中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2025)08-0117-10
Abstract:As a structured semantic knowledge base,the Knowledge Graph plays a key role in many fields such as informationretrval,intellgntquestionasweringandcommendationsystems.Thisapeviews tetheecorecopoents of KnowledgeGraphconstruction,informationextraction,knowledgefusion,andknowledgerasoning.Informationetraction technologyhasdevelopedfromrule-basedmethods toMachineLearing model,andthentoDepLeaingmodel.Itiscurently evolvingtowardsajoint EntityRelationshipExtractionmodel thatreduces erorpropagationandimprovesaccuracy.Inthepart ofknowledgefusion,thestrategiesofentitylinkingandkowledge mergingarediscussed,andtheproblemofentityrecogition is solved byentitydisambiguationand entity alignment.The sectionon knowledge reasoning analyzes the reasoning methods basedonrules,epresentationlearningandDeepLeaming,anditsaplcationinnewknowledge discoveryanderorinformation corection.Finallytehallengesinteonstuctionprocessaepontedout,andsuggestiosforutureesearchditiosare proposed to promote the development of knowledge graph research and application.
Keywords: Knowledge Graph; information extraction; knowledge fusion; knowledge reasoning; Deep Learning
0 引言
20世纪90年代,计算机网络在世界各地得到普及,网络信息资源日渐丰富,信息数据呈现规模海量、类型繁多和快速增长等特征。为方便网络中的数据得到更好地共享和使用,90年代末,万维网之父TimBerners-Lee提出“语义网”的概念。“语义网”描述了万维网中资源、数据之间的关系,通过给万维网上的文档添加能够被计算机所理解的语义“元数据”,形成标准化,从而使整个互联网成为一个通用的信息交换媒介。2012年,Google公司基于“语义网”提出知识图谱的概念,其以实体(客观世界的概念)和关系(两个实体间的关联)为基础,通过有向图的方式展现了实体间的关系。图1是一个小型知识图谱:其中《飞驰人生2》是一个电影实体,韩寒是一个导演实体,沈腾是一个演员实体,韩寒和《飞驰人生2》之间的关系是执导,沈腾和《飞驰人生2》之间的关系是出演。知识图谱对事物间“关系”地注重提高了搜索引擎对用户搜索意图的理解,使其返回的结果更符合用户的需求。之后,随着人工智能技术的蓬勃发展,人工智能对知识的需求愈发庞大且不断增长,促进了国内外各种通用或领域知识图谱的发展应用,比较有代表性的有微软提出的概率性概念知识图谱Probase[1],基于维基百科的多领域知识图谱DBpedia[2],国内开放知识图谱OpenKG[3]等。
为使人和计算机能更好地理解和应用知识,相关研究者针对知识图谱的构建开展了大量研究,研究的重心围绕着知识图谱构建过程中的信息抽取、知识融合、知识推理三部分。现对这三个部分的研究进行介绍并加以综述,并简要分析知识图谱目前的挑战和未来的研究方向,为其下一步的研究提供参考。图2为知识图谱的体系架构。
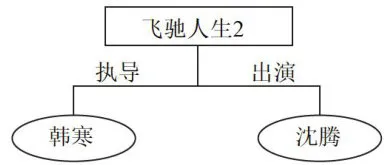 图1小型知识图谱
图1小型知识图谱1信息抽取
知识图谱的本质是一个知识网络,其基本组成单元是由(实体1、关系、实体2)组成的三元组,通过三元组可以描述现实世界中的复杂关系。因此,从海量非结构化、半结构化数据中,提取出结构化三元组的信息抽取技术可谓至关重要。信息抽取包含命名实体识别和实体关系抽取两个子任务。
1. 1 命名实体识别
命名实体识别指的是从文本中识别出具有特定意义的实体,如人名、地名、时间、数字等。在文本“春节档热映的电影《飞驰人生2》由韩寒执导”中,“飞驰人生2”和“韩寒”就是实体,实体“飞驰人生2”的类型是“电影”,实体“韩寒”的类型是“导演”。对命名实体识别的研究主要经历了基于规则的方法、基于机器学习的方法和基于深度学习的方法三个阶段。
1.1.1 基于规则的命名实体识别方法
早期的命名实体识别方法需先针对目标实体通过人工构建规则,再根据规则从文本中寻找匹配的内容来识别实体。例如文献[4]提出的DL-CoTrain方法,通过预先规定规则集合,再根据语料对该集合进行训练迭代,以得到更多的规则,最后将规则用于对命名实体的识别。文献[5]采用基于规则的方式对结构较规范的数词和时间词进行命名实体识别,并取得了较好的效果。
