
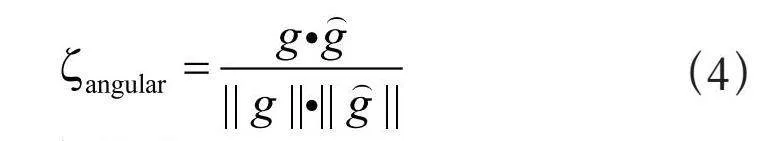

摘" 要:近年来,基于外观的注视估计取得了显著进展。然而,现有方法多以庞大的网络参数量为代价来提高精度,使得模型的开发部署成本昂贵。针对此问题,提出一种基于多级特征提炼的轻量化注视估计网络(Lightweight Network with Multi-level Feature Refining, LMLFR-Net)。其包含一种轻量级特征提取模块(SECA)和一种轻量级多级特征提炼模块(FRM)。SECA融合了挤压激励和协调注意力,以提高模型对特征的精化能力;FRM将主干网络的多级特征进行融合提炼,通过同时利用低层与高层特征,提升了模型对细节的捕获能力,在不显著增加参数量的同时,改善轻量级网络的估计精度。实验表明,所提出的网络在MPIIFaceGaze数据集上的估计精度相比FAR-Net提升了2.14%,参数量减少了85.35%,表现出了良好的轻量化性能。
关键词:注视估计;轻量化网络;注意力机制;特征提炼
中图分类号:TP391.4" 文献标识码:A" 文章编号:2096-4706(2024)23-0028-05
Lightweight Gaze Estimation Method Based on Multi-level Feature Refining
ZHOU Guangao, TAO Zhanpeng
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan" 232001, China)
Abstract: Appearance-based gaze estimation has made significant progress in recent years. However, existing methods mostly improve accuracy at the expense of a huge amount of network parameters. This makes the development and deployment cost of the model expensive. In view of this problem, a lightweight gaze estimation network based on multi-level feature refining (Lightweight Network with Multi-level Feature