
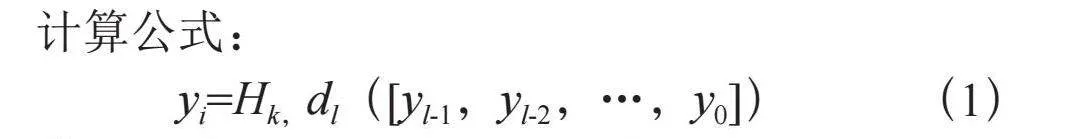


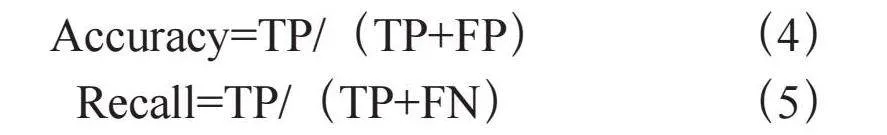

摘" 要:文章为解决手势识别研究中欠缺考虑多时相、特征多样性的问题,提出了一种基于改进DeeplabV3+模型的手势识别提取方法。通过更改模型中ASPP模块结构,使用多个不同的空洞率以及图像金字塔池化等操作,增加CBAM注意力机制模块,提升模型的提取精度和效率。在公开Freihand数据集上进行验证,结果表明:改进后的DeeplabV3+模型训练速度提高了29.2%,识别精确度提升了0.04%,相似度提升了0.68%,召回率提高了0.36%。
关键词:语义分割;手势识别;深度学习;DeepLabV3+模型
中图分类号:TP391.4" " 文献标识码:A" 文章编号:2096-4706(2024)18-0039-05
Research on DeepLabV3+ Algorithm Based on Gesture Recognition
WANG Yu, PAN Jinghao, WU Chaoming, CHEN Zongyan, WANG Yaning, XIE Yue
(School of Information and Communication Engineering, Nanjing Institute of Technology, Nanjing" 211167, China)
Abstract: In order to solve the problems that multi-temporal and feature diversity are not considered in gesture recognition research, this paper proposes a gesture recognition extraction method based on improved DeeplabV3+ model. By changing the ASPP module structure in the model, using multiple different void rates