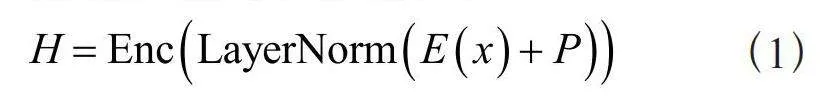
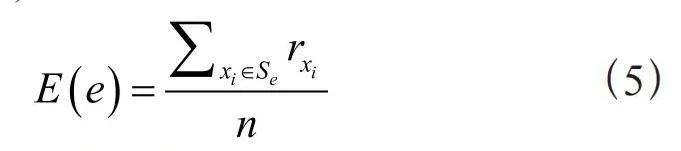
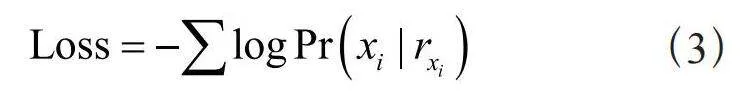
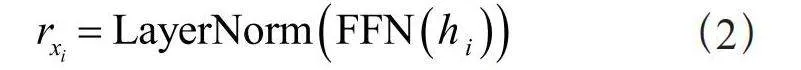

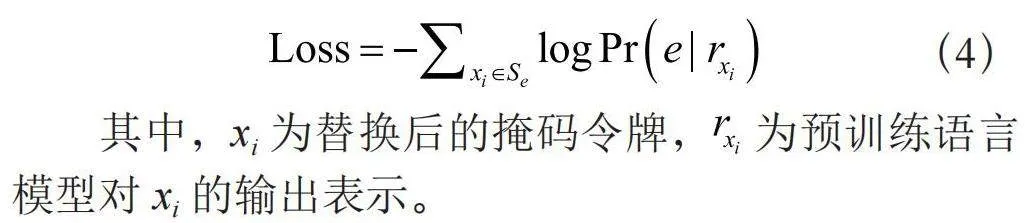

摘" 要:石油炼化领域中的命名实体识别任务存在着标注数据稀缺,以及现有的预训练语言模型不能很好识别领域组合和嵌套实体的问题。基于此,首先提出一种基于外部实体知识的数据增强方法(EEKR),通过引入外部实体知识库,将其与标注数据中的实体进行实体级别替换完成数据增强,有效解决标注数据稀缺的问题。之后提出了基于内部实体知识的命名实体识别模型(IIEKNER),通过获取标注样本中的内部实体嵌入,将内部实体知识融入预训练模型,从而可以更准确地识别出石油炼化领域中的嵌套和组合实体。实验结果显示,相比于其他模型,基于EEKR数据增强方法的IIEKNER模型的识别效果更优。
关键词:命名实体识别;石油炼化领域;数据增强;BERT
中图分类号:TP391.1" 文献标识码:A" 文章编号:2096-4706(2024)12-0040-07
Named Entity Recognition in Petroleum Refining Domain Based on Entity Knowledge
DING Jianxin1, WANG Xiaowei2, WEN Xin1, QU Kejiang1, WANG Jianhua1, ZHAO Yanhong1, HU Siying2
(1.Smart Oil Services Business Unit, Kunlun Digital Technology Co., Ltd., Beijing" 100071, China; 2.College of Information Science and Engineering/College of Artificial Intelligence, China University of Petroleum (Beijing), Beijing" 102249, China)
Abstract: Named entity recognition task in the petroleum refining domain suffers from the problems of scarcity of labeled data as well as the existing pre-trained language models cannot recognize domain combination and nested entities well. Based on this, a data augmentation method EEKR (External Entity Knowledge Replacement, EEKR) based on external entity knowledge is firstly proposed, which effectively solves the problem of scarcity of labeled data by introducing an external entity knowledge base and completing