Refining, LMLFR-Net) is proposed. It includes a lightweight feature extraction module (SECA) and a lightweight multi-level Feature Refining Module (FRM). SECA combines Squeeze-and-Excitation and Coordinate Attention to improve the models ability to refine features. FRM integrates and refines the multi-level features of the backbone network, and improves the models ability to capture details by simultaneously utilizing low-level and high-level features. It improves the estimation accuracy of lightweight networks without significantly increasing the number of parameters. Experiments show that the estimation accuracy of the proposed network on the MPIIFaceGaze data set is improved by 2.14% compared to FAR-Net, and the number of parameters is reduced by 85.35%, showing good lightweight performance.
Keywords: gaze estimation; lightweight network; Attention Mechanism; feature refining
0" 引" 言
视觉信息在人类获取的外界信息中所占比例高达80%,眼睛通常被认为是心灵的窗口,在非语言交际中起着至关重要的作用。眼睛注视的方向为理解人类认知和行为提供了至关重要的线索。注视估计是一种融合了计算机视觉和机器学习等多学科前沿技术,通过分析眼部特征和眼睛运动规律来对人的注意力进行预测的技术。目前,注视估计已被广泛应用于人机交互[1]、增强现实/虚拟现实[2]、自动驾驶[3]等领域,为这些领域的发展和创新提供了有力支撑。