and image Pyramid Pooling and other operations, CBAM Attention Mechanism modules are added to improve the extraction accuracy and efficiency of the model. The results show that the training speed of improved DeeplabV3+ model is improved by 29.2%, the recognition accuracy is improved by 0.04%, the similarity is improved by 0.68%, and the recall rate is improved by 0.36%.
Keywords: semantic segmentation; gesture recognition; Deep Learning; DeepLabV3+ model
0" 引" 言
手势识别是计算机科学中的一个议题,它类属于计算机视觉和人机交互领域,旨在通过识别和解释人类的手势动作,赋予计算机可以理解人的意图的能力并与人进行直接的自然交互。早期的手势识别方法主要基于传感器技术。然而,这些方法存在诸多限制,如传感器的高成本、佩戴设备的不便以及对特定环境的依赖性等,这些外部设备的介入虽提升了手势识别的准确度和稳定性,但丢失了手势自然的表达方式,因此,基于视觉的手势识别方式随之诞生,视觉手势识别是通过对视频采集设备拍摄到的包含手势的图像序列,运用计算机视觉技术进行处理,进而对手势加以识别[2]。
前人的研究工作提出了一种基于深度学习的卷积神经网络模型,它能够区分手部与抓握物体的不同,提取出手部的图像,并通过提取和学习手势图像的特征,实现了对手势动作的准确识别。该方法在标准数据集上获得了高精度性,为实际应用提供了可行的解决方案。另外,针对手势动作的时序性和动态性,提出了一种基于循环神经网络的方法,能够有效捕捉手势序列的时序特征,并实现实时的手势识别。该方法在实验测试中表现出了较好的准确率和实时性,为实际交互系统的设计提供了有力支持。
