
摘" 要:金融欺诈严重威胁金融市场稳定,而现有的反欺诈手段存在单一性和低效率的问题。为此,文章基于集成学习方法构建了金融交易欺诈识别模型,旨在提升欺诈识别效果。研究中采用装袋法(Bagging)和提升法(Boosting)构建了4个基础模型,并通过优化参数筛选出2个效果较好的模型。随后,利用堆叠法(Stacking)对这2个模型进行融合训练,进一步提高了模型的识别率。实验结果表明,融合模型在金融交易欺诈识别中具有显著优势。与基础模型相比,其在不同数据集上的准确率更高,尤其在处理复杂欺诈模式和新型手段时,展现出更高的准确性和稳定性。这种改进的模型方法为金融决策者和相关部门提供了有效的决策支持,有助于提升金融市场的安全性。
关键词:集成学习;金融欺诈;Boosting;Stacking
中图分类号:TP181;F830" 文献标识码:A" 文章编号:2096-4706(2025)04-0173-06
Research on Financial Transaction Fraud Identification Based on Ensemble Learning
ZHENG Deming1, LI Sijia2, PAN Yankai2, ZHENG Jianlong1
(1.Graduate School, China Peoples Police University, Langfang" 065000, China;
2.Smart Policing College, China Peoples Police University, Langfang" 065000, China)
Abstract: Financial fraud seriously threatens the stability of financial markets, and the existing anti-fraud methods have the problems of singleness and inefficiency. Therefore, this paper constructs a financial transaction fraud recognition model based on the Ensemble Learning method, aiming to improve the fraud recognition effect. In the research, four basic models are constructed by Bagging and Boosting, and two models with better effects are selected by optimizing parameters. Subsequently, the Stacking method is used to conduct fusion training for the two models, which further improves the recognition rate of