基于规则的命名实体识别方法依托于前期规则的构建,在特定语料上能得到较高的识别效果,但规则非常依赖领域知识。当跨领域应用时,预定义的规则难以生效,而通过人工重新制定规则成本过高且难以覆盖所有情况。因此,想要通过人工指定的有限规则去识别近乎无限的命名实体,其可行性不高。
1.1.2基于机器学习的命名实体识别方法
为克服人工构建规则有限的问题,有研究者提出基于机器学习的方法。该类方法利用机器学习算法模型实现命名实体识别,一般通过学习特征向量并进行分类,但需要大量的标注数据。文献[6]采用支持向量机(SupportVectorMachine,SVM)模型进行命名实体研究,并取得了较好的效果。文献[7]基于条件随机场(ConditionalRandomFields,CRF)对音乐领域进行命名实体识别研究,并通过实验,结果表明CRF在音乐领域的命名实体识别中,准确率与支持向量机(SVM)模型和最大熵(Maximum Entropy,ME)模型相比具有一定的优势。文献[8]通过CRF条件随机场模型建立了一种航天命名实体识别的方法,并取得了较高的准确率。文献[9]通过若干个隐马尔科夫(HiddenMarkovModels,HMM)模型串联对法律文本进行多层次实体识别。文献[10]基于Hadoop平台进行HMM模型的参数训练,并验证了该模型相比于CRF模型的参数训练效率的优劣。
机器学习方法对命名实体识别的早期研究针对的大多是英文文本,为提高这些模型对中文文本命名实体识别的效果,有研究者根据汉语文本的语法、特点等对模型进行了改进。如层叠隐马尔可夫模型[11-12]、层叠条件随机场模型[13-14]等。另有研究者将机器学习模型与规则等方法结合起来,期望能够提高命名实体识别的效果。如文献[15]结合CRF和ME,采用两阶段方法识别中文命名实体,有效降低了模型计算的复杂度。文献[16]提出一种结合SVM和主动学习策略的命名实体识别方法,该方法通过SVM识别切分标注过语料中的中文机构名,并通过主动学习策略减少了人工标注成本。文献[17]提出一种结合SVM和基于规则的方法应用于生物实体识别,该方法运用基于转换的错误驱动学习方法修正SVM模型的测试结果,提高了对生物实体识别的效果。文献[18]和文献[19]将CRF与规则相结合,分别应用在工程领域和地理领域,并取得了较好的命名实体识别效果。
1.1.3基于深度学习的命名实体识别方法
传统的命名实体识别方法中,基于规则的方法依赖人工构建规则系统,难以覆盖所有语言领域。基于机器学习的方法需要大量的人工标注数据,且依赖特征工程和模型参数设计。而深度学习技术可以自动学习特征,对新的领域和语言也能更好地处理。深度学习在命名实体识别中的应用,一般是通过将词向量作为特征输入到模型中[20],使用词向量来表示词语,相比人工选择特征的方式能够获得更多的语义信息。除词向量的应用外,注意力机制(Attention)[21-22]、BERT(Bidirectional EncoderRepresentations from Transformers)[23-24]、长短期记忆网络(Long Short-Term Memory,LSTM)[25-26]、卷积神经网络(Convolutional Neural Networks, CNN)[27]、GRU(Gated Recurrent Unit)[28-29]等深度学习技术也成功用于命名实体识别研究中。
但上述深度学习模型在处理命名实体识别任务时各有长短。例如,注意力机制(Attention)可以更好地捕捉文本中的重要信息,但训练时间较长。CNN能够有效提取文本的局部特征,但在处理长距离依赖和文本的全局上下文信息方面不如RNN(RecursiveNeuralNetwork)模型。LSTM对长文本的处理能力较强,但存在梯度问题。BERT可以处理异构数据,但训练时间较长,且对于低频词汇的处理能力较弱。GRU可以有效地抑制梯度消失或爆炸,但不能完全解决梯度消失问题。对此,有研究者尝试将多种深度学习方法结合应用于命名实体识别研究。文献[30]提出一种基于注意力机制的卷积神经网络模型,在不依赖词汇资源的情况下取得了较好的效果。文献[31]通过BERT获取文本特征,并利用BiLSTM(Bi-directionalLongShort-TermMemory,BiLSTM)神经网络获取序列化文本的上下文特征,再通过CRF进行序列解码标注以提取实体。最后通过实验验证了该方法的有效性。文献[32]提出一种结合双向GRU和双重注意力机制的中文电子病历医疗实体关系识别方法。该方法采用双向GRU学习字的上下文信息,通过注意力机制提高对关系识别起决定作用的字的权重,并从句子中获取可增强识别性能的特征。通过与BiLSTM-Attention模型进行对比实验,该方法取得了更好的效果。文献[33]提出一种基于Attention机制的深度学习方法。该方法先后利用双向长短期记忆网络和Attention机制获得词在整篇文本中的上下文表示,之后通过CRF得到文本的标签序列。通过对比实验验证了相比现有研究模型,该方法提高了在同篇文本中实体识别的一致性。文献[34]通过残差结构促进深度神经网络的梯度传播,从而使卷积神经网络可以拥有更深的架构。文献[35]提出一种结合CNN、BiGRU(Bidirectional GatedRecurrentUnit)和自注意力(Self-Attention)机制的方法,其模型具有较强的特征提取能力。文献[36]提出一种结合CNN和Self-Attention机制的方法,并提出一种反思机制来处理模型中潜在的词汇冲突问题。
1.2 关系抽取