综上所述,前人的研究工作在手势识别领域取得了一定的突破,为解决手势识别问题提供了有效的方法和技术。然而,现有方法仍然存在一些挑战,如复杂背景下的识别问题、多人手势识别,抗异物遮挡干扰等方面仍需进一步改进和提高。因此,本论文旨在提升神经网络模型性能的方法以应对这些挑战,并提出高效可靠的解决方案,以促进手势识别技术在实际应用中的推广和应用[1-2]。
1" 模型与算法
1.1" 原DeeplabV3+介绍
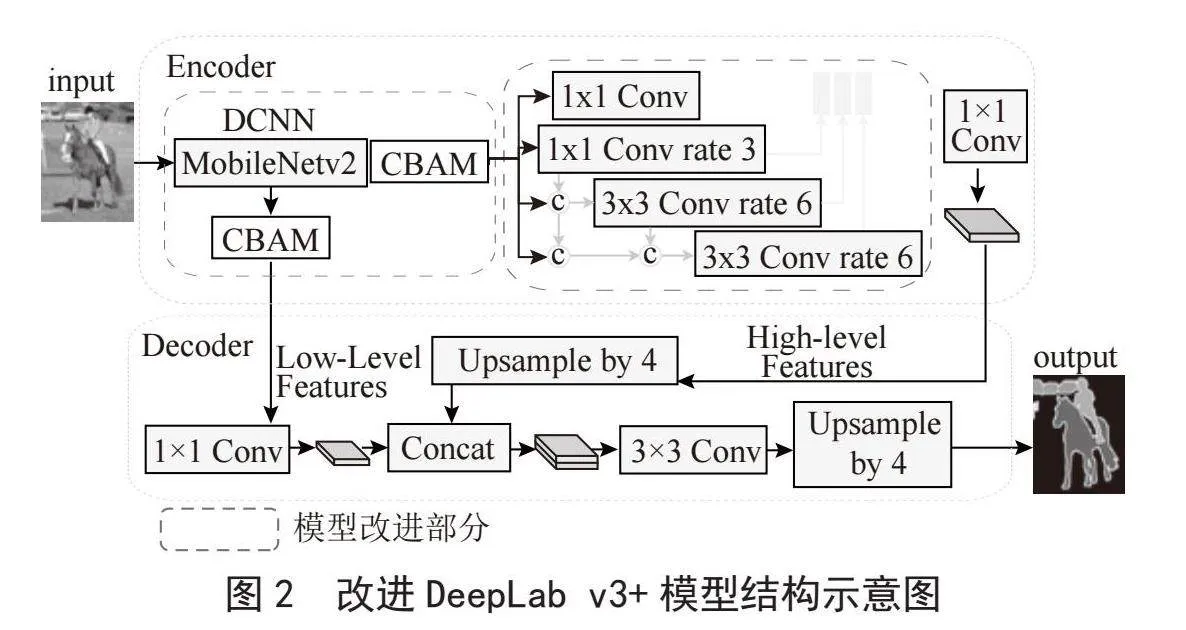
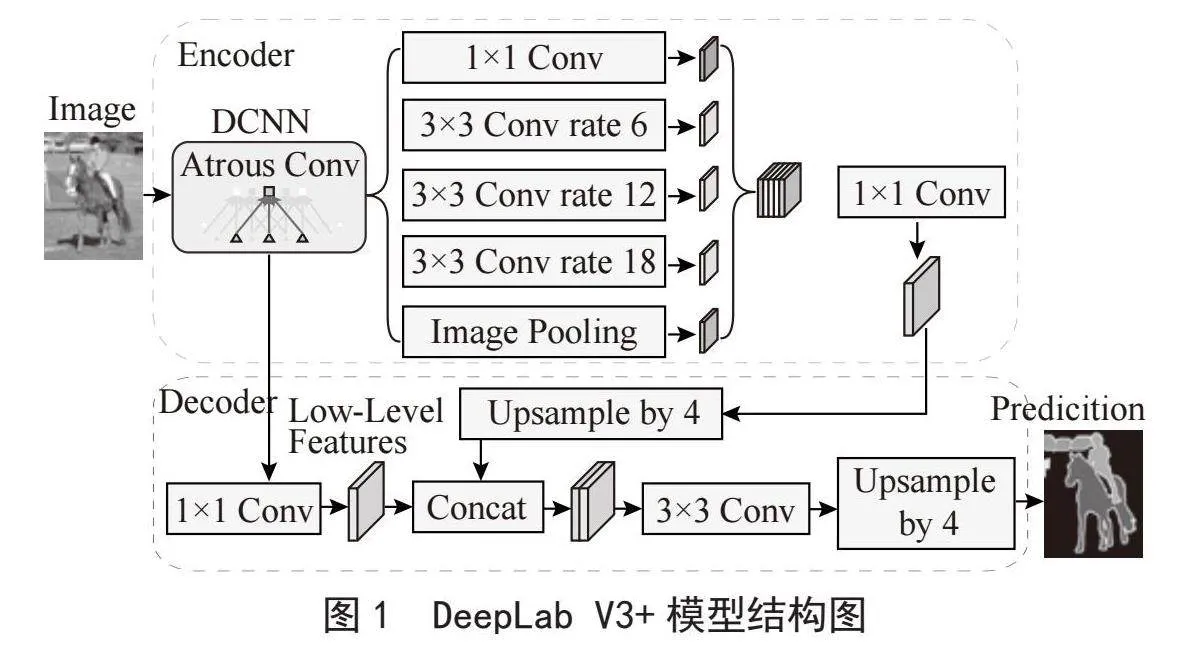
DeepLabV3+是一个用于图像语义分割的深度学习模型,它由Google的研究人员开发。这种模型在图像处理领域非常重要,因为它能够对图像中的每个像素进行分类。语义分割是计算机视觉中的一项挑战,它要求模型对图像中的每个像素分配类别标签,而不区分属于同一类别的不同实例(即,实例分割)。其结构核心如图1所示。
DeepLabV3+模型的核心贡献在于它的空间金字塔池化(Spatial Pyramid Pooling, SPP)模块,这个可以聚合不同尺度的上下文信息,使得模型能够在保持细节的同时进行有效的语义分割。
在DeepLabV3+模型中,空洞空间卷积池化金字塔(Atrous spatial pyramid pooling, ASPP)[3]模块被集成到一个编码器-解码器架构中,这种结构允许模型在保持高分辨率输出(即解码器部分)的同时,通过编码器部分获取更深的特征表示和多尺度信息。这种设计提高了模型对像素级分类的准确性。
1.2" 改进后的deeplabv3+算法
DeepLabV3+模型在图像分割任务中已经取得了很好的性能[3]。为了进一步提高模型的性能,本文将ASPP模块替换为密集空洞空间金字塔池化(Densely connected AtrousSpatialPyramid Pooling, DenseASPP)模块,并加入自注意模块。这种改进带来了以下优势:DenseASPP模块通过全局和局部特征的融合,能够更好地捕捉图像中的语义信息。全局特征融合使模型能够从整个图像中获取全局上下文信息,而局部特征融合则更加关注与目标相关的局部细节。自注意模块能够自动关注与目标相关的特征信息。通过引入自注意机制,模型能够自动选择对语义分割任务更重要的特征,并对它们进行加权处理。