the model. The experimental results show that the fusion model has significant advantages in financial transaction fraud identification. Compared with the basic model, it has higher accuracy with different datasets, especially in dealing with complex fraud patterns and new means, showing higher accuracy and stability. This improved model method provides effective decision support for financial decision makers and relevant departments, and helps to improve the security of financial markets.
Keywords: Ensemble Learning; financial fraud; Boosting; Stacking
0" 引" 言
随着金融科技的迅猛发展,金融交易活动日益便捷和多样化,但这也为金融诈骗行为提供了更为广阔的舞台,使得金融交易欺诈检测成为金融业和金融监管机构面临的重大挑战。频繁发生的新型金融欺诈事件,严重破坏了金融市场的秩序,阻碍了社会经济的健康发展[1]。2022年3月的政府工作报告中明确指出,加强风险预警、防控机制和能力建设的必要性[2]。尽管传统的金融欺诈检测方法已经取得了一定的成效,但随着诈骗手段的不断升级,产生了包括对新型欺诈模式识别不足、误报率高和适应性差等的许多问题。集成学习通过结合多个学习器来提高识别精度,在金融诈骗检测中表现出显著优越。与单一模型比,其能处理噪声和不平衡问题,增强泛化能力,并保持较高的稳健性。因此,本文基于集成学习方法,研究金融交易欺诈识别,优化模型选择,为金融欺诈检测注入新活力,辅助投资者决策,提供金融行业未来发展理论依据。
近年来,集成学习被广泛应用于各个领域。许多学者利用集成学习方法来有针对性地提升所需模型性能。陈静[3]提出一种基于Stacking相异模型融合的异常行为检测方法。欧阳潇琴改进AdaBoost算法,提高分类速度和降低计算成本[4]。王军利用蚁群优化算法选择性集成构建数据流分类模型[5]。徐晓杨改进极限学习机(ELM)优化输出权值矩阵计算[6]。王进提出DNA微阵列数据分类的多分类器选择性集成方法[7]。张燕平基于Q统计提出决策树选择性集成学习方法[8]。Zhang构建基于干扰因素的SVM集成学习模型[9]。Feng提出集成学习和专家知识的特征选择方法[10]。Ijeh设计基于决策树的网络攻击检测方法[11]。Wang[12]改进启发式-栈式集成学习提高华法林剂量预测准确性。Moon提出新型异常检测集成学习方法[13]。Huang基于集成学习的特征选择方法融合不同特征选择技术[14]。Nadia提出多模态优化(MMO)技术结合萤火虫算法和互信息评估[15]。Parthasarathy提出基于CART和BIRCH的推荐系统模型提高精确度和F1值[16]。这些研究为集成学习在金融欺诈检测中的应用奠定了基础。
