
摘" 要:基于开源大语言模型ChatGLM,构建一个面向教学和科研的对话语言模型。首先,介绍了ChatGLM的基本原理和在自然语言处理领域的优势。其次,探讨了如何利用ChatGLM构建适用于教学和科研场景的对话语言模型,包括模型的部署、模型的微调、问答系统的构建等关键步骤。最后,对构建完成的模型效果进行了评估,并根据教研行业的特点,对其在教育和科研场景的应用进行探索,实现AI赋能教学和科研的目标。将大语言模型应用于教学科研和学生管理工作中,为提升教师工作效率和质量提供了新的思路和解决方案。
关键词:ChatGLM;教研对话;大语言模型;自然语言处理;问答系统
中图分类号:TP18;TP391" 文献标识码:A" 文章编号:2096-4706(2025)04-0162-05
Research on Teaching and Research Dialogue Language Model Based on ChatGLM
ZOU Yanni, HE Xueqi
(Guangdong Polytechnic of Science and Technology, Zhuhai" 519090, China)
Abstract: Based on the open source Large Language Model ChatGLM, a dialogue language model for teaching and research is constructed. Firstly, the basic principles of ChatGLM and its advantages in the field of Natural Language Processing are introduced. Secondly, it discusses how to use ChatGLM to construct a dialogue language model suitable for teaching and research scenarios, including key steps such as model deployment, model fine-tuning, and question answering system construction. Finally, the effect of the constructed model is evaluated, and according to the characteristics of the teaching and research industry, its application in education and scientific research scenarios is explored to achieve the goal of AI enabling teaching and scientific research. The application of Large Language Model in teaching and scientific research and student management work provides new ideas and solutions for improving the efficiency and quality of teachers work.