1.2.1" DenseASPP
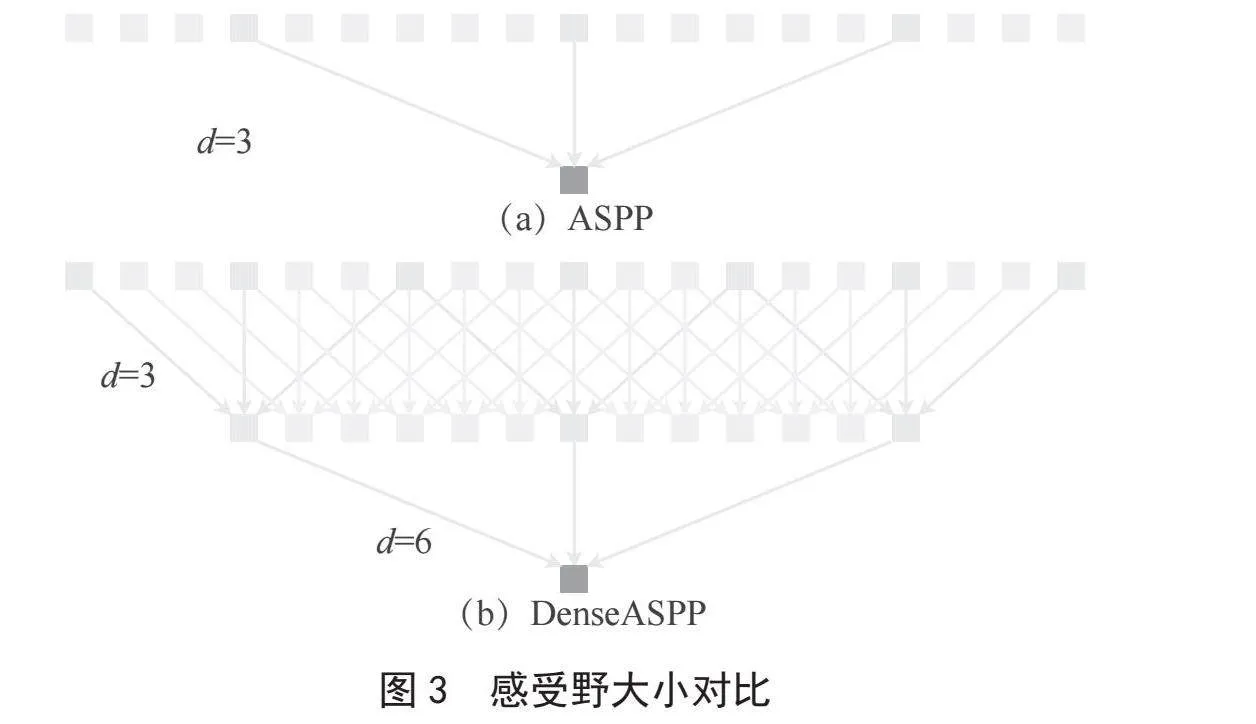
DenseASPP如图2所示:其中每一层的膨胀率一层一层地增加。下部是小膨胀率的层,上面是大膨胀率的层。DenseASPP的最终输出是一个由多膨胀率、多尺度的空洞卷积生成的特征图。
计算公式:
yi=Hk,dl([yl-1,yl-2,…,y0]) (1)
其中dl表示第l层的膨胀率,[…]表示concat操作。[yl-1,yl-2,…,y0]表示通过连接之前所有层的输出而形成的特征图。与最初的ASPP相比,DenseASPP将所有扩展的层堆叠在一起,并通过密集的连接将它们连接起来。这种变化给我们带来了主要的两个好处:更密集的特征金字塔和更大的接受域[4]。为了控制模型的大小并防止网络变得太宽,在DenseASPP的每一个扩张层之前增加一个1×1的卷积层来减少特征图宽度,以将特征图的深度减少到原始大小的一半[5]。
图3(a)为传统的一维空洞卷积层,其膨胀率为6。这种卷积的接受域大小为13。然而,在如此大的核中,只有3个像素被采样进行计算。这种现象在二维情况下会变得更糟。虽然获得了较大的接受域,但在计算过程中却放弃了大量的信息,在DenseASPP中,扩张率一层层地增加,因此,上层的卷积可以利用下层的特征,使像素采样更密集。图3(b)说明了这一过程:在膨胀速率3的层下方放置膨胀速率6的膨胀层。对于膨胀速率为6的原始膨胀层,7像素的信息将有助于最终的计算,比原来的3像素密度更大。如此庞大接受域可以为高分辨率图像中的大物体提供全局信息[6]。
1.2.2" 卷积注意力机制
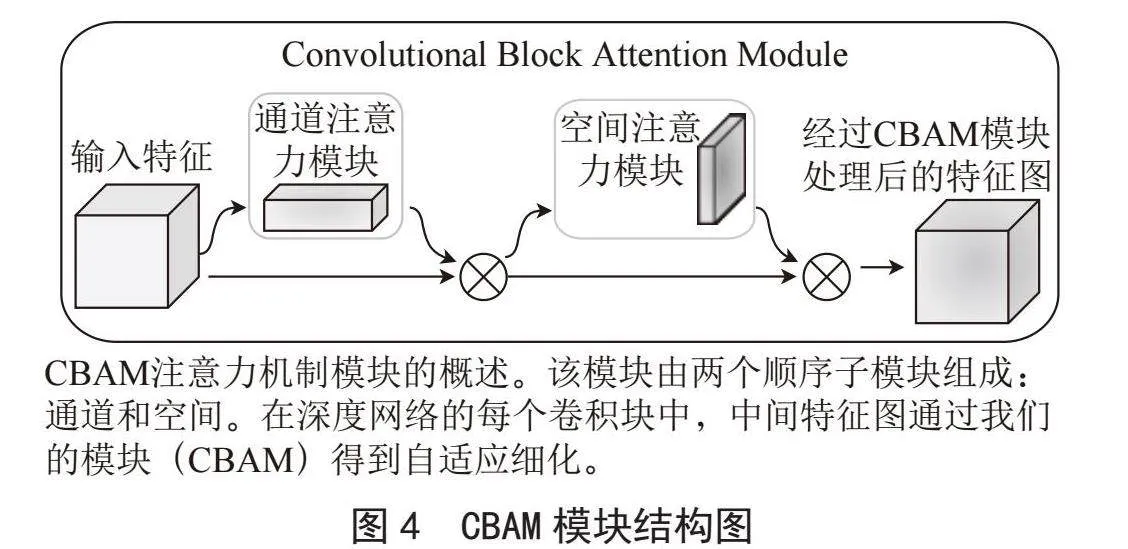
卷积注意力机制(Convolutional Block Attention Module, CBAM)[7]是一种简单而高效的注意力模块,专为前馈卷积神经网络设计。当给定一个中间特征图时,CBAM能够沿着通道和空间这两个独立的维度,依次推断出相应的注意力图。这些注意力图随后会与输入特征图相乘,从而实现对特征的自适应修饰。其结构如图4所示。