data augmentation by replacing it with entities in the labeled data at the entity level. After that, a named entity recognition model IIEKNER (Namd Entity Recognition Incorporating Internal Entity Knowledge, IIEKNER) is proposed, which incorporates internal entity knowledge into the pre-training model by obtaining internal entity embeddings in the labeled samples. Thus, nested and combined entities in the petroleum refining domain can be recognized more accurately. The experimental results show that compared to other models, the IIEKNER model based on EEKR data augmentation method has better recognition performance.
Keywords: named entity recognition; petroleum refining domain; data augmentation; BERT
0" 引" 言
命名实体识别(Named Entity Recognition, NER)[1]是指从文本中识别出具有特殊意义的词汇或专有名词。其不仅需要识别出命名实体的边界,还需要将其分类到正确的实体类型中。命名实体识别的结果可用于构建知识图谱,用户可从中检索和使用所需要的知识,同时为文本理解、智能问答[2]等下游任务提供数据支持。
近年来,石油炼化领域快速发展,在发展过程中累积了大量的文档。这些文档的存储和管理通常以非结构化形式实现,它们构成了石油炼化领域的大型语料库。命名实体识别主要抽取装置、设备以及工艺技术等实体。
石油炼化领域的命名实体识别面临着两个问题:第一个问题是数据集的问题,由于该领域缺乏标注好的公开数据集,导致深度神经网络模型不能很好地发挥作用。因此,如何在少量标注数据下实现准确识别命名实体亟待考虑和解决;第二个问题是该领域存在大量嵌套命名实体,这些命名实体给该领域命名实体识别任务带来很大挑战,例如句子“目前在流化床催化裂化中,广泛应用的是合成无定形硅酸铝催化剂。”其中的“流化床催化裂化”“无定形硅酸铝催化剂”很难被精确识别。
因此,首先需要解决石油炼化领域命名实体识别任务存在的缺乏大规模标注数据集问题,传统的数据增强方法[3]会造成石油炼化领域目标实体丢失和无效扩充的问题。为此,设计一种专门针对石油炼化领域的数据增强方法是很有必要的,本文提出了外部实体知识的数据增强方法EEKR(External Entity Knowledge Replacement)。该方法通过引入外部实体知识库,将其与标注数据中的实体进行实体级别语义理解替换从而进行数据增强,这种增强数据中的实体是真实且属于石油炼化领域,可以有效解决标注数据稀缺的问题。之后,针对现有的预训练语言模型不能很好识别领域嵌套实体的问题,本文提出了IIEKNER(Namd Entity Recognition Incorporating Internal Entity Knowledge)模型。该模型基于标注样本中的内部实体知识,首先对实体知识进行定义并获取领域实体知识,之后向预训练语言模型融入实体知识。该模型可以有效识别石油炼化领域的嵌套实体。本文的主要贡献包括:
1)提出EEKR数据增强方法,利用外部的实体知识进行数据增强,有效解决领域内样本稀缺问题。
2)设计了IIEKNER模型,通过融合内部实体知识,有效解决领域内嵌套实体的实体问题。
3)构建了石油炼化领域数据集,同时通过实验对比,基于EEKR数据增强方法的IIEKNER模型在石油炼化领域取得了显著的成效。与其他模型相比,我们的模型具有更高的精确率、召回率和F1值。
1" 相关工作
在命名实体识别的研究中,按照其适用领域可以划分为两类,一类是通用领域,另一类是垂直领域,如医疗领域、有色冶金领域、航空安全领域等。垂直领域的实体区别于通用领域,有着领域的专业性和独特性,难以直接使用通用领域的模型。
在英文医疗领域中,Li等基于BERT多特征融合进行医学命名实体识别[4]。Landolsi等采用通过周围序列匹配的命名实体标记,添加提示序列信息,提高了F1值[5]。Le等人通过使用特定领域的语义类型依赖作为额外知识[6],有效提升了医疗临床文本命名实体识别的准确率。Wang等提出了一种结合BERT预训练模型和BilSTM-CRF模型的新模型改进识别效果[7]。在中文医疗领域,针对医疗文本研究首先是电子病例的命名实体识别研究[8],之后是公开的中文医疗语料库的构建。Lee等提出了一种基于多嵌入增强多图神经网络[9],结合多特征融合方法,有效解决了中文医疗命名实体识别任务存在的样本不平衡、实体多样性和语言多样性等问题。Zhu等将多个BiLSTM模型和BERT结合[10],实现了在取得较好识别效果的同时花费更少的训练时间。Xiong等为提升临床医疗文本的实体识别效果,提出了一种基于关系图卷积网络的方法[11]。An等提出了一个基于多头自注意的双向长短期记忆条件随机场(MUSA-BiLSTM-CRF)模型[12],提升了模型性能。
在航空安全领域,孙安亮等[13]采用双向长短期记忆模型、卷积神经网络和条件随机场,构建了一种使用字符与词两个粒度的模型,可以有效提高航空安全领域命名实体识别效果。在电网调度领域,毛宏亮等[14]提出一种融合多头注意力机制和双向长短时记忆网络的中文命名实体识别方法,较好解决了电网调度领域实体识别任务中标注数据稀少和精度较低的问题。在有色冶金领域,贵向泉等[15]提出了一种基于机器阅读理解框架和知识增强语义表示模型的MEAB模型结构,在有色冶金领域取得了显著的成效。
2" 命名实体识别方法设计
2.1" EEKR数据增强方法
传统的数据增强方法如同义词替换方法,替换的单词是随机的,这些单词不一定是石油炼化领域实体,不一定可以让模型学习到更多的石油炼化领域实体特征,虽然通过替换可以丰富句子的结构,但是预训练语言模型已经在大量语料上进行了预训练,从中学习了中文句式和语法规则,所以同义词替换对预训练语言模型的效果十分有限。此外,在石油炼化领域中,由于分词不准确和存在大量组合嵌套实体的原因,利用分词无法准确获得全部目标实体,如果利用上述方法,会导致错误的词语替换,消除语料库中原有的实体,影响研究的准确性。
