

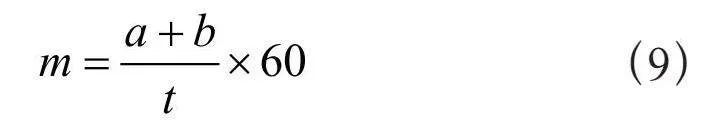
摘" 要:随着汽车保有量的增加,智能交通中路况分析技术变得日益重要。它广泛应用于目标检测、自动驾驶和汽车碰撞危险预警等领域,具有显著的研究意义。文章基于Python语言,提出了一种结合YOLOv5s和Attention机制的改进模型,实现了路况检测与车流量分析,能广泛用于汽车碰撞危险等级预警的场景,结合对乘员坐姿的智能识别,可以为乘员提供更恰当的保护。系统支持用户上传图像,利用改进模型对车辆进行识别并统计车流量,实现对路况的分析。实验采用近8万张图片的数据集,其中80%用于训练,20%用于测试。结果表明,改进后的模型在目标检测性能上有明显提升,准确度和效率优于基础模型,在预警汽车碰撞等领域具有一定的实际意义。
关键词:Attention机制;路况分析;目标检测;碰撞预警
中图分类号:TP391.4" " 文献标识码:A" " 文章编号:2096-4706(2024)23-0127-06
Analysis and Application of In-automobile Video Road Condition Based on Attention Mechanism
XU Deheng, XIANG Feifei, WANG Bingkun, YU Pan, LIN Yuxiang
(Jiangxi University of Technology, Nanchang" 330098, China)
Abstract: With the increase in the number of automobiles, road condition analysis technology in intelligent transportation has become increasingly important. It is widely used in the fields of Object Detection, autonomous driving and automobile collision hazard early warning, and has significant research significance. Based on the Python language, this paper proposes an improved model combining YOLOv5s and Attention Mechanism, which realizes road condition detection and traffic flow analysis and can be widely used in the scene of automobile collision hazard