可以看到 CBAM 包含2个独立的子模块,通道注意力模块(Channel Attention Module, CAM)[8]和空间注意力模块(Spartial Attention Module, SAM),CBAM注意力机制由两个部分组成:通道注意力和空间注意力。
通道注意力机制是一种专门处理特征图通道间关系的方法。该机制首先将特征图在空间维度上进行压缩,得到一个一维矢量,以便更好地分析通道间的依赖关系。在压缩过程中,通道注意力机制不仅利用了平均值池化(Average Pooling, AP),还考虑了最大值池化(Max Pooling, MP),从而能够更全面地捕捉特征映射的空间信息。这两种池化方式分别将特征图的空间信息聚合起来,并送入一个共享网络进行处理。随后,通过逐元素求和合并这两种池化方式的结果,生成通道注意力图。由此通道注意力机制可以表达为:
Mc(F)=σ(MLP(AvgPool(F))
+MLP(MaxPool(F)))
=σ(W1(W0())" " " " " " " " (2)
+W1(W0()))
空间注意力机制聚焦于特征图中的空间位置,通过压缩通道维度来提取空间信息。在这一过程中,它分别应用了平均值池化和最大值池化。最大值池化(MaxPool)操作是在每个通道上寻找最大值,次数等于特征图的高度乘以宽度;而平均值池化(AvgPool)则是计算每个通道的平均值,同样覆盖整个空间维度。这两种池化方式生成的特征图随后合并,形成一个包含两个通道的特征图,分别代表最大和平均空间信息。经过CBAM的处理,新的特征图会获得通道和空间两个维度上的注意力权重。这种双重关注极大地加强了特征在通道和空间上的联系,使得模型能够更精确地提取目标的有效特征[9],从而提升了整体性能。该过程可按照以下公式表示:
(3)
对于输入的特征图,CBAM模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将将注意力图与输入的特征图相乘以进行自适应特征优化[10]。
2" 实验及结果分析
2.1" 实验环境
