

摘" 要:针对天气尤其是南方天气的变化,人们需要掌握出行时段内的具体天气,包括日常出行(上班、上学等)、出差、旅游等,并做好相应的出行安排。所设计的系统从中国新闻网等数据源爬取各地天气数据,利用Spark技术进行数据处理和调取,通过ECharts库绘制各种图表和图形,用以展示不同城市的天气数据变化趋势,并采用线性回归算法对天气数据进行预测分析。该系统能够实现对304个城市的实时天气搜索,预测未来3天的气温,以及对实时温度、降水、风力、气压、湿度等进行分析,为人们查询天气提供了高效、便捷的方法。
关键词:天气预测;线性回归;Python;爬虫;可视化
中图分类号:TP311" 文献标识码:A" 文章编号:2096-4706(2024)23-0133-06
Design and Implementation of Meteorological Data Prediction and Visualization System Based on Linear Regression
XIONG Jianfang1, FENG Wen1, GAO Ji2, PENG Zengyan1
(1.School of Computer Science and Intelligence Education, Lingnan Normal University, Zhanjian" 524048, China;
2.The 704 Research Institute of CSSC, Shanghai" 200031, China)
Abstract: In view of the changes of the weather, especially the weather in the south, people need to master the specific weather during the travel periods, including daily travel (going work or school), business trips, tourism, and so on, and make corresponding travel arrangements. This designed system crawls weather data everywhere from data sources such as China News Network, uses Spark technology for data