level early warning. It can provide more appropriate protection for passengers in combination with the intelligent recognition of passengers sitting position. The system supports users to upload images, and uses the improved model to identify automobiles and count traffic flow to realize the analysis of road condition. The experiment uses a dataset of nearly 80 000 images, of which 80% is used for training and 20% for testing. The results show that the improved model has a significant improvement in Object Detection performance, and its accuracy and efficiency are better than those of the basic model, which has a certain practical significance in the automobile collision early warning and other fields.
Keywords: Attention Mechanism; road condition analysis; Object Detection; collision early warning
0" 引" 言
随着社会经济的不断发展,汽车保有量逐年增加,交通压力与日俱增。为了更好地应对这一挑战,智能交通系统(ITS)逐渐成为现代城市交通管理中的重要组成部分。其中,车辆流量监控作为智能交通的重要技术之一,能够实时获取道路上的车辆信息,分析交通流量,并为交通管理、交通控制和道路规划提供有效支持。
车辆流量检测技术涉及图像处理、模式识别和自动控制等多个领域,并在目标跟踪、自动驾驶、医疗诊断以及智能交通等方面具有广泛应用。近年来,基于神经网络的物体检测的方法取得了显著成果,尤其是YOLO(You Only Look Once)系列算法因其实时性和高精度,被广泛应用于车辆检测任务中[1]。
然而,尽管现有的YOLO算法在目标检测中表现优异,但在复杂交通场景下的检测精度和鲁棒性仍有改进空间。为此,本文提出了一种基于YOLOv5s并结合Attention机制的改进模型,用于车辆目标检测与车流量统计分析。该模型通过引入注意力机制,有效提升了模型在检测小目标和密集目标时的表现[2]。此外,本文系统采用Python语言实现,结合近8万张图像的数据集进行训练和测试,以评估模型的性能。