实验仿真环境为Python 3.7.12,Anaconda 3,TensorFlow 2.6.4,Keras 2.6.0,采用Linux操作系统。硬件环境为深度学习GPU运算塔式服务器主机,装有TeslaP100专业计算卡,采用GP100核心,有16 GB的HBM2显存。实验中,将学习率设置为0.001,训练批次为50,每批16个训练集。本次实验属于语义分割模型范畴,故采用处理二分类问题的交叉熵作为损失函数[11],它是基于信息熵(cross-entropy)理论计算分类结果的误差度量值。
2.2" 数据集
本实验采用Freiburg University提供的FreiHAND数据集,这是一个用于从彩色图像中估计手部姿势和形状的数据集,既可以用于算法模型的训练也可以用来作为模型的测试评估。它包含4×32 560=130 240个训练样本和3 960个评估样本,每个训练样本提供RGB图像(224×224像素),手部分割蒙版,3D形状注释,21个手部关键点的3D关键注释。对数据集采用随机排序操作,提升训练的随机性,将数据进行归一化和离散化操作,以改善模型训练和收敛能力,减少数据量,提高模型化能力。接着采用随机划分的方法将数据集分为训练集,验真集,测试集,数据量分别为1 000,500,200。
2.3" 实验分析
为了方便理解模型训练过程,实验采用梯度加权类激活映射(Gradient-weighted Class Activation Mapping, GradCAM)算法,通过观察GradCAM生成的热力图来理解模型在做出分类决策时,哪些区域对于特定类别是最重要的。这有助于探索模型的决策过程并提供可视化的解释。如图5所示,第一列为手势的原始图像。第二列为原始图像的掩码。第三列为模型预测的掩码。第四列为原始图像中重叠部分的预测,明亮的部分即时图中重叠区域的预测。第五列是GradCAM生成的热力图,其中绿色的部分即为识别出来的手势部分。
2.4" 实验结果
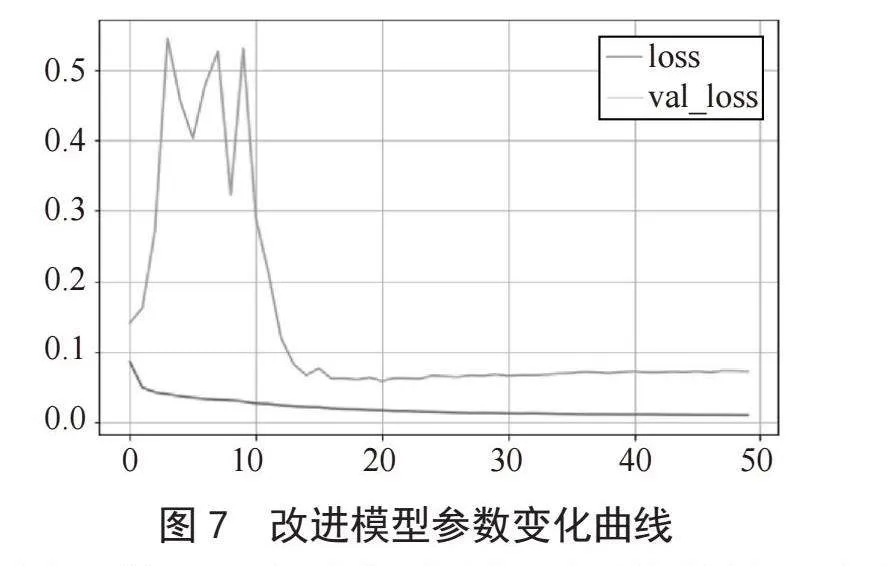
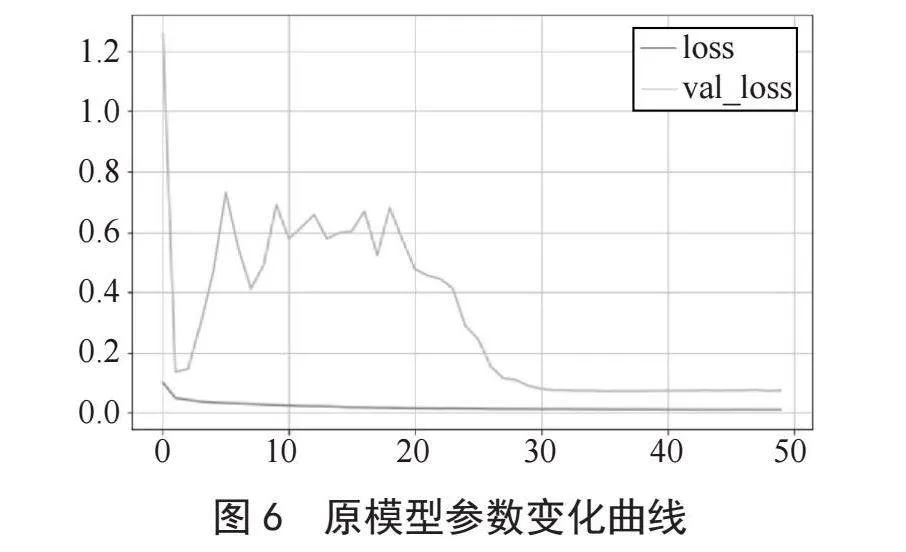
图6、7分别为原模型和改进后模型的损失率变化曲线,其中横坐标代表训练批次,纵坐标代表损失率,橙色和红色曲线分别代表模型在验证集和训练集上的损失率大小。相比较原模型,改进后的模型在收敛速度上得到显著提升,原模型从25批次时开始收敛,而改进后的模型从15批次开始收敛,在收敛速度上改进后的模型明显优于原模型。