集成学习的改进与发展使将其运用在交易欺诈检测成为可能。因此,本文通过构建集成学习模型,探究最优模型用于金融交易欺诈识别。为可能引起公共关注的金融欺诈事件提出参考意见,为经济危机管理和社会平稳提供科学依据。
1" 数据来源与处理
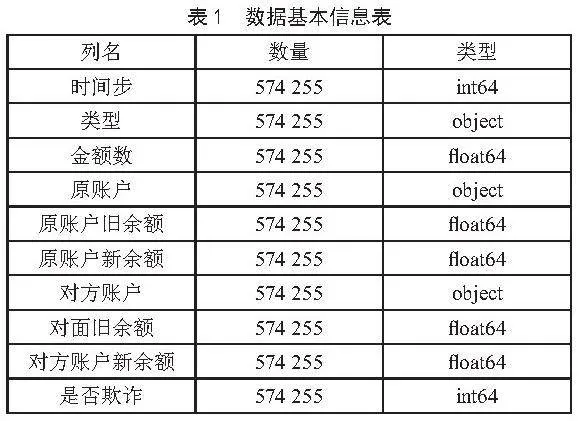
本文采用Kaggle平台上的金融欺诈数据集,该数据集由PaySim模拟器生成,模拟真实交易的同时保护隐私。数据集基于非洲国家真实交易记录,由跨国金融交易服务公司提供,包含常规金融活动和欺诈交易案例。本文仅选取了其中一个交易日的数据进行分析,共涉及574 255笔交易记录,数据由10个不同类型的列组成,部分数据如表1所示。
2" 数据集划分和采样
将数据集划分为训练集和测试集,并将测试集占比设置为20%,这种划分方式能确保模型在训练时有足够的数据进行学习,也能在测试时也能获得足够多的独立样本来评估模型的泛化能力。通过设置stratify参数为标签列,保证了训练集和测试集中正常金融交易与金融诈骗交易的比例与原始数据集一致。此外,模型还设置随机种子,确保了数据划分的一致性和实验的可重复性。
3" 随机森林模型构建与实验分析
随机森林模型是装袋法中的一种经典模型,通过组合多个决策树的预测结果,增强模型的整体泛化性能和预测准确性。在本文中,随机森林模型是基于sklearn.ensemble中的RandomForestClassifier构建的。
在模型构建过程中,本文设定基学习器(决策树)的个数设定为20,以保证模型有足够的多样性。同时,通过设置了随机种子为5,保证实验的可重复性。针对数据集中存在的类别不平衡的问题,采用了class_weight=balanced策略,让模型在训练时对不同类别的样本给予不同的权重,从而提高少数类样本的识别率。经过训练后,利用训练好的随机森林模型对测试集进行预测,并计算了混淆矩阵来评估模型的性能。混淆矩阵直观地展示了模型在各类别上的分类效果,包括真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)的数量。
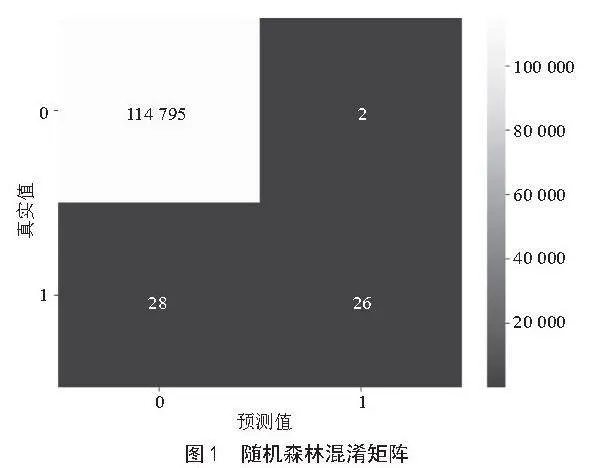
为了更直观地展示混淆矩阵,绘制了混淆矩阵热力图,如图1所示。
根据混淆矩阵的结果,可以看到模型在负类(标签为0)上的表现非常出色,几乎达到了完美的分类效果,真反例(TN)高达114 796,假反例(FN)仅有28。然而,在正类(标签为1)上,模型的表现稍显不足,虽然真正例(TP)有26,但假正例(FP)也有1个,导致了较低的召回率(Recall)。
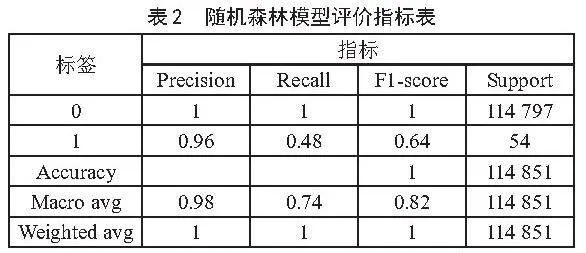