Keywords: ChatGLM; teaching and research dialogue; Large Language Model; Natural Language Processing; question answering system
0" 引" 言
随着人工智能技术的飞速发展,自然语言处理(Natural Language Processing, NLP)在很多领域展现出了巨大的潜力和价值。特别是随着大语言模型(Large Language Model, LLM)的兴起,人工智能领域迎来了飞速发展,并在医疗健康、金融服务等领域得到了广泛应用。教育技术作为推动教育现代化的重要力量,一直在寻求与新兴技术的结合点。如何将这些技术有效融入教育工作中,提升教育质量和效率,仍是教育领域面临的重要挑战。
2023年5月,联合国教科文组织召开全球教育部长会议,共同探讨人工智能应用在当下和长远意义上给教育系统带来的机遇、挑战与风险[1]。同年,发布了《生成式人工智能在教育和科研中的应用指南》[2]。2023年5月29日,习近平总书记也在主持中共中央政治局第五次集体学习时指出:“教育数字化是我国开辟教育发展新赛道和塑造教育发展新优势的重要突破口”[3]。随着人工智能时代的到来,全国顶尖高校积极应对,纷纷发布相关指南,以引领人工智能赋能教育教学发展前沿。使用生成式人工智能,可以帮助学生提高学习效率,辅助教师进行教学设计,提供教学资源,充当教学助手。尽管生成式人工智能技术在教育领域的应用前景广阔,但要充分发挥其潜能,还需要进行深入的研究。通用大模型通常基于广泛的公开文献和网络信息进行训练,缺乏专业知识和行业数据的积累,因此对于特定行业和领域在专业性、精准度方面还存在一定的不足[4]。构建教研场景的私有化大模型,基于专业的教学资源、科研材料,不仅能够增强数据的隐私和安全性还能实现定制化和灵活性。
1" 教研对话语言模型的构建
1.1" 预训练模型选择
2023年,ChatGPT 3.5的问世,在全社会引起了巨大反响。OpenAI使用人类反馈强化学习(Reinforce-ment Learning from Human Feedbac, RLHF)技术对ChatGPT进行训练,它能够准确理解和生成自然语言。国内众多企业和科研机构也纷纷推出自主研发的大模型产品,如百度的文心一言、智谱AI的GLM大模型、中科院的紫东太初大模型、百川智能的百川大模型、科大讯飞的星火大模型等[2]。其中,由智谱AI和清华大学KEG实验室联合发布的对话预训练模型ChatGLM备受关注。
ChatGLM是基于Transformer架构的对话生成模型,通过自注意力机制和位置编码来捕捉输入序列中的长距离依赖关系,能够更好地处理长距离依赖和复杂语言现象[5-6]。通过对大规模文本数据进行无监督学习,构建了一个生成式预训练模型。这个模型能够生成连贯、有逻辑的文本,从而在对话中产生自然流畅的回复。ChatGLM 3是智谱AI和清华大学KEG实验室联合发布的第三代对话预训练模型。ChatGLM 3-6B是ChatGLM 3系列中的开源模型,不仅对话流畅,部署门槛低,而且有更强大的基础模型,更完整的功能支持,以及更全面的开源序列。对于10B以下模型,它在语义、数学、推理、代码和知识等不同维度的性能都名列前茅,在中英文数据集上的表现也非常突出。最重要的一点是保持6B这种低参数量,让我们可以在消费级的显卡上部署大语言模型[7]。因此,选择ChatGLM 3-6B作为本次研究的基础模型,探索其在教研领域的应用价值。
1.2" 模型部署与微调