如图8所示,为了直观地展示对比结果,本文选择了较典型的手势识别进行展示。如图8所示,(a)(b)(c)分别表示原图像,原模型分割结果,本文模型分割结果,从中可见,DeeplabV3+模型在面对复杂手势动作时,存在漏提取、误取现象。本文模型在提取效果上要优于DeeplabV3+模型,对于手指凹凸区域轮廓也能准确提取。
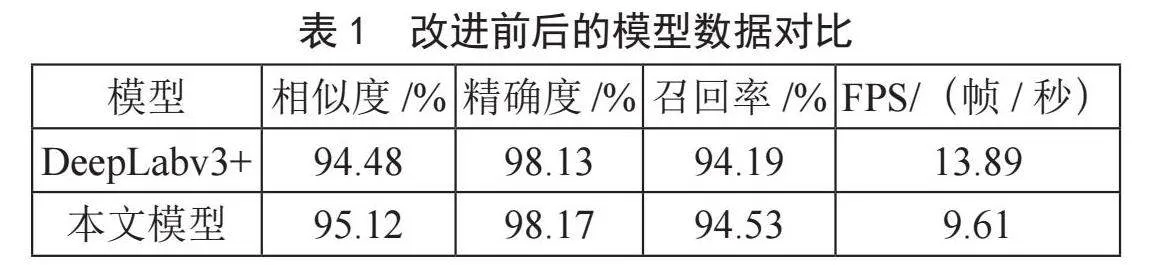
为了从数值上更加准确的感受到改进模型的优势,实验中运用到了相似度,精确度,准确率等计算方法来评估比较模型的相关性能。相似度的计算使用ResNet50模型对预测后的图像和标签图像进行预测,得到图像的特征向量。然后将两张图片的特征向量进行比较,使用余弦相似度来评估它们的相似性(余弦相似度是一种度量两个向量之间相似度的方法,它的值范围在-1到1之间,当两个向量的方向相同时余弦相似度接近1),最终计算得到的余弦相似度得分。精确度(Accuracy)和召回率(Recall)的计算涉及混淆矩阵的计算,通过标签与预测结果来构造混淆矩阵,从而得到正确预测的正样本(TP),错误预测的正样本(TP),错误预测的阴性样本(FN),正确预测的阴性样本(TN)等数值。通过式(4)和式(5)的计算最终得到模型的精确度和准确率。相关实验数据统计如表1所示。从结果分析计算得到改进后的模型识别精确度提升了0.04%,相似度提升了0.68%,召回率提高了0.36%。
Accuracy=TP/(TP+FP) (4)
Recall=TP/(TP+FN) (5)
改进后的模型不仅分割效果更优而且在单张图片运行速度(ms)与大小(MB)上也更优。在每秒处理照片的效率上,改进后的模型速度提升约6帧/秒,有效提升了模型的使用成本。
3" 结" 论
本文对DeeplabV3+模型在手势识别研究中未考虑的多时相、特征多样性等问题,提出了一种新兴的改进算法。我们通过对DeeplabV3+模型中的ASPP模块进行结构改进,同时优化了模型的特征提取网络,并且增加了CBAM注意力机制,从而提升了手势识别的准确性和效率。在FreiHand数据集上进行验证,实验结果证明,本文提出的算法可以增强原模型对复杂手势的分割效果,处理模型的速度也有所提高。同时还存在着处理时间久,计算量大的问题,未来将聚焦于降低模型复杂度,减少计算量等方面。