表2展示随机森林模型评价指标。模型分类精度达1.00,但正类精确率虽然较高,召回率只有(0.48),漏报率较高。F1值较低,反映出模型在正类综合性能不佳。尽管随机森林模型在负类样本的分类上表现出色,但在正类样本上的性能表现还不是很好。
4" CART决策树模型构建与实验分析
为进一步实现目标,本文还采用了CART决策树模型对数据进行分类。本文利用sklearn.tree中的DecisionTreeClassifier类创建了CART决策树分类器。在模型创建过程中,选择基尼不纯度作为划分标准,并设置类别权重平衡,以应对数据集类别不平衡问题。确保模型训练关注各样本,避免偏向多数类,提升少数类识别率。
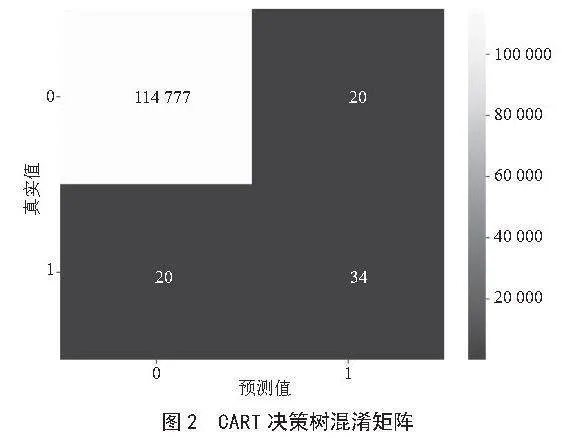
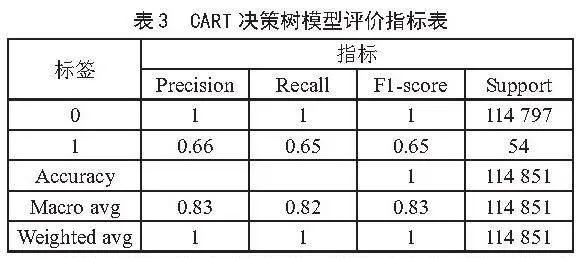
在模型构建完成后,使用训练数据对模型进行了拟合。通过递归地将训练数据划分为不同的子集,并在每个子集上做出预测,模型逐渐学会了如何根据输入特征进行分类。然后,使用训练好的模型对测试数据进行了预测。并做出混淆矩阵热力图和模型评价指标图,如图2和如表3所示。
从混淆矩阵的结果来看,模型在负类(标签为0)上的表现非常出色,真反例(TN)高达114 777,假反例(FN)仅有20个,这表明模型对负类样本的识别能力很强。然而,在正类(标签为1)上,模型的表现略显不足,虽然真正例(TP)有34个,但假正例(FP)也有20个,导致正类的精确率(Precision)和召回率(Recall)均仅为0.63。
表3为CART决策树模型的评价指标表。分类指标显出,模型的整体精度(Accuracy)很高,达到了1.00,但这主要得益于负类样本的准确分类。对于正类样本,尽管模型虽然能够识别出部分真正例,但同时也存在较多的误分类情况,导致精确率和召回率均较低。
5" XGBoost模型构建与实验分析
5.1" XGBoost模型构建
XGBoost是一种基于决策树的集成机器学习算法,它利用梯度提升框架对交易数据进行学习和预测。在本文研究中,我们首先建立了一个XGBoost分类器,其中包含100个基学习器,即模型将融合100棵决策树进行训练。将学习率设定为0.3,该参数决定了各个树对最终结果的影响程度。考虑到金融欺诈数据的不平衡性,本文采用了binary:logistic作为目标函数,并通过scale_pos_weight参数给予少数类(欺诈类)更高的权重,以此来弥补正样本相对于负样本数量的不足。
在模型训练过程中,本文使用训练集x_train和y_train来训练XGBoost分类器。通过模型拟合训练数据,XGBoost能够学习到数据的复杂结构和交易之间的关系。随后,模型在测试集x_test上进行预测,生成预测结果y_pred_xgbt。
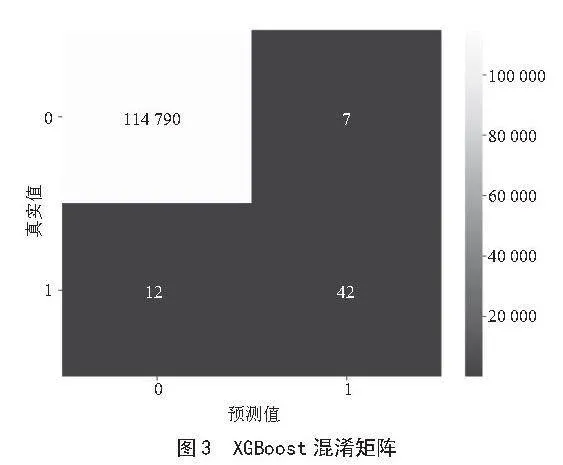
模型训练完成后,本文利用测试集对模型进行了评估,并输出了混淆矩阵。同时绘制了XGBoost模型混淆矩阵热力图和模型评价指标图,如图3所示。