processing and retrieval, and draws various charts and graphs through ECharts library, to show the change trend of weather data in different cities. And the Linear Regression algorithm is used to predict and analyze the weather data. The system can realize the real-time weather search in 304 cities, predict the temperature in the next 3 days, and analyze the real-time temperature, precipitation, wind force, air pressure, humidity, and so on, providing an efficient and convenient method for people to check the weather.
Keywords: weather prediction; Linear Regression; Python; crawler; visualization
0" 引" 言
气象预报直接影响着人类活动的各个方面,是现代社会不可或缺的一部分。及时获取气象资料能够预警各种自然灾害,比如暴雨、大风、冰雹等,减轻灾害给人类带来的影响[1]。随着信息技术的迅速发展,网络爬虫技术受到越来越多重视。通过利用网络爬虫技术,可以更高效地收集和利用天气信息数据,从而节省人力和物力成本。在气象预测方面,有研究使用Scrapy框架编写天气爬虫,利用Python字符切割和Split技术获取目标数据,并借助Spark进行服务器端编程,清洗后的数据存储到MySQL数据库,最终通过ECharts在网页上呈现天气数据的可视化图表。
1" 整体设计
1.1" 开发技术
1.1.1" 爬虫技术
Python作为一种强大的编程语言,在网络爬虫领域发挥了重要作用[2]。它提供了丰富的第三方库和标准库,简化了网络爬虫编程的复杂性,使得进行网络爬虫编程更加方便[3-4]。同时,Python提供了用于访问前端页面的API,这使得使用Python进行网页文档接口的抓取变得更加轻松和高效。此外,Python还提供了网络请求库Requests和正则工具RE,它们是爬虫编程中常用的工具之一[5]。Requests对Python内置的网络请求模块进行了高度封装,能够完全满足HTTP测试需求,使得对网页的爬取和解析变得更加快捷。由于气象数据的高时效性,爬虫程序必须定期检查目标网站,以确定哪些页面需要更新,从而确保及时获取最新的数据。
