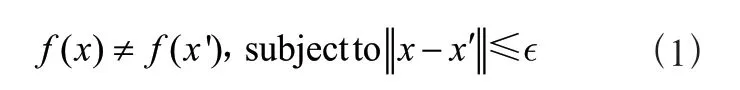


摘" 要:在信息化时代教育变革的背景下,个性化学习逐渐成为研究的焦点,实现个性化学习的关键之一是对学习者的认知能力进行精准评估,以便对学生成绩做出准确预测。文章基于认知诊断和集成学习理论,提出了一种基于多特征认知诊断的学生成绩预测模型,综合考虑学生的潜在能力特质和知识点掌握程度对答题表现的影响,旨在提高成绩预测的准确性。通过对比实验、参数敏感性实验和案例分析,验证了模型的有效性。
关键词:认知诊断;集成学习;成绩预测
中图分类号:TP391.1" 文献标识码:A" 文章编号:2096-4706(2024)23-0033-04
Student Performance Prediction Model Based on Multi-feature Cognitive Diagnosis
LI Shulin1, LI Zilin2
(1.Guangyuan Lizhou Secondary Specialized School, Guangyuan" 628017, China;
2.North Sichuan College of Preschool Teacher Education, Guangyuan" 628017, China)
Abstract: In the context of educational reform in the information age, personalized learning has gradually become a focal point of research. One of the key aspects of achieving personalized learning is the precise assessment of learners cognitive abilities to accurately predict