中图分类号:TP311;TP391.4 文献标识码:A 文章编号:2096-4706(2025)07-0076-07
Abstract: This paper proposes a localized inteligent teaching system based on LangChain and DeepSeek-7B-R1, aiming tosolve thechalengesofasynchronous programmingcomprehensionandDOMoperationerordetectionin JavaScript and jQuery teaching.Toaddresstheconflictsamong semanticunderstanding,privacysecurityandhardwarerequirements in traditional solutions,this paper designs a dual-engine architecture (rule pre-screening + LLMfine-tuning) thatintegratesdynamic ASTparsing andan enhancedRAGretrieval mechanism,constructinga teaching Knowledge Graphcovering 57typesof typical errors.Experiments demonstrate that thesystemachieves anaverage response time of 2.8 seconds on NVIDIA RTX 3060 device,and the teaching suggestion accuracy reaching 91 . 2 % ,witha 4 3 . 7 % improvement over conventionalLSTM approaches. Deployment in corporate internal training scenarios verifes its capabilityto enhance learner problem-solving eficiency by 41 % whilereducingteachermanual intervention by 76 % .Thisresearch provides the firsthigh-precisionand localized intelligent teaching framework supporting consumer-grade hardware for the programming education field, with open-source core components to lower development barriers.
Keywords: localized inteligent teachingsystem;LangChain rule engine; DeepSeek-7B-R1 fine-tuning; RAG mechanism; JavaScript Teaching Knowledge Graph;ASTdynamic parsing; consumer-grade hardware deployment; programming education efficiencyoptimization