本文的研究旨在通过改进车辆检测算法,为智能交通系统提供更精准的车流量监控解决方案。本文的主要贡献是提出了一种YOLOv5s+Attention模型,该模型以YOLOv5s为原型进行改进,能极大提升行车目标检测的性能。构建了一个支持用户图像上传的车辆流量分析系统,能够实现实时检测和流量统计。通过实验验证了改进模型在复杂交通场景中的检测性能,展示了其优于基础YOLOv5s模型的表现。接下来,本文将对国内外的相关研究现状进行综述,并详细介绍所采用的算法和模型设计。
1" 国内外现状
作为智能交通系统的重要组成部分,近年来,随着深度学习和计算机视觉技术的快速发展,车辆检测与车流量分析的研究取得了显著进展。在本部分中,我们将对国内外关于车辆检测和流量分析的研究现状进行综述,重点介绍当前技术的发展趋势与挑战。
1.1" 国际研究现状
在国际上,基于深度学习的目标检测技术已成为车辆检测领域的主流方法[3]。传统的图像处理和机器学习方法,如背景减除、边缘检测、HOG(Histogram of Oriented Gradients)特征提取以及SVM分类器,虽然曾在车辆检测中发挥过重要作用,但其在复杂交通场景下的表现受限于环境噪声、光照变化和视角问题。近年来,深度学习方法尤其是卷积神经网络(CNN)的引入,为目标检测领域带来了革命性进展。Girshick提出的R-CNN(Region-based Convolutional Neural Network)及其后续的Fast R-CNN和Faster R-CNN模型在目标检测任务上表现出色[4]。然而,这些模型由于区域生成过程较为复杂,计算效率不高,不适合实时检测需求。
为了解决实时检测问题,Redmon提出了YOLO(You Only Look Once)算法[5]。YOLO通过将目标检测问题转化为单个回归问题,实现了图像特征提取和目标检测的端到端处理。YOLO系列的模型如YOLOv2、YOLOv3和YOLOv5进一步优化了检测精度和速度,广泛应用于交通监控、无人驾驶等领域[6]。然而,YOLO模型在复杂交通场景中,尤其是面对车辆密集、遮挡或小目标时,检测性能仍有待提升。
近年来,Transformer和Attention机制逐渐被引入目标检测领域。Attention机制能够自动捕捉图像中对检测任务更为关键的特征,尤其在小目标检测中表现出色[7]。诸如DETR(Detection Transformer)和使用Attention增强YOLO模型的研究逐渐兴起,展示了在复杂场景下的检测性能提升。
1.2" 国内研究现状
智能交通的飞速发展促使国内研究者对车辆检测和流量分析领域进行了大量探索。许多高校和科研机构致力于基于深度学习的车辆检测算法的研发,并取得了显著成果。