关系抽取作为信息抽取的重要子任务,可以在命名实体识别的基础上,自动识别实体之间的语义关系,并将其转化为关系三元组的形式。在文本“春节档热映的电影《飞驰人生2》由韩寒执导”中,实体“飞驰人生2”和“韩寒”存在着“执导”关系。
根据对人工标注数据的依赖程度,实体关系抽取方法可分为有监督、半监督、无监督三种。近年来,基于深度学习的关系抽取方法也受到了相关研究者的青睐。
1.2.1 有监督的关系抽取方法
基于特征向量的关系抽取方法一般先从句中提取词性、句法、语法等特征,并以此设计显式特征向量,再结合机器学习算法来构造关系抽取模型。该类方法在关系抽取领域取得了不错的效果,但较为依赖特征工程。文献[37-44]都使用了基于特征向量的关系抽取方法。
基于核函数的方法通过隐式计算特征向量的内积,以隐性特征映射代替显性特征映射。该方法可以直接利用核函数比较关系实例之间的结构相似性。但在处理大规模语料时,运算速度上存在一定的缺陷。文献[45-50]都使用了基于核函数的关系抽取方法。
1.2.2 半监督的关系抽取方法
半监督的关系抽取方法只需少量人工标记数据作为种子,结合学习算法对大量无标记数据进行训练,即可得到关系抽取模型。该方法在一定程度上降低了有监督的关系抽取方法需人工标注数据的成本。自文献[51]首次将自举技术Bootstrapping应用在关系抽取领域并构建出DIPRE系统后,自举法成为半监督关系抽取的常用方法之一。文献[52]在文献[51]的基础上对关系的描述方法进行改进,提出了Snowball方法。文献[53]利用自举法,根据语料库中词语的特征提取实体关系指示词,并取得了较好的效果。
半监督的方法虽然降低了关系抽取对于人工标注数据的依赖性,但是对最初种子集的选取要求较高,且迭代过程中的噪声问题也是该方法的一大弊端
1.2.3 无监督的关系抽取方法
无监督的关系抽取方法是基于聚类思想实现的。该方法先根据相似性将实体进行聚类,再用合适的词语对聚类集合进行关系标注。这种自底向上的关系抽取方法无须预定义关系类型,不依赖人工标注语料,因此可以在多领域中得到应用。但无监督的关系抽取方法缺乏人工标注数据和语料库,其准确性可能受到影响。自文献[54]首次提出无监督的实体关系抽取方法以来,该类方法已成为关系抽取的常用方法之一。如文献[55-61]都使用了无监督的实体关系抽取方法。
1.2.4基于深度学习的关系抽取
深度学习方法相比于传统机器学习方法,具有特征提取和自动学习的优势,因此研究者们大量开展了基于深度学习的关系抽取方法研究。该类方法可分为基于单一神经网络的关系抽取方法、基于混合神经网络的关系抽取方法和实体关系联合抽取方法。其中,基于单一神经网络的关系抽取方法主要涉及的神经网络基本结构有CNN[62-64]、递归神经网络(RNN)[65-67]、图神经网络(GraphConvolutionalNeuralNetworks,GCN)[68-70]等。
1.2.5基于混合神经网络关系抽取方法
为了发挥各种神经网络在关系抽取模型中的优势并避免其缺点,基于混合神经网络的关系抽取方法目前较为流行。例如,文献[71]结合BiLSTM和CNN用于临床关系提取,并取得了较好的效果。文献[72]提出一种结合BiLSTM和Attention机制的多情感分类方法,该方法构建了五个分别对应幸福、愤怒、悲伤、恐惧和惊喜的情感分类器,并进行了情感预测实验,分析了五个分类器的性能。文献[32]提出一种结合BiGRU和双重注意力机制的实体关系抽取方法,并通过实验验证了该方法能有效解决现有实体关系抽取方法中可能存在的标签错误问题。文献[73]提出了一种结合BERT、BiLSTM和Attention机制的关系抽取模型,并与最短路径模型和注意力导向图卷积神经网络等模型进行对比实验,结果验证了该模型的合理性。文献[74]提出一种结合BERT和BiGRU的中文专利文本自动分类方法,用以解决中文发明专利文本的文字描述专业性强等问题,并设计了多组对比实验,验证了该方法的有效性。
1.3实体关系联合抽取方法
命名实体识别和关系抽取这两个任务传统上是采用流水线方法分两步执行的,其在模型选择上较为灵活。但由于实体识别和关系抽取这两个模型相互独立,实体抽取阶段的识别错误、遗漏等问题会直接传递并影响到关系抽取阶段的效果。针对上述问题,有研究者开展了实体关系联合抽取的研究。文献[75]首次将深度学习应用于实体关系联合抽取任务,其采用端到端的深度学习模型对联合任务进行建模。文献[76]提出基于新序列标注的联合抽取方法,首次将实体关系联合抽取简化为序列标注问题。文献[77]先基于BiLSTM抽取序列特征,再利用GCN编码依存分析图中的先验词间关系信息,并对实体关系进行标注,最终生成实体关系三元组。文献[78]针对实体识别引起的误差传播和联合抽取模型中存在的实体重叠及关系重叠问题,提出了词性注意力机制和融合先验知识的实体关系分类器,并以此构建大学数字图书馆系统,用以抽取大学课本的实体关系三元组。
表1为本节所列的信息抽取相关方法及其优缺点对比。
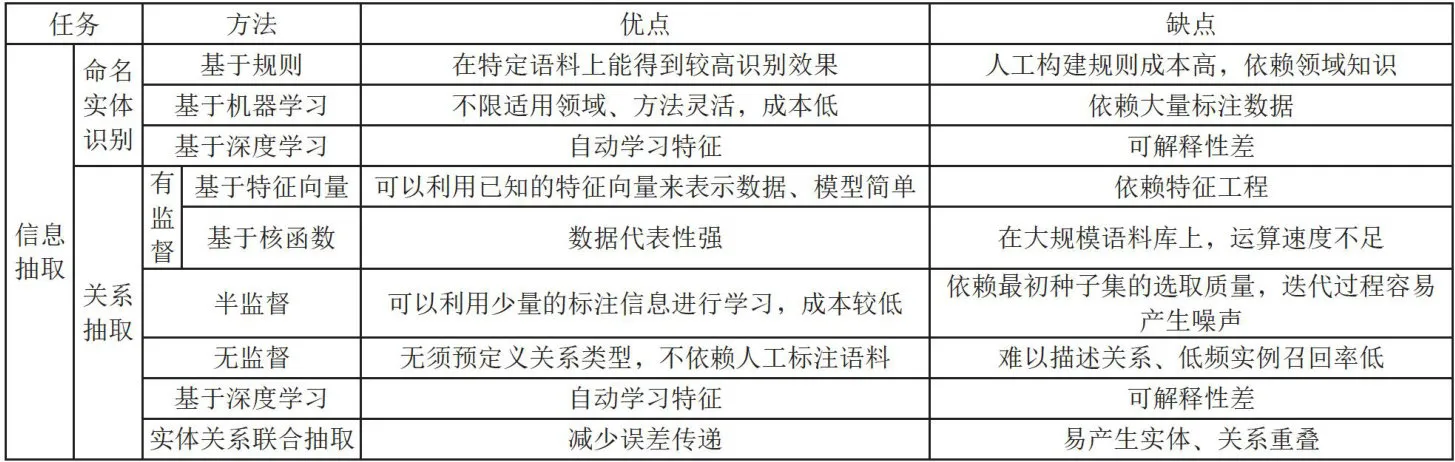 表1信息抽取相关方法及优、缺点对比
表1信息抽取相关方法及优、缺点对比2 知识融合
信息抽取任务为初步构建知识图谱提供了数量可观的结构化知识,但由于知识的多源异构性,不同知识源获取到的知识可能存在冲突或重叠,导致信息抽取的结果中可能存在大量的冗余和错误。为最大程度地利用知识,满足不同用户的知识需求,研究者们开展了知识融合技术的相关研究。知识融合主要包括实体链接和知识合并两部分。
2. 1 实体链接