student performance. Based on cognitive diagnosis and Ensemble Learning theories, this paper proposes a student performance prediction model based on multi-feature cognitive diagnosis, which comprehensively considers the impact of students latent ability traits and mastery degree of knowledge points on answering performance, aiming to improve the accuracy of performance prediction. Through comparative experiments, parameter sensitivity experiments and case analysis, the effectiveness of the model is verified.
Keywords: cognitive diagnosis; Ensemble Learning; performance prediction
0" 引" 言
《中国教育现代化2035》[1]指出,要加快信息化时代教育变革。建设智能化校园,统筹建设一体化智能化教学、管理与服务台。随着教育信息化的持续深入以及互联网的迅猛发展,在线教育已成为计算机融合传统教育领域而形成的一个新的重要研究和应用方向[2]。认知诊断是在线教育中对学生的认知水平进行分析的重要理论。通过模型分析后的数据,教师可以掌握学生的详细情况,进而做到有的放矢。
认知诊断作为个性化学习的核心技术,已有30多年的发展历史。认知诊断可以对学生的知识结构和认知过程进行评价。传统的认知诊断模型通常依赖于人为设计的交互函数,其中最经典的就是确定性技能诊断模型(DINA[3]),随着时代发展,技术的进步,深度学习在不同的领域都取得了不错的结果,2020年Wang等人通过神经网络应用与教育认知诊断相结合,提出了神经认知诊断模型[4],它借助神经网络对学生、试题、学生与试题的交互过程三者进行建模,提高了模型的学习能力,之后又在此模型上进行了扩展,在该模型的基础上考虑知识点之间的隐性关系对学生知识点掌握程度的影响,实现了深度学习与认知诊断的结合。
为了发挥不同认知诊断模型的优势,本文采用了集成学习算法。集成学习模仿了人类在做出重大决策前会寻求多种意见来辅助判断的行为。人类做出重大的决定前会寻求多种意见来辅助决策,集成学习算法就是模仿这种行为而产生[5]。通过结合多个基学习器的优势,集成学习可以提升模型整体的效果。集成学习更多的是一种框架思想,因此集成学习与其他机器学习方法无缝结合成为可能[6]。
目前的认知诊断模型主要集中于诊断学生的知识点掌握情况,往往忽略了学生潜在能力特质的影响。本文提出了一种基于多认知诊断模型集成的学生成绩预测方法,综合考虑学生的潜在能力特质和知识点掌握程度对答题表现的影响,以提高预测的准确性和全面性。
1" 模型架构
模型的构建基于集成学习Stacking思想,通过集成多维项目反应理论模型和基于深度学习的认知诊断模型,综合考虑了学生的潜在能力特质和知识点掌握程度特征,得到更准确的评估。
1.1" 模型框架
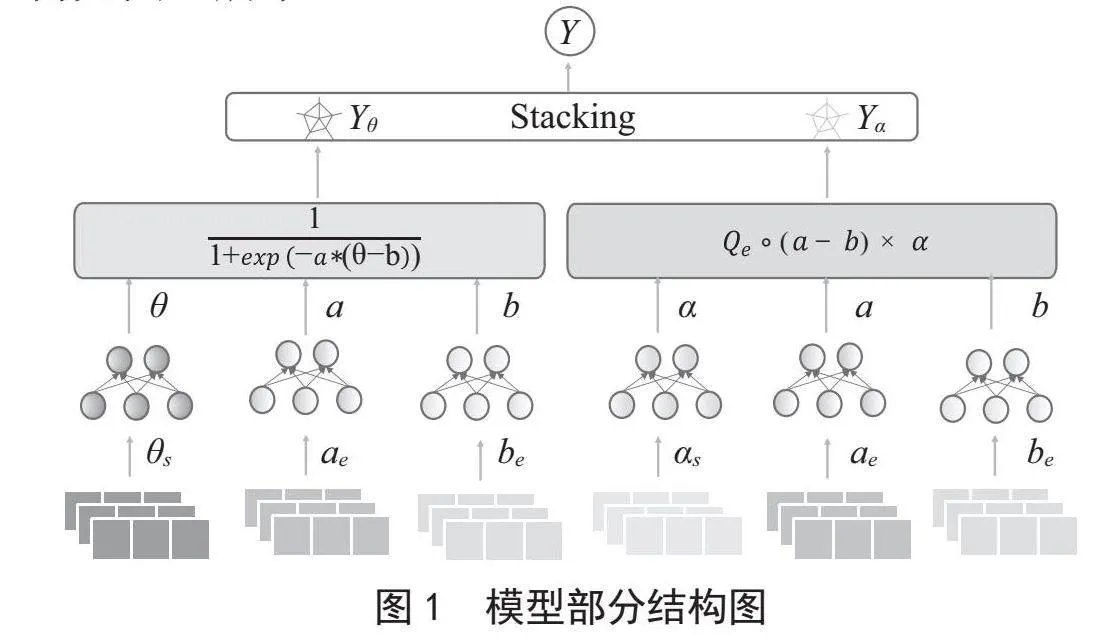
该模型将神经认知诊断模型与多维项目反应理论模型进行集成,在预测的时候同时考虑了知识点掌握程度和潜在能力特质对答题情况的影响。模型部分结构如图1所示。
1.2" 模型输入层
该文将学生的特征以及试题特征分别送入模型中,学生的特征以θ与α来表示本文认为学生的知识点掌握程度以及能力均是连续的,其每个数都介于0到1之间。其中θs以及αs可以通过学生的独热码向量xs以及深度网络训练出来的矩阵得到,如式(1)所示:
θs,αs⇒X s (1)
试题难度与区分度也会影响学生知识点的掌握情况,因此利用b向量来表示试题的难度特征,而a表示试题区分度向量,其向量的每个数都介于0到1之间,为连续小数。a、b可以通过试题的独热码向量xe和通过深度学习训练出来的B、C矩阵得到,如式(2)所示:
a,b⇒X e (2)
1.3" 模型中间层
在得到向量θs、αs、a、b后,再将此向量分别送入式(3)和(4)。其中Qe为Q矩阵向量,即该题所包含的知识点。根据公式即可分别得到知识点掌握程度,以及学生的潜在能力值。
(3)
(4)
1.4" 模型输出层
在得到θ与α之后,将此向量进行拼接,送入全连接层,如式(5)所示:
(5)
在模型训练阶段,通过最输出试题答对的概率和正确标签之间的标准交叉熵损失来学习模型的参数,如式(6)所示。其中ytrue表示真实的答题结果,取值为0或1,表示学生的答题是错误还是正确。通过将这个损失最小化,模型的参数w和b将被调整,从而使模型在测试数据上可以更准确地预测学生答题的正确性。
(6)
2" 实验结果及分析
2.1" 数据集
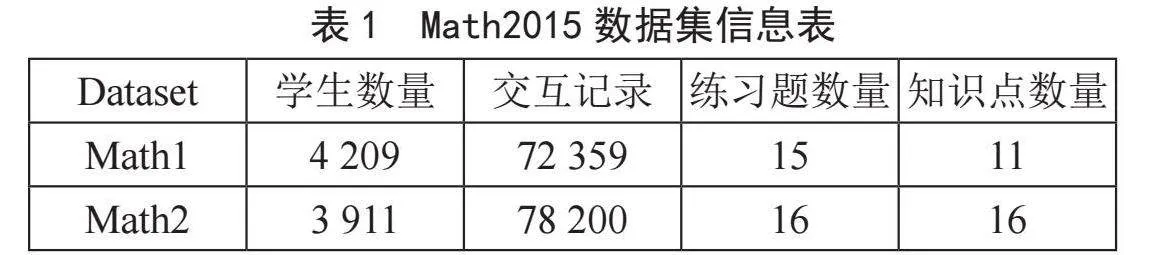
实验采用Math2015数据集。该数据集中包含Math1和Math2两个数据集的信息,如表1所示。
Math1数据集(http://staff.ustc.edu.cn/~qiliuql/data/math2015.rar)是某高中最终数学测试的数据,测试练习包括客观练习和主观练习。该数据集有72 359个交互记录,4 209个学习者,15个客观练习题,5个主观练习题和11个知识概念。这里采用Math1数据集中的客观题部分来进行实验。
Math2数据集(http://staff.ustc.edu.cn/~qiliuql/data/math2015.rar)是某高中最终数学测试的数据,测试练习包括客观练习和主观练习。该数据集有62 578个交互记录,3 911个学习者,16个客观练习题,4个主观练习题和16个知识概念。这里采用Math2数据集中的客观题部分来进行实验。