1.1.2" Spark技术
Apache Spark作为一个快速通用的计算引擎,其灵活性和高效性使得它成了许多大规模数据处理任务的首选技术。Spark强大的API和丰富的工具生态系统,让开发人员能够轻松构建复杂的数据处理和分析应用,并快速迭代和调试代码。在数据挖掘、机器学习、实时分析等领域,Spark都表现出色,为业界带来了许多创新和进步。随着大数据技术的不断发展和普及,Spark将继续发挥其重要作用,推动大数据处理领域的进一步发展,并为构建智能、高效的数据处理系统提供支持[6]。
1.1.3" 线性回归算法
在机器学习中,线性回归是最简单、最基本的一种有监督学习预测算法,其主要原理是建立输入特征和目标值之间的线性关系模型,以预测新样本的目标值[7]。在此模型中,假设目标值与输入特征之间呈线性关系,即目标值可由输入特征的线性组合加上一个偏置项表示。线性回归模型的数学计算式为:
其中,y为目标值,X1,X2,…,Xn为输入特征,β0,β1,…,βn为模型的参数(也称为权重),∈为误差项。模型的目标是通过调整参数的数值,从而使预测值y尽可能接近真实值。线性回归通常采用最小化平方误差的损失函数来进行参数估计。
1.2nbsp; 可视化系统的架构设计
在前端获取到统计和预测的数据后,利用ECharts库绘制各种图表和图形包括柱状图、折线图、饼图等,用以展示不同城市的天气数据变化趋势[8]。
在前端获取到统计和预测的数据后,这些数据可以动态地传递给对应的可视化组件,例如柱状图用于展示城市的温度和降水情况、折线图用于展示气温的变化趋势、饼图用于展示城市的风力和湿度情况。通过将数据与可视化组件进行绑定,可以确保图表能够实时更新,并以直观的方式呈现天气信息,使用户能够轻松地获取气象信息。
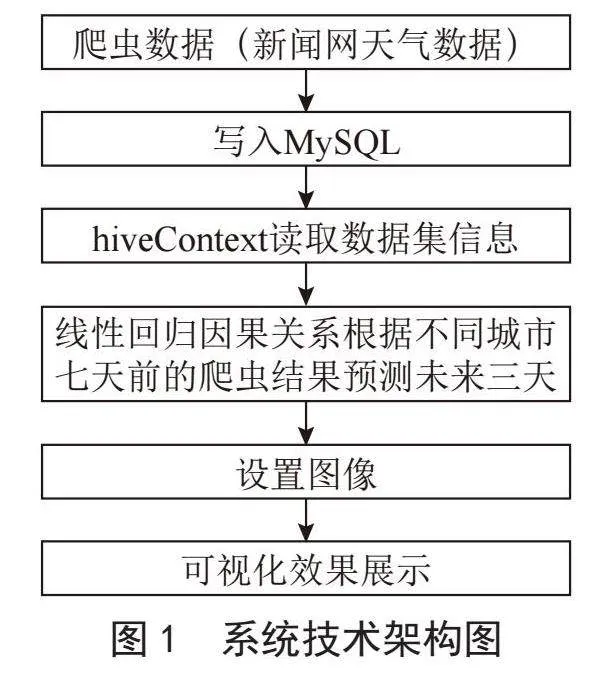
通过前端的Vue.js框架[9]和可视化库ECharts的应用,该系统可以为用户提供直观、清晰的天气信息展示,进一步提升用户体验和数据的可解释性。同时,通过动态加入统计数据和预测到可视化内容中,用户可以更全面地了解天气情况,并做出相应的决策和规划。技术机构图如图1所示。
2" 系统设计与实现
2.1" 数据采集模块设计