知识图谱中任何一个实体应该明确对应现实世界中的某个客观事物。但在知识图谱构建过程中,通过信息抽取得到的实体可能出现“同名异义”或“同义异名”的情况。“同名异义”指同一个名称对应不同的客观事物,例如名称为“小米”的实体既可以指国产手机品牌,也可以指谷物。“同义异名”是指同一客观事物对应不同的名称,例如“南昌”“英雄城”和“洪城”都对应同一个客观事物。根据上述两种不同情况,实体链接又分为实体消歧和实体对齐。
2.1.1 实体消歧
为确保每一个实体都有明确的对应,采用实体消歧来实现。实体消歧方法的一般思路是通过结合上下文语境,并计算词汇与实体之间的相似度来实现。文献[79]利用维基百科的语义知识来衡量实体间的相似性,从而实现实体消歧。文献[80]同时利用维基百科和英文词库WordNet作为背景知识,基于文本相似性和主题一致性提出了LINDEN模型进行实体消歧。文献[81]根据候选实体和上下文单词间可能存在的语义联系,提出了Category2Vec模型来实现命名实体消歧。文献[82]通过比较实体的时序特征和输入实体上下文的时序特征进行实体消歧,该方法能够在实体上下文信息不充分的情况下进行消歧。文献[83]将实体上下文的语义相似度、实体属性的背景相似度和主题词的主题相似度结合起来刻画实体,实现实体消歧,并通过实验验证,这种多元相似度融合方法相比于传统实体消歧方法,具有更高的实体消歧准确率。文献[84]针对传统实体消歧方法在短文本上提取的特征较为缺乏的问题,提出一种基于实体主题关系的中文短文本图模型消歧法,并通过实验验证该方法在短文本上取得了较优的实体消歧效果。
2.1.2 实体对齐
为判断不同实体是否指向同一客观事物,采用实体对齐的方式。文献[85]使用向量空间模型和余弦相似度计算实体相似性,其运算速度较高,但准确率较低。文献[86]基于嵌入的方法设计了DvGNet模型进行实体对齐。文献[87]通过计算每个实体的三元组嵌入,再以此进行实体对齐,并提出了一种三元组嵌入计算方法用以感知知识图谱中的关系类型。通过在公开数据集上进行实验,验证了该方法的有效性。文献[88]提出一种自适应特征融合机制,根据不同模态数据质量动态融合实体结构信息和视觉信息,并设计了视觉特征处理模块和三元组筛选模块,分别用来提升视觉信息的有效利用率及缓解结构差异性。之后通过实验验证了其在多模态实体对齐任务上的性能优越。
2.2 知识合并
实体链接方法是从实体层面提升知识图谱的知识质量。而知识合并方法是基于现有知识库和知识图谱来提升知识图谱的质量,但现有知识库或知识图谱因设计需求或应用领域的不同,导致存在很多知识上的差异和重复。知识合并针对解决的就是上述问题。文献[89]以两个知识库为输入设计了一种知识融合算法PARIS,能同时对齐类别、实例、属性和关系,但该算法需要人工参与,无法自动获取知识并融合。文献[90]先对多个知识图谱的数据进行预处理以统一格式,其次建立知识图谱的实体内容索引,再读取每个实体的三元组数据并去除冗余,最后构建实体信息字典以合并多个知识图谱。文献[91]探索了概念层知识融合和语义层知识融合的实现路径,并以高血压疾病为例进行实验,结果表明融合后的高血压领域本体,其概念体系、本体内容和领域知识门类都得到了丰富。
表2为本节所列的知识融合相关方法及其优缺点对比。
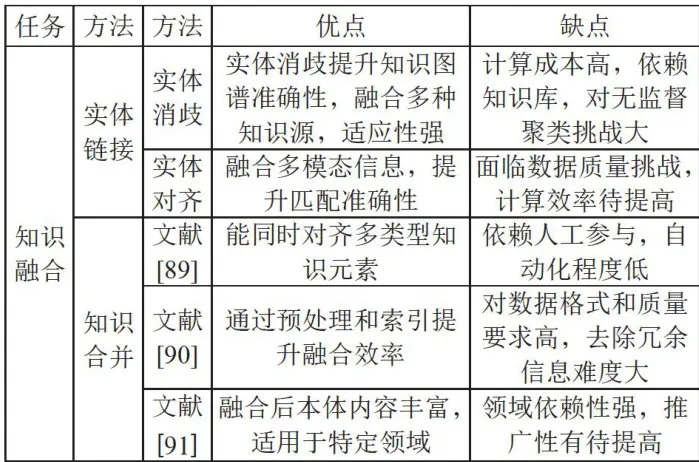 表2知识融合相关方法及优、缺点对比
表2知识融合相关方法及优、缺点对比3 知识推理
知识推理技术在初步构建出知识图谱的基础上,可以进一步从已有知识中挖掘出隐含信息,并识别出错误知识。知识图谱上的推理方法主要分为基于规则的推理方法、基于表示学习的推理方法和基于深度学习的推理方法。
3.1基于规则的推理方法
该类方法可借助现存的定理,或根据特定的场景自定义规则,来实现推理过程。例如,定义“妈妈的爸爸是外公”,已知“a是b的爸爸”,“b是c的妈妈”,则可以推出“a是c的外公”。基于规则的推理方法可解释性强,因此在知识图谱推理的早期研究中较为流行。文献[92]基于一阶谓词逻辑方法预测知识图中潜在的关系。文献[93]设计了柑橘病虫害领域的相关规则来实现知识推理。基于规则的推理方法因简单、高效,适用于对小型知识图谱进行推理,但在大型知识图谱上的知识推理效果有限。
3.2基于表示学习的推理方法
该类方法的基本思想是将知识图谱中的实体、关系等映射到向量空间中进行推理。文献[94]将实体和向量联系起来,并捕捉其中隐含的语义。文献[95]基于时序特征提出一种时序知识图谱链接预测模型。文献[96]通过一个拥有三个虚部的超复数来表示知识图谱中的实体和关系,并以此提出了QuatE模型。
3.3基于深度学习的推理方法
近年来,神经网络被广泛用于知识推理领域,相比于其他推理方法,在进行大规模数据抽取有用信息的任务中更有优势。文献[97]首次将胶囊网络用于知识图谱推理任务,采用预训练的实体及关系特征表示进行推理,并提出了CapsE模型。文献[98]结合LSTM和图注意力机制,设计了AttnPath模型用于实体和关系推理任务。文献[99]设计的InteractE模型使用循环卷积运算提取特征,并通过改变特征组合的方式来捕获更多特征交互,并通过实验证明,该模型具有较好的知识图谱推理性能。文献[100]采用分层注意力机制对邻域信息和类型信息进行多维度感知,以此实现实体推理。文献[101]利用RoBERTa-PubMed神经网络、ConvE和HypER构建了一个大规模网络系统SympGAN,用以提供用户对症状、基因、疾病和药物之间关系的数据库访问。
表3为本节所列的知识推理相关方法及其优缺点对比。
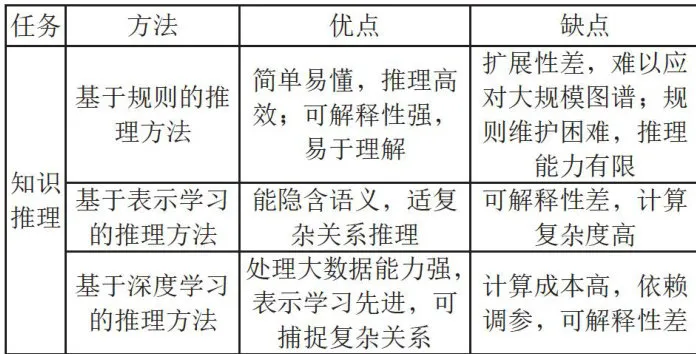 表3知识推理相关方法及优、缺点对比
表3知识推理相关方法及优、缺点对比综上所述,通过信息抽取技术可从杂乱无章的数据中获取实体、关系和属性等信息;通过知识融合技术可消除实体、关系间的歧义,得到客观的事实表达;最后通过知识推理技术可得到完整的知识图谱。