国内的早期研究主要集中在基于传统机器学习方法的车辆检测,例如基于Adaboost分类器的车辆检测方法,利用Haar特征实现快速检测。然而,这些方法的准确率和鲁棒性较低,难以应对复杂的城市交通场景[8]。
近年来,国内的研究重点逐渐转向基于深度学习的目标检测方法。例如,申铉京团队提出了一种结合CNN和多尺度特征的车辆检测方法,有效提升了在不同场景下的检测性能[9]。同时,国内还出现了对YOLO模型的多种改进研究,目的是提高其在密集交通场景中的检测效果。马军策等提出了一种基于YOLOv4的改进模型,通过引入多尺度特征融合技术,显著提升了小目标检测的精度[10]。
1.3" 当前技术的挑战与问题
尽管国际和国内的研究在车辆检测和流量分析领域取得了许多进展,但仍然面临一些挑战和问题:
1)复杂场景中的检测精度。现有的检测模型在处理密集、遮挡或光照变化较大的场景时,容易出现漏检或误检。
2)小目标检测。交通场景中,远距离或视角受限的车辆检测效果较差。
3)实时性与计算效率。虽然YOLO模型在实时检测上具备优势,但在面对大型高分辨率数据集时,计算资源的需求依然较大。
针对这些问题,本文提出了改进的YOLOv5s+ Attention模型,通过Attention机制提升模型对小目标和复杂场景的适应性。同时,本文结合实际交通数据集进行训练和测试,为智能交通中的车辆流量检测提供了有效的解决方案。
2" 车载视频图像数据预处理
2.1" 数据集分析
实验采用BDD100K数据集,包含约80 000张标注了10个类别的图像,包括小汽车、公交车、行人等。数据集按80%训练集和20%测试集划分,涵盖不同道路、时间和天气场景。为适应YOLOv5的输入要求,所有图像尺寸调整为640×640,并进行数据增强和灰度化去噪处理,以降低过拟合风险。
2.2" 图像处理
彩色图像通常使用RGB模型表示,包含大量数据,影响算法实时性。对于车辆识别,灰度图像足以满足需求。灰度转换将RGB三个分量设为相同值,灰度值范围为0到255,有两种常用方法:1)平均法。R、G、B的灰度值均为(R+G+B)/3。2)加权法。R=0.3R+0.59G+0.11B,G和B同样按此权重计算。
图像增强是预处理技术之一,能够突出关键信息,弱化无关细节,提升图像的视觉效果和应用价值。在驾驶场景中,光照、噪声、阴影等干扰因素常见,图像增强有助于提高识别准确性。常用的增强方法包括旋转、平移、随机裁剪、水平翻转等,此外还使用马赛克策略,将四张图像随机组合,增加数据多样性。实验表明,改进后的图像提升了远处交通灯和车辆的检测精度,识别率显著提高,如图1所示。