模型部署指在服务器上部署私有化模型,这种部署方式能够完全控制其数据,保证隐私及数据安全。在进行部署之前,首先要确认硬件环境,需要一台或多台高性能的个人计算机或服务器。对应ChatGLM 3-6B模型的硬件配置说明,在选择GPU时,若量化等级为单精度,微调时GPU显存占用需22 GB,量化等级为半精度,微调时GPU显存占用需14 GB。若硬件显存不够,也可以开启量化,量化等级为INT8,微调时GPU显存占用需9 GB,量化等级为INT4,微调时GPU显存占用需7 GB。同时要保证硬件和驱动的支持,包括CUDA、PyTorch等,特别要注意CUDA和PyTorch版本的兼容性。在模型部署阶段,首先要下载ChatGLM3的代码仓库,并进入仓库目录安装相关依赖。然后下载ChatGLM 3-6B模型的全部文件,ChatGLM 3-6B提供了两种WebUI,分别是Gradio和Streamlit,修改变量路径为下载模型的路径即可启动服务,服务启动后在浏览器中即可访问该服务。
微调是指将预训练模型在特定数据集上进一步训练的过程,使得模型能够更好地适应特定任务[8]。为了提升模型的生成效率和适应性,让其在教学科研场景中发挥更大的价值,需要收集教研语料,对模型进行微调。微调是一个有监督学习的过程,从微调的参数规模来说,常用的微调方法包括全量微调(Full Fine Tuning, FFT)和参数高效微调(Parameter-Efficient Fine Tuning, PEFT)等[9]。大语言模型的微调是一项计算密集型的任务,全量微调利用特定任务数据调整预训练模型的所有参数,以充分适应新任务。它依赖大规模计算资源,微调过程中,内存不仅要存储模型,还要存储训练过程中必要的参数,其计算资源可能会存在挑战,简单的硬件无法处理这种挑战。而参数高效微调主要通过最小化微调参数数量和计算复杂度,实现高效的迁移学习。它只更新模型中的部分参数,显著降低训练时间和成本,适用于计算资源有限的情况,本研究选用高效参数微调,常用的参数高效微调技术有BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、Adapter Tuning、LoRA(Low-Rank Adaptation of Large Language Models)等。
本研究使用LoRA微调,对大型模型的权重矩阵进行隐式的低秩转换,提高权重的更新效率。在原始的预训练模型旁边增加一个旁路做一个降维再升维的操作,该技术核心在于将模型的关键权重矩阵W重新参数化为一个基础矩阵W0(代表原始模型的权重)与两个低秩矩阵A和B的乘积之和的形式即:
这里,A和B作为待学习的低秩矩阵,在训练过程中被优化以捕获特定任务或数据集上所需的局部适应性变化。通过精心设计的低秩分解,LoRA能够在不显著改变模型全局架构与性能的前提下,仅通过调整这些低秩矩阵,实现对模型输出的精细微调。这种方法不仅大幅减少了需要学习的参数数量,降低了计算复杂度与内存需求,还显著加速了训练过程。
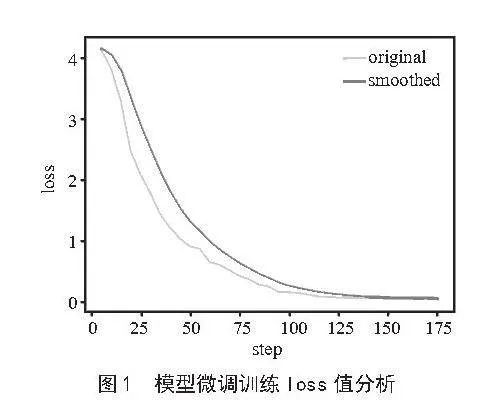
在本研究中,首先准备微调数据集,收集教研领域的专业数据将其转化为微调的指令提示数据集,配置训练参数如模型路径、数据集、学习率、训练轮数、最大梯度范数、截断长度、输出目录等,启动模型的训练过程,训练完成后,就可以使用训练好的模型进行推理,模型微调训练loss值分析如图1所示。
1.3" 基于Lang Chain的检索增强生成RAG问答系统
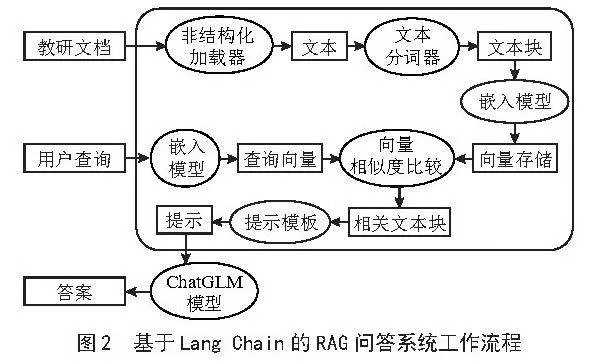