2.2" 实验参数和评价指标
本文实验使用的主要的参数如下:
1)批大小(batch_size)。批大小用于指定每次送入网络中训练数据样本的大小,本研究批大小设置为32。
2)学习率(learning_rate)。学习率用来控制网络参数权重的更新幅度,本研究最终设置学习率为0.002。
3)迭代次数(epoch)。深度学习模型中的迭代次数代表模型进行完整训练的次数,本文设定迭代次数为30。
4)优化器(optimizer)。基于梯度使用不同的优化器来最小化损失函数会有不同的效果,本研究选择的优化器为Adam[7]算法。
同时本研究采用了以下四个评价指标:准确性(ACC)、曲线下面积(AUC)、均方根误差(RMSE),与神经认知诊断(NCDM)保持一致。
2.3" 对比实验
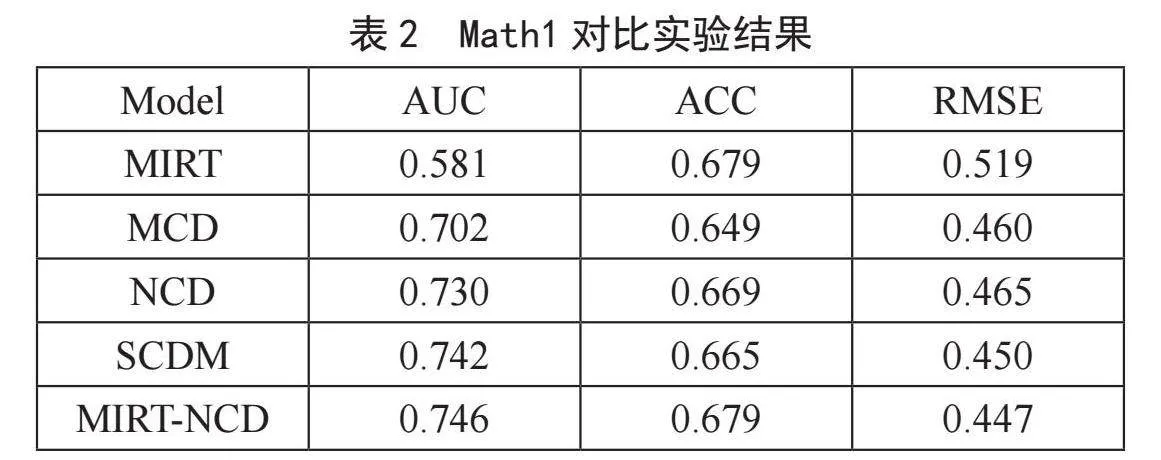
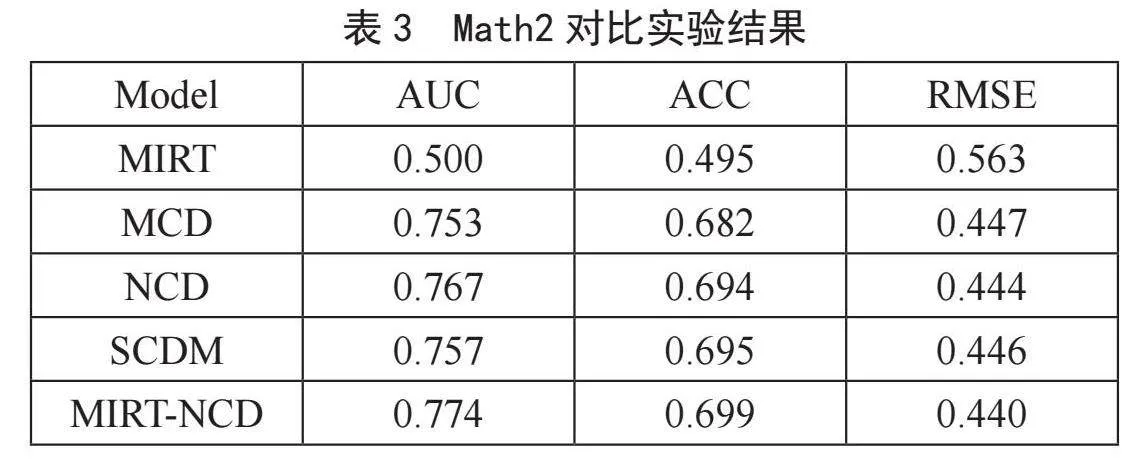
选取的基线有MIRT[8]、MCD、NCD[4]和SCDM[9],其中MIRT属于项目反应理论,MCD为数据挖掘下的认知诊断模型,NCD与SCDM均为深度学习下的认知诊断模型,Wang等人[4]和Gao等人[10]的研究证明,将训练集和测试集按8∶2的比例划分可以获得最佳的实验结果。数据集随机划分为8∶2分别作为训练集和测试集,在测试集上进行对比实验。实验结果如表2和表3所示。
2.4" 超参数敏感性实验
参数敏感性实验对评估模型在不同参数配置下的性能表现起到重要作用。本实验分别从batch_size参数敏感性和learnig_rate参数敏感性入手。
2.4.1" batch_size 参数敏感性实验
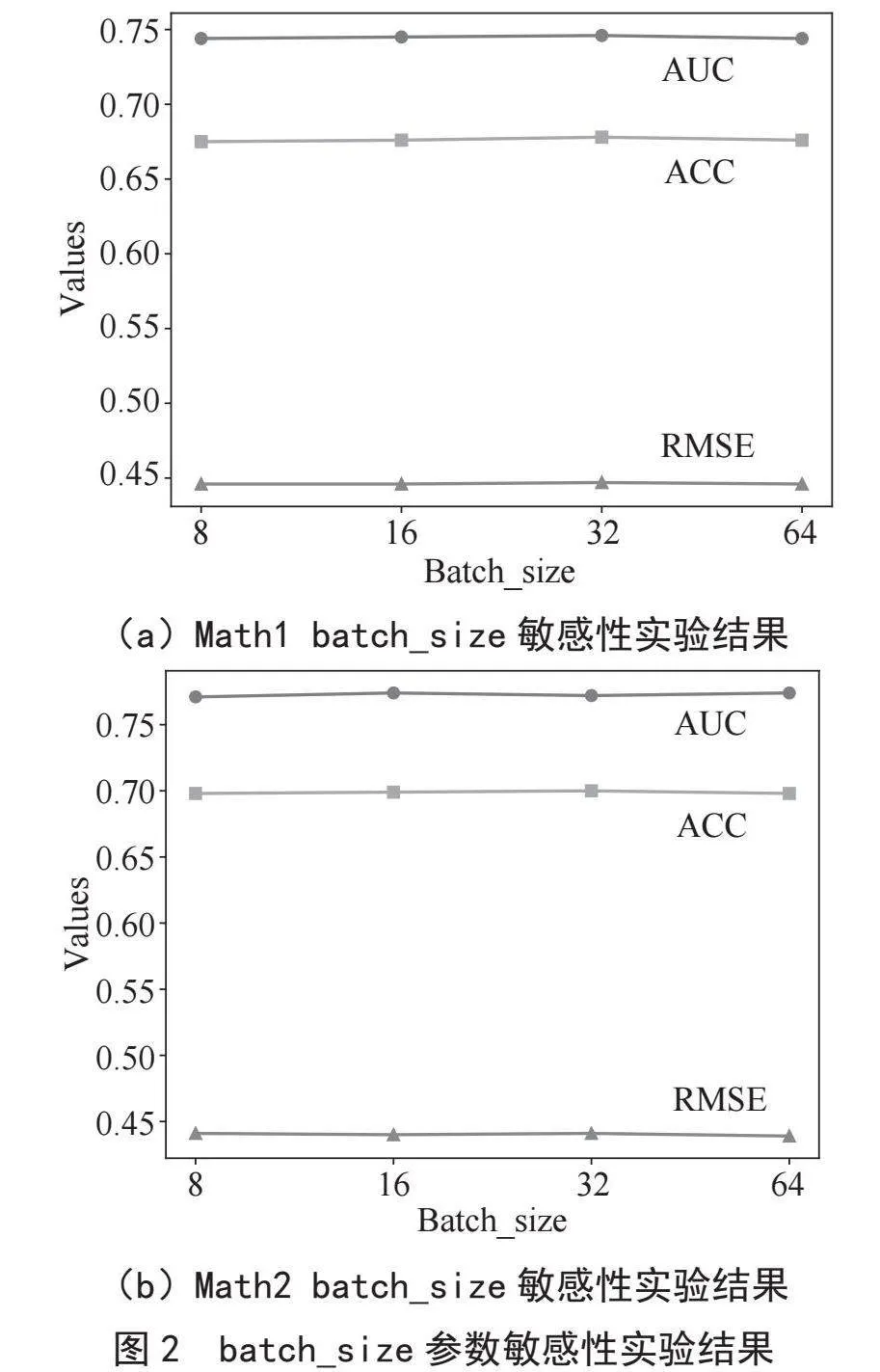