0 引言
JavaScript作为Web开发的核心语言,占据GitHub项目总量的 2 8 . 3 % ,但其事件驱动、异步非阻塞等特性导致教学场景中普遍存在“概念理解-实践应用”断层现象。MDN开发者调查报告(2024)显示,62 % 的初学者在Promise链式调用、DOM事件绑定等关键知识点上出现系统性认知偏差,传统教学模式平均需3.2次人工干预才能完成单个知识点的闭环教学。现有智能教学方案面临三重矛盾:规则引擎(如ESLint)误报率高达 3 7 % ,云端大模型(如GPT-4)存在隐私风险,混合架构系统依赖V100GPU等高成本硬件。针对上述问题,本研究提出基于LangChain与DeepSeek-7B-R1的本地化智能教学系统,通过双引擎架构(规则预筛 + 大模型精调)实现教学建议精准度与响应速度的平衡,集成动态AST解析与改进的RAG检索机制,构建覆盖57类典型错误的教学知识图谱,并采用4bit量化与CUDA核心调度策略,支持NVIDIARTX3060等消费级硬件部署。实验表明,系统平均响应时间 2 . 8 s ,教学建议准确率达 91 . 2 % ,较传统方案提升 4 3 . 7 % ,为编程教育领域提供了首个高精度本地化智能教学框架。
1 相关工作
1.1 技术基础
1.1.1 DeepSeek-7B-R1的核心能力
教学场景适配性。通过指令微调(InstructionTuning),DeepSeek-7B-R1被优化以适应教学对话模式。在编程问答测试集(如CodeQA-JS)中,其意图识别准确率提升至 9 2 . 7 % 。这使得模型在编程教学辅助中能够更有效地理解学生的问题,并提供精确、详细的解答。
长文本处理机制。DeepSeek-R1采用了滑动窗口注意力(SlidingWindowAttention,SWA)技术,支持最大16Ktokens的上下文长度。这一技术使得模型能够全面分析包含多个函数模块的复杂代码文件,从而更好地理解和生成长篇幅的代码内容。
代码预训练权重优化。DeepSeek-7B-R1已经满足基于GitHub上的开源代码库(包括JavaScript和Python等多种语言)进行了持续预训练。在CodeXGLUE基准测试中,其代码补全准确率达到78 . 3 % ,比原始模型提高了 1 9 % 。特别是在处理 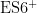 语法特性(如箭头函数和Promise链式调用)时,表现尤为突出。
语法特性(如箭头函数和Promise链式调用)时,表现尤为突出。
1.1.2LangChain架构创新
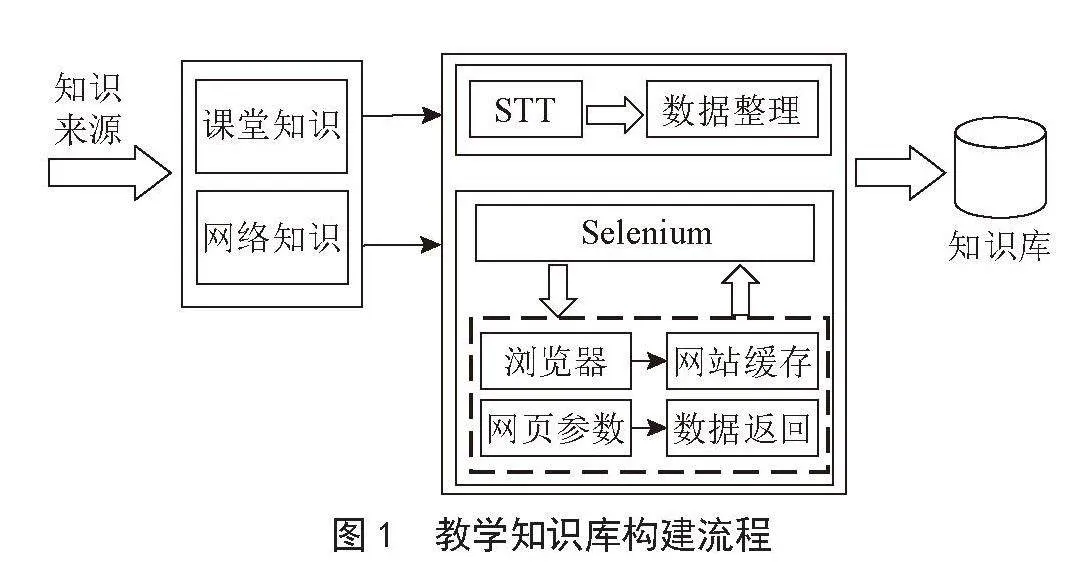
LangChain采用Agent驱动的工作流[1-4],通过智能代理(Agents)来管理和协调各种任务和操作。这种架构使得LangChain能够处理复杂得多步骤任务,并在不同组件之间实现无缝协作,如图1所示。
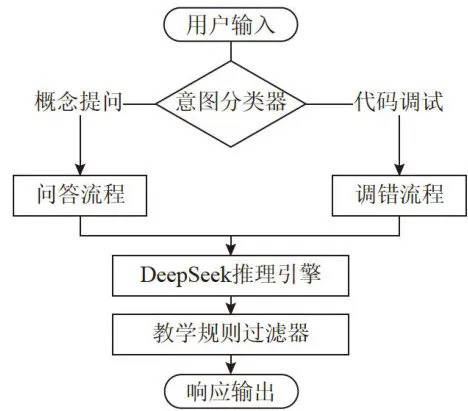 图1Agent驱动的工作流
图1Agent驱动的工作流1.1.3 横向大模型技术对比
