现空间中学习到相关信息,还可以关注来自不同表现子空间的重要信息,从而获取更全面的信息。自注意力蒸馏机制使用一维卷积操作和池化操作降维输入序列,使每层的解码器都可以将输入序列的长度缩短一半,降低了空间复杂度和时间复杂度。
在解码器的部分中使用了一个标准的decoder结构,其由两个一样的多头注意层组成的。多头概率稀疏自注意力机制可以防止每个时间只注意到下一个位置而忽略了未来的信息,从而避免自回归。生成式解码器使用一个全连接层一步式生成全部预测序列,大大降低了预测的时间复杂度,也避免了误差在预测中的累计。
基于Informer的预测模型整体结构如图2所示,编码器在接收到大量长序列数据后,利用自注意力蒸馏机制降低了网络复杂度。这种机制通过层层叠加结构增强了模型的鲁棒性。解码器接收长序列输入后,通过将目标元素置零并测量特征图的加权注意力组合,输出生成式格式的结果。
1.1.3" Informer模型的自注意力机制
自注意力机制是所有Transformer结构模型的核心,通过将序列中任意两个位置之间的距离化为一个常量有效地捕获信息间的长距离依赖关系,非顺序计算结构良好的并行性使其在不同场景下的任务表现优秀。注意力机制利用Key和value记录已学习的参数,同时查找query得到模型的输出。根据query和相应的Key计算出每个value的权重公式:
注意力函数输出矩阵公式:
Transformer的性能比经典模型更为优秀,但是依然存在预测效率低、计算复杂和内存占用过大的问题。Informer模型提出了概率稀疏自注意力机制解决了计算复杂度高的问题。其先通过KL(Kullback-Leibler)散度公式筛选出对注意力值有主要贡献的查询矩阵,再进行缩放点积运算,计算公式:
式中,Q为模型筛选出的少数对注意力值贡献比重较大的查询矩阵,K为键矩阵,V为值矩阵,d为Q、K及V的维数。经过改进,Informer在保证较高预测能力的前提下降低了计算的复杂度,提升了模型的计算效率[8]。Informer模型展现出在长时间序列预测问题上的潜力,因此本文将Informer模型运用到比特币的价格预测问题上。
1.2" 情绪指标的构建
RoBERTa是文献《RoBERTa: A Robustly Optimized BERT Pretraining Approach》中提出的BERT的强化版本,也是BERT模型更为精细的调优版本。
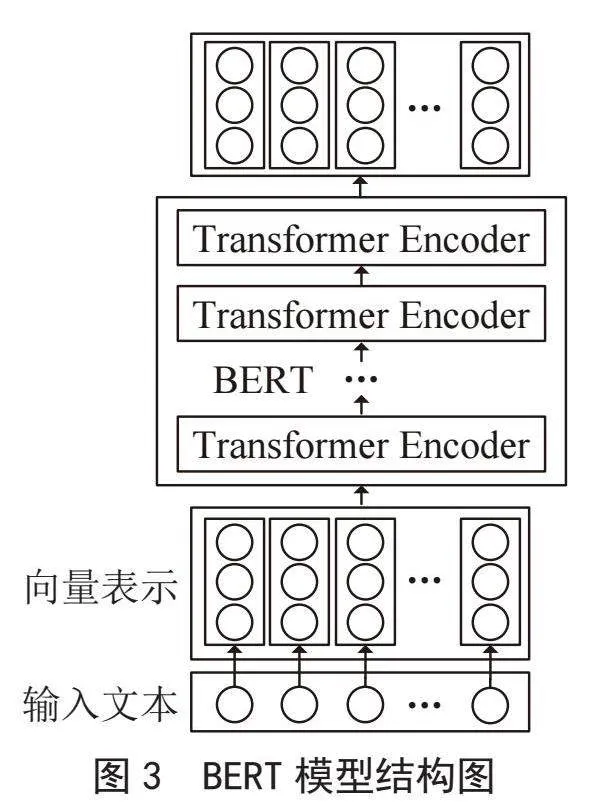