batch_size定义了每次迭代训练时用于更新模型权重的样本数量。本实验将batch_size分别设置为8、16、32和64,从而了解不同batch_size对实验结果的影响。本实验在Math1和Math2两个数据集上分别进行。结果表明,batch_size设为不同值时,曲线下面积(AUC)值和准确性(ACC)值均相对稳定,即本模型在两个数据集上对batch_size大小变化的敏感度较低,表现相对稳定。实验结果如图2所示。
2.4.2" learnig_rate参数敏感性实验
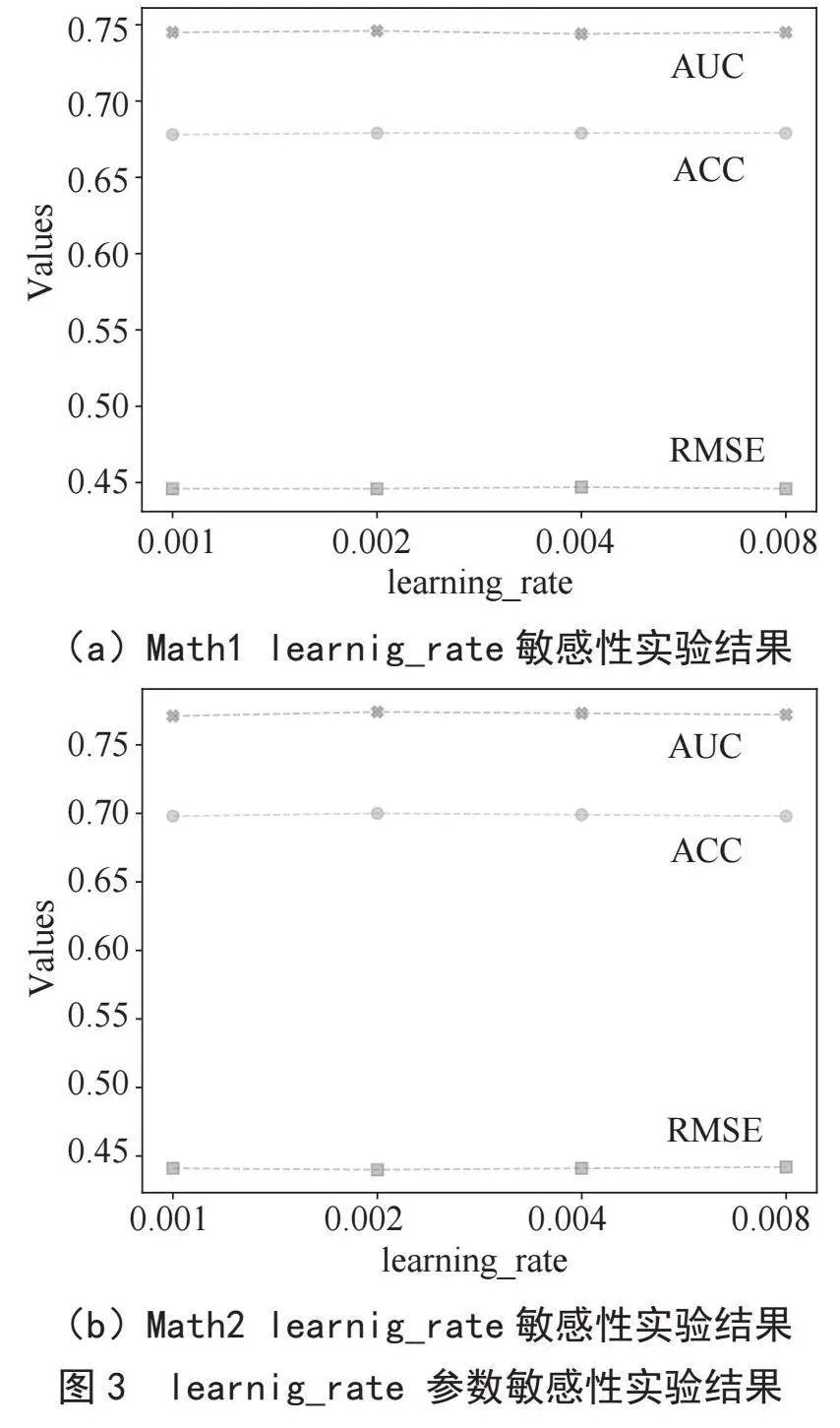
learnig_rate用于确定每次迭代中的步长,使损失函数收敛到最小值。本实验将learnig_rate分别设置为0.001、0.002、0.004和0.008,从而了解不同learnig_rate对实验结果的影响。同样,本实验在Math1和Math2两个数据集上分别进行。结果表明,learnig_rate设为0.002时,AUC和ACC的值达到最佳表现。而learnig_rate在其他值时,模型的表现也相对稳定。实验结果如图3所示。
2.5" 案例分析
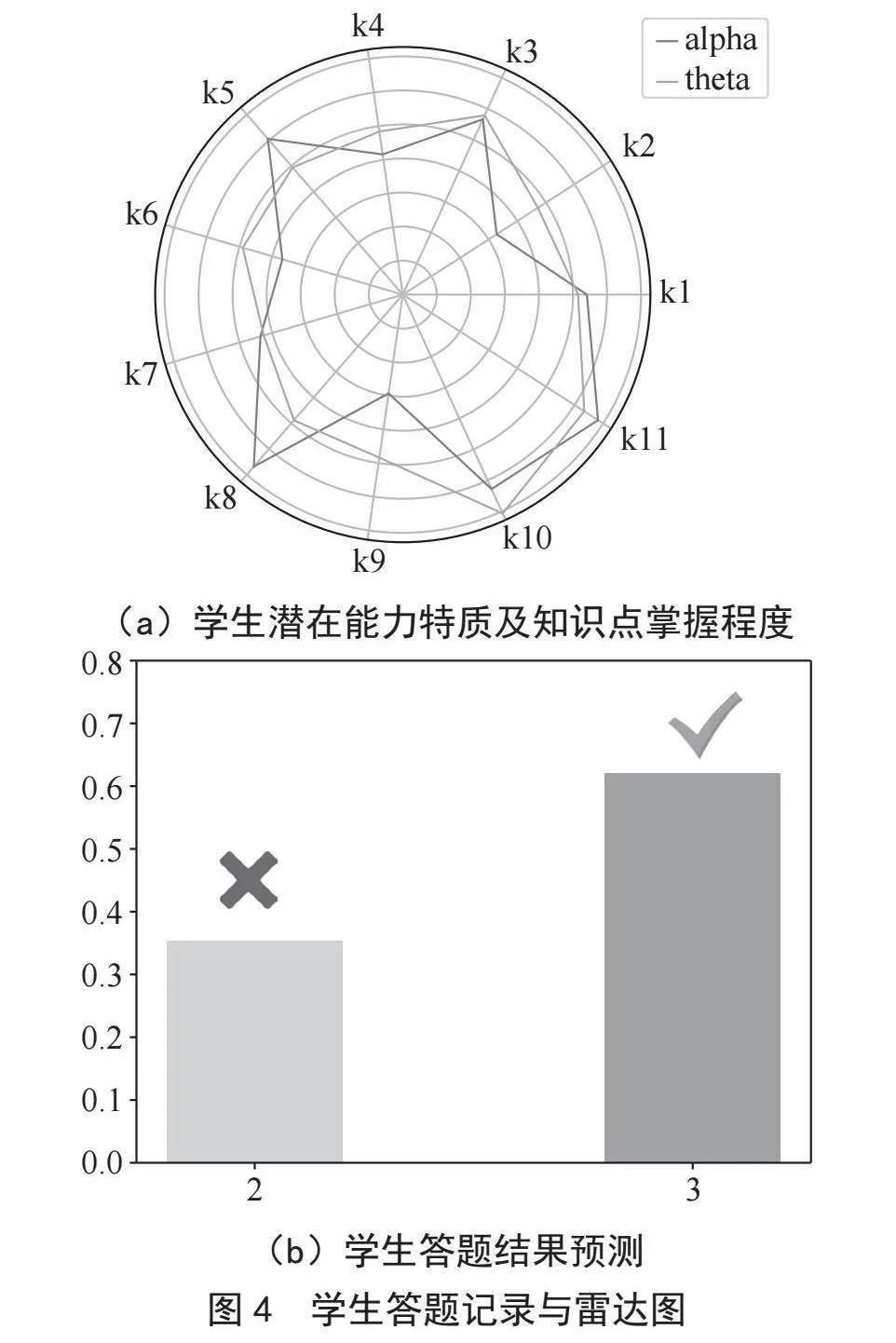
本文随机选取了一名学生,通过雷达图对其知识点掌握程度及潜在能力特质进行了可视化分析,并基于此对该学生在第2题和第3题的答题情况进行了详细分析。第2题和第3题分别涉及第3、8和第3、11知识点。可视化分析结果如图4所示。
从图中可以看到,学生答错了第2题。首先,学生在第3知识点的潜在能力特质与知识点掌握程度相当。但在第8知识点上,虽然学生掌握了该知识点,其潜在能力特质较低,导致第2题答错。而对于第3题,学生答对了,这主要归因于其在第11知识点上的潜在能力特质和知识点掌握程度得分较高。因此,可以得出结论,学生的潜在能力特质对其答题情况有一定的影响。
3" 结" 论