Lang Chain是一个强大的自然语言处理框架,它允许开发人员将大型语言模型与外部的数据源结合起来,比如数据库、PDF文件或其他文档等,它具备强大的文本生成能力和语义理解能力,可以为用户提供高质量的对话体验,简化了大语言模型的应用开发过程。使用RAG的目的是增强大模型,解决大语言模型知识更新困难的问题。不仅可以减少大模型在回答问题时的幻觉问题,还能让大模型的回答基于或参考知识库的相关资料。为了更好地辅助教师和学生,在教学、科研、学生管理等方面助力教师提效提质,在课程学习和答疑等方面为学生提供智能化的服务和支持,帮助学生更高效地学习、提高成绩,使用Lang Chain框架构建RAG问答系统,其工作流程如图2所示。
1.3.1" 构建知识库
知识库是RAG的核心基础,主要将本地数据转换为向量,建立索引并进行存储的详细过程如下:
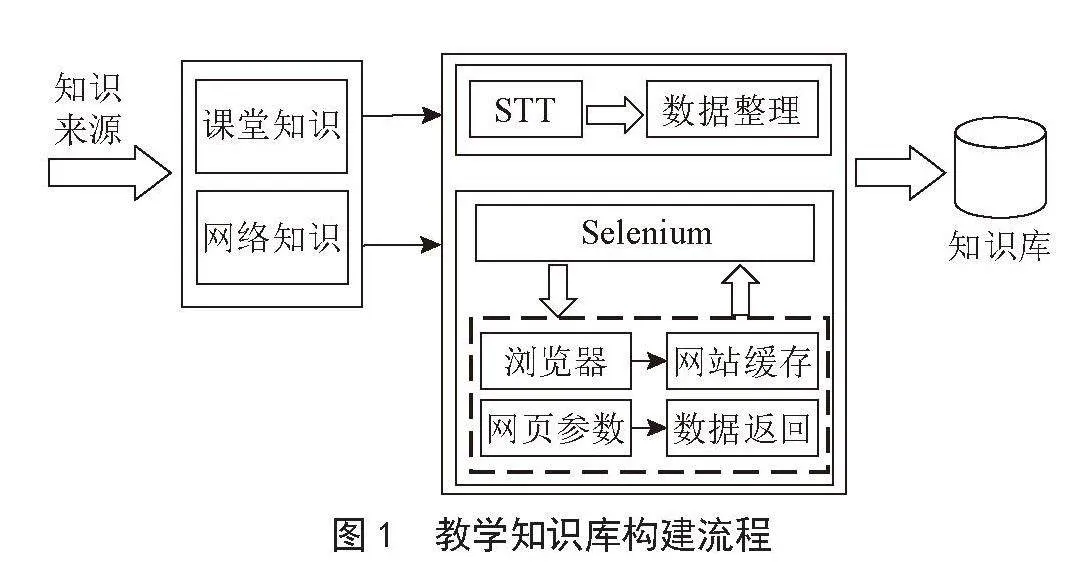
1)数据提取,数据可以来自结构化的数据库,如MySQL,也可以是非结构化的文档体系,如PDF、Word等各类文件,甚至是两者兼具的综合形式。本系统根据需要创建课程知识库、科研知识库、工作助手知识库、校园百科知识库等,并收集对应的课程资料、科研材料、管理文件、校园百科信息等非结构化的文档构成知识库。Lang Chain架构将文档数据通过非结构化加载的方式转换为文本格式,提取知识内容。
2)文本分割,利用分词器将文本转换为文本块。这个过程能够保证所有文本内容能够适应嵌入模型所限定的输入尺寸,同时也能够提升检索效率。
3)向量化,M3E(Multi-task Multi-view Multi-granularity Embedding)是一个多任务、多视角、多粒度的嵌入模型,通过该模型即可实现文本向量化。在Lang Chain框架中,利用该嵌入模型将文本块转换为文本向量。
4)向量数据入库,将文本向量存储到向量数据库中。
1.3.2" 问题检索
用户查询时,系统首先将问题文本输入到嵌入模型中进行向量化处理。随后进行向量相似性检索,在向量数据库中搜索与该问题向量语义上相似的知识文本。
1.3.3" 答案生成
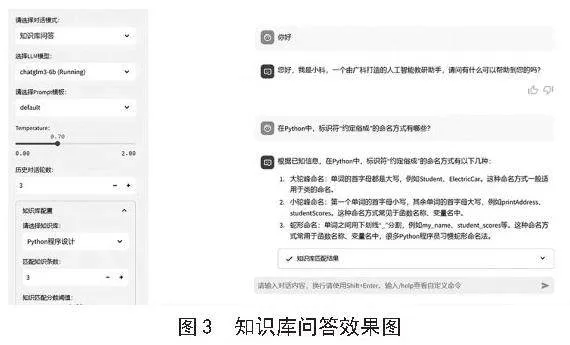
在Lang Chain框架中,需要指定要加载的大语言模型,此时,我们可以通过model_path参数指定要加载的模型为微调后的ChatGLM 3-6B。在答案生成阶段,将问题检索阶段得到的知识文本输入到指定的大语言模型中,通过大语言模型的处理得到问题相应的答案。以Python程序设计课程为例,创建课程知识库,根据知识库进行问答的效果如图3所示。
2" 模型评估
为了进一步验证本文提出的教研对话语言模型的可行性,对模型的效果进行评估。从回答效果展示和性能两个方面进行评估。
2.1" 回答效果展示
实验使用原ChatGLM 3-6B和本研究的模型进行比较,如下所述:
1)ChatGLM 3-6B表示不使用RAG,直接将问题输入到原ChatGLM 3-6B模型生成答案,没有在知识库的相关文档中进行检索。
2)本模型表示微调后的模型,使用RAG,结合知识库生成答案。
以Python程序设计课程知识库和工作助手知识库为例,分别收集Python程序设计课程相关数据和学校管理文件相关数据构成测试集进行实验,模型回答效果示例如下:
问题1:
file=open(rD:\python.txt,r)
file.read(20)
file.read(10)
file.read()
这段代码中,为什么read()函数可以连续读取文件中的内容呢?