BERT的创新之处在于使用Transformer Decoder(包含Masked Multi-Head Attention)作为提取器。BERT运用了一种独特的掩码训练方法。尽管这种设计使得BERT不具备文本生成能力,但在对输入文本进行编码的过程中,BERT能够充分利用每个单词的所有上下文信息。与此相比,传统的单向编码器只能利用前序信息提取语义[9,10]。因此,BERT在语义信息提取方面具有更强的能力。多个Transformer Encoder一层一层地堆叠起来就组成了BERT模型,如图3所示。
为构建能反映加密货币市场情绪变化的指标,选取以下几种市场数据中包含的因素:
1)波动率:对比特币的当前波动率和最大成交额进行测量,并与过去30天和90天的相应平均值进行比较,本文认为波动率异常上升是市场恐慌的迹象。
2)市场成交量趋势:测量当前比特币的交易量和市场动量,并将这两个值与过去30/90天的平均值进行比较,当市场上的购买量显著提升时,得出当前市场表现得过于贪婪/过于乐观的结论。
3)社交媒体活跃度:收集并统计多个社交媒体中各种相关标签上的帖子,监测它们在特定时间段内的交互速度和数量。互动率的上涨表明公众对比特币的兴趣增加,本文认为,这与市场的贪婪情绪相对应。
4)社交媒体情绪值:收集并统计多个社交媒体中各种相关标签上的帖子,并使用深度学习模型进行情绪分析,得到这些帖子的相关情绪极性。本文认为一段时间内帖子的情绪积极/消极反应出市场的贪婪/恐惧。
5)加密货币主导优势:加密货币的主导地位就是某单一币种在整个加密市场市值的份额占比。特别是对于比特币,这种主导地位更加明显。本文认为比特币主导地位的上升是由于担心市场未来走势从而减少投机性过高的加密货币替代投资,因此投资比特币逐渐成为加密货币投资者的稳妥选择。另一方面,当比特币的主导地位减弱时,说明投资者越来越贪婪,更多的资金用于投资风险更高的币种,梦想着在下一轮牛市中有机会获取更高的利润。本文认为,分析比特币及其他货币在加密货币中的主导地位可以预测特定货币涨跌。
6)搜索引擎趋势:查询提取与加密货币相关联的谷歌趋势数据和百度搜索数据,并处理这些数据,特别是相关词条搜索量的突然变化以及推荐的其他当前流行搜索关键词可能预示着市场异动。本文认为搜索引擎趋势变化反映出市场投资者获取信息的主动程度。
本文采用主成分分析法加权度量当前加密货币市场的投资者情绪,并将其压缩成一个从0到100的简单计量表。0表示“极度恐惧”,而100表示“极度贪婪”。极度恐惧可能表明投资者过于担心,那可能是一个买入机会。当投资者变得过于贪婪时,这意味着市场需要调整。指标加权公式为:
(4)
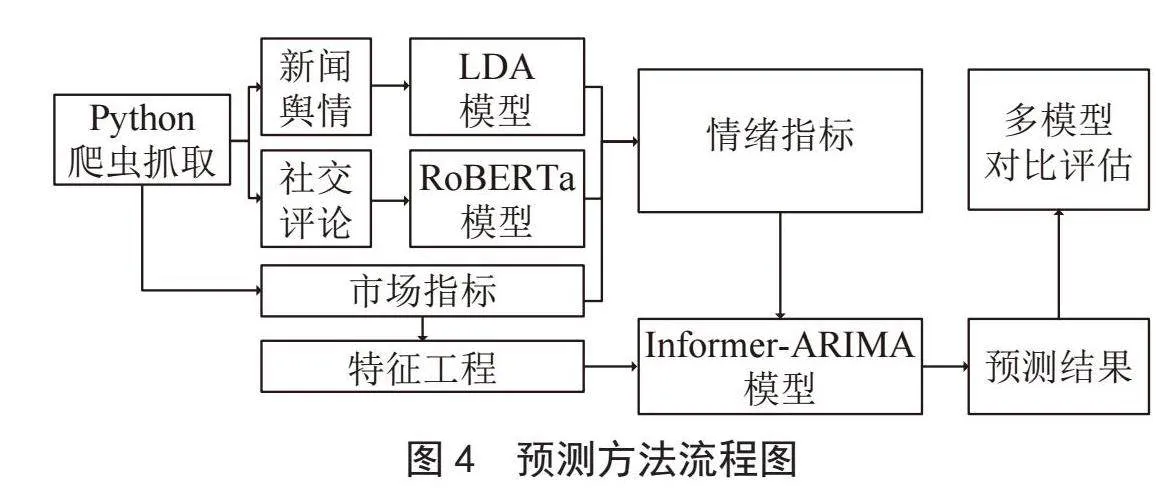
1.3" 预测方法构建
预测方法流程如图4所示。首先将预处理过的文本数据作为RoBERTa模型的输入,生成带有反映市场情绪的时间序列输出,再将该序列与加密货币市场序列整合成模型所需的目标序列。将目标序列标准化处理作为Informer模型的输入序列,通过概率稀疏自注意机制着重对高得分点积对进行关注,从而有效减少模型的时间和空间成本。通过自注意力蒸馏机制提取到稳定的长期特征,通过生成式解码器来获取输出序列避免多步预测中累积误差的扩散。最后通过加权拟合差分整合自回归移动平均模型(Autoregressive Integrated Moving Average model, ARIMA)算法预测序列来得出最后的预测结果,即对加密货币价格走势的预测。
1.4" 差分整合自回归移动平均模型
ARIMA时序预测领域应用最为广泛的统计学模型。将输入数据序列表达为{Xt},其模型ARIMA(p,
d,q)表达式如下:
式中,p为自回归阶数,d为差分阶数,q为移动平均阶数,Xt为时间序列中第t期的值,L为时间序列中每一期的滞后算子, 为AR参数, 而为MA参数。
ARIMA模型的本质就是把时间序列数据中趋势性、季节性、带有业务场景周期性的规律先找出来并模型化,最后的数据就剩下没有规律的噪声,理想的时候是白噪声。最后使用通过检验的模型对资产价格进行预测。
2" 实例分析
2.1" 实验环境与数据
实验环境为Python 3.6,PyTorch 1.8框架,处理器为AMD Ryzen 75800H with Radeon Graphics 3.20 GHz,显卡为NVIDIA GeForce RTX 3060 Laptop GPU,内存16 GB,操作系统为Windows 11,64位操作系统。
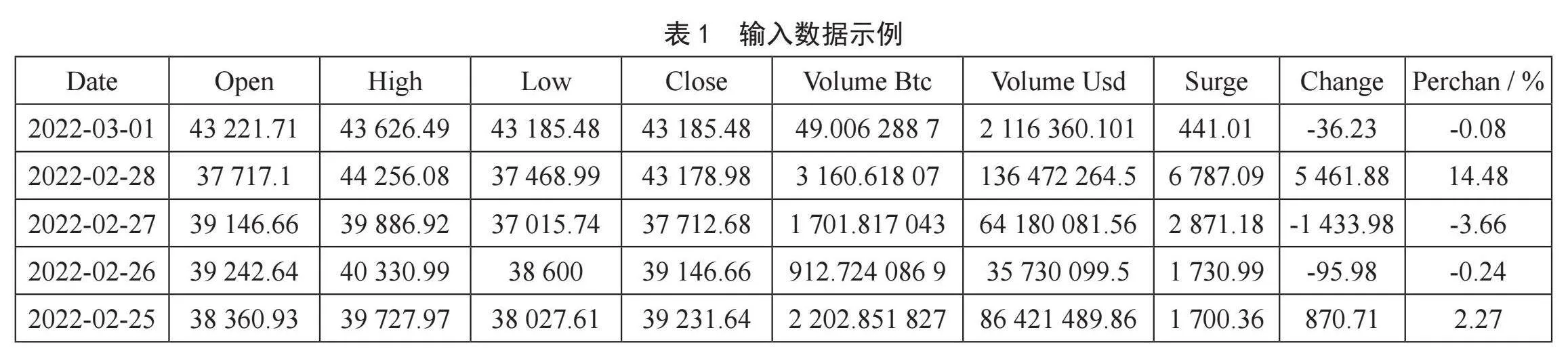
实验选取2017-03-01至2022-03-01的Binance交易所比特币以日作为颗粒度单位数据格式,选取每日收开盘价格、每日最高成交价格、每日最低成交价格、成交价跨度,涨跌幅和交易量作为模型运算数据。数据集格式示例如表1所示。
2.2" 数据预处理
模型利用过去t天的价格数据,对未来f天的价格走势进行窗口滚动式的时间序列预测。为提高模型预测精度,对数据进行归一化处理,并将缺省值使用差值填充。处理后的序列不但使信息更加集中清晰,而且保存了信息的时频特征,在模型中能获得更好的效果。