基于上述分析,本节提出了基于外部实体知识的数据增强算法EEKR,通过引入外部实体知识库,将其与标注数据中的实体进行实体级别语义理解替换从而完成数据增强。具体思想为:用Word2Vec获得词语的词向量,与腾讯中文词汇和短语向量中的向量进行相似度计算,返回结果最相近且大于阈值的向量对应的词语,对于出现未登录词(OOV),采用人工方式处理。EEKR算法流程为:首先将需要处理的句子复制n (m + 1) - 1遍,其中n为句子中实体个数,m为扩充规模,将复制后的句子原实体依次替换成原实体语义理解的结果。EEKR算法具体步骤如下:
输入:包含实体的语句集合Sentences,扩充规模m
输出:扩充后的语句集合Result
FOR(Sentence IN Sentences)
统计Sentence中实体的个数n及其位置loc
将Sentence复制n (m + 1) - 1加入临时句子集合temp_s
FOR(temp IN temp_s)
根据loc将Sentence中实体按实体及其同类词的语义相似程度大小依次替换
END FOR
将temp_s加入Result,将temp_s清空
END FOR
部分词语的语义理解结果如表1所示,对于命名实体“油藏”而言,其语义理解结果最相近的三个命名实体为“储层”“油气藏”和“水平井”。
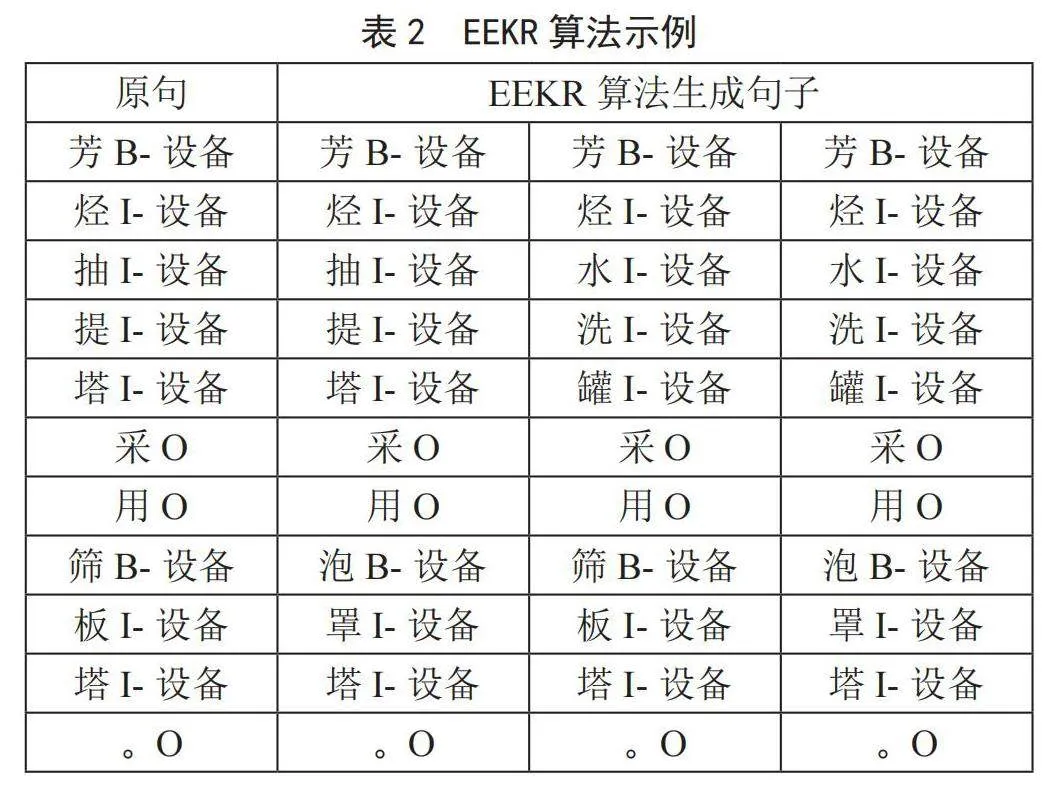
例如当扩充规模为1时,处理的句子为“芳烃抽提塔采用筛板塔。”时,EEKR算法处理结果如表2所示。原句包含两个命名实体:“芳烃抽提塔”和“筛板塔”,将原句复制三遍。由于“芳烃抽提塔”为嵌套实体,在腾讯中文词汇和短语向量中找不到与该实体相似度大于阈值的向量,我们对该实体后半部分实体“抽提塔”进行语义理解,由于扩充规模为1,得到“水洗罐”,对于“筛板塔”,经过语义理解得到“泡罩塔”,将复制的三个句子中的实体部分进行替换。
2.2" IIEKNER模型
预训练语言模型的出现极大地提升了自然语言处理各项任务的性能,最新的一些研究表明,预训练语言模型通过自我监督的预训练,从大规模语料库中获取知识,再将学习到的知识编码用到模型参数中[16-18]。在石油炼化领域命名实体识别任务中,存在很多嵌套和组合实体,现有的预训练语言模型不能充分地从模型参数中获取实体知识,所以不能准确地识别这些实体。
为了使预训练语言模型能够准确地识别嵌套和组合实体,需要提高预训练语言模型对实体的理解能力。如果从知识图谱、实体描述、语料库中获取外部实体知识,将外部实体知识嵌入与原实体进行对齐,虽然提高了模型对实体的理解能力,但是这些方法没有从预训练语言模型出发研究实体嵌入,导致学习到的实体嵌入映射缺少领域适用性。如果通过采用相关的预训练任务来加强实体表示,将实体知识注入预训练语言模型的参数中,则需要巨大的预计算,大幅增加了命名实体识别等下游任务的成本。
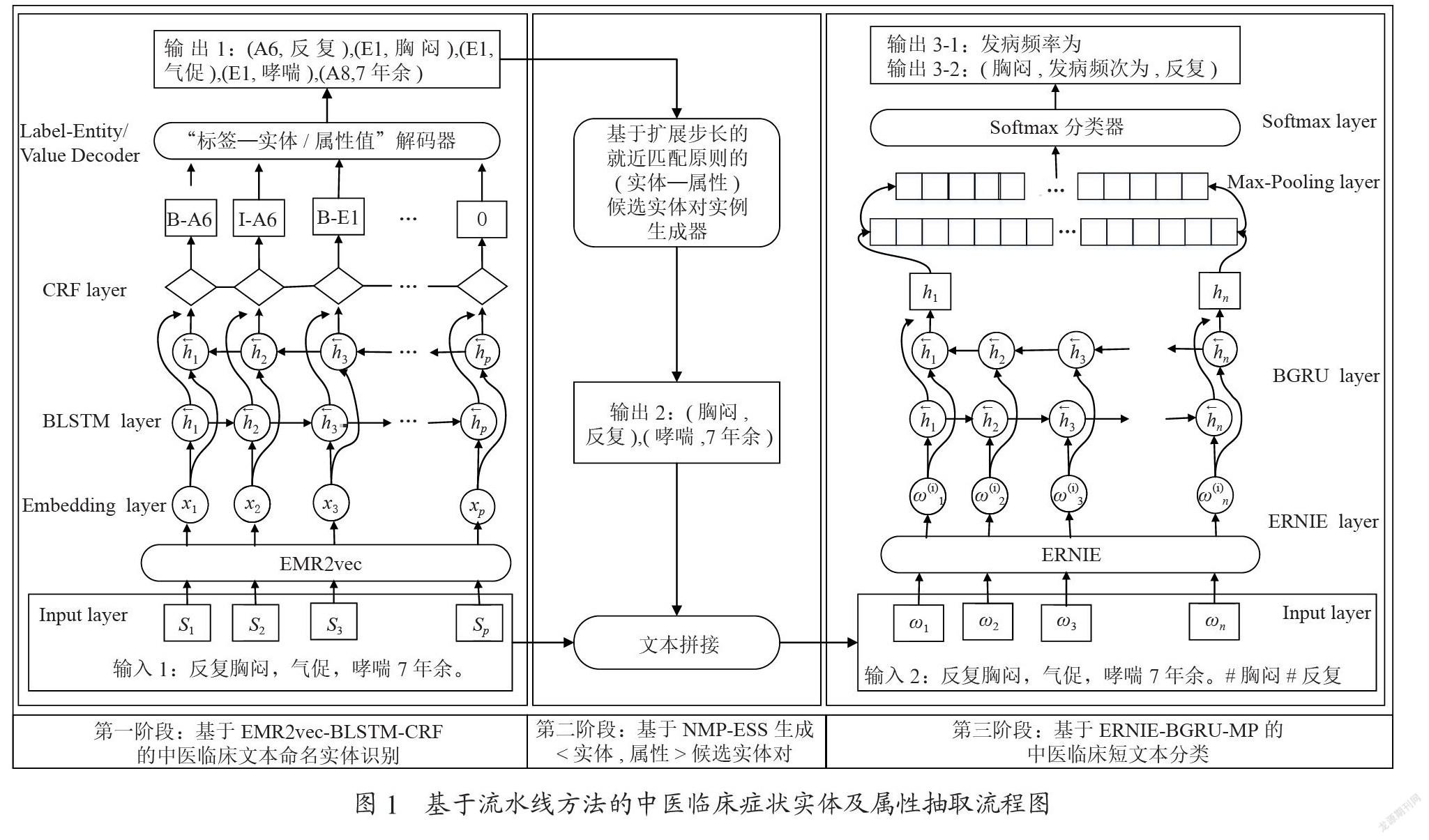
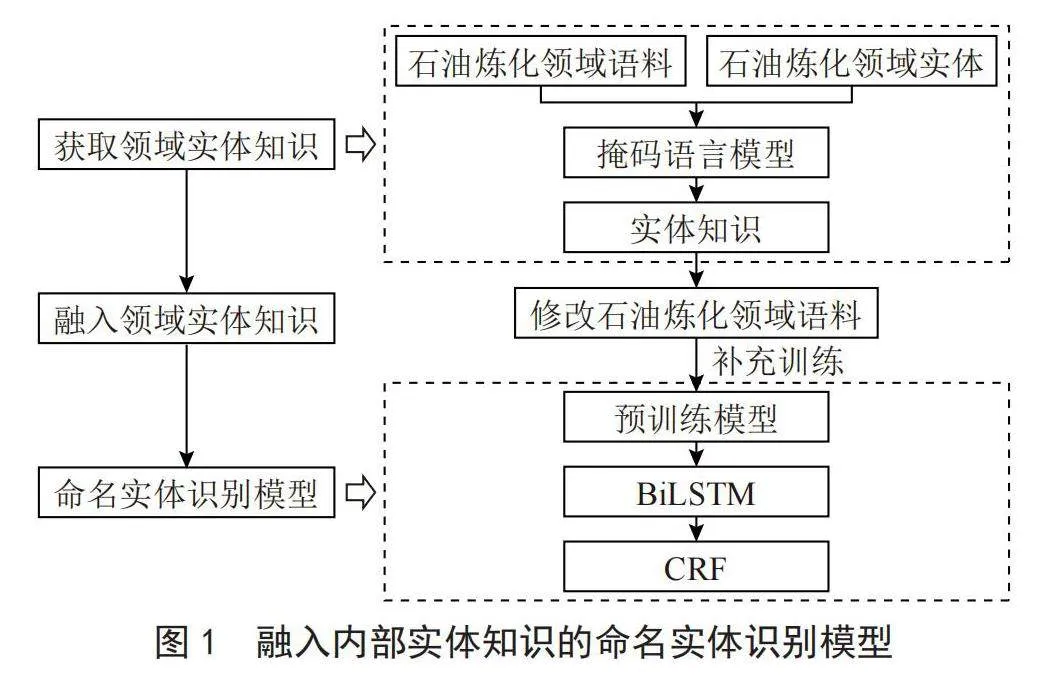
IIEKNER模型从预训练语言模型方向出发研究实体嵌入,通过掩码策略巧妙获取实体嵌入,通过改变实体向量映射将实体知识融入预训练语言模型,不需要改变预训练语言模型的其他参数。具体流程如下:首先通过第2.2.1节的方法获取领域实体知识,然后通过第2.2.2节的方法将领域实体知识融入模型中,从而提升模型对石油炼化领域命名实体的识别效果。整个流程如图1所示,图中左边为简略流程,右边为详细流程。
2.2.1" 获取领域实体知识