人们对注视估计方法的研究可分为两类:基于模型和基于外观。传统的基于模型的方法需借助特定的仪器(例如红外相机)来获取特征,其成本较高,因此通常仅适用于实验室环境。相反,基于外观的注视估计方法则直接从面部图像中提取特征,一般仅需使用普通相机,并表现出更好的鲁棒性。近年来,随着深度学习技术的兴起,研究者开始探索将卷积神经网络(CNN)引入基于外观的注视估计。例如,Zhang等人[4]首次提出利用CNN进行基于全脸图像的注视估计模型Full-Face。该模型设计了一种空间加权机制,对人脸各个区域的信息进行加权,以增强特征表征。最近,OH等人[5]在提出的基于面部图像的注视估计网络中融合了卷积、自注意力和反卷积等技术。此外,当前的研究还涉及基于弱监督学习[6]和基于对比学习[7]等方法的注视估计。受益于大量相关数据集的公开,基于CNN的注视估计方法取得了较高的准确度。然而,随着模型准确度的提高,网络参数量也在剧增。当前提出的注视估计模型参数庞大,这给模型的训练和实际部署带来了挑战。因此,如何进行模型轻量化,已成为该领域急需解决的问题。
针对轻量化问题,目前主要有两个研究方向:一是对训练好的复杂网络进行压缩(模型剪枝、知识蒸馏等)得到轻量化网络,二是直接设计轻量化网络进行训练。本文针对注视估计任务提出了一种新型的轻量化注视估计模型LMLFR-Net。LMLFR-Net由一个用于特征提取的轻量级注意力特征提取模块(Squeeze-and-Excitation and Coordinated Attention Feature Extraction Module, SECA)和一种轻量级多阶段特征提炼模块(Multi-level Feature Refining Module, FRM)组成。其中SECA通过将挤压激励(Squeeze-and-Excitation, SE)模块和协调注意力(Coordinate Attention, CA)模块相结合,增强了模型对全局特征的细化能力,显著降低了模型参数以及计算复杂度。FRM通过捕获主干网络的多级特征信息,提高模型对细节的捕获能力,在保证参数量不显著升高的前提下,改善了轻量级网络的注视估计精度。
1" 模型设计
1.1" 整体架构
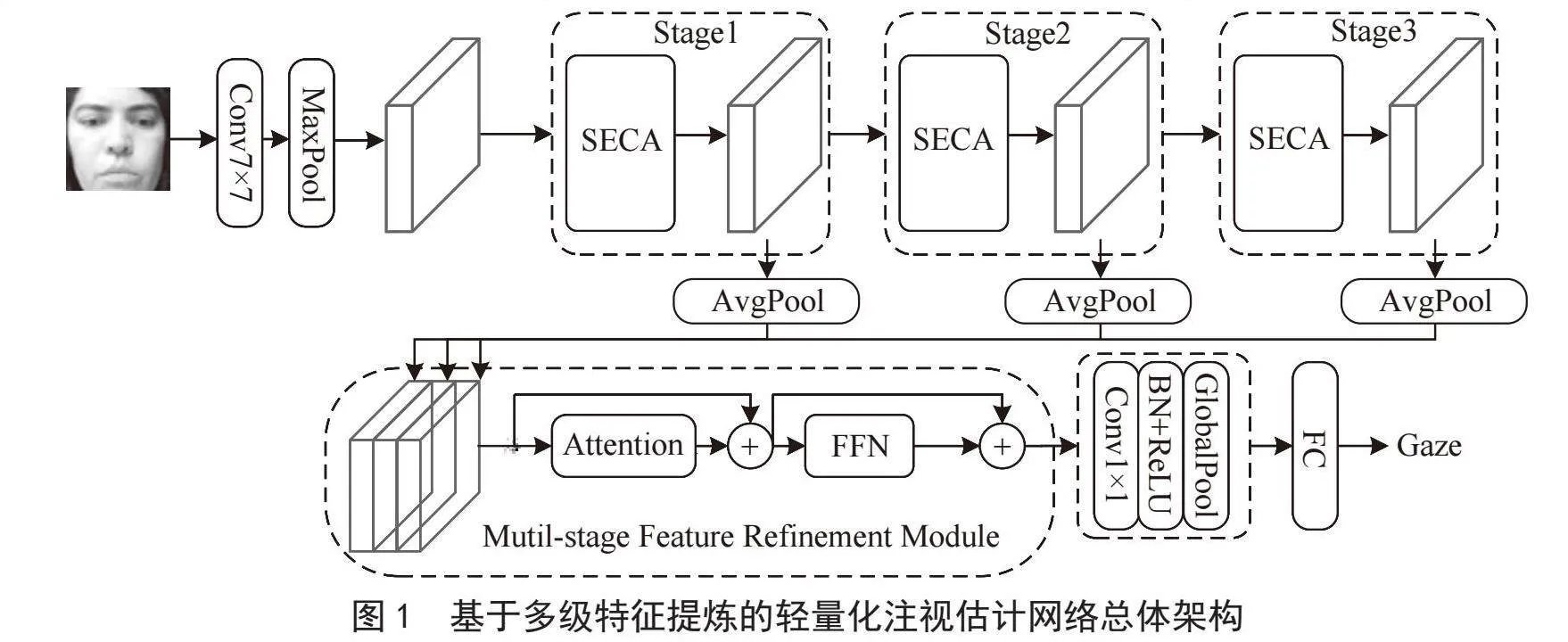