4结论
知识图谱作为知识工程的重要资源管理技术,可实现对数据资源的有效组织和高效利用。本文对知识图谱构建过程中的信息抽取、知识融合和知识推理三个重要部分进行了系统综述,其中深度学习技术贯穿于知识图谱构建的各个环节,对于知识图谱的应用和优化也有着重要作用。尽管知识图谱已经取得较为丰富的研究成果,但其构建过程仍存在一些问题亟待解决:
第一,实体关系联合抽取方法减少了实体识别和关系抽取分步进行可能带来的错误信息和冗余信息,但也带来了实体、关系重叠的新问题。且当前的实体关系联合抽取模型主要是抽取三元组形式的实体关系,而实际应用中的语料库中往往包含大量的多元信息。
第二,自然语言具有多源异构性,因此需确保知识融合能准确将“同名异义”的实体消歧并将“同义异名”的实体对齐,否则会导致知识图谱中出现知识冗余或错误。但在知识融合相关研究中,针对理论方法的研究较多,实证研究较少。
第三,知识图谱推理缺乏对时间、空间等动态特征的研究。而如医学领域的疾病发展、农业领域的作物生长等知识易随时间变化而变化。且基于深度学习的知识推理模型,因“黑箱效应”存在可解释性差的问题,在如何衡量各种模型在可解释性上的优劣也缺乏标准。
因此,本文认为在未来的研究工作重点可能主要在以下几个方面:
第一,改进序列标注策略和三元组匹配规则,用以解决实体关系联合抽取中的实体、关系重叠问题,并开展针对多元信息的实体关系联合抽取方法的研究。
第二,针对不同规模的知识图谱,开展知识融合的实证研究,以进一步验证现有知识融合方法的有效性。
第三,从知识图谱的可视化和时态信息的因果关联等角度出发,增强知识推理的可解释性。研究针对各种神经网络模型的解释机制,以准确反映模型的内部工作逻辑。使用增量学习、时间序列嵌入等方法加强知识图谱的动态推理,提高其推理的深度。
参考文献:
[1]WUWT,LIHS,WANGHX,etal.Probase:AProbabilistic Taxonomy for Text Understanding[C]//Proceedingsof the 2012 ACMSIGMOD International Conference onManagementofData.Scottsdale:ACM,2012:481-492.
[2]AUERS,BIZERC,KOBILAROVG,etal.DBpedia:ANucleus forAWeb of Open Data [C]//Proceedings of the 6thInternational The Semantic Web and 2nd Asian ConferenceonAsianSemanticWebConference.Busan:ACM,2007:722-735.
[3]GUPTA S,KENKRE S,TALUKDARP.CaRe:OpenKnowledgeGraphEmbeddings[C]//Proceedingsof the2019Conference on Empirical Methods in Natural Language Processingand the 9th International Joint Conference on Natural LanguageProcessing.Hong Kong: ACL,2019: 378-388.
[4] COLLINS M,SINGER Y. Unsupervised Models forNamed Entity Classification [C]//Proceedings of the Joint SIGDATConference on Empirical Methods in Natural Language Processingand Very Large Corpora.Hong Kong:ACL,1999:100-110.
[5]程志刚.基于规则和条件随机场的中文命名实体识别方法研究[D].武汉:华中师范大学,2015.
[6] ISOZAKI H, KAZAWA H. Efficient Support VectorClassifiers for Named Entity Recognition [C]//Proceedings ofthe 19th International Conference on Computational Linguistics.
Taipei:ACL,2002,1:1-7.
[7]郝乐川.基于条件随机场的音乐领域命名实体识别[D].哈尔滨:哈尔滨工业大学,2012.
[8]徐建忠,朱俊,赵瑞,等.基于CRF算法的航天命名实体识别[J].电子设计工程,2017,25(20):42-46.
[9]周晓辉.基于隐式马尔科夫模型的法律命名实体识别模型的设计与应用[D].广州:华南理工大学,2018.
[10]李世超.基于Hadoop平台和隐马尔可夫模型的生物医学命名实体识别方法研究[D].咸阳:西北农林科技大学,2018.
[11]俞鸿魁,张华平,刘群,等.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006,27(2):87-94.
[12] LI LS,MAO T,HUANGD G,et al. Hybrid Modelsfor Chinese Named Entity Recognition [C]/Proceedings of theFifth SIGHAN Workshop on Chinese Language Processing.Sydney:ACL,2006,:72-78.
[13] 周俊生,戴新宇,尹存燕,等.基于层叠条件随机场模型的中文机构名自动识别[J].电子学报,2006(5):804-809.