ChatGLM 3-6B:这段代码中的read()函数并没有实现连续读取文件中的内容。实际上,read()函数一次读取一行内容,直到文件结束。在这个例子中,read()函数被调用了三次,分别读取了20行、10行和所有行。当你尝试使用read()函数连续读取文件内容时,你将得到一个EOFError错误,因为文件已经读取完毕。要连续读取文件内容,你可以使用readline()函数或循环读取文件,如while循环。
本模型:这是因为文件对象有一个指针(游标),它指向了文件的某个位置。当使用open()函数打开文件时,文件指针的起始位置为0,表示位于文件的开头处(指向第1个字符)。在上述代码中,file.read(20)读取20个字符后,指针的位置变为20(即指向第21个字符);file.read(10)则继续读取10个字符,指针的位置变为为30(即指向第31个字符);file.read()读取剩余的所有字符。要获取文件指针当前位置,可以通过file.tell()方法获得。
问题2:参加期末考试,考试开始多久后才能交卷?
ChatGLM 3-6B:对于期末考试,具体的交卷时间安排因学校和老师而异。通常情况下,考试开始后的1-2小时内,您可以开始作答。考试时间结束后,您可以在老师允许的时间内交卷。请务必看您的课程表或向您的老师咨询,以获取详细信息。
本模型:参加期末考试,考试开始30分钟后方允许交卷。
问题3:旷课12学时会被处分吗?
ChatGLM 3-6B:旷课12学时是否会被处分,需要看具体的学校规定和旷课原因。通常情况下,旷课数量较多时,学校可能会采取警告、纪律处分等措施。但每个学校的规定和处理方式可能不同,因此最好还是咨询学校相关部门了解具体的情况。同时,建议学生遵守学校纪律,珍惜学习机会。
本模型:旷课12学时根据情节轻重及认识态度,应该给予警告以上处分。
从回答效果来看,在进行课程知识问答时,由于模型幻觉,ChatGLM 3-6B模型会生成一些不准确或超出学生认知范围的答案,而本研究的模型,通过在知识库中进行检索,能够生成更具有引导意义和符合学生认知范围的答案,同时可以检索相对应的教学资料让学生学习。在学生管理制度问答中,这个现象更为明显,由于缺乏内部资料,很多问题原ChatGLM 3-6B模型没办法提供准确的答案,而本研究的模型,能够从内部知识库中检索到准确的答案。
2.2" 性能评估
选择准确率来衡量生成答案的精准程度[10],准确率使用包容性匹配的方法进行计算,包含正确答案就认为回答是正确的,准确率计算式为:
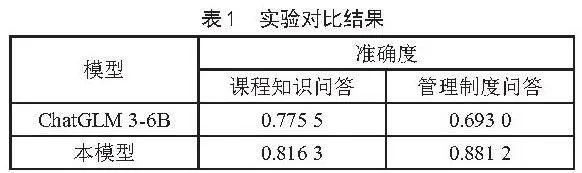
其中,tt为正确回答的数量,nums为要测评的实例数量,实验对比结果如表1所示。
从表1可以看出,在进行课程知识问答时,使用检索增强生成技术生成的答案比原模型会更准确,在学生管理制度问答中,本研究的模型准确度要明显高于原ChatGLM 3-6B模型。
3" 应用场景探索
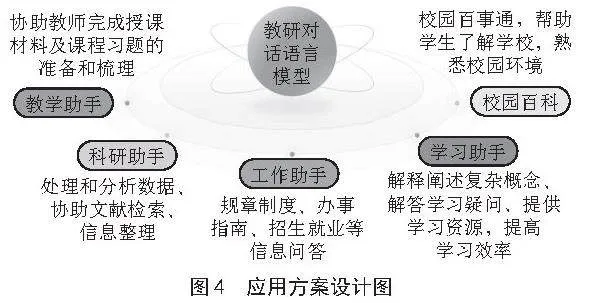
针对教学科研的需要,本模型聚焦多个应用场景,解放人力资源,提高教师的工作效率,给学生提供更加准确和具有引导意义的答案。助力教师教学科研,协助学生高效地完成课程学习,其应用方案设计图如图4所示。
教学助手:根据课程资源,构建课程知识库。协助教师快速完成授课材料及课程习题的准备和梳理等,减轻教师的压力,将教师从繁杂的课前备课和课后答疑的工作中解放出来,让教师有更多时间去关注教学设计、教学评估等更高级别的教学任务。