从混淆矩阵的结果来看,模型对于类别0即非欺诈交易,表现出极高的识别能力,精确率、召回率和F1分数均达到1.00。对于类别1即欺诈交易,尽管数据集中的正例较少,模型仍然实现了0.68的精确率和0.78的召回率,F1分数为0.72。这表明模型在保持低误报率的同时,能够较好地识别出欺诈交易。通过上述分析发现,基于XGBoost的集成学习模型的识别效果最佳。
5.2" XGBoost模型的优化
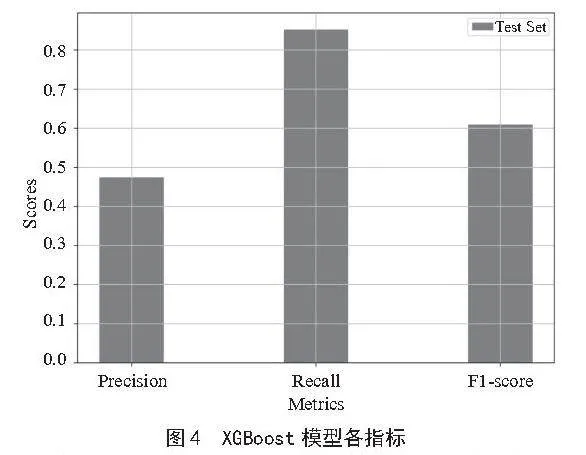
在XGBoost模型的调参过程中,本文借助采用网格搜索(GridSearchCV)来寻找最优参数组合。首先,定义了参数网格param_grid,其中包含了n_estimators(树的数量)和scale_pos_weight(正样本权重)的候选值。本文重点关注这两个候选值,通过手动输入参数范围,网格搜索会自动遍历所有可能的参数组合,并基于F1分数评估每个组合的性能,最终输出最佳参数和对应的分数。通过多组参数实验,将其性能优化。最终确定在选择参数n_estimators=5,和scale_pos_weight=25时,模型表现良好,对金融诈骗交易(少数类)的召回率达到了85.2%,各项指标展示如图4所示。
为了进一步提升模型性能,将基学习器的数量增加到1 000,增加迭代空间以缓慢学习数据中的复杂模式。然而,基学习器数量的增加往往会伴随着过拟合风险,因此我们将学习率降低至0.01,以增强模型的泛化能力并确保学习过程的稳定性。同时,设置树的最大深度为6,以平衡模型复杂性和性能。较小深度限制学习能力,避免过拟合。此外,将子样本和特征列比例设为0.8,每次迭代随机选择80%样本和特征训练树,从而增加模型多样性并提高其稳定性和准确性。
XGBoost模型升级,还调高了scale_pos_weight以应对数据不平衡问题,进一步聚焦金融欺诈识别。同时,引入早停机制,连续10轮无改善即停止训练,以减少计算成本并防过拟合。
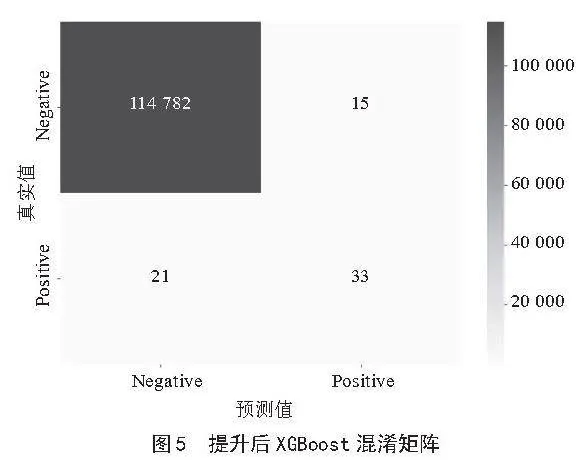
改进后的XGBoost模型在精确率上有了显著提升从0.47增加到0.60。召回率保持在0.85,表示模型依旧能够识别绝大多数正样本。这两个方面的提升也使得F1分数增加到了0.70,表明改进后的模型在保持较高召回率的同时,提高了识别正样本的准确性,更加有效地平衡了分类的精确度和召回率,如图5所示。
6" 融合模型构建与实验分析
本文采用Stacking集成学习技术,将不同基模型的决策能力结合起来,形成一个更加强大的预测器。本文的融合模型使用了两种基学习器:XGBoost和CART决策树,以及一个作为元学习器的逻辑回归模型。
具体操作为配置XGBoost的参数,包括200个树模型的数量,0.3的学习速率,以及针对二分类目标的binary:logistic为目标函数。同时,为了对抗数据集中可能存在的类别不平衡,本文设定了scale_pos_weight参数。
另一方面,CART决策树以其简单直观和对数据中非线性关系的捕捉能力而被选中。决策树的gini准则用于测量分割的纯度,而class_weight参数设置为balanced,以自动调整权重,这对抗数据集中的类别不平衡同样至关重要。