2.1.1" 数据采集
本系统涉及的数据(全国各省市县的天气信息、当日实时天气和未来24小时的天气预报)均来源于腾讯天气API,通过访问API接口获取各地区的天气数据。数据采集频率设置为每小时一次,以保证天气信息的及时性和准确性。
使用requests库爬取http://wis.qq.com/weather/common网站的信息进行数据分析。首先根据各个城市、时间等参数构建爬取地址,导入Requests模块代替浏览器做HTTP请求,访问相关信息网站,对整个页面进行下载。然后使用RE正则工具对请求到的HTTP界面进行正则筛选,检查字符串是否与某种模式匹配,来获取所需要的数据。发送HTTP请求以获取天气API接口返回的JSON格式数据,然后进行解析和处理。
获取到的天气数据经过处理后存储到MySQL数据库中,以便后续的数据分析和可视化展示,同时处理过程包括解析数据、提取所需信息,如温度、湿度、风速、气压等[10]。
2.1.2" 数据清洗与统计
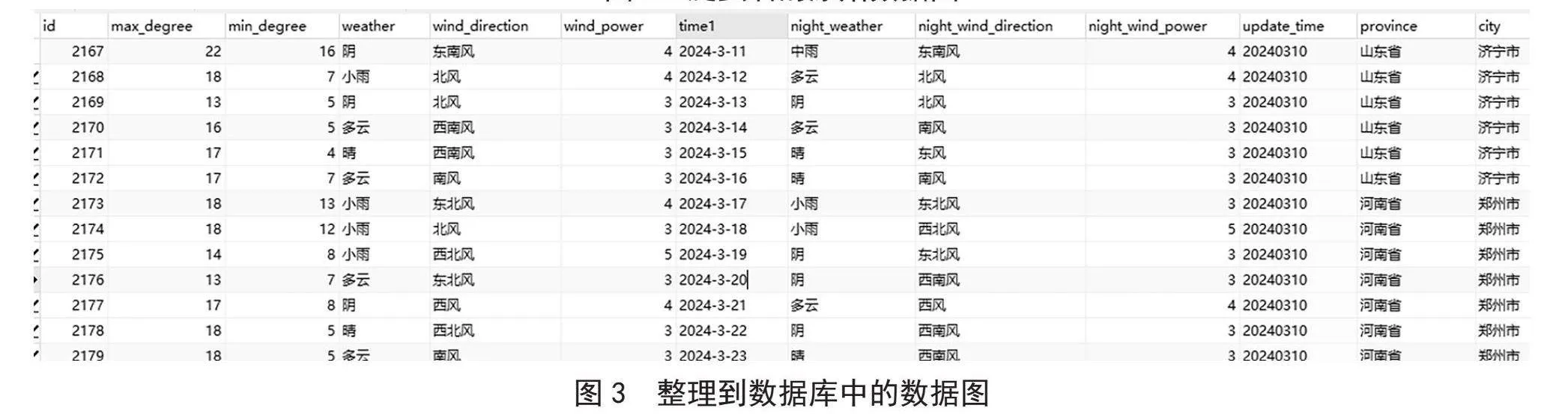
首先,使用SQLContext的read().jdbc()方法从数据库中读取数据,然后根据指定的条件进行筛选。其次,将读取到的数据转换为JavaRDD,并通过collect()方法获取所有数据行。最后,通过调用size()方法获取数据行的数量,并将其作为统计结果返回。以上操作保证了数据的高效处理和准确统计,为后续的数据分析和可视化提供了有力支持。在数据处理的最后阶段,将数据经过精心加工后重新写入MySQL数据库中。此外,在数据处理模块中,需要确保能够轻松地获取MySQL数据库的连接信息,这样才能保证与数据库的顺畅交互。通过以上设计,数据处理模块能够高效地与MySQL数据库进行交互。以上流程不仅保证了数据的完整性和一致性,还提高了系统的可扩展性和可维护性。同时,将数据存储在数据库中也为多个模块之间的数据共享提供了便利,使得整个系统更加协同和高效。爬虫后的存储后的数据如图2所示,将爬虫后的数据整理到数据库中,如图3所示。
数据处理主要代码如下:
datetime.date.today().strftime(\"%Y%m%d\"), province, city, county)
# 构造SQL语句并执行
sql = \"REPLACE INTO tb_forecast( max_degree, min_degree, weather, wind_direction,\" \