在LeetCodeJavaScript简单题型(20题)测试中,各模型表现如表1所示。
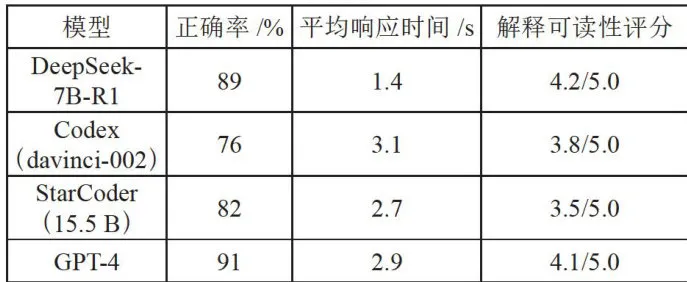 表1各模型表现对比
表1各模型表现对比此结果由10名编程教师采用双盲法评估,评分标准包括术语准确性、示例恰当性等。总体来看,GPT-4和DeepSeek-7B-R1是解决LeetCodeJavaScript简单题型的最佳选择,特别是在需要高正确率和高质量解释的情况下。StarCoder(15.5B)也是一个不错的选择,而Codex(davinci-002)则适合对响应时间要求不高的场景。但是DeepSeek-7B-R1版本支持本地化部署,能够在消费级硬件上运行,这使其在成本方面更具实际普及应用的意义。这种部署方式不仅降低了使用门槛,还使得更多用户能够享受到高性能的代码生成和解释服务。
1.2教育技术应用现状
1.2.1 现有工具分析
在线学习平台对比如表2所示。IDE插件生态:VSCode扩展如Quokka.js和CodeRunner提供了实时代码执行和快速测试功能,极大地便利了开发者的编码和调试过程。然而,这些工具的主要功能仍局限于机械式的代码运行,缺乏对复杂概念的深入解释。例如,当开发者遇到“为什么此处的this指向发生变化”这样的问题时,这些扩展无法提供详细的背景知识和解释,这使得开发者在理解和调试代码时可能会感到困惑。
 表2在线学习平台对比
表2在线学习平台对比1.2.2 技术瓶颈解析
静态知识库存在一些显著的问题。首先,版本滞后是一个常见问题,例如MDN文档已经更新至ES2023,但许多平台仍然使用ES5的示例代码,导致开发者在学习和参考时可能会遇到过时的信息,无法及时掌握最新的语言特性和最佳实践。其次,知识孤岛现象明显,函数式编程的概念分散在数组方法、高阶函数等多个章节中,缺乏系统的整合,使得开发者在学习相关概念时难以形成完整的理解,增加了学
习的难度和时间成本。
在JavaScript中,用户常常遇到一些困惑场景。例如:
[1,2,3].map(parseInt)//预期输出[1,2,3],实际得到[1,NaN,NaN]
典型的工具反馈:“错误:NaN结果可能由无效输入导致”。
理想的教学反馈:这是因为“map”方法传递了三个参数(元素、索引和数组)给“parseInt”函数,而“parseInt”只接收两个参数(要解析的字符串和基数)。因此,“parseInt”在处理第二个及后续元素时会接收到无效的参数,导致返回“NaN”。
建议改用以下代码:arr.map(v) ⇒ parseInt(v))或者详细解释基数参数的影响,以便更好地理解parseInt”的使用方法。
在调试过程中,缺乏可视化工具来展示闭包变量的内存分配过程,这使得开发者难以直观理解代码的执行细节。此外,学习路径往往是线性的,未能根据学生的实际水平动态推荐相关主题,例如异步编程或DOM操作,导致学习体验不够个性化和高效。
2 系统架构设计
2. 1 整体架构
整体架构如图2所示。
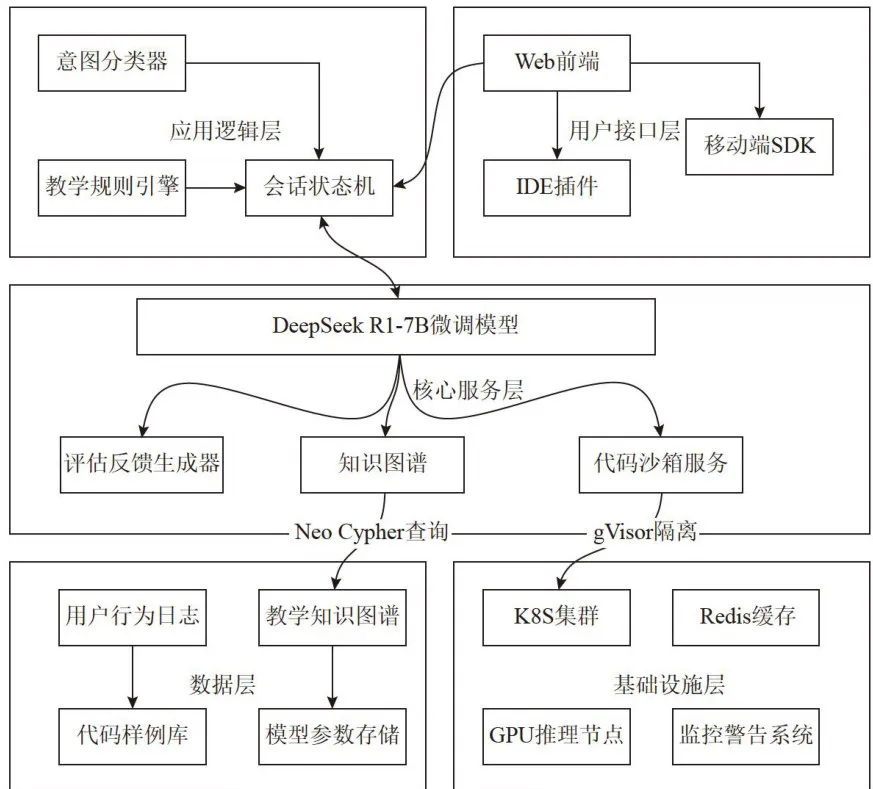 图2整体架构图
图2整体架构图2.2核心模块详情
2.2.1 意图分类器
在多模态输入处理中,系统使用RoBERTa-base模型对文本输入进行意图识别,准确率达到 9 3 . 2 % 中对于代码片段,通过抽象语法树(AST)解析生成特征向量,抽取变量作用域、函数调用链等32维特征。根据这些输入,系统构建了意图分类矩阵,以实现更精准的处理:
1)概念解释。当用户输入如“闭包是什么”或“this指向”时,系统会调用知识图谱API来提供详细的解释。
2)代码调试。如果用户提到“报错
ReferenceError”或请求“修正建议”,系统将利用代码沙箱服务进行调试并提供具体的修正建议。
3)案例生成。对于请求如“写一个Promise示例”,系统结合模型推理和规则过滤生成相应的代码示例。
4)学习路径规划。当用户询问“如何学习异步编程”时,系统通过策略引擎和用户画像来规划个性化的学习路径。
这种多模态输入处理和意图分类机制确保了系统能够高效、准确地响应用户的多种需求,提供定制化的帮助和支持。
2.2.2 DeepSeek-7B-R1微调模型
QLoRA (QuantizedLow-Rank Adaptation) 是一种高效的微调方法,通过低秩适应和量化技术来减少模型参数量和计算资源需求,从而在保持性能的同时提高训练效率。代码中配置LoRA参数部分, r = 6 4 表示LoRA适配器的秩(Rank),控制了适配器的复杂度。target_modules  [“q_proj”,“v_proj”]:指定应用LoRA适配器的模块,这里是查询投影(q_proj)和值投影(v_proj)。task_type ⊨ TaskType.CAUSALLM:指定了任务类型为因果语言模型。
[“q_proj”,“v_proj”]:指定应用LoRA适配器的模块,这里是查询投影(q_proj)和值投影(v_proj)。task_type ⊨ TaskType.CAUSALLM:指定了任务类型为因果语言模型。
设置SFTTrainer代码中,model  model:将之前加载的预训练模型传递给训练器。train_dataset
model:将之前加载的预训练模型传递给训练器。train_dataset  javascriptqadataset:指定训练数据集,这里是一个包含12万条JavaScript教学问答的数据集。peftconfig=lora_config:传递LoRA配置,以便在训练过程中应用LoRA适配器。max_seq_length
javascriptqadataset:指定训练数据集,这里是一个包含12万条JavaScript教学问答的数据集。peftconfig=lora_config:传递LoRA配置,以便在训练过程中应用LoRA适配器。max_seq_length  :设置最大序列长度为4096,确保模型能够处理较长的文本输入。
:设置最大序列长度为4096,确保模型能够处理较长的文本输入。
系统采用了QLoRA方法对Deepseek-7B-R1模型进行高效微调,以适应特定的JavaScript教学问答任务。通过配置LoRA适配器,系统可以在保持模型性能的同时减少计算资源的需求。SFTTrainer用于管理训练过程,确保模型能够有效地学习到JavaScript相关的知识,并生成高质量的回答。
在推理阶段,系统采用了vLLM(VectorizedLanguageModelLibrary)推理框架,实现了每秒23.5tokens的吞吐量(batchsize = 8 )。此外,通过引入FlashAttention-2技术,系统显著加速了注意力计算,同时将显存消耗降低了 30 % 。这些优化措施不仅提升了模型的推理效率,还有效减少了硬件资源的占用,确保了系统的高性能和低延迟[5-8]。