预训练语言模型通过自监督预训练任务,从大规模未标记语料库中学习语义和语法任务[19],例如掩码语言模型(Masked Language Model, MLM)。该模型可以看作是完形填空任务,首先掩盖掉输入序列中的token,模型根据上下文表示预测被掩盖的token。该模型可以形式化表述为:给定一个符号序列X = (x1,x2,…,xn),将xi替换成[MASK],BERT等预训练语言模型将token的词嵌入和位置嵌入作为输入,得到其上下文表示,如式(1)所示:
(1)
其中,Enc(⋅)为Transformer编码器。
获得上下文表示后,BERT等预训练语言模型利用向前反馈网络(Feedforward Neural Network, FFN)和层归一化来计算xi的输出:
(2)
由于Softmax层的权重和词嵌入绑定在BERT等预训练语言模型中,模型首先计算" 与输入词嵌入矩阵的乘积,进一步计算xi在所有词之间的交叉熵损失:
(3)
由于训练效率的不同,常见预训练语言模型的词汇量通常在30 000到60 000之间,这些模型必须将大量实体的信息分散到子词嵌入中。通过分析式(3)中的掩码语言模型损失,可以直观地观察到单词嵌入和BERT等预训练语言模型的输出表示位于同一个向量空间中。因此,我们能够从BERT等预训练语言模型的输出表示中恢复实体嵌入,从而将它们的上下文知识注入模型中。
在石油炼化领域命名实体识别任务的研究中,实体知识的定义为该实体在语料库语句中所有实体嵌入的算数平均。对于该领域的实体e,例如“催化剂”,按照以下方法获取实体知识E(e):
首先统计语料中含有“催化剂”的句子集合Se,在其他参数不变的情况下,将这些句子中的“催化剂”替换成“[MASK]”,则该实体知识对掩码语言模型损失的影响优化为式(4):
(4)
其中,xi为替换后的掩码令牌, 为预训练语言模型对xi的输出表示。
实体知识E(e)表示为:
(5)
其中,n为实体出现的次数。对于其他词语的掩码语言模型损失而言,实体知识可以作为负对数似然损失[20]。Gao等人指出,从这种负对数似然获得的梯度下降,会使得所有词语倾向统一,影响罕见词的表征质量[21]。在石油炼化领域中,罕见词出现的上下文比较固定,可以忽略这一负项,通过式(5)获取实体知识。
针对石油炼化领域,本文通过汇总标注语料中的实体形成石油炼化领域内部实体集合。对于每个实体,首先从语料库中提取包含该实体的句子,然后采用上述方法获取这些领域实体的实体知识并进行存储。
2.2.2" 融入领域实体知识
上节得到的领域实体知识和原始词嵌入都属于掩码语言模型的目标,实体可以看作是一种特殊的输入标记。为了将领域实体知识融入预训练语言模型中,本节采用一对大括号将构建的实体知识括起来,然后将其插入到原始实体后,生成新的输入序列,如表3所示。
在表3例子中,“催化裂化装置{催化裂化装置}采用的都是分子筛催化剂{分子筛催化剂}。”作为预训练语言模型的输入,在掩码语言过程阶段,当遮挡实体“催化裂化装置”和“分子筛催化剂”时,将实体的向量表示替换成上节构建的实体知识,而其他词语使用了它们原始的实体嵌入。通过该方法,实现了将领域实体知识传递给预训练语言模型进行编码,在不需要修改结构和额外参数的前提下,向预训练语言模型融入了领域实体知识。
2.2.3" 融入领域实体知识
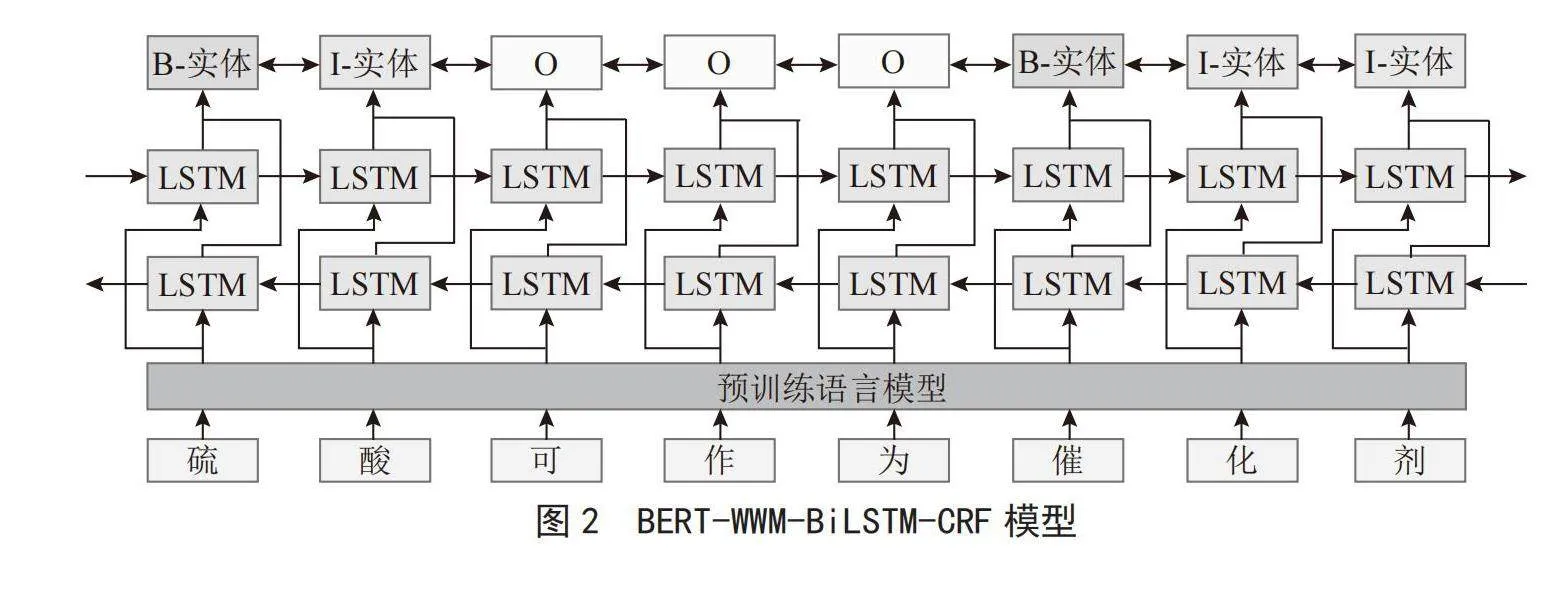
IIEKNER模型在BERT-WWM-BiLSTM-CRF命名实体识别模型中融入内部实体知识,BERT-WWM-BiLSTM-CRF命名实体识别模型结构如图2所示。