本文提出的LMLFR-Net总体架构如图1所示。在网络最初阶段,首先采用7×7卷积和最大池化操作来对特征图进行维度调节。在提取出基础特征的基础上减小了特征图的维度,有利于参数量的减少和后续的处理。在此基础上,设计了一个由三个阶段组成的主干网络,分别使用SECA特征提取模块进行特征提取。之后,各阶段生成的特征图通过平均池化进行维度对齐后,统一输入FRM模块中,实现对多级特征信息的提炼,有效利用低层和高层特征,进一步提升模型的精度。最后,通过1×1的卷积以及池化来调整特征图的维度,并将特征图转换为一维向量输入全连接层进行注视估计回归预测。
1.2" SECA轻量级特征提取模块
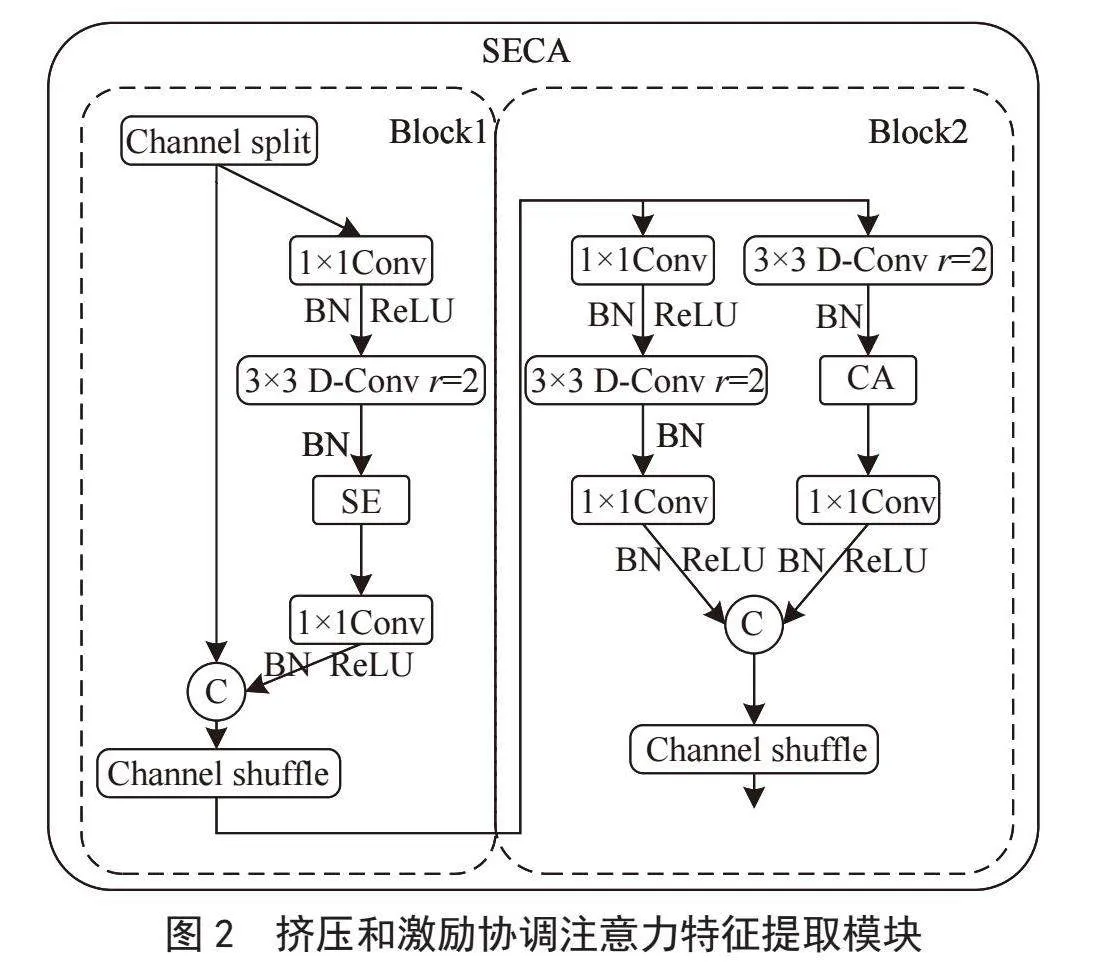
如图2所示,SECA轻量级特征提取模块的设计借鉴了ShuffleNetV2[8]的Shuffle结构。考虑到并行使用SE和CA两种注意力机制(如图2)会产生重叠或冗余信息,导致算法的训练和部署开销增加。本文采用新的思路,串行使用两者。SE模块会先通过训练学习到多个通道之间的关联关系,然后通过对通道特征进行加权,除去无关信息,增强对有效信息的表征能力。紧接着将结果传递给CA模块进行空间注意力加权。这种串行设计使得通道与空间的关联更加明确,降低了模型的重复计算,提升了模型的估计精度。与此同时,本文将利用一个膨胀率为2的3×3空洞卷积(Dilated Convolution, D-Conv)代替深度可分离卷积(DWConv)。该方法可以在不明显增大运算量的前提下,获得更大的感知野,从而加快了网络的学习与推理。
在SECA模块的Block1中,先利用通道分割(Channel Split)方法对特征进行通道划分。这一操作是为了减少随后各层的计算负担。然后,通过1×1卷积进行特征融合。其次,使用批归一化(Batch Normalization, BN)和ReLU激活函数对特征进行标准化处理的同时引入非线性特征,增强模型的表达能力。接下来,通过3×3的空洞卷积增加感受野,在不额外增加参数量的情况下,获取更大范围的上下文信息。后续SE模块通过学习特征图通道间的相互依赖性,实现对通道响应的动态调整,凸显有利特征。接着,一组1×1卷积被用来对特征进行后续的变换与融合,再通过通道合并将处理过的两个特征子集进行合并,输入到最后一层进行通道洗牌(Channel Shuffle),实现特征重构。实现了不同组之间的信息的高效交互,提高模型对多元特征的捕获与融合能力以及泛化性能。挤压和激励模块、协调注意力模块如图3所示。
Block2类似Block1,但由于Block1已经进行了通道划分,Block2采用分组卷积实现特征信息的抽取,并使用协调注意力CA来对进行加权。这一步骤旨在深入挖掘提炼图像中的特征,提高网络对有益特征的学习能力。在此基础上,将两组特征进行合并,使用通道洗牌交互重组,确保模型能够学习到更为复杂和有效的特征表示,为后续的预测提供更多特异性信息。