本文最终选择逻辑回归为元学习器。这些模型被集成在一个StackingClassifier中,其中estimators参数包含了所选的基学习器,它们的预测结果将作为新特征提供给逻辑回归模型进行最终的预测。StackingClassifier的stack_method参数设为auto,允许模型自动选择每个基模型的堆叠方法,而n_jobs参数设置为-1,以利用所有可用的CPU核心进行模型训练,以加速训练过程。
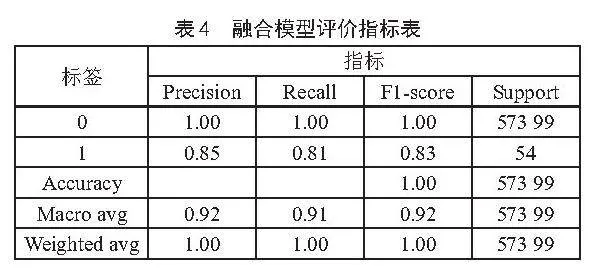
对于类别0即非欺诈交易,精确率、召回率和F1分数均为1.00。这一结果凸显了模型在识别正常金融交易的强大能力。对于类别1即欺诈交易,模型精确率达到0.85,召回率达到0.81,而F1分数达到了0.83。这表明Stacking模型能够有效地识别出绝大多数欺诈交易,并且保持较低的误报率。图6为Stacking融合模型混淆矩阵,表4为融合模型评价指标表。
7" 实验结果对比分析
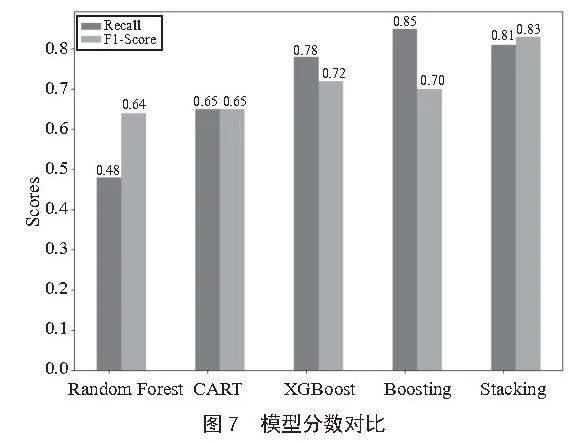
在金融交易欺诈识别领域,召回率和F1值常被用来评价模型性能。召回率衡量模型识别欺诈案例比例,与金融机构防欺诈能力密切相关;F1值综合精确率和召回率,能够更全面地评估不平衡数据集模型表现。本文比较五种集成学习模型在这两方面的性能,如图7所示。
基于上述分析综合考虑召回率和F1值,在单个基础集成学习模型中,XGBoost模型表现出最优的识别效果。而Stacking融合模型在上述金融交易欺诈识别的集成学习研究中呈现出最佳的性能。它能保持较高的召回率,也有着较好的精确率与F1值,表明了其在识别金融欺诈交易的同时,减少了误判的可能性。综上所述,Stacking融合模型在研究中显示出了最佳性能,并且是最有应用前景的模型。
8" 结" 论
本文基于集成学习的方法,构建了多个金融交易欺诈识别模型,包括随机森林、CART、XGBoost以及XGBoost提升后模型和Stacking融合模型。通过对这些模型进行实验分析,比较了它们的性能差异,并找出了适合金融交易欺诈识别的模型。
本文的研究和实验分析尝试将集成学习方法应用在警务实,借助先进的金融交易欺诈识别技术,以对于提升警务实战能力。金融交易欺诈识别技术在集成学习方面的发展将为警务实战提供有力支持,也应加强与金融机构、科技公司等的合作,共同建立金融交易欺诈信息共享平台,实现数据的互通有无。这将有利于警务部门更全面地掌握金融交易欺诈的情况,制定更有针对性的打击策略。从而助力我们构建一个更加安全、稳定的金融和社会环境。
参考文献:
[1] XU J,CHEN D Y,CHAU M. Identifying Features for Detecting Fraudulent Loan Requests on P2P Platforms [C]//2016 IEEE Conference on Intelligence and Security Informatics (ISI).Tucson:IEEE,2016:79-84.