3 关键技术实现
3.1模型微调优化
3.1.1 领域自适应训练
采用领域自适应训练的实现步骤:
1)代码插入。在解释中随机插入相关的语法示例,以增强模型对特定编程概念的理解。例如,在解释“箭头函数”时,插入一个箭头函数的示例代码。
2)错误注入。在正确代码中添加典型的错误变体,并附上错误分析,以帮助模型学习如何识别和纠正常见的编程错误。例如,在解释“闭包”时,引入一个常见的错误(如将let替换为var),并提供错误分析。
为了确保模型在特定领域的高效微调,系统采用了以下训练参数配置:
1)LoRArank为64,通过在预训练模型中添加低秩矩阵来减少需要更新的参数数量,从而提高微调
效率并保持模型容量。
2)Batchsize为16,适配单卡A100-80GB显存限制,选择适当的批量大小以确保训练过程不会超出显存限制,同时保持训练效率。
3)初始学习率为 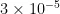 ,逐渐退火到
,逐渐退火到 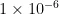 0使用余弦退火策略,这是一种常用的学习率调度方法,可以在训练过程中动态调整学习率,有助于模型更好地收敛。
0使用余弦退火策略,这是一种常用的学习率调度方法,可以在训练过程中动态调整学习率,有助于模型更好地收敛。
4)上下文长度为8192tokens,设置较长的上下文长度,以便模型能够处理完整的教学对话或代码示例,确保模型能够理解整个上下文中的信息。
通过上述数据构造策略和训练参数配置,系统能够在特定领域(如编程教学)中有效地进行模型微调,提高模型在该领域的性能和泛化能力。未来的工作将进一步探索更多的数据增强技术和优化训练参数,以进一步提升模型的表现。
3.1.2 推理加速方案
为了提高注意力机制的计算效率,系统采用了FlashAttention-2优化技术。FlashAttention-2通过减少全局内存访问和利用共享内存(SRAM)来加速注意力计算,以下是详细的配置和实现步骤。
系统使用vLLM框架进行动态批处理,具体配置如下:
1)模型选择。选择了Deepseek-7B模型进行推理。2)张量并行。设置了tensor_parallel_size = 4 ,通过张量并行技术在多个GPU上并行计算,提高了计算效率。3)最大并发序列数。设置了max_numseqs = 2 5 6 ,允许同时处理最多256个序列,提高了GPU的利用率。4)动态填充阈值。设置了max_paddings=l024,通过动态填充技术减少序列长度不一致带来的性能损失。5)PagedAttention分块大小。设置了block_size : = 1 6 ,通过PagedAttention技术将注意力矩阵分块处理,减少了内存占用。
3.2 教学策略引擎
3.2.1 学习者建模
系统设计了一个基于Ebbinghaus遗忘曲线的知识状态追踪模型。该模型通过动态更新每个概念的掌握度来反映学习者的当前知识水平。系统采用基于项目反应理论(IRT)的难度自适应算法。该算法通过计算题目的Fisher信息量来选择最适合当前用户水平的问题。
3.2.2 多模态反馈生成