2.3" 实验评价标准
选择两个性能指标:平均绝对百分比误差(Mean Absolute Percentage Error, MAPE),均方根误差(Root Mean Square Error, RMSE),来评估所用模型和各个对比模型的预测能力。在多模型实验下,观察实际的序列和预测的序列的拟合效果:
式中,yi为实际值; 为模型输出的预测值;n为测试数据的长度,MAPE的值越小,说明预测模型具有更高的精确程度。
式中,yi为实际值; 为网络输出的预测值;n为测试数据的长度,RMSE的值越小,说明预测值与真实值直接的误差越小,模型精确性越好。
2.4" 实验结果与分析
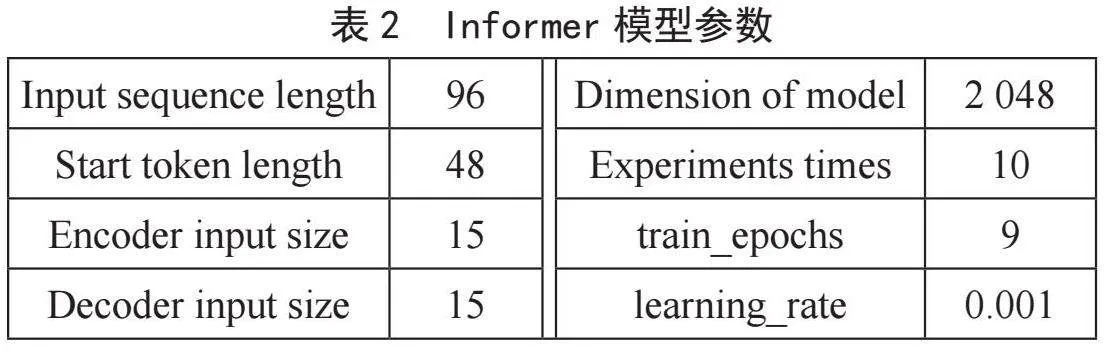
实验于使用PyTorch深度学习框架实现,多种模型基于Python库Darts实现。通过构建不同模型生成的图像拟合程度与评价指标判断模型效果优劣。并通过修改不同的批尺寸、学习率、迭代次数来确定模型的最佳的参数以获得最优的效果。经多轮实验调试后的Informer模型参数如表2所示。
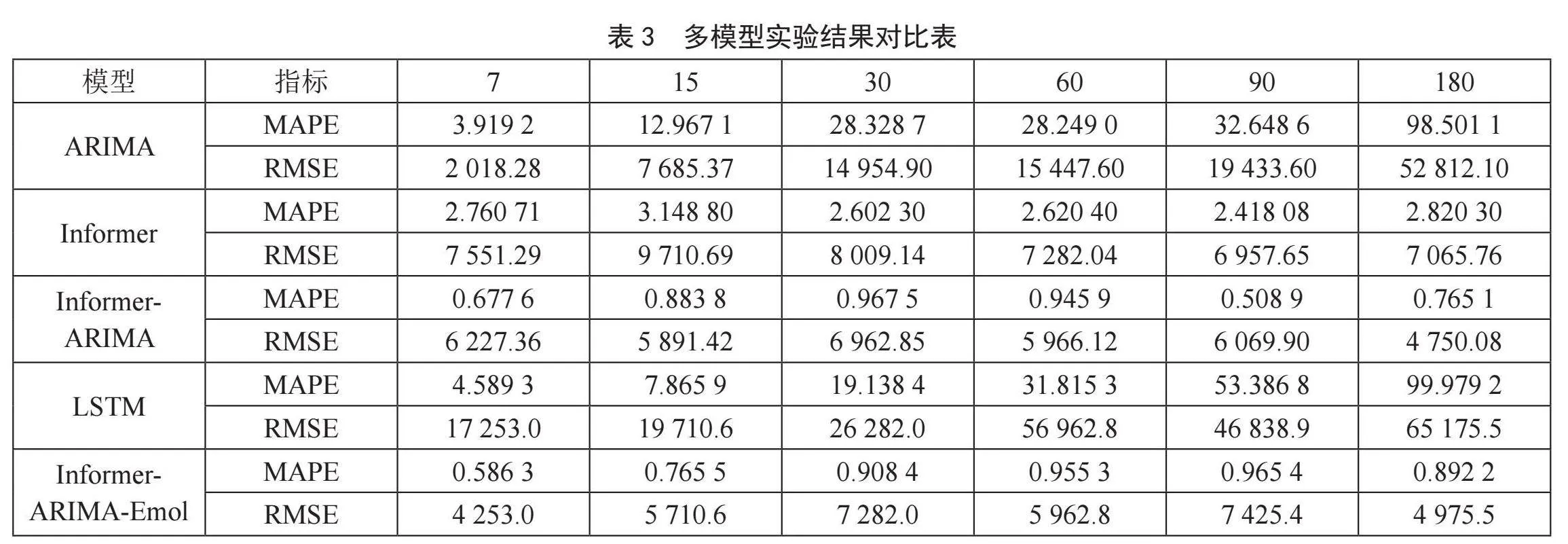
多模型实验对比结果如表3所示,Informer模型始终能够获得较高的拟合度,而且Informer模型的误差更小。在多种预测序列长度下Informer模型在预测精度与稳定性上表现均强与单一ARIMA和LSTM,而混合模型Informer-ARIMA则在多个实验下取得了更好的效果。ARIMA与LSTM模型的预测效果随预测序列的增长呈现断崖式下滑,Informer模型更为稳定,这在长序列预测上更为明显。在引入情绪指标后的实验结果如表3所示。
随着预测序列长度的增加,Informer模型在对长时间序列预测问题上表现出超越其他模型的效果。其在解决输出和输入之间由于距离长而导致依靠关系没有被很好捕捉的问题的同时优化了原来Transformer 中的注意力机制的时间和空间复杂度,使得Informer模型可以得到较高的预测精度。由表3可知,在所设计的实验条件下Informer-ARIMA预测方法的预测精度最高。其中,LSTM模型方法在该实验环境预测的精度较低。Informer-ARIMA组合模型比单一模型展现出更优的预测精度,在长序列预测上的效果也更好。引入情绪指标后使得模型的预测能力得到进一步的提升。
3" 结" 论