1.3" FRM特征提炼模块
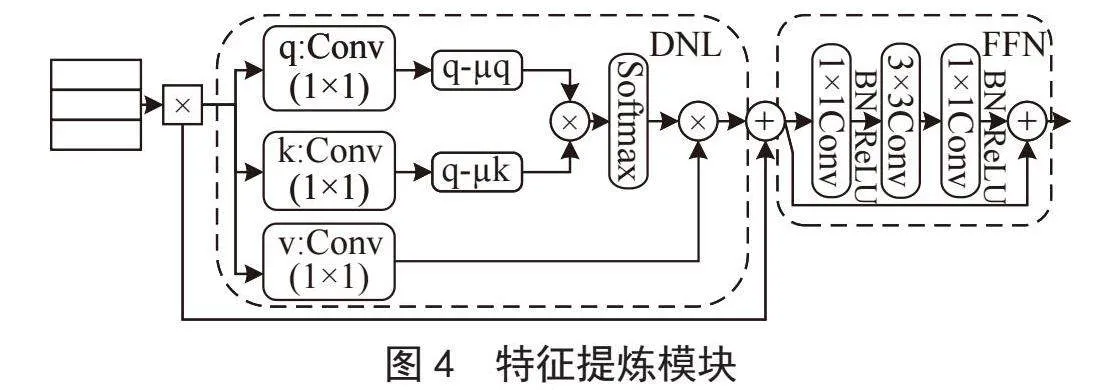
为提炼出更丰富注视相关特征信息,本文提出了特征提炼模块FRM,如图4所示。与仅使用轻量化骨干网络的最后一级特征不同,FRM将所有3个阶段的特征进行融合,从而更好地挖掘轻量级主干各个阶段的优势信息。
具体地,FRM采用平均池化方法进行多尺度特征的对齐,然后将它们拼接在一起。过程如下:
(1)
其中,Cat()表示拼接操作;avgpool()表示平均池化操作;F1、F2、F3分别表示来自三个阶段的输出特征。FRM模块利用解耦非局部块(Disentangled Non-local Block, DNL)来增强各区域间的相关性,从而获得全局的上下文信息。在此基础上,根据各像素点之间的相关性,DNL块自适应地对各区域进行加权处理,提炼优势信息。具体来说,每个像素的上下文是通过计算拼接的特征Fc中所有像素的加权和来评估的。用xi表示位置i处的值,DNL的输出yi计算为:
(2)
其中,w(xi,xj)表示xi、xj的相似度;g(xj)表示xj的一元变换。Ω表示所有像素的集合。权重函数w(xi,xj)定义为:
(3)
其中,σ()表示Softmax函数。将嵌入qi、kj矩阵使用1×1卷积分别计算为Wq xi和Wk xj。Wq、Wk为待学习的权值矩阵。之后对qi和kj进行归一化,减去其均值μq和μk。在归一化后进行矩阵相乘,然后,使用Softmax函数进行归一化,再通过元素加法与矩阵乘法运算,就可以获得后续需要的精炼特征。
FRM模块利用前馈网络FFN以期提升网络表征能力。FFN由两个1×1卷积、一个3×3卷积组成。其中,FFN使用1×1卷积对输入图像特征进行线性变换,扩展通道的维数,使其能够捕获更多维度的信息。随后通过3×3卷积和BN、ReLU,实现更大范围的空间特征抽取,增强其对复杂场景的处理能力。最后,再次利用1×1卷积进行线性变换,调整特征通道的维数,减少后续层的计算量。FRM模块充分使用到了所有阶段的特征信息,使得不同层级上的特征得到了有效的整合,增强了特征的丰富性和表征能力。提高了轻量级网络特征提取精炼能力,极大提升了模型的注视估计准确性。
2" 实验结果与分析
2.1" 数据集与评价指标