[14]红霞.基于层叠条件随机场的中文机构名识别的研究[D].大连:大连理工大学,2010.
[15]毛新年,董远,庞文博,等.一种基于条件随机场和最大熵的两阶段识别中文命名实体方法(英文)[C]/第七届中文信息处理国际会议.武汉:电子工业出版社,2007:445-459.
[16] 陈霄.基于支持向量机的中文组织机构名识别[D].上海:上海交通大学,2007.
[17]黄浩炜.SVM与基于转换的错误驱动学习方法相结合的生物实体识别[D].长沙:国防科学技术大学,2008.
[18] 郭喜跃,周琴,陈前军.基于CRF与规则的工程领域命名实体识别方法[J].软件导刊,2014,13(11):28-30.
[19]何炎祥,罗楚威,胡彬尧.基于CRF和规则相结合的地理命名实体识别方法[J].计算机应用与软件,2015,32(1):179-185+202.
[20]CHERRYC,GUO HY. The UnreasonableEffectiveness of Word Representations for Twiter Named EntityRecognition [C]//Proceedings of the 2015 Conference of theNorth American Chapter of the Association for ComputationalLinguistics: Human Language Technologies.Denver: ACL,2015: 735-745.
[21]陈琛,刘小云,方玉华.融合注意力机制的电子病历命名实体识别[J].计算机技术与发展,2020,30(10):216-220.
[22]常君.基于注意力机制的命名实体识别研究[D].太原:太原理工大学,2022.
[23]封红旗,孙杨,杨森,等.基于BERT的中文电子病历命名实体识别[J].计算机工程与设计,2023,44(4):1220-1227.
[24]王为国.基于Bert的命名实体识别研究[D].广州:广州大学,2021.
[25] PENG N,DREDZE M. Improving Named EntityRecognition for Chinese Social Media With Word SegmentationRepresentation Learning [C]//Proceedings of the 54th AnnualMeeting of the Association for Computational Linguistics.Berlin:ACL,2016,2:149-155.
[26]尹光花,陈鹏.基于双向LSTM模型的中文命名实体识别[J].信息技术与信息化,2021(10):44-46.
[27] DONG X S,QIANL J,GUANY,et al.A Multi-Class Classification Method Based on Deep Learning for NamedEntity Recognition in Electronic Medical Records [C]/016 NewYork Scientific Data Summit.New York:IEEE,2016:1-10.
[28] 李一斌,张欢欢.基于双向GRU-CRF 的中文包装产品实体识别[J].华东理工大学学报:自然科学版,2019,45(3):486-490.
[29] 吴超,王汉军.基于GRU的电力调度领域命名实体识别方法[J].计算机系统应用,2020,29(8):185-191.
[30] ZHU Y,WANG G. CAN-NER: Convolutional AttentionNetwork for Chinese Named Entity Recognition [C]//Proceedings ofNAACL-HLT2019.Minneapolis:ACL,2019:3384-3393.
[31]王子牛,姜猛,高建瓴,等.基于BERT的中文命名实体识别方法[J].计算机科学,2019,46(S2):138-142.
[32] 张志昌,周侗,张瑞芳,等.融合双向GRU与注意力机制的医疗实体关系识别[J].计算机工程,2020,46(6):296-302.
[33]杨培,杨志豪,罗凌,等.基于注意机制的化学药物命名实体识别[J].计算机研究与发展,2018,55(7):1548-1556.
[34]张浩.基于深度学习的生物医学实体关系抽取算法研究[D].长春:吉林大学,2020.
[35] ZHU Y,WANG G. CAN-NER: ConvolutionalAttention Network for Chinese Named Entity Recognition [C]/Proc of the 2019 Conference of the North American Chapter ofthe Association for Computational Linguistics:Human LanguageTechnologies.Minneapolis:ACL,2019:3384-3393.
[36] GUI T,MART,ZHANGQ,et al. CNN-basedChinese NER with Lexicon Rethinking [C]//Proceedings ofthe Twenty-Eighth International Joint Conference on ArtificialIntelligence.Macao:JCAI,2019:4982-4988.
[37]车万翔,刘挺,李生.实体关系自动抽取[J].中文信息学报,2005,19(2):2-7.
[38] CULOTTA A,MCCALLUM A,BETZ J. IntegratingProbabilistic Extraction Models and Data Mining to DiscoverRelations and Patterns in Text [C]//Proceedings of the mainconference on Human Language Technology Conference of theNorth American Chapter of the Association of ComputationalLinguistics.New York:ACL,2006:296-303.
[39] JIANG JING, ZHAI CHENGXIANG. A SystematicExploration of the Feature Space for Relation Extraction [C]//Proceedings of NAACL HLT 2007.New York: ACL,2007:113-120.
[40] SUN X,DONG L H. Feature-Based Approachto Chinese Term Relation Extraction [C]//20o9 InternationalConference on Signal Processing Systems.Singapore Piscataway:IEEE,2009:410-414.
[41] TRATZ S,HOVY E. Isi: Automatic Classification ofRelations Between Nominals Using a Maximum Entropy Classifier[C]/Proceedings of the 5th International Workshop on SemanticEvaluation.Los Angeles:ACL,2010:222-225.
[42]郭喜跃,何婷婷,胡小华,等.基于句法语义特征的中文实体关系抽取[J].中文信息学报,2014,28(6):183-189.
[43]高俊平,张晖,赵旭剑,等.面向维基百科的领域知识演化关系抽取[J].计算机学报,2016,39(10):2088-2101.
[44] 甘丽新,万常选,刘德喜,等.基于句法语义特征的中文实体关系抽取[J].计算机研究与发展,2016,53(2):284-302.
[45] ZHANG M, ZHANG J, SU J. Exploring SyntacticFeatures for Relation Extraction using a Convolution Tree Kernel [C]//Proceedings of the Main Conference on Human Language TechnologyConference of the North American Chapter of the Association of
Computational Linguistics.New York:ACL,288-295.
[46] ZHOU G D,QIAN L H,FAN J X. Tree Kemel-BasedSemantic Relation Extraction with Rich Syntactic and SemanticInformation[J].Information Sciences,2010,180(8):1313-1325.