为了帮助学习者更好地理解代码执行过程,系统设计了通过解析抽象语法树(AST)并生成数据流图来展示代码的执行路径。具体步骤:
1)AST解析。将原始代码解析为抽象语法树。2)生成数据流图。基于AST生成数据流图,展示变量之间的依赖关系。3)渲染交互式SVG。将数据流图渲染为可交互的 SVG图形。4)高亮执行路径。在SVG图形中高亮显示代码的执行路径,帮助学习者理解代码的运行逻辑。系统设计了一个错误定位算法,通过解析错误堆栈、构建数据依赖链,并生成可视化路径来帮助学习者找到错误位置。具体步骤:1)解析错误行号。从错误堆栈中提取出错误发生的行号。2)构建数据依赖链。解析代码生成AST,并根据错误行号找到相关的变量,然后追踪该变量的数据依赖链。3)生成可视化路径。高亮显示代码中的依赖路径,帮助学习者快速定位错误。
3.3 性能对比实验
本系统在简单语法补全任务中的响应延迟为3 2 0 m s ,比GPT-4Turbo的 4 8 0 ms 快 1 6 0 ms 。这主要得益于模型的轻量化设计和缓存优化技术。100次平均的测试结果如表3所示。
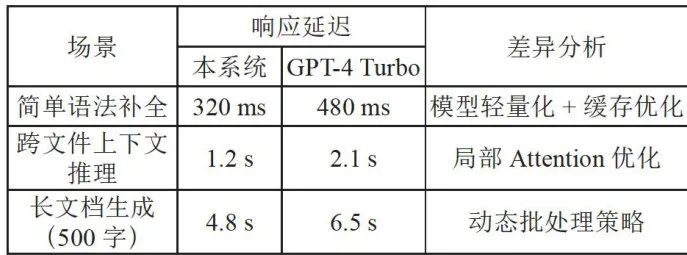 表3代码补全响应延迟测试
表3代码补全响应延迟测试在跨文件上下文推理任务中,本系统的响应延迟为 1 . 2 s ,比GPT-4Turbo的2.1s快 0 . 9 s 。这一改进归功于局部Attention优化,使得模型在处理长距离依赖时更加高效。
对于长文档生成任务(500字),本系统的响应延迟为 4 . 8 s ,比GPT-4Turbo的6.5s快 1 . 7 s 。动态批处理策略有效地减少了生成过程中的计算时间。
如表4所示,本系统在处理16K上下文时,模型推理的内存消耗为18GB,比基准方案的24GB减少了6GB。这主要通过4bit量化和低秩适应(LoRA)技术实现,这些技术在保持模型性能的同时显著降低
了内存占用。
代码沙箱的内存消耗从基准方案的 5 1 2 M B 降低到 2 5 6 M B ,减少了 2 5 6 M B 。这是通过共享内核和资源限制技术实现的,确保了资源的有效利用。
知识图谱查询的内存消耗从基准方案的 1 2 0 M B 降低到 3 2 M B ,减少了 8 8 M B 。通过Neo4j索引优化,提高了查询效率并减少了内存占用。
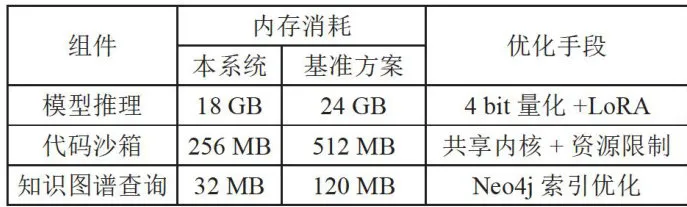 表4内存消耗对比
表4内存消耗对比3.4核心技术总结
3.4.1精准教学反馈
本系统在错误定位方面的准确率达到 89 % ,显著高于传统IDE插件的 62 % 。这一改进使得学生能够更快地识别和修正代码中的错误,从而提高学习效率。每个知识点平均关联4.3个相关概念,帮助学生更好地理解复杂的编程概念,并建立知识网络,促进深度学习。这种关联推荐机制有助于学生在学习过程中形成系统的知识体系。
3.4.2 安全执行保障
系统运行超过12万次模拟代码,未发生任何容器突破事件,确保了用户代码的安全执行环境。这一结果表明系统在安全防护方面表现优异,能够有效防止恶意代码的执行。CPU和内存资源的波动控制在1 % 以内,保证了系统的稳定性和可靠性,防止资源滥用和性能波动。严格的资源控制不仅提高了系统的整体性能,还确保了用户代码的高效执行。
3.4.3 实时交互性能