本文实验在主流数据集MPIIFaceGaze[4]上进行。MPIIFaceGaze数据集是一个广泛用于注视估计研究的公开数据集。该数据集由德国马普学会计算机科学研究所的研究人员创建,并提供了大量的面部图像和相应的注视位置标注。这些注视位置标注指示了被拍摄者在图像中所看的方向,为研究者提供了理想的资源来训练和评估注视估计算法。MPIIFaceGaze数据集包含15个参与者的45 000张图像,这些图像是通过在笔记本电脑屏幕上向参与者显示随机点来收集的,包含了来自不同场景和不同人群的图像,这些图像涵盖了不同的头部姿势、光照条件和背景环境。为了评估模型的性能,在该数据集上采用留一策略。
注视估计领域通常采用角度误差来评估模型性能,也就是真实注视方向g和预测注视向量之间的角度误差,角度误差越小,模型精度越高。计算式为:
(4)
2.2" 实验环境及参数配置
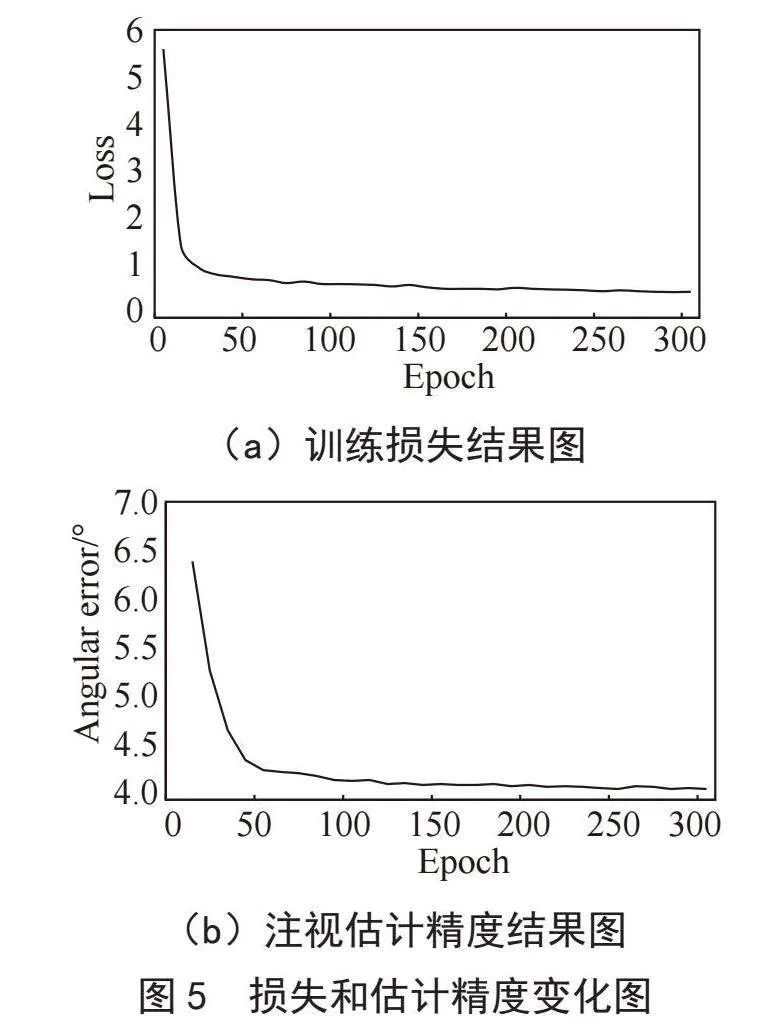
LMLFR-Net采用PyTorch框架构建,并使用NVIDIA-A4000 GPU进行训练与测试。在MPIIFaceGaze数据集上,采用了留一法交叉验证策略。模型训练时初始学习率设置为0.000 1,并通过动态调整来优化模型的训练过程。每个训练批次的batch_size设置为16,共进行了300轮训练,每10轮保存一次模型用于测试。损失函数采用L1损失函数。模型采用式(4)进行注视估计精度的评估。图5显示了模型在训练过程中的损失和估计精度变化情况。模型训练损失收敛速度较快,大约在第50轮左右时稳定下来。同时,模型测试精度也在第50轮时趋于稳定。
2.3" 实验结果与分析
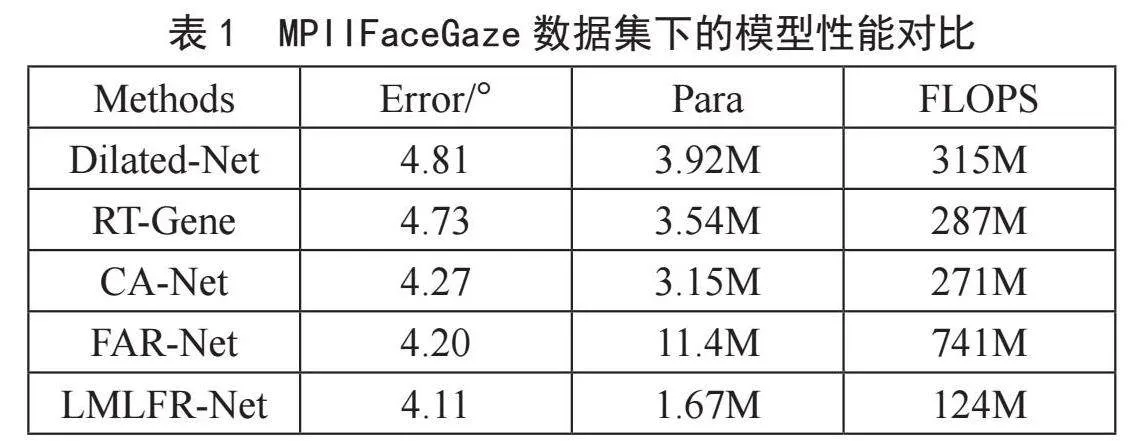
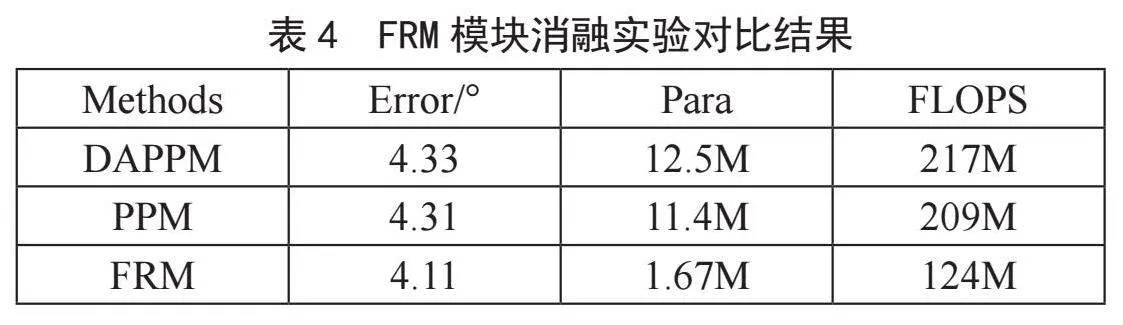
为验证所提出网络LMLFR-Net的性能,本文基于MPIIFaceGaze数据集从估计误差(Error)、模型参数量(Para)和计算量(FLOPS)3个方面进行评估。结果如表1所示。相比其他4种先进的注视估计方法(Dilated-Net[9]、RT-Gene[10]、FAR-Net[11]、CA-Net[12]),所提出的模型达到了更低的角度误差(4.11°),并且模型仅有1.67M的参数量。对比结果显示出所提出的模型在实现轻量化方面有着明显的优势。另外,该模型计算高效(FLOPS仅为124.13M),在保证高效率和高精度的前提下,LMLFR-Net表现出了良好的性能。
2.4" 消融实验
2.4.1" SECA消融实验
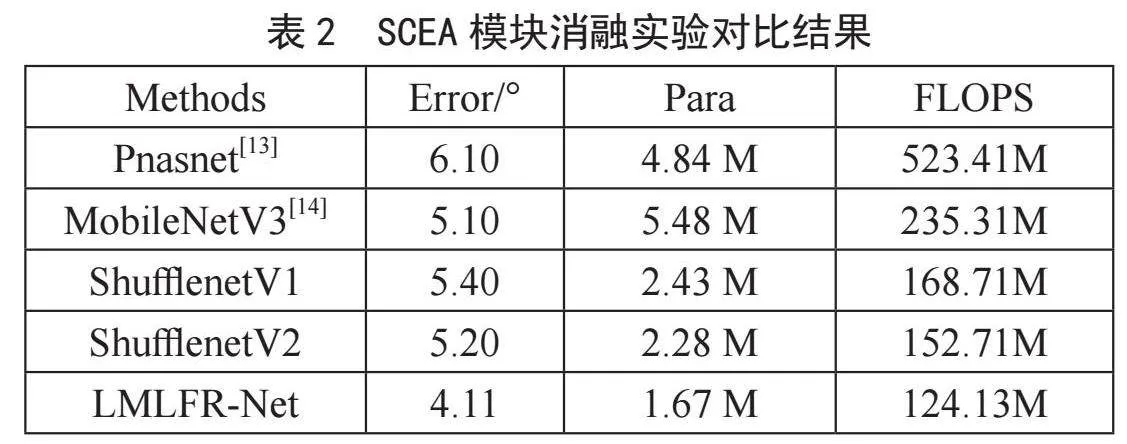