图像去噪方法包括高斯滤波、均值滤波、中值滤波和双边滤波。高斯滤波基于高斯曲线分配权重,能有效去噪且失真较低。均值滤波通过求窗口内像素的平均值去噪,但会导致图像模糊和细节丢失。中值滤波对高斯噪声处理较好,能保留边缘细节,适合处理脉冲噪声,但对椒盐噪声效果不佳。双边滤波能同时去噪和平滑图像,并保留边缘细节,通过结合像素亮度和相似性进行加权平均计算。图像去噪前后对比如图2所示。
3" 基于融合注意力机制的目标检测算法
3.1" 注意力机制
近年来,注意力机制在深度学习中的重要性日益凸显,其模仿人类视觉系统,通过忽略无关细节来捕捉关键信息。该机制扫描全局数据,挑选对当前任务重要的信息并合理分配注意力资源。注意力机制分为“软”和“硬”两种,软注意力使用全部输入信息并赋予不同权重,而硬注意力随机选择信息,训练过程较为复杂,故软注意力更为广泛应用。根据基本理念,注意力机制可进一步细分为通道注意机制、空间注意机制和混合注意机制。通道注意机制强调关键特征通道,减少无关通道影响;空间注意机制则关注特定区域,弱化其他区域。两者结合形成综合模型。注意力模块(CBAM)是常用的合成模块,通过处理特征图并结合通道与空间注意力,生成具有两种特征的特征图。CBAM不改变输入特征图的尺寸,因此可方便地集成至网络架构中。
3.2" YOLOv5s融合卷积注意力机制
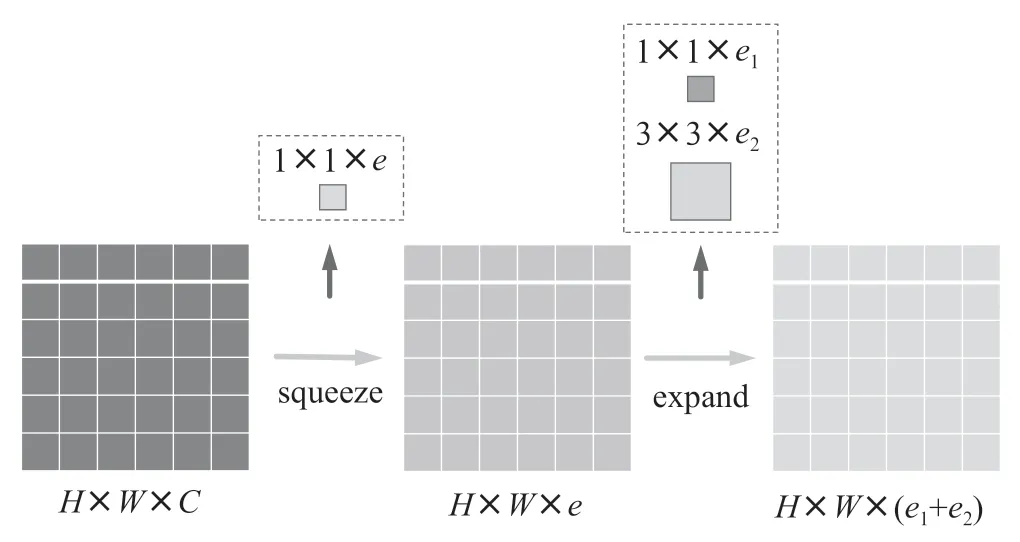
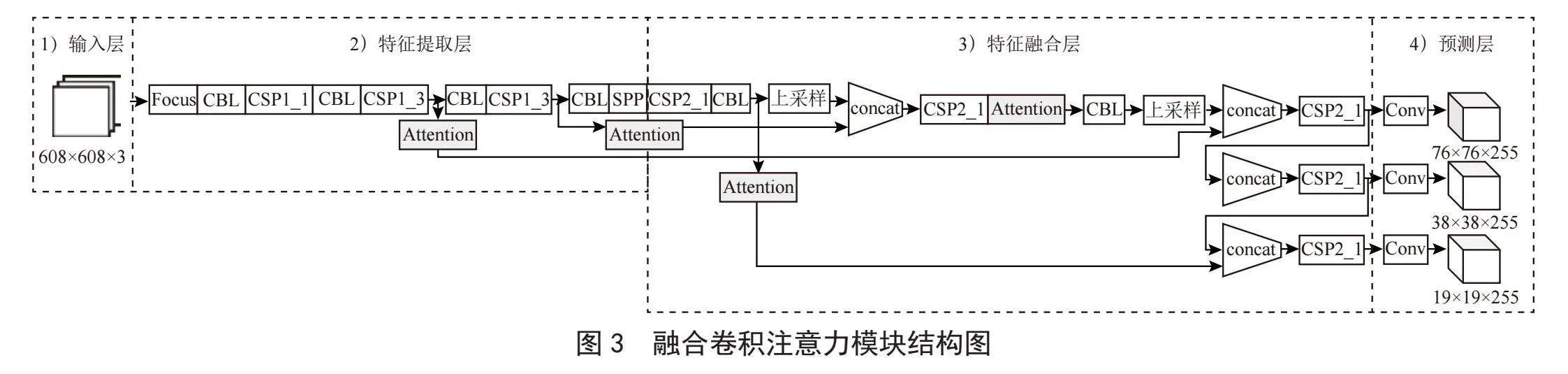
卷积注意力模块(CBAM)旨在将特征与特征空间相结合,提升神经网络的学习能力。本文拟构建融合注意力机制的YOLOv5s模型,加入注意模块能够高效捕获感兴趣部分,并增强YOLOv5s的特征抽取能力。通过精细调整特征信息,特征图更为丰富,从而实现更好的检测效果。在CBAM中,特征空间提取分为两个步骤,首先筛选通道重要度,再传递至特征空间,空间注意力模块借鉴通道注意力,通过最大池化和平均池化确定特征图的空间权重,最终,空间权重与输入特征点相乘,实现特征图的空间权重缩放至1×w×h。如图3所示,注意力模块的输入输出特征图保持相同尺寸,可无缝集成至卷积神经网络,且无须调整通道数。因此,在特征提取层,注意力模块放置于CSP1模块后,而在特征整合层,模块则位于CSP2模块后。这个版本突出了CBAM的核心功能和实施步骤,简化了语言,使内容更加清晰。
3.3" 损失函数
损失函数衡量模型预测值f(x)与真实值Y的不一致性,常表示为L(Y,f(x))。损失越小,模型的鲁棒性越强。总损失由分类损失、定位损失和置信度损失组成,其中类概率和目标可信度使用二元交叉熵损失函数进行计算,每个标记均采用此算法,且不增加算法复杂度。如下式所示:
(1)
其中Ln为第n批次的分类函数损失值。
置信度损失lossconf计算公式与分类损失相同,均采BCEWithLogitsLoss损失函数:
(2)
定位损失即lossbox的计算为:
(3)
设置IoU为检测目标的置信度,即有:
(4)
故将定位损失、分类损失、置信度的损失值求和则为本文定义的损失函数计算式,即:
(5)
4" 实验设计与结果分析
本文实验在Windows 10测试,在Ubuntu 18.04系统上训练,均搭建PyTorch框架以完成模型训练和测试任务。
4.1" 实验设计与评价指标
4.1.1" 精确率与召回率
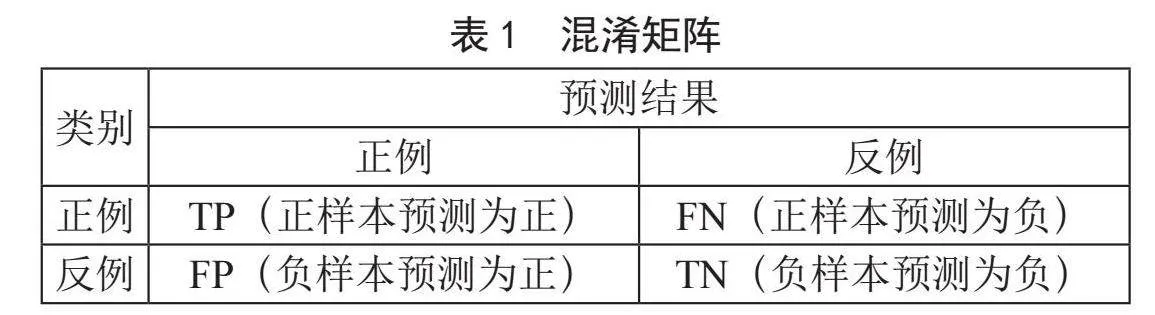
精确率(P)与召回率(R)可以用来衡量分类器准确率,混淆矩阵用来表示样本预测值和真实值之间的关系,如表1所示。
(6)
(7)
4.1.2" 交通车辆流量
车流量计算式为:
(8)
式(8)计算当下关键帧的时间,t为当前关键帧时间(单位:秒),n为当前帧数,f为抽帧频率。为了计算当前时刻t的平均车流量,本文设每分钟的平均车流量记为m(单位:辆/分),记累计驶入车辆数为a,记累计驶出车辆数为b,则平均车流量为:
(9)
4.1.3" 平均精度
平均精度,简称mAP,是所有数据集类别的目标平均值。准确度的平均值。当数据集包中只有一个样本时,mAP的含义通常与AP相同。当有多个样本时,每种样本的AP平均值称为mAP。本文中的交通物检测模型评价指标均基于mAP。
4.1.4" 置信度
将置信度定义为pr(object)*IoU(true,pref),Pr(Object)表示的是边界框中存在目标对象的概率,用于评估检测框内是否存在物体。当检测到框内物体时,本文约定Pr(Object)=1;如果检测框内没有物体,则约定Pr(Object)=0。因此,Pr(Object)作为一个二值化的指标,在目标检测过程中扮演着重要的角色,帮助模型初步确定边界框内是否有物体需要进一步分析。IoU(Intersection over Union)则是用于衡量预测框与真实框重合程度的指标,将预测框和真实框的交集面积除以两者的并集面积,结果是0到1之间的数值。IoU值越大,说明预测框与真实框的重合程度越高,即模型对物体位置的预测越精确。通常,IoU是模型评估目标定位准确度的核心指标,广泛应用于目标检测的性能评估中。
在YOLO(You Only Look Once)目标检测模型中,置信度是另一个关键概念,范围在0到1之间。置信度代表了模型对其所检测到的目标的信心程度。置信度越接近1,表示模型更有把握检测框内包含一个物体;而置信度接近0则表示模型认为该框内几乎没有物体。因此,置信度不仅仅是模型对检测结果的信心,还结合了边界框的准确性。通过将置信度与IoU结合,YOLO能够在实际应用中进行快速、准确的目标检测。
4.2" 模型训练与结果分析
4.2.1" 模型训练参数设定
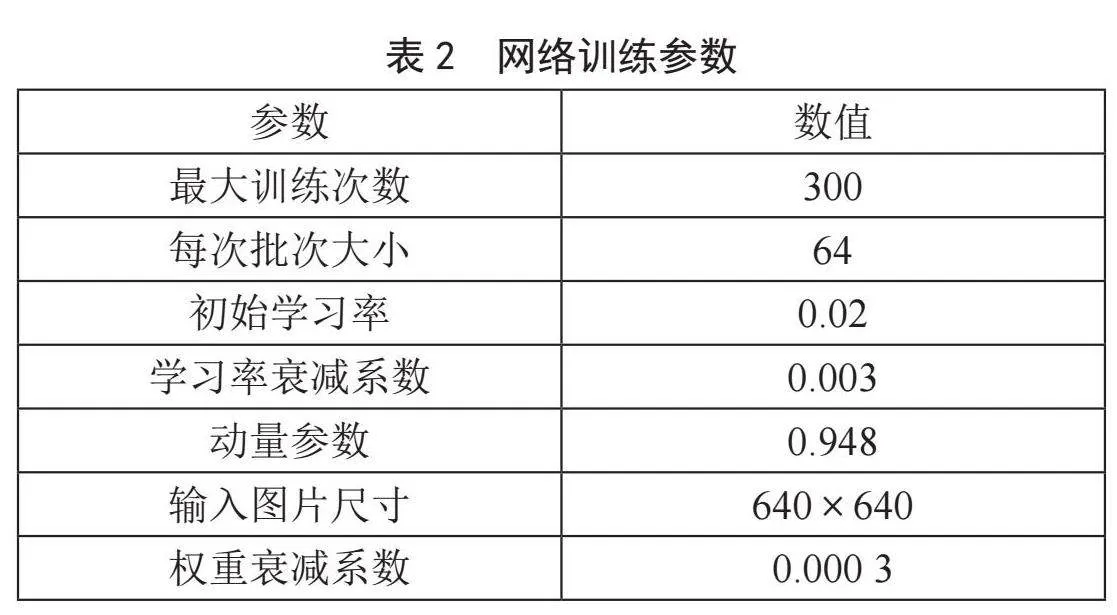