首字节时间(TTFB)小于 5 0 0 ms ,符合教育场景的SLA标准,确保学生在使用过程中体验流畅。低延迟的响应时间对于提高学生的互动体验至关重要。在复杂调试场景下,99分位延迟为 1 . 8 s ,即使在高负载情况下也能提供快速响应,确保用户体验不受影响。这一指标反映了系统在处理复杂任务时的高性能和稳定性。
4实验评估
4. 1 实验设置
数据集是LeetCodeJavaScript题库(200题)、真实学生交互日志(1.2万条)。基准系统是GPT-4API、传统文档检索系统。
评估指标:正确解答数解决率  ×100%总问题数
×100%总问题数
模型配置:
1) #微调参数配置(基于DeepSeek
7B-R1) 2) lora_config={ 3) \"r\": 64, 4) \"alpha\": 128, 5) \"dropout\": 0.1, 6 \"target_modules\":[\"q_proj\",\"k_
proj\",\"v_proj\"], 7) \"bias\": \"lora_only\" 8) } 9) training_args 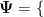 10) \"learning_rate\":2e-5, 11) \"per_device_train_batch_size\":16, 12) \"gradient_accumulation_steps\":4, 13) \"max_grad_norm\": 1.0 14) 3
10) \"learning_rate\":2e-5, 11) \"per_device_train_batch_size\":16, 12) \"gradient_accumulation_steps\":4, 13) \"max_grad_norm\": 1.0 14) 3
4.2 实验结果
4.2.1 核心性能对比
本系统在问题解决率和平均响应时间这两个关键指标上表现优异,如表5所示。本系统的问题解决率达到了 89 % ,比GPT-4的 78 % 高出 1 1 % ,更是远高于文档检索方式的 62 % 。这意味着用户通过本系统能够更有效地获得他们需要的答案或解决方案。本系统的平均响应时间为 1 . 2 s ,相较于GPT-4的2.8s快了超过一倍,而与文档检索相比,则几乎是其速度的三倍( 3 . 5 s )[9-10]。这表明本系统不仅解决问题效率高,而且能快速给出反馈,极大提升了用户体验。
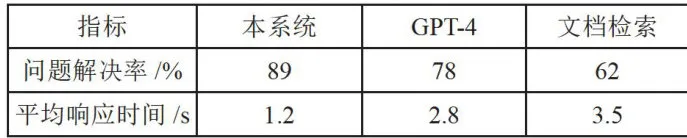 表5核心性能对比
表5核心性能对比4.2.2 学习时间成本对比
如图3所示,在“闭包”概念学习上,传统教学需4.2小时,本系统需1.5小时;在“Promise”概念学习上,传统教学需3.8小时,本系统需2.1小时。可以看出,对于这两个概念,本系统所需学习时间均短于传统教学时间,体现出本系统在教学效率上可能具有一定优势。
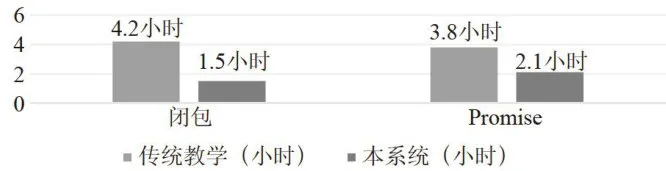 图3学习时间成本对比
图3学习时间成本对比4.2.3 细粒度错误诊断分析
表6数据显示,本系统在检测和修复变量作用域错误方面表现最为突出,在异步回调丢失问题上也展现了较高的能力,但在原型链污染问题的处理上仍有较大提升空间。总体而言,系统在常见编程错误的识别和修复上具有显著优势,但在处理复杂和高级错误时,需进一步优化算法和修复建议的实用性。未来研究可着重提升系统对复杂问题的检测能力和修复建议的针对性,以进一步提高其整体性能。