\"wind_power, time1," night_weather, night_wind_direction,\" \
\"night_wind_power,update_time,\" \
\"province, city, county) \
VALUES ( %d,%d,%s,%s,%d,%s,%s,%s,%d,%s,%s,%s,%s) \" % \
(int(_forecast[max_degree]), int(_forecast[min_degree]), _forecast[day_weather],
_forecast[day_wind_direction], day_wind_power, _forecast[time],
_forecast[night_weather], _forecast[night_wind_direction], night_wind_power,
2.1.3" 线性回归预测模型
本系统采用大数据技术进行天气预测,借助大似然估计进行线性回归分析,旨在提高对未来3天天气情况的准确性。为实现这一目标,深入探索了以下几个方面:
1)数据预处理与特征工程。在建立预测模型之前,进行数据预处理和特征工程。这包括数据清洗、缺失值处理、异常值检测等步骤,以确保数据的质量和完整性。同时,在原始数据中建立了因果关系,并利用前7天的数据集提取关键特征,如温度、湿度、气压等,作为模型的输入变量。
2)模型选择与优化。在选择预测模型时,我们比较了多种算法,如线性回归、决策树、随机森林等。在探索线性回归过程中需处理的问题时:给定一组输入样本,和每个样本对应的目标值,需要在某一损失准则下,找到(学习到)目标值和输入值的函数关系,这样,当有一个新的样本到达时,可以预测其对应的目标值是多少。选择线性回归作为主要的预测模型时,对模型进行了参数调优,以提高预测准确性。通过交叉验证的方式,调整线性回归模型中的正则化参数(如L1正则化的惩罚项系数α或L2正则化的惩罚项系数λ),以控制模型的复杂度,避免过拟合或欠拟合。
3)预测模型构建。调用生成JSON函数,提取前7天的数据集,并设置自变量和因变量。其中,x为天数,w为前7天的天气训练结果。通过对前7天数据集中w的排序,得到不同效果的w2、w3、w4,并结合自变量x进行未来3天天气的预测。将预处理后的历史气温数据输入已经建立好的线性回归模型中。模型会利用历史数据中的特征与目标值之间的关系,来学习并建立一个线性回归方程[11]。