融入内部实体知识的方式为:首先,汇总标注数据中所有实体名称,对于这些实体中的每个实体,统计不超过150个包含该实体的句子,利用第2.2.1节中的方式获取该实体的实体知识,之后对包含该实体的所有语句进行如表3的处理,最后将预训练语言模型在处理后的语料进行补充训练,在掩码语言模型阶段,将实体[MASK]去掉,将其实体表示替换成实体知识,实现实体知识的注入,提高了预训练语言模型对领域实体的理解能力。
3" 实验及结果分析
3.1" 数据集获取
由于石油炼化领域缺乏开源数据集,因此首先要获取数据集。获取数据集主要包括三个步骤:实体类别定义、语料获取和语料标注。
3.1.1" 实体类别定义与语料获取
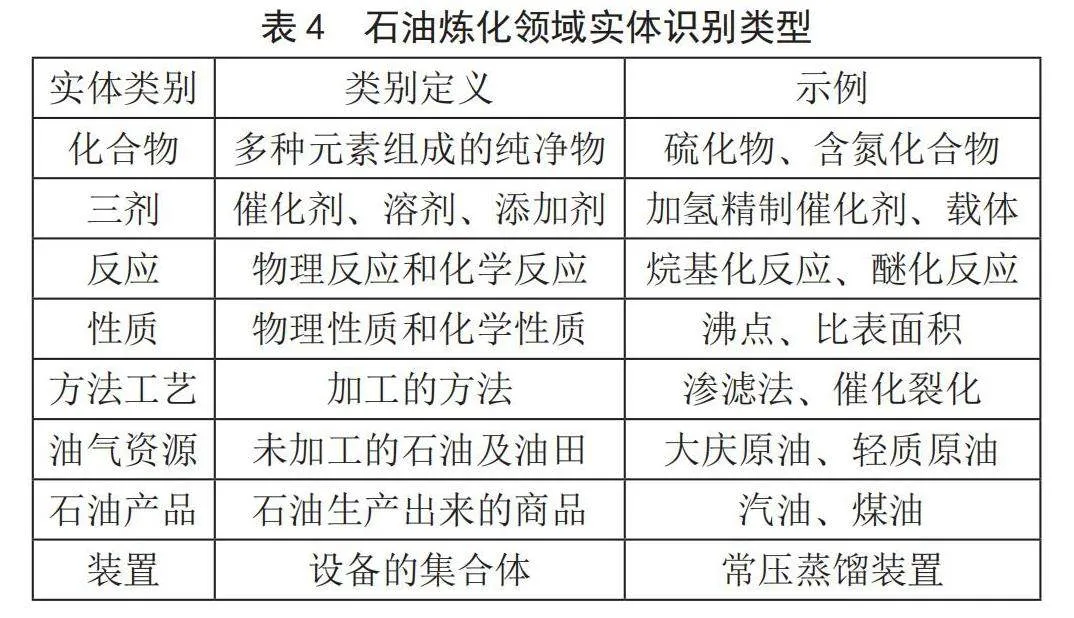
在进行石油炼化领域的命名实体识别任务时,需要先确定该领域的实体类别。由于石油炼化领域没有公开的实体类型定义,可以通过对领域内的专业文献、技术规范、专利文件和工艺流程等进行分析和总结得出。本文通过查阅石油炼化领域专业文献并与石油炼化领域专家进行讨论,最终定义了石油炼化领域十大类实体类型,即:化合物、三剂、反应、性质、方法工艺、油气资源、石油产品、装置、设备、其他。每个类型的定义及具体解释如表4所示。
构建石油炼化领域数据集,首先需要获取石油炼化领域原始语料,其次对原始语料进行格式转换和分句等处理后得到石油炼化领域语料,最后对石油炼化领域语料进行预处理和标注。石油炼化领域原始语料来自《石油学报(石油加工)》2010—2020年间共1 768篇文献以及石油出版社提供的相关图书和生产案例等。
3.1.2" 语料标注
本文采用BIO标注对文本进行标注。在BIO标注中,每个字都被标记为“B”“I”或“O”。如果字是实体的开始,则标记为“B-N”,如果词语是实体的中间部分,则标记为“I-N”,其中N为实体类型,如果词语不是实体的一部分,则标记为“O”。
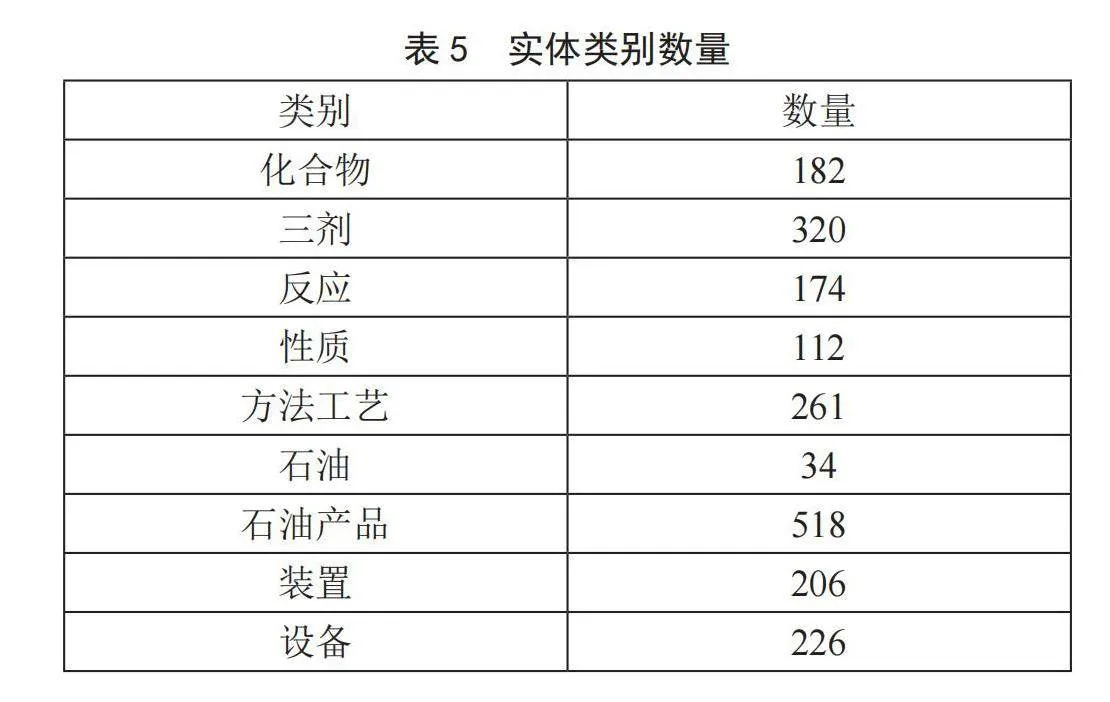
本节对石油炼化领域语料中存在实体的6 000个句子共计262 054字进行标注。将这些句子划分为两部分,一部分包含1 000个句子,共计34 053字符,实体个数共计2 033个,其中单一实体1 422个,组合实体610个,各类实体个数如表5所示,这一部分数据集主要用于本章数据增广研究。另一部分包含5 000个句子,228 001个字符,9 965个实体,主要用于实验验证。
3.2" 评价指标
由于本文研究的是油气勘探领域的命名实体识别,分为两个部分进行实现,即先确定实体边界,然后对实体进行分类。因此不仅要判断实体的边界是否正确,同时还需要判断实体类别是否准确。本文采用严格的评价指标,即实体边界和实体类型必须都正确才算正确识别油气勘探领域的命名实体。我们采用精确率(P)、召回率(R)、F1值(F)来评价模型结果。
3.3" 实验分析
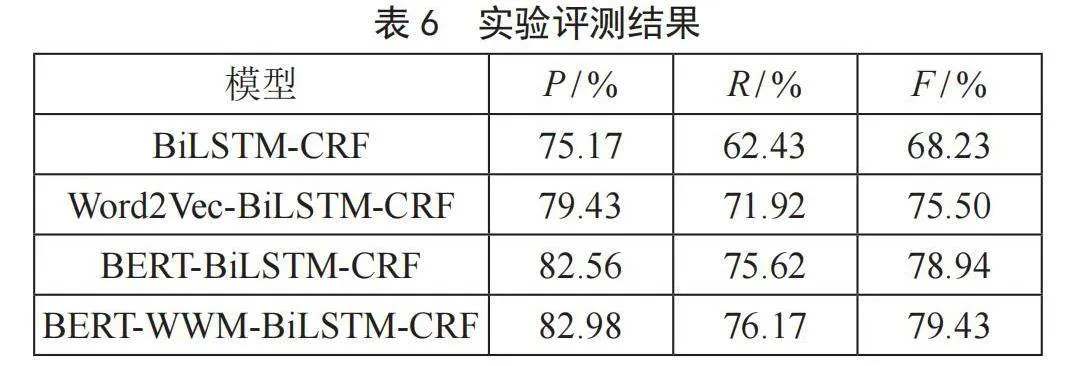
为了探究“预训练语言模型-BiLSTM-CRF”在石油炼化领域命名实体识别任务上的性能表现,本节使用BERT-WWM、BERT、Word2Vec三种预训练模型结合BiLSTM-CRF在石油炼化数据集上进行实验,实验结果如表6所示。
由表6可知,在石油炼化领域数据集上,“预训练语言模型-BiLSTM-CRF”各项评价指标均比BiLSTM-CRF高,BERT-WWM-BiLSTM-CRF在石油炼化领域命名实体识别任务上效果最好。相比于Word2Vec,BERT系列基于Transformer构建,能够处理长文本序列中的依赖关系,而Word2Vec基于n-gram构建,对于长文本序列处理效果差。此外,BERT系列属于动态语言模型,可以理解词语在上下文中的语义并解决一词多义问题。相比于BERT,BERT-WWM在掩码策略上采用全词掩码,拥有更丰富的词语级别的语义信息,因此效果较好。所以本文之后使用并比较的预训练模型均为BERT-WWM。