文章将基于Transformer 改进的Informer模型与ARIMA相结合用于比特币价格预测问题,来满足该问题对长序列预测问题精度的需要,并通过引入情绪指标进一步提升了预测能力。通过比较所提模型与基准模型在不同预测范围下的效果,结果表明:就文中实验环境下的预测效果而言,本文提出的模型效果更优,其有效地捕获到了输入与输出之间的长期依赖关系。该方法提高了预测的准确性,可在金融投资活动中发挥指导作用。
参考文献:
[1] 张宁,方靖雯,赵雨宣.基于LSTM混合模型的比特币价格预测 [J].计算机科学,2021,48(S2):39-45.
[2] 莫世冰,林晖竣,陈云伟,等.基于小波分析的Arima-Transformer组合模型的比特币价格预测 [J].现代信息科技,2022,6(3):32-35.
[3] ZHOU H Y,ZHANG S H,PENG J Q,et al. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting [EB/OL].[2023-08-06].https://arxiv.org/pdf/2012.07436.pdf.
[4] 吴明晖,张广洁,金苍宏.基于多模态信息融合的时间序列预测模型 [J].计算机应用,2022,42(8):2326-2332.
[5] 牛红丽,赵亚枝.利用Bagging算法和GRU模型预测股票价格指数 [J].计算机工程与应用,2022,58(12):132-138.
[6] 李龙祥,彭晨,李军,等.基于Informer的城市住宅区负荷预测研究 [J].怀化学院学报,2022,41(5):48-53.
[7] 刘洪笑,向勉,周丙涛,等.基于Informer的长序列时间序列电力负荷预测 [J].湖北民族大学学报:自然科学版,2021,39(3):326-331.
[8] 董浩,孙琳,欧阳峰.基于Informer的PM2.5浓度预测 [J].环境工程,2022,40(6):48-54+62.
[9] 陈雪松,毛佳昕,马为之,等.中西方媒体报道各国疫情的对比及情感分析方法研究[J].计算机学报,2022,45(5):993-1002.
[10] 王珊,黄海燕,乔伟涛.基于Reformer模型的文本情感分析 [J].计算机工程与设计,2022,43(4):1089-1095.
作者简介:张雅波(1997—),男,汉族,吉林白山人,硕士在读,研究方向:物联网与智慧管理;陈春晖(1974—),男,汉族,湖南衡阳人,副教授,博士,研究方向:数据、模型与决策。