4)统计分析和个性化效果提取。利用Spark调取数据集进行信息提取,用线性回归方法进行统计分析,绘制柱状图、饼图等,进行样式表的分析。根据不同城市的效果进行数据提取和分析,以满足不同城市的需求和特点。
模型的目标是通过调整参数的数值,从而使预测值y尽可能接近真实值。线性回归通常采用最小化平方误差的损失函数来进行参数估计。这样不仅实现了对未来3天天气的准确预测,还为天气预测系统的性能提升和用户体验改善提供了重要技术支持,对模型预测的结果进行解释和分析。可以比较预测值与实际观测值的差异,评估模型的准确性和稳定性。线性回归模型的主要代码如下:
def fitSLR (x , y) :
n = len(x)
dim = 0
mune = 0
for i in range(0,len(x)):
mune += (x[i] - np.mean(x))*(y[i] - np.mean(y))
dim += (x[i] - np.mean(x))**2
print(\"numerator:\" , mune , \"\n\" , \"dinominator:\",dim)
b1 = mune/float(dim)
b0 = np.mean(y)/float(np.mean(x))
return(b0,b1)
def predict(x , b0 ,b1):
return(b0 + x*b1)
def linaer_regression_predict(p1, p2, n):
print(p1)
print(p2)
b0, b1 = fitSLR(p1, p2)
print(\"intercept:\", b0, \"\n\", \"slope\", b1)
x_t = float(n)
y_t = predict(x_t, b0, b1)
return y_t
sql = \"select" degree" from" tb_weather where city=%s \" \
\"and update_time in" (select" *" from" "\" \
\"(select" distinct update_time from tb_weather \" \
\"where" "city =%s order by update_time desc limit 7 ) as t)\" % (city, city)
w = []
tt = session.execute(text(sql))
for c in cur:
w.append(c[0])
print(w)
x = [1, 2, 3, 4, 5, 6, 7]