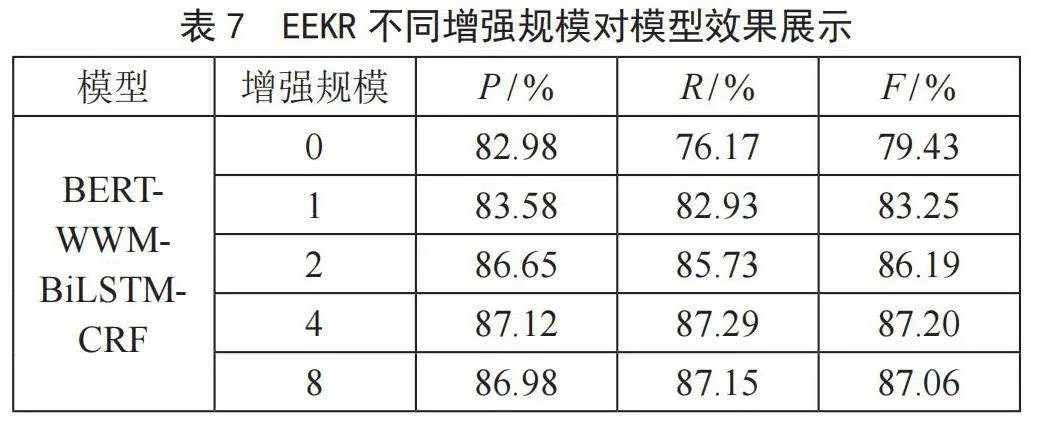
3.3.1" EEKR数据增强方法实验结果
为了探究EEKR数据增强算法对石油炼化领域命名实体识别效果的影响,本节采用EEKR算法对数据进行增强,使用不融入内部实体知识的BERT-WWM-BiLSTM-CRF模型在不同增强规模的数据集上进行训练,实验结果如表7所示。EEKR数据增强算法对于石油炼化领域数据集的效果是非常明显的,对于BERT-WWM-BiLSTM-CRF,当增广规模达到4时,P、R和F分别提升了4.14%、11.12%、7.77%。该方法的有效性在于不会破坏实体的真正含义,同时可以丰富实体,符合石油炼化领域数据标准,有效解决了石油炼化领域数据稀缺的问题。
3.3.2" IIEKNER模型实验结果
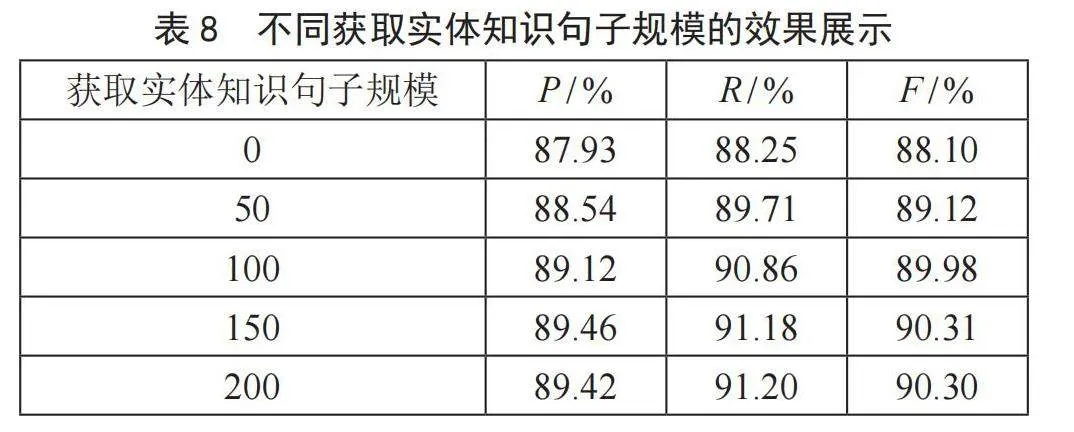
为了验证IIEKNER模型的有效性,本节与未融入内部实体知识的BERT-WWM-BiLSTM-CRF模型(获取实体知识的句子规模为0时)进行对比,之后设置获取实体知识的句子规模分别为50、100、150、200,然后对比融入这些实体知识后模型的识别效果,如表8所示。
分析表8可知,与未融入内部实体知识的BERT-WWM-BiLSTM-CRF模型相比,我们的IIEKNER模型在获取实体知识的句子数量为150时,将获取的实体知识融入预训练模型后F最大,增加了2.21%。但与数量为200的时候相差不大。所以针对石油炼化领域实体而言,获取实体知识的最佳句子规模为150。同时证明了我们的命名实体识别模型IIEKNER的有效性。
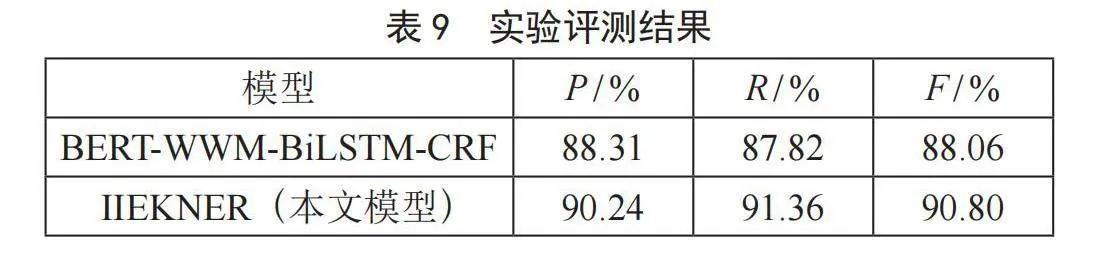
3.3.3" 基于EEKR的IIEKNER模型实验结果
为了证明IIEKNER模型在使用EEKR数据增强方法的同时,效果同样有效,我们在EEKR数据增强规模为4,以及IIEKNER模型获取实体知识句子规模为150的情况下,与BERT-WWM-BiLSTM-CRF模型进行对比。模型对比实验结果如表9所示。结果表明,基于EEKR方法的IIEKNER模型在石油炼化领域的效果有着显著提升。
4" 结" 论
本文针对石油炼化领域中的命名实体识别任务存在的标注数据稀缺,以及现有的预训练语言模型不能很好识别领域组合和嵌套实体的问题,首先提出EEKR数据增强方法,解决了标注数据稀缺的问题,之后提出IIEKNER模型,解决了预训练语言模型不能很好识别领域组合和嵌套实体的问题。经过实验的对比和分析,EEKR数据增强方法和IIEKNER模型对于石油炼化领域的效果都是有效的,同时基于EEKR方法的IIEKNER模型对比其他基线模型也获得了最好的识别效果,二者并不冲突。
参考文献:
[1] XU J J,HE H F,SUN X,et al. Cross-Domain and Semisupervised Named Entity Recognition in Chinese Social Media: A Unified Model [J].IEEE/ACM Transactions on Audio, Speech, and Language Processing,2018,26(11):2142-2152.