[47] ZHANG XF,GAO ZQ,ZHU M. Kernel methodsand its application in Relation Extraction [C]// 2011 InternationalConference on Computer Science and Service System(CSSS).Nanjing:IEEE,2011:1362-1365.
[48]刘克彬.基于核函数中文关系自动抽取系统的实现[J].计算机研究与发展,2007,44(8):1406-1411.
[49] 陈鹏.基于多核融合的中文领域实体关系抽取研究[D].昆明:昆明理工大学,2014.
[50]郭剑毅,陈鹏,余正涛,等.基于多核融合的中文领域实体关系抽取[J].中文信息学报,2016,30(1):24-29.
[51] BRIN S. Extracting Patterns and Relations from theWorld Wide Web [J].Lecture Notes in Computer Science,1998,1590:172-183.
[52] AGICHTEIN E, GRAVANO L. Snowball: ExtractingRelations from Large Plain-Text Collections [C]//Proceedings ofthe Fifth ACMConference on Digital libraries.New York:ACMPress,2000:85-94.
[53] YU L,FENG L,LIU X L.A Bootstrapping BasedApproach for Open Geo-entity Relation Extraction [J].ActaGeodaetica et Cartographica Sinica,2016,45(5):616-622.
[54]HASEGAWA T,SEKINE S,GRISHMAN R.Discovering Relations among Named Entities from Large Corpora[C]/Proceedings of the 42nd Annual Meeting on Association forComputational Linguistics.Barcelona:ACL,20o4:415-422.
[55] DAVIDOVD,RAPPOPORT A,KOPPEL M. FullyUnsupervised Discovery of Concept-Specific Relationships byWebMining [C]//Proceedings of the 45th Annual Meeting of theAssociation of ComputationalLinguistics.Proceedings of the 45thAnnual Meeting of the Association of Computational Linguistics:ACL,2007:232-239.
[56] GONZALEZ E, TURMO J. Unsupervised RelationExtraction by Massive Clustering [C]//2009 Ninth IEEE InternationalConference onData Mining.Miami: IEEE,2009:782-787.
[57] YAN YL,OKAZAKI N,MATSUO Y,et al.Unsupervised Relation Extraction By Mining Wikipedia TextsUsing Information from the Web [C]//Proceedings of the JointConference of the 47th Annual Meeting of the ACL and the 4thInternational Joint Conference on Natural Language Processng ofthe AFNLP.Suntec:ACL,2009:1021-1029.
[58] BOLLEGALAD T,MATSUO Y,ISHIZUKA M.Measuring the Similarity Between Implicit Semantic Relations fromthe Web [C]//Proceedings of the 18th International Conference onWorld WideWeb.Madrid:ACM,2009:651-660.
[59]王晶.无监督的中文实体关系抽取研究[D].上海:华东师范大学,2012.
[60]孙勇亮.开放领域的中文实体无监督关系抽取[D].上海:华东师范大学,2014.
[61]施琦.无监督中文实体关系抽取研究[D].北京:中国地质大学(北京),2015.
[62] ZENGDJ,LIUK,LAISW,etal.RelationClassification via Convolutional Deep Neural Network [C]//Proceedings of COLING 2014, the 25th Intermational Conferenceon Computational Linguistics.Dublin:DCUamp; ACL,2014:2335-2344.
[63] NGUYEN TH,GRISHMAN R. Relation Extraction:Perspective from Convolutional Neural Networks [C]//Proceedingsof the 1st Workshop on Vector Space Modeling for NaturalLanguage Processing.Denver,2015:39-48.
[64] XUK,FENGY S,HUANGSF,et al. SemanticRelation Classification via Convolutional Neural Networkswith Simple Negative Sampling [C]//Proceedings of the 2015Conference on Empirical Methods in Natural Language Processing.Lisbon:ACL,2015:536-540.
[65] SOCHERR,PENNINGTONJ,HUANGEH,et al. Semi-Supervised Recursive Auto Encoders for PredictingSentiment Distributions [C]//Proceedings of the Conference on
Empirical Methods in Natural Language Processing.Edinburgh:
ACL,2011:151-161.
[66] HASHIMOTO K,MIWA M,TSURUOKAY,et al.Simple Customization of Recursive Neural Networks for SemanticRelation Classification [C]//Proceedings of the 2013 Conferenceon Empirical Methods in Natural Language Processing.Seattle:ACL,2013:1372-1376
[67] EBRAHIMI J,DOU D. Chain Based RNN for RelationClassification [C]//Proceedings of the 2015 Conference of theNorth American Chapter of the Association for ComputationalLinguistics: Human Language Technologies.Denver: ACL,2015:1244-1249.
[68] SCHLICHTKRULL M,KIPF T N,BLOEMP,etal.Modeling Relational Data with Graph Convolutional Networks[C]//Proceedings of the European Semantic Web Conference.Heraklion:Springer,2018:593-607.
[69] GUO Z J, ZHANG Y,LU W. Attention Guided GraphConvolutional Networks for Relation Extraction [C]/Proceedingsof the 57th Annual Meeting of the ACL.Florence:ACL,2019:241-251.
[70] SUN K, ZHANG R CG,MAO Y Y,et al. RelationExtraction with Convolutional Network over Learnable Syntax-Transport Graph [J].Proceedings of the AAAI Conference onArtificial Intelligence,2020,34(5):8928-8935.
[71] LI ZH,YANG ZH, SHENC,et al. IntegratingshortestDependency Path and Sentence Sequence into a Deep LearningFramework forRelationExtraction in Clinical Text[J/OL].BMCMedical Informatics and Decision Making,2019,19(1):1-8[2024-09-10].https://doi.0rg/10.1186/s12911-019-0736-9.
[72]王婷伟.基于Attention与BiLSTM模型的多情感分类方法研究[D].衡阳:南华大学,2020.
[73]徐瑞涓,高建瓴.基于BERT和注意力引导图卷积网络的关系抽取[J].智能计算机与应用,2023,13(2):204-209.
[74] 刘燕.基于BERT-BiGRU的中文专利文本自动分类[J].郑州大学学报:理学版,2023,55(2):33-40.