w2 = linaer_regression_predict(x, w, 7)
w3 = linaer_regression_predict(x, w, 8)
w4 = linaer_regression_predict(x, w, 9)
2.2" 系统实现
2.2.1" 主要城市气温展示图
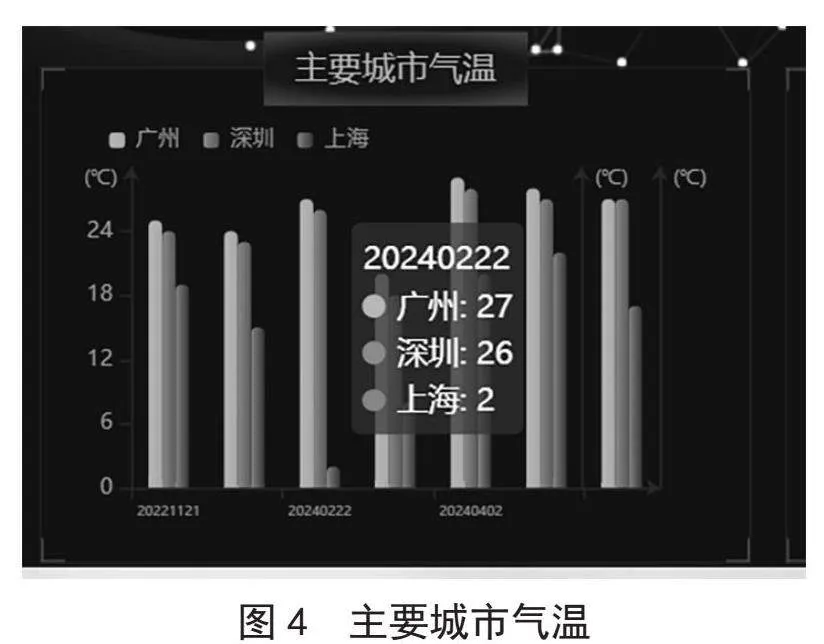
图4是主要城市气温图,以柱状图的形式展现了广州、上海、深圳三个主要城市的气温情况。通过色彩的深浅变化,直观地呈现了不同城市的气温高低分布,用户可以一目了然地比较各城市的气温差异。这种图不仅展示了当前的气温情况,还反映了气温的季节性变化和日间夜间温差,为用户提供了重要的气象信息。
2.2.2" 城市温度图
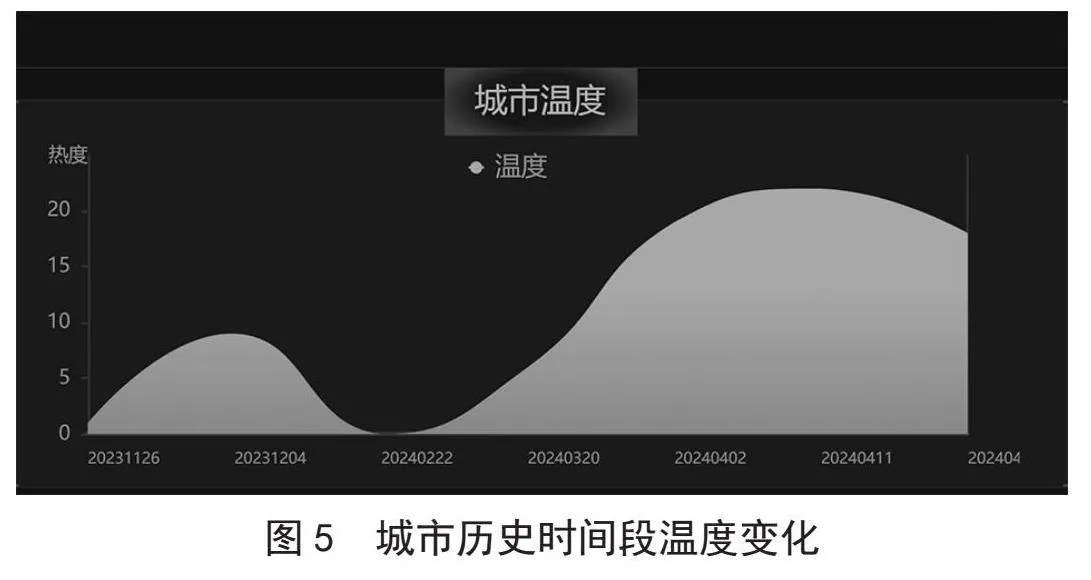
图5中展示了特定城市过去一段时间的历史温度情况,通过图的形式直观地展示了每天的温度变化趋势。这种图表不仅可以帮助用户了解过去一周内城市温度的变化情况,还可以分析温度的波动情况,揭示温度的季节性和周期性变化。用户可以通过观察温度图快速了解城市的气候特点和变化规律。
2.2.3" 气温预测
气温预测图天气预报系统中的重要组成部分,它基于历史数据进行分析和预测,为用户提供未来3天的气温趋势展示。通过分析过去一段时间的气温数据,系统可以识别出气温的周期性变化和趋势,进而预测未来的气温变化情况,如图6所示。
2.2.4" 切换城市页面
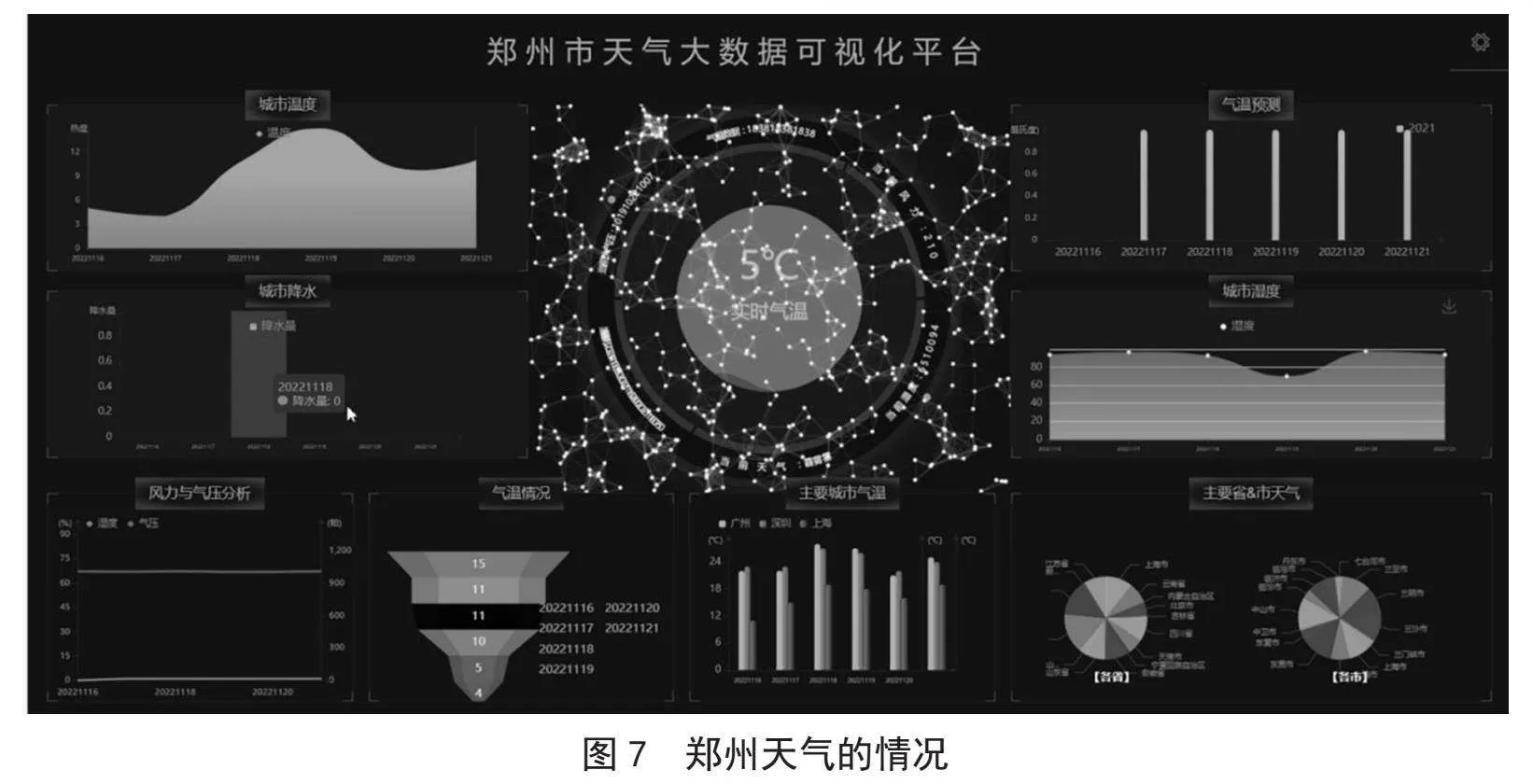
图7中展示了切换到郑州天气的情况。在该模块的设计中,本系统主要运用Python语言进行样式表的切换,同时利用Spark技术调取数据库中的信息。通过线性回归算法进行自动分析,系统设计更加直观,而且代码结构简洁明了,易于执行。同时,这一设计实现了大屏幕的效果,使得用户可以在一个界面上轻松切换不同城市的天气信息,提高了用户体验和系统的可用性。这种简洁而高效的设计,使得用户可以快速获取所需的天气预报,为其日常生活和出行提供了便利。通过这样的设计,用户不仅可以方便地查看当前城市的天气情况,还能快速切换到其他城市,满足不同用户的需求。这种用户友好的设计,有助于提升系统的实用性和用户满意度,进而促进系统的广泛应用。
2.2.5" 实时更新
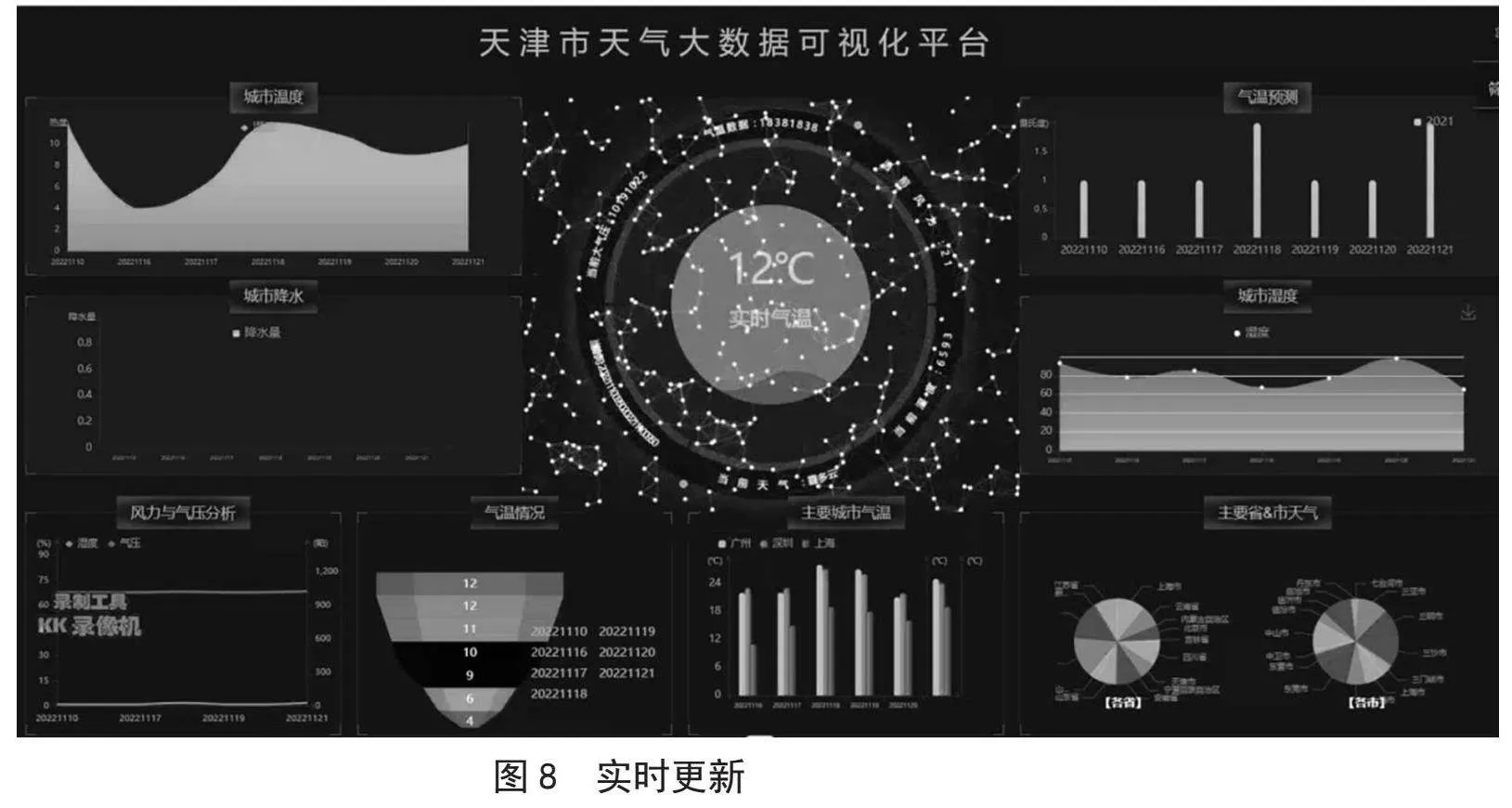