准确预测学生的学习成绩对教师掌握学生的学习情况具有重要意义,有助于提高教学质量、促进学生学业进步,并有针对性地培养学生的能力。本文采用集成学习方法,结合多种认知诊断模型的优势,综合考虑了不同特征,不仅能够更准确地评估学生对知识点的掌握情况,还能揭示学生的潜在能力特质。未来的研究将重点探索如何结合更多学生的学习特征,以进一步提升模型的整体表现。
参考文献:
[1] 新华社.中共中央、国务院印发《中国教育现代化2035》 [R/OL].(2019-02-23).https://www.gov.cn/zhengce/ 2019-02/23/content_5367987.htm.
[2] 刘淇,陈恩红,朱天宇,等.面向在线智慧学习的教育数据挖掘技术研究 [J].模式识别与人工智能,2018,31(1):77-90.
[3] TORRE J D L,DOUGLAS J A J P. Higher-Order Latent Trait Models for Cognitive Diagnosis [J].2004,69(3):333-353.
[4] WANG F,LIU Q,CHEN E H,et al. Neural Cognitive Diagnosis for Intelligent Education Systems [C]//Proceedings of the AAAI Conference on Artificial Intelligence.New York:AAAI Press,2020,34(4):6153-6161.
[5] 徐继伟,杨云.集成学习方法:研究综述 [J].云南大学学报:自然科学版,2018,40(6):1082-1092.
[6] DONG X B,YU Z W,CAO W M,et al. A survey on ensemble learning [J].Frontiers of Computer Science,2020,14:241-258.
[7] KINGMA D P,BA J. Adam: A Method for Stochastic Optimization [J/OL].arXiv:1412.6980 [cs.LG].[2024-09-06].https://doi.org/10.48550/arXiv.1412.6980.
[8] YAO L H. A Multidimensional Partial Credit Model With Associated Item and Test Statistics: An Application to Mixed-Format Tests [J].2006,30(6):469-492.
[9] SHEN J H,QIAN H,ZHANG W,et al. Symbolic Cognitive Diagnosis via Hybrid Optimization for Intelligent Education Systems [C]//Proceedings of the AAAI Conference on Artificial Intelligence.Vancouver:AAAI Press,2024,38(13):14928-14936.
[10] GAO W B,LIU Q,HUANG Z Y,et al. RCD: Relation Map Driven Cognitive Diagnosis for Intelligent Education Systems [C]//SIGIR21: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval.[S.I.]:Association for Computing Machinery,2021:501-510.
作者简介:李姝霖(1999—),女,汉族,四川广元人,助理讲师,硕士研究生,研究方向:智能教育;李子林(1993—),男,汉族,黑龙江哈尔滨人,专任教师,硕士研究生,研究方向:智能教育。