参考文献:
[1] 房爱印,尹曦萌,谢成磊,等.一种提升水尺水位识别响应速度的方法、设备及存储介质:CN116883808A [P].2023-10-13.
[2] 武霞,张崎,许艳旭.手势识别研究发展现状综述 [J].电子科技,2013,26(6):171-174.
[3] 徐建功,马晓双.基于深度学习的极化SAR影像海面溢油检测研究 [C]//第七届高分辨率对地观测学术年会.长沙:[出版者不详],2020:804-812.
[4] 姬晓飞,张可心,唐李荣.改进DeepLabv3+网络的图书书脊分割算法 [J].计算机应用,2023,43(12):3927-3932.
[5] 曹连雨,张小璐.语义分割方法、装置、计算机设备和存储介质:CN116543161A [P].2023-08-04.
[6] 戴伟达.基于全卷积神经网络的语义分割算法研究 [D].南京:南京邮电大学,2019.
[7] 刘祥.基于卷积神经网络的遥感图像目标检测 [J].微型电脑应用,2021,37(7):127-130.
[8] 陈茂龙.基于深度学习的肺结节特征提取与病灶检测算法研究 [D].长春:长春工业大学,2023.
[9] 何东宇,朱荣光,范彬彬,等.倒置残差网络结合注意力机制的掺假羊肉分类检测系统构建 [J].农业工程学报,2022,38(20):266-275.
[10] WOO S H,PARK J C,LEE J Y,et al. CBAM: Convolutional Block Attention module [C]//Proceedings of the European Conference on Computer Vision (ECCV).Munich:Springer,2018:3-19.
[11] 胡家珩,岑咏华,吴承尧.基于深度学习的领域情感词典自动构建——以金融领域为例[J].数据分析与知识发现,2018,2(10):95-102.
作者简介:王宇(2004—),男,汉族,江苏宿迁人,本科在读,研究方向:人工智能。