[2] 夏平凡.面向数字金融欺诈的智能风险预测方法研究 [D].合肥:合肥工业大学,2022.
[3] 陈静,王铭海,江灏,等.Stacking相异模型融合的实验室异常用电行为检测 [J].实验室研究与探索,2024,43(1):231-237.
[4] 欧阳潇琴,王秋华.基于改进权值更新和选择性集成的AdaBoost算法 [J].软件导刊,2020,19(4):257-262.
[5] 王军,刘三民,刘涛.基于蚁群优化的选择性集成数据流分类方法 [J].长江大学学报:自科版,2017,14(5):37-43+85-86.
[6] 徐晓杨,纪志成.选择性集成极限学习机分类器建模研究 [J].计算机应用与软件,2016,33(9):279-283.
[7] 王进,冉仟元,丁凌,等.Bagging选择性集成演化硬件DNA微阵列数据分类方法 [J].高技术通讯,2013,23(12):1236-1241.
[8] 张燕平,曹振田,赵姝,等.一种新的决策树选择性集成学习方法 [J].计算机工程与应用,2010,46(17):41-44.
[9] ZHANG D,JIAO L C,BAI X,et al. A Robust Semi-Supervised SVM Via Ensemble Learning [J].Applied Soft Computing,2018,65:632-643.
[10] FENG X,ZHAO Y L,ZHANG M,et al. Ensemble Learning-Based Stability Improvement Method for Feature Selection Towards Performance Prediction [J].Journal of Manufacturing Systems,2024,74:55-67.
[11] IJEH V,MORSI W G. Smart Grid Cyberattack Types Classification: A Fine Tree Bagging-based Ensemble Learning Approach with Feature Selection [J/OL].Sustainable Energy,Grids and Networks,2024,38:101291[2024-08-20].https://www.sciencedirect.com/science/article/abs/pii/S2352467724000201?via%3Dihub.
[12] WANG M Y,QIAN Y Y,YANG Y D,et al. Improved Stacking Ensemble Learning Based on Feature Selection to Accurately Predict Warfarin Dose [J/OL].Frontiers in Cardiovascular Medicine,2024,10:1320938(2021-01-19).https://doi.org/10.3389/fcvm.2023.1320938.
[13] MOON J H,YU J H,SOHN K A. An Ensemble Approach to Anomaly Detection Using High- and Low-variance Principal Components [J/OL].Computers and Electrical Engineering,2022,99:107773[2024-08-26].https://www.sciencedirect.com/science/article/abs/pii/S0045790622000714?via%3Dihub.
[14] HUANG D,LIU Z G,WU D. Research on Ensemble Learning-Based Feature Selection Method for Time-Series Prediction [J/OL].Applied Sciences,2023,14(1):40(2023-12-20).https://doi.org/10.3390/app14010040.
[15] NADIA N,MORTEZA R,MAHDI E. A New Evolutionary Ensemble Learning of Multimodal Feature Selection from Microarray Data [J].Neural Processing Letters,2023,55(5):6753-6780.
[16] PARTHASARATHY G,DEVI S S. Ensemble Learning Based Collaborative Filtering with Instance Selection and Enhanced Clustering [J].Computers, Materials amp; Continua,2022,71(2):2419-2434.
作者简介:郑德铭(1998—),男,汉族,福建莆田人,硕士研究生,研究方向:数据警务技术;李思佳(1987—),女,汉族,江西南昌人,讲师,硕士生导师,博士,研究方向:网络舆情、大数据分析;潘彦恺(2002—),男,汉族,湖南常德人,本科在读,研究方向:数据警务技术;郑健龙(2001—),男,汉族,浙江义乌人,硕士研究生在读,研究方向:数据警务技术。
收稿日期:2024-10-02
基金项目:河北省社会科学基金项目(HB22SH011)