由于本文中定义的目标类别较多且数据量庞大,同时在模型训练过程中某些目标的外观较小,因此网络的输入图像大小设定为640×640。为提高模型的训练效果,选择了较多的迭代轮数(例如300轮)。由于硬件限制,批量学习的最大图像大小为64。学习率的起始值为0.02,衰减系数为0.003。此外,为了防止网络过拟合并降低模型性能,权重衰减系数设置为0.000 3。训练参数设置如表2所示。
4.2.2" 模型性能评价
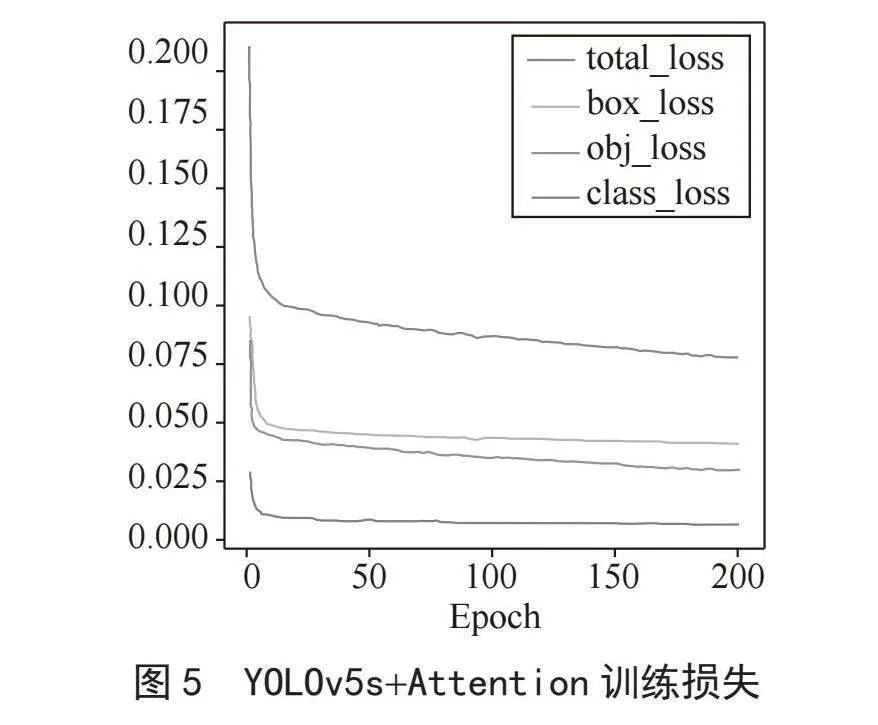
为了对模型性能进行评价,本文引入损失函数来衡量预测值与实际值之间的差异。当损失函数的值较大时,预报误差也相应较大;反之,若损失函数的值较小,则预测结果更接近真实数值。
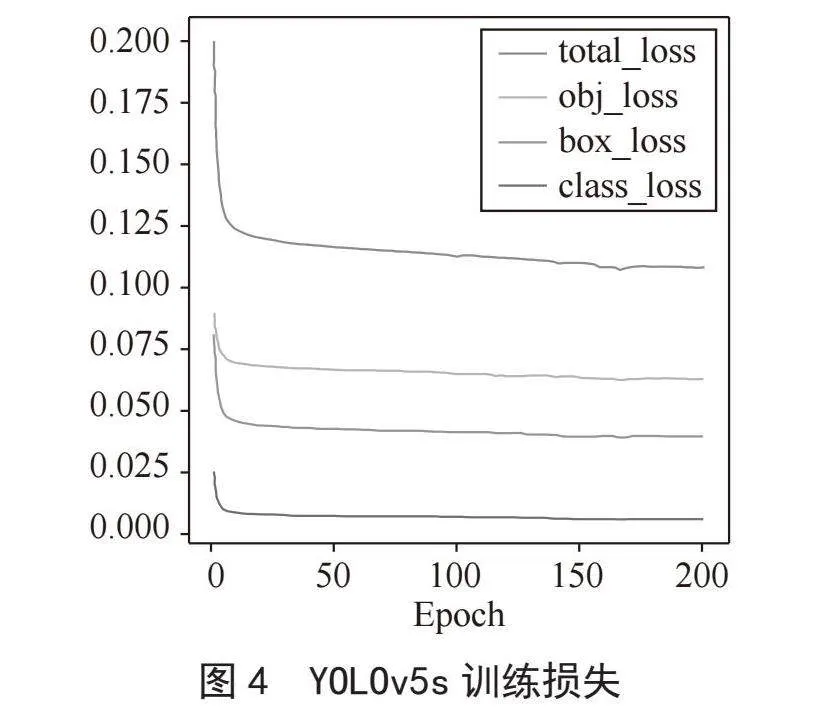
图4和图5分别为YOLOv5s和YOLOv5s+ Attention训练过程中的损失变化。由图可知,趋于稳定后,两模型的损失值都较低。训练初期,YOLOv5s损失值为0.21,约经过150轮训练迭代后逐渐收敛,当轮次到达200轮时损失函数最低至0.11。而YOLOv5s+Attention初始损失为0.22,约170次迭代后收敛,200次时损失最低至0.079。
4.2.3" 模型验证
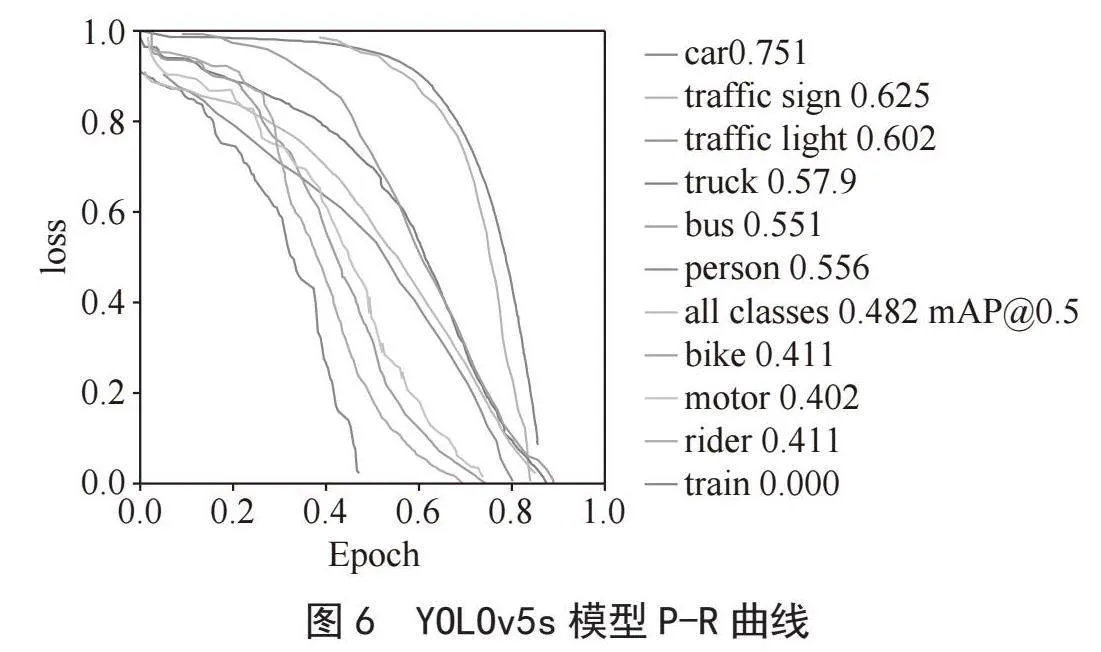
本文使用P-R曲线计算AP值,以评估各类目标的检测表现,并通过mAP评估模型的整体检测效果。为确保训练条件一致,本文对YOLOv5s模型和YOLOv5s+Attention模型进行了训练。随后利用测试集检验训练好的模型,并计算其准确率及其他性能指标。需要强调的是,准确率和召回率这两个指标一般都会呈现相反趋势,提高准确率往往会导致召回率降低。如果希望将召回率提升,可以适当降低双分类器预测正例的阈值。在实践时本文结合这两者综合调控,通过P-R曲线全面评估模型性能。
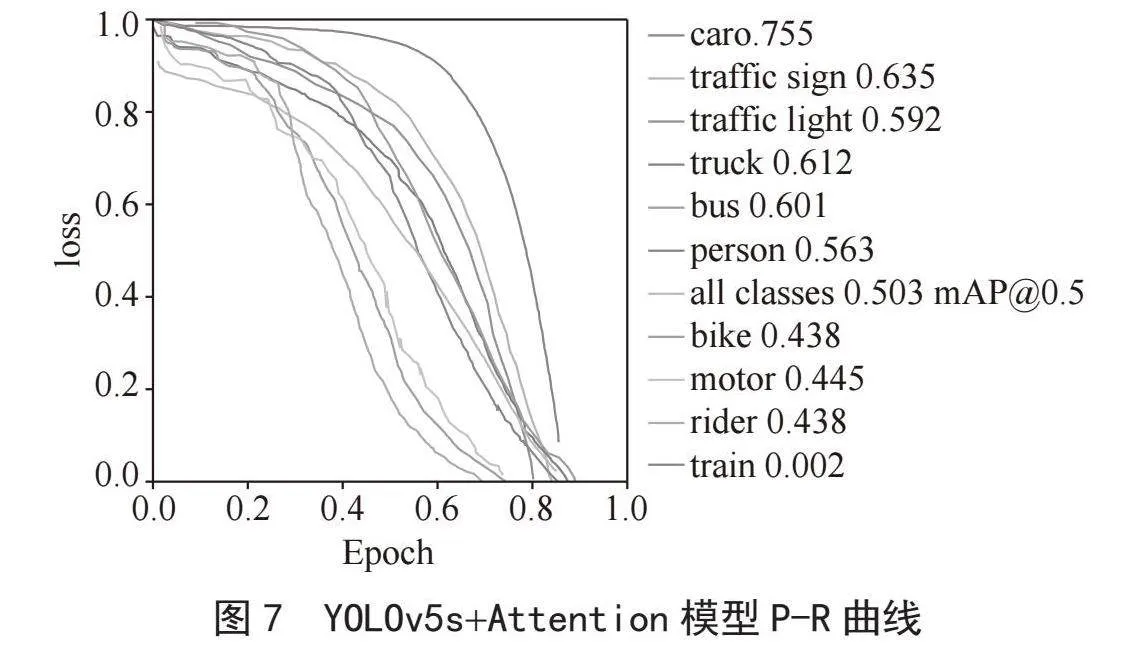
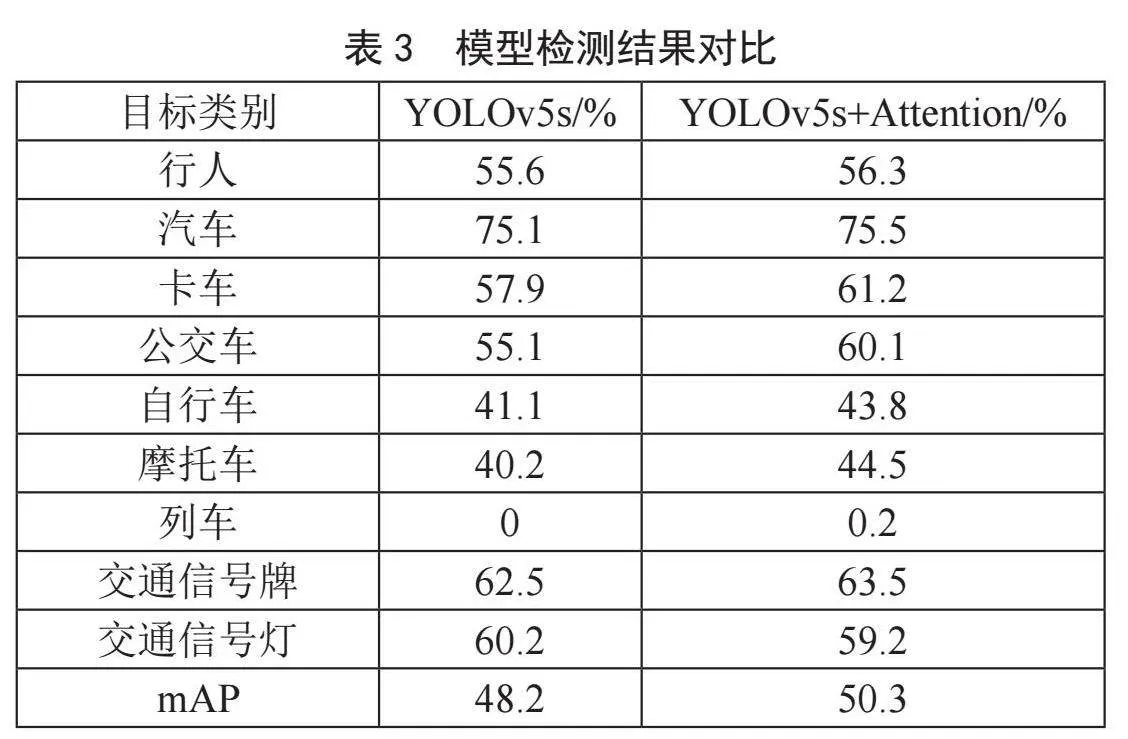
图6和图7给出了为置信度阈值为0.5时,YOLOv5s和YOLOv5s+Attention模型的目标检测P-R曲线图,不同颜色的线条表示了不同检测目标,检测目标曲线下的面积即为该目标的AP值,计算各个目标的AP值后得到mAP值即蓝色线。由图中可以看出,相较于YOLOv5s,YOLOv5s+Attention模型的mAP曲线更向右倾斜,表明引入注意力机制后的模型mAP值提高。
表3的实验结果显示,模型在引入注意力机制后,对各目标的检测准确性上均有所提升。其中,汽车的检测准确率较高,而列车的识别效果相对较差,这主要是由于列车的形状较大且数据集中列车样本比例较少。其他实验条件相同,YOLOv5s+Attention模型的mAP值为50.3%,而YOLOv5s模型为48.2%。引入注意力机制后,YOLOv5s+Attention模型在各目标检测精度上均有所提高,mAP值比YOLOv5s模型高出2.1%。实验证明,YOLOv5s+Attention模型表现更为优越。