科研助手:根据中英文科研文献资料,构建科研知识库。通过知识库问答,科研人员可以快速获得文献的关键信息,减轻教师的科研负担,提高科研工作的效率。
工作助手:实时上传学校最新制度、政策法规、办事指南,招生就业信息等文件构建工作助手知识库。问答内容可以定位到制度原文,让教师更方便地了解和遵循学校的规章制度,提高学生管理能力和水平。
学习助手:帮助学生理解复杂问题,通过自然语言处理技术,解释和阐述复杂概念,帮助学生更好地掌握知识,提升学习兴趣与效率。针对学生提出的问题,还可以通过知识库问答,自动匹配该问题的课程资源,解答学生的疑问,提高学习效率和质量。
校园百科:根据学校简介、学校章程、校徽校训、办学历史、学校风貌、地理位置等学校百科信息数据,构建校园百科知识库,满足学生需求,特别是帮助新生更快了解学校,熟悉校园环境。
4" 结" 论
本研究对大模型技术应用于教学科研领域进行了深入探讨研究,部署开源大模型ChatGLM 3-6B,对其进行微调,并探索其与Lang Chain结合实现问答系统的构建。通过对实际应用场景的探索,该模型能够有效提升教师工作效率,解答学生学习生活的疑问。但是该模型还有很大提升空间,受模型参数、教研语料、知识库质量的限制,该模型还有不断进行优化和提升的空间,以更好适应教学科研应用场景。
参考文献:
[1] 崔爽.AIGC时代大学教育的变与不变 [N].科技日报,2023-08-09(5).
[2] 林敏,吴雨宸,宋萑.人工智能时代教师教育转型:理论立场、转型方式和潜在挑战[J].开放教育研究,2024,30(4):28-36.
[3] 刘月涵,霍浩彬,金灿国.构建企业级私有化大语言模型助手基于ChatGLM3与RPA技术的实践与探索 [J].建筑设计管理,2023,40(12):33-40.
[4] 杨兴睿,马斌,李森垚,等.基于大语言模型的教育文本幂等摘要方法 [J].计算机工程,2024,50(7):32-41.
[5] 金立,王丹.归纳与人工智能的双向驱动——基于对ChatGPT的考察 [J].福建论坛:人文社会科学版,2023(7):64-75.
[6] 赖鄹,吴巍,杨晨,等.ChatGPT的发展现状、风险及应对 [J].中国信息安全,2023(7):86-89.
[7] 尹娴,冯艳红,叶仕根.基于ChatGLM的水生动物疾病诊断智能对话系统的优化研究[J].现代电子技术,2024,47(14):177-181.
[8] 官璐,何康,斗维红.微调大模型:个性化人机信息交互模式分析 [J].新闻界,2023(11):44-51+76.
[9] 程乐超.视觉大模型参数高效微调技术应用与展望 [J].人工智能,2024(1):54-65.
[10] 胡志强,李朋骏,王金龙,等.基于ChatGPT增强和监督对比学习的政策工具归类研究 [J].计算机工程与应用,2024,60(7):292-305.
作者简介:邹燕妮(1994—),女,汉族,湖南衡阳人,讲师,硕士,研究方向:大数据技术、信息处理;何雪琪(1995—),女,锡伯族,贵州遵义人,讲师,硕士,研究方向:智能信息处理、机器学习。
收稿日期:2024-08-29
基金项目:2023年广东省普通高校青年创新人才类项目(2023KQNCX183);2022年广东省教育厅特色创新项目(2022KTSCX253)