图8展示的是温度变化后的效果,当前温度为12 ℃,并且该数值是实时更新的。这种实时变化是通过数据库的递增效果实现的,数据库会不断地接收最新的数据,因此天气情况也会相应地实时变更。实时更新的功能使得系统及时呈现当前的气温,用户可以随时了解到天气的最新状态。例如,在温度发生突然变化时,用户可以立即得知,从而做出相应的活动调整。这种及时性和准确性为用户提供了便利,增强了系统的实用性和用户满意度。同时,实时更新也表明了系统的高度自动化和智能化,为用户提供了更加便捷的天气信息查询体验。
3" 结" 论
本系统能够实现对国内304个城市的实时天气搜索,并利用线性回归算法预测未来3天的天气温度情况,同时实现对实时温度、降水、风力、气压、湿度等方面的分析。系通过大屏可视化效果,用户可以直观地了解各地天气情况,为出行和生产生活提供便利。
参考文献:
[1] 李璐,郭淇汶,陆宇,等.基于Python的天气预测系统研究 [J].信息技术与信息化,2020(10):18-20.
[2] 张一恒,王芹,刁炜卿,等.基于Scrapy爬虫技术和图神经网络的生态旅游推荐技术 [J].自动化与仪器仪表,2024(2):6-10.
[3] 冯艳茹.基于Python的网络爬虫系统的设计与实现 [J].电脑与信息技术,2021,29(6):47-50.
[4] 周玮.基于网络爬虫技术的财务大数据采集系统设计 [J].中国新技术新产品,2024(3):37-40.
[5] 沈承放,莫达隆.Python语言中re库的使用技巧与目标网络数据的抓取 [J].贺州学院学报,2019,35(3):151-156.
[6] 冯超,兰唱,周冬雪.基于大数据分析的气象信息网络数据监控系统设计与实现 [J].长江信息通信,2023,36(12):125-127.
[7] 王静怡,甄翠敏.工商银行不良贷款影响因素分析——基于多元线性回归模型 [J].河北企业,2024(5):84-86.
[8] 万腾.基于Echarts的跨平台教学资源数字化展现解决方案 [J].办公自动化,2024,29(3):47-50.
[9] 罗光武,陈典灿,吴荷,等.应用Springboot+Vue框架的时间管理软件的设计与实现 [J].工业控制计算机,2024,37(4):64-66.
[10] 郑博培,李媛.基于物联网的智能天气识别系统设计 [J].物联网技术,2020,10(12):7-9.
[11] 张涵夏.适用于线性回归和逻辑回归的场景分析 [J].自动化与仪器仪表,2022(10):1-4+8.
作者简介:熊建芳(1980—),女,汉族,江西樟树人,讲师,硕士,主要研究方向:人工智能算法、数据分析。