[2] LI J,SUN A X,HAN J L,et al. A Survey on Deep Learning for Named Entity Recognition [J].IEEE Transactions on Knowledge and Data Engineering,2022,34(1):50-70.
[3] WEI J,ZOU K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).Hong Kong:Association for Computational Linguistics,2019:6382-6388.
[4] LI Z M,YUN H Y,GUO Z B,et al. Medical Named Entity Recognition Based on Multi Feature Fusion of BERT [C]//Proceedings of the 4th International Conference on Big Data Technologies.Zibo:Association for Computing Machinery,2021:86-91.
[5] LANDOLSI M Y,ROMDHANE L B,HLAOUA L. Medical Named Entity Recognition using Surrounding Sequences Matching [J].Procedia Computer Science,2022,207:674-683.
[6] LE L,ZUCCON G,DEMARTINI G,et al. Leveraging Semantic Type Dependencies for Clinical Named Entity Recognition [J].AMIA Annu Symp Proc,2022,2022:662-671.
[7] WANG T Z,ZHANG Y X,ZHANG Y F,et al. A Hybrid Model Based on Deep Convolutional Network for Medical Named Entity Recognition [J/OL].Journal of Electrical and Computer Engineering,2023,2023[2023-12-02].https://doi.org/10.1155/2023/8969144.
[8] 杨锦锋,于秋滨,关毅,等.电子病历命名实体识别和实体关系抽取研究综述 [J].自动化学报,2014,40(8):1537-1562.
[9] LEE L H,LU Y. Multiple Embeddings Enhanced Multi-Graph Neural Networks for Chinese Healthcare Named Entity Recognition [J].IEEE Journal of Biomedical and Health Informatics,2021,25(7):2801-2810.
[10] ZHU Z C,LI J Q,ZHAO Q,et al. Medical named entity recognition of Chinese electronic medical records based on stacked Bidirectional Long Short-Term Memory [C]//2021 IEEE 45th Annual Computers,Software,and Applications Conference (COMPSAC).Madrid:IEEE,2021:1930-1935.
[11] XIONG Y,PENG H,XIANG Y,et al. Leveraging Multi-Source Knowledge for Chinese Clinical Named Entity Recognition Via Relational Graph Convolutional Network [J/OL].Journal of Biomedical Informatics,2022,128:104035[2023-11-12].https://doi.org/10.1016/j.jbi.2022.104035.
[12] AN Y,XIA X Y,CHEN X L,et al. Chinese Clinical Named Entity Recognition Via Multi-Head Self-Attention Based BiLSTM-CRF [J/OL].Artificial Intelligence in Medicine,2022,127:102282[2023-11-12].https://doi.org/10.1016/j.artmed.2022.102282.
[13] 孙安亮,时宏伟,王金策.基于字符与单词嵌入的航空安全命名实体识别 [J].计算机技术与发展,2022,32(9):148-153.
[14] 毛宏亮,艾孜尔古丽,陈德刚.基于多头注意力的电网调度领域命名实体识别 [J].计算机技术与发展,2023,33(2):181-186+194.
[15] 贵向泉,郭亮,李立.基于MRC和ERNIE的有色冶金命名实体识别模型 [J].计算机技术与发展,2023,33(10):93-100.
[16] TENNEY I, XIA P,CHEN B,et al. What do You Learn from Context? Probing for Sentence Structure in Contextualized Word Representations [J/OL].arXiv:1905.06316 [cs.CL].[2023-12-03].https://arxiv.org/abs/1905.06316.
[17] PETRONI F,ROCKTÄSCHEL T,LEWIS P,et al. Language Models as Knowledge Bases? [J/OL]. arXiv:1909.01066 [cs.CL].[2023-12-03].https://arxiv.org/abs/1909.01066.
[18] ROBERTS A,RAFFEL C,SHAZEER N. How Much Knowledge Can You Pack Into the Parameters of a Language Model? [J/OL].arXiv:2002.08910 [cs.CL].[2023-12-13].https://arxiv.org/abs/2002.08910.
[19] ROGERS A,KOVALEVA O,RUMSHISKY A. A Primer in BERTology: What We Know About How BERT Works [J].Transactions of the Association for Computational Linguistics,2020,8:842-866.
[20] KONG L P,DAUTUME C M,LING W,et al. A Mutual Information Maximization Perspective of Language Representation Learning [J/OL].arXiv:1910.08350 [cs.CL].[2023-12-13].https://arxiv.org/abs/1910.08350.
[21] GAO J,HE D,TAN X,et al. Representation Degeneration Problem in Training Natural Language Generation Models [J/OL].arXiv:1907.12009 [cs.CL].[2023-12-15].https://arxiv.org/abs/1907.12009.
作者简介:丁建新(1980—),男,汉族,浙江台州人,高级工程师,硕士,研究方向:工程技术数字化转型和钻完井人工智能应用;王晓伟(1997—),男,汉族,山西运城人,硕士研究生,研究方向:自然语言处理;温欣(1978—),男,汉族,甘肃兰州人,工程师,硕士,研究方向:油气勘探开发业务、工业互联网建设、人工智能技术行业应用和相关领域数字化转型;屈克将(1984—),男,汉族,山东泰安人,工程师,硕士,研究方向:石油工程技术领域软件设计和开发;王建华(1982—),男,汉族,湖北荆州人,工程师,硕士,研究方向:油田技术服务行业数字化转型的技术研究;赵艳红(1986—),女,汉族,江苏徐州人,高级工程师,博士,研究方向:石油领域数据建设、数据智能化分析与应用、钻完井知识图谱构建等;通讯作者:胡思颍(2000—),男,汉族,浙江温州人,硕士研究生在读,研究方向:自然语言处理。