[75] MIWA M,BANSAL M. End-to-end RelationExtraction using LSTMs on Sequences and Tree Structures [J/OL].arXiv:1601.00770 [cs.CL].[2024-08-26].https://doi.0rg/10.48550/arXiv.1601.00770.
[76] ZHENG S C,WANG F,BAO H Y,et al. JointExtraction of Entities and Relations Based on a Novel TaggingScheme [J/OL].arXiv:1706.05075 [cs.CL].[2024-08-23].https://doi.org/10.48550/arXiv.1706.05075.
[77]张军莲,张一帆,汪鸣泉,等.基于图卷积神经网络的中文实体关系联合抽取[J].计算机工程,2021,47(12):103-111.
[78]何怀前.基于深度学习的实体关系联合抽取方法研究与系统实现[D].上海:东华大学,2023.
[79] HAN X P,ZHAO J. Named Entity DisambiguationbyLeveraging Wikipedia Semantic Knowledge [C]//Proceedingsofthe 18th ACM Conference on Informationand KnowledgeManagement.HongKong:ACM,2009:215-224.
[80] SHEN W,WANG JY,LUO P,et al. Linden: LinkingNamed EntitieswithKnowledgeBaseVia SemanticKnowledge[C]/Proceedings of the 21st International Conference on WorldWide Web.Lyon:ACM,2012:449-458.
[81] ZHU G G,IGLESIAS C A. Exploiting SemanticSimilarity for Named EntityDisambiguation in Knowledge Graphs[J].Expert Systems with Applications,2018,101:8-24.
[82] AGARWAL P, STROTGEN J,DEL CORRO L,et al.diaNED: Time-Aware Named Entity Disambiguation forDiachronic Corpora [C]/Proceedings of the 56th Annual Meetingof the Association for Computational Linguistics.Melbourne:ACL,2018:686-693.
[83]石水倩,金晶,沈耕宇,等.基于多元相似度融合的中文命名实体消歧方法[J].数据分析与知识发现,2024,8(2):56-64.
[84] 马瑛超,张晓滨.基于主题关系的中文短文本图模型实体消歧[J].计算机工程与科学,2023,45(1):154-162.
[85] LI J Z,WANG ZC,ZHANG X,et al. Large ScaleInstance Matching Via Multiple Indexes and Candidate Selection[J].Knowledge-Based Systems,2013,50(9):112-120.
[86] JINY,WJI,Y SHI,et al,Meta-path Guided GraphAttention Network for Explainable Herb 5-5Recommendation[J].Health Information Science and Systems,Springer,2023.11(1): 5-5.
[87]李凤英,黎家鹏.联合三元组嵌入的实体对齐[J].计算机工程与应用,2023,59(24):70-77.
[88]郭浩,李欣奕,唐九阳,等.自适应特征融合的多模态实体对齐研究[J].自动化学报,2024,50(4):758-770.
[89]SUCHANEKFM,ABITEBOUL S,SENELLARTP.PARIS:Probabilistic Alignment of Relations, Instances,andSchema[J].Proceedings of the VLDB Endowment,2011,5(3):157-168.
[90]杨元锋.面向问答的知识图谱推理技术和合并技术研究[D].哈尔滨:哈尔滨工业大学,2020.
[91]周利琴.面向智慧健康的多源异构知识融合研究[D].武汉:武汉大学,2022.
[92] SCHOENMACKERS S, DAVIS J,ETZIONI O,et al.Learming First Order Horn Clauses from Web Text[C]//Proceedingsof the 2O10 Conference on Empirical Methods in Natural LanguageProcessing.Cambridge:ACL,2010:1088-1098.
[93]杨洁.基于本体的柑橘病虫害知识建模及推理研究[D].武汉:华中师范大学,2014.
[94] NICKEL M,TRESPV,KRIEGEL HP.A Three-Way Model for Collctive Learning on Multi-Relational Data[C]//The 28th International Conference on Machine LearningThe International Conference on Machine Learning. Bellevue:Omnipress,2011:809-816.
[95]陈德华,殷苏娜,乐嘉锦,等.一种面向临床领域时序知识图谱的链接预测模型[J].计算机研究与发展,2017,54(12):2687-2697.
[96] ZHANG S,TAYY,YAO LN,et al.QuaternionKnowledge Graph Embeddings [C]//Thirty-third Conferenceon Neural Information Processing Systems.Vancouver:CurranAssociates Inc,2019:2735-2745.
[97] NGUYEN DQ,VUT,NGUYEN TD,et al.A CapsuleNetwork-based Embedding Model for Knowledge Graph Completionand Search Personalization [J/OL].arXiv:1808.04122 [cs.CL].[2024-08-10].https://doi.org/10.48550/arXiv.1808.04122.
[98] WANGH,LISY,PANR,et al. IncorporatingGraph AttentionMechanisminto Knowledge GraphReasoningBased on DeepReinforcementLearning[C]//2019ConferenceonEmpirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing (EMNLPIJCNLP).HongKong:ACL,2019:2623-2631.
[99]VASHISHTHS,SANYALS,NITINV,etal.InteractE:Improving Convolution-Based Knowledge GraphEmbeddingsbyIncreasingFeature Interactions[C]//ProceedingsoftheThirty-FourthAAAIConferenceonArtificialIntelligence.NewYork:AAAIPress,2020,34(3):3009-3016.
[100] WANGYZ,WANGHZ,HEJW,et al.TAGAT:Type-Aware Graph Attention Networks for Reasoning Over KnowledgeGraphs[J/OL].Knowledge-BasedSystems, 2021,233:107500[2024-08-05].https://doi.org/10.1016/ j.knosys.2021.107500.
[101]KEZHIL,KUOY,HAILONG S,etal.SympGAN: ASystematic KnowledgeIntegration System forSymptom-Gene Associations Network[J/OL].Knowledge-Based Systems, 2023,276:110752[2024-08-03].https://doi.0rg/10.1016/ j.knosys.2023.110752.
作者简介:杨延云(1995.04—),女,汉族,河北张家口人,助教,硕士研究生,研究方向:自然语言处理、数据挖掘、软件开发;胡军(1996.09一),男,汉族,江西抚州人,助教,硕士研究生,研究方向:数据挖掘。