为了检验SECA模块对LMLFR-Net性能的影响,本文分别将其与当前流行的轻量级特征提取网络进行替换比较。从表2可以看出,SECA模块对注视估计精度有着积极的贡献。相较ShufflenetV1和V2在MPIIFaceGaze数据集上注视精度分别增加了1.3°和1.1°,且模型参数量有效减少。SECA在提高注视估计精度的同时,显著降低了参数量。
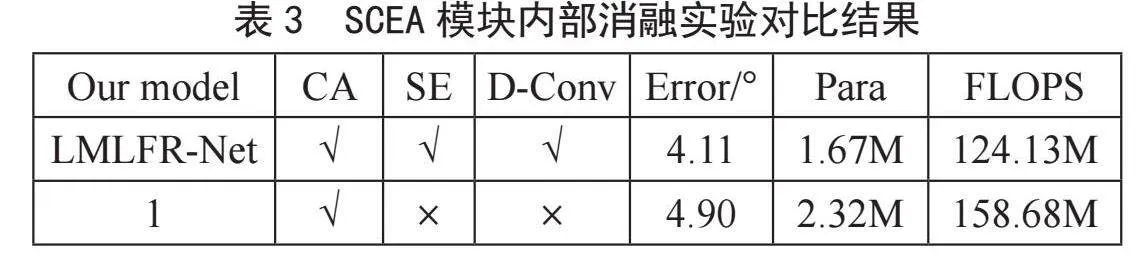
2.4.2" SECA内部消融实验
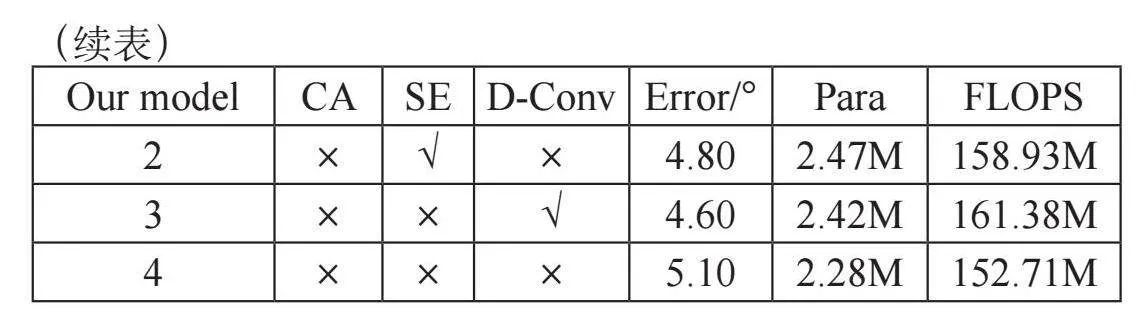
针对SECA模块的内部结构进行了相应的消融实验。消融实验设计包括:1)SECA是否使用SE模块;2)是否使用CA模块;3)是否用空洞卷积代替深度可分离卷积。结果如表3所示,单一加入不同的功能模块,对模型精度的提升不显著,而将两种功能组合起来,则能显著改善模型性能,且参数的数量基本保持不变。在参数数量变化很小的情况下,模型的训练速度和训练后的测试速度没有发生很大的变化,并且具有较高的精度。
2.4.3" FRM消融实验
对于FRM模块,本文将其与现有的金字塔池模块PPM[15]、深度聚合金字塔池模块DAPPM[16]进行对比。实验将主干网络的多级段特征拼接起来作为PPM和DAPPM的输入。表4显示了在 MPIIFaceGaze数据集上的对比结果。相比于PPM和DAPPM,FRM模块将注视误差降低了约0.2°,并且大幅减少了计算量。
3" 结" 论
针对当前注视估计模型参数量较大,开发部署较为困难这一问题,本文提出一种基于多级特征提炼的轻量化注视估计网络LMLFR-Net。包含了用于特征提取的轻量级特征提取模块SECA和一种轻量级多级特征提炼模块FRM。实验结果表明,所提出的模型各模块均有效,整体上具有良好的轻量化性能。但轻量化网络的特征提取能力有限,导致模型精度提升不够显著,因此在后续的研究中将会尝试将知识蒸馏引入,进一步增强轻量化网络的特征提取能力。
参考文献:
[1] LOMBARDI M,MAIETTINI E,DETOMMASO D,et al. Toward an Attentive Robotic Architecture: Learning-Based Mutual Gaze Estimation in Human-Robot Interaction [J/OL].Frontiers in Robotics and AI,2022,9:770165[2024-05-10].https://doi.org/10.3389/frobt.2022.770165.