5" 结" 论
随着人工智能技术和智能驾驶领域的快速进展,路况分析检测成为交通管理中的重要部分。有效的路况分析不仅有助于保障交通安全,还能优化交通流量、减少拥堵。
本文关注复杂路况下的识别准确率问题,提出了一种改进的YOLOv5s模型,融合卷积注意力机制,以提升在复杂环境中的检测精度。经过全面评估,最后进行了实验,结果表明,YOLOv5s+Attention模型的平均准确率提升了2.1%,达49.9%,显示出引入注意力机制的显著效果。
本文提出的模型适用于汽车行驶过程中的路况分析、多种物体检测任务,能有效应对城市、乡村和高速公路等复杂驾驶场景,实现汽车碰撞预警等目标。本文的方法实现了车辆对道路上车辆的精准检测和车流量统计,为驾驶决策提供了可靠数据支持,为未来智能交通系统的优化提供了重要理论依据和实践指导,具有一定的实际意义。
参考文献:
[1] 林德铝,刘畅,陈琦,等.基于低秩分解的YOLO轻量化目标检测模型 [J].机车电传动,2024(1):138-144.
[2] 李小波,李阳贵,郭宁,等.融合注意力机制的YOLOv5口罩检测算法 [J].图学学报,2023,44(1):16-25.
[3] 李明熹,林正奎,曲毅.计算机视觉下的车辆目标检测算法综述 [J].计算机工程与应用,2019,55(24):20-28.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[6] 孙钿,张意,韩旭东,等.基于YOLOV5s改进的复杂场景下军事目标检测算法 [J/OL].弹箭与制导学报, 2024:1-8(2024-09-12).http://kns.cnki.net/kcms/detail/61.1234. TJ.20240911.2041.004.html.
[7] 袁家乐,郑建明,宋宇峰.基于改进的YOLOv7地下矿无人驾驶目标检测 [J].长江信息通信,2024,37(7):52-55.
[8] 陆金辉,鲍楠,胡晗,等.城市道路车辆行为识别方法研究 [J].移动通信,2023,47(10):38-43.
[9] 申铉京,李涵宇,黄永平,等.基于自适应多尺度特征融合网络的车辆检测方法 [J/OL].电子学报,2024:1-9(2024-03-31).http://kns.cnki.net/kcms/detail/11.2087. tn.20230330.1000.056.html.
[10] 马军策.面向自动驾驶的三维目标检测方法研究与应用 [D].北京:北方工业大学,2024.
作者简介:许德衡(1993.09—),男,汉族,江西上饶人,助教,硕士,研究方向:计算机视觉。