[2] LEMLEY J,KAR A,CORCORAN P. Eye Tracking in Augmented Spaces: A Deep Learning Approach [C]//2018 IEEE Games, Entertainment. Media Conference (GEM).Galway:IEEE,2018:1-6.
[3] URAMUNE R,SAWAMURA K,IKEDA S,et al. Gaze Depth Estimation for In-vehicle AR Displays [C]//AHs23: Proceedings of the Augmented Humans International Conference.Glasgow:Association for Computing Machinery,2023:323–325.
[4] ZHANG X C,SUGANO Y,FRITZ M,et al. Its Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).Honolulu:IEEE,2017:2299-2308.
[5] OH J O,CHANG H J,CHOI S L. Self-Attention with Convolution and Deconvolution for Efficient Eye Gaze Estimation from a Full Face Image [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).New Orleans:IEEE,2022:4988-4996.
[6] KOTHARI R,MELLO S D,IQBAL U,et al. Weakly-Supervised Physically Unconstrained Gaze Estimation [C]//In Proceedings of the Conference on Computer Vision and Pattern Recognition.Nashville:IEEE,2021:9975-9984.
[7] WANG Y M,JIANG Y Z,LI J,et al. Contrastive Regression for Domain Adaptation on Gaze Estimation [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).New Orleans:IEEE,2022:19354-19363.
[8] MA N,ZHANG X Y,ZHENG H T,et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design [C]//Computer Vision-ECCV 2018.Munich:Springer,2018:122-138.
[9] CHEN Z K,SHI B E. Appearance-Based Gaze Estimation Using Dilated-Convolutions [J/OL].arXiv:1903.07296 [cs.CV].[2024-05-13].https://doi.org/10.48550/arXiv.1903.07296.
[10] FISCHER T,CHANG H J,DEMIRIS Y. RT-GENE: Real-Time Eye Gaze Estimation in Natural Environments [C]//Computer Vision-ECCV 2018.Munich:Springer,2018:339-357.
[11] YIHUA CHENG,ZHANG X C,FENG LU,et al. Gaze Estimation by Exploring Two-Eye Asymmetry [J]. IEEE Transactions on Image Processing,2020:29:5259–5272.
[12] CHENG Y H,HUANG S Y,WANG F,et al. A Coarse-to-Fine Adaptive Network for Appearance-Based Gaze Estimation [C]//Proceedings of the AAAI Conference on Artificial Intelligence.Vancouver:AAAI Press,2020,34(7):10623-10630.
[13] LIU C X,ZOPH B,NEUMANN M,et al. Progressive Neural Architecture Search [C]//Proceedings of the European Conference on Computer Vision.Munich:Springer,2018:19-35.
[14] HOWARD A,SANDLER M,CHEN B,et al. Searching for MobileNetV3 [C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul:IEEE,2019: 1314-1324.
[15] ZHAO H S,SHI J P,QI X J,et al. Pyramid Scene Parsing Network [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6230-6239.
[16] PAN H H,HONG Y D,SUN W C,et al. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Traffic Scenes [J].IEEE Transactions on Intelligent Transportation Systems,2023,24(3):3448-3460.
作者简介:周广澳(1999—),男,汉族,安徽蚌埠人,硕士研究生在读,研究方向:计算机视觉、注视估计;陶展鹏(1997—),男,汉族,安徽淮南人,硕士研究生在读,研究方向:计算机视觉、注视估计。