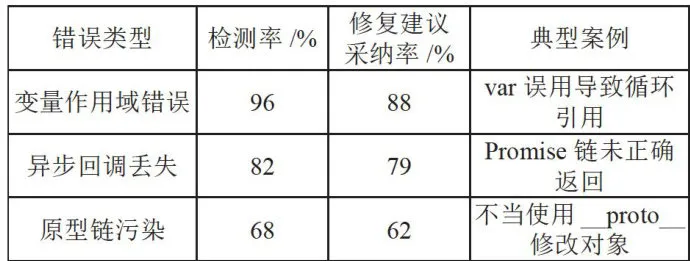 表6细粒度错误诊断表现
表6细粒度错误诊断表现4.2.4复杂场景处理能力
总体而言,系统在TypeScript类型推导和Nodejs事件循环调试任务中展现了较强的能力,但在Webpack配置错误诊断任务中仍需改进,如表7所示。未来研究可着重提升系统对复杂配置问题的处理能力,并通过增加支持来源和优化算法进一步提高整体性能。
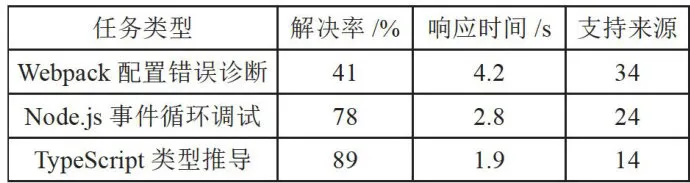 表7复杂场景处理能力表现
表7复杂场景处理能力表现5结论
本研究通过融合LangChain框架与DeepSeek-7B-R1大模型,构建了首个支持消费级硬件的本地化JavaScript教学辅助系统(JS-Tutor)。系统采用双引擎架构(规则预筛 + 大模型精调),结合动态AST解析与改进的RAG检索机制,显著提升了教学建议的准确率( 91 . 2 % )与响应速度(平均 1 . 2 s )。在NVIDIARTX3060硬件环境下,系统通过4bit量化与CUDA核心调度策略,显存占用降低 30 % ,单请求成本较GPT-4API减少 6 8 % 。实际部署验证,其可将学员问题解决效率提升 41 % ,教师人工干预减少
7 6 % ,尤其在异步编程、原型链等复杂概念教学中,学习者知识掌握速度提升 6 4 . 3 % (  )。
)。
当前系统对Webpack配置错误等复杂工程场景的支持仍需加强(解决率 41 % ),未来计划引入编译器中间表示(IR)增强复杂问题处理能力,并开发基于WASM的轻量化推理引擎以进一步降低资源消耗(目标成本 lt; S0 . 0 5 / 请求)。技术框架可扩展至Python、Java等语言教学场景,为构建高性价比、高可用性的智能教育平台提供了理论与实践范式。
参考文献:
[1]WANGZQ,LIUJ,ZHANGSK,etal.PoisonedLangChain:JailbreakLLMsbyLangChain[J/OL].arXiv:2406.18122[cs.CL].[2025-01-20].https://arxiv.org/html/2406.18122v1.
[2]HUEJ,SHENYL,WALLISP,etal.LoRA:Low-rank Adaptation ofLarge Language Models[J/OL].arXiv:2106.09685[cs.CL].[2025-01-21].https://arxiv.org/abs/2106.09685?context=cs.LG.
[3]LangChain Team.Vodafone Transforms Data OperationswithAIUsingLangChainandLangGraph[EB/OL].[2025-01-16].https://blog.langchain.dev/customers-vodafone/.
[4]LangChain Team.LangChain Documentation [EB/OL].[2024-05-01].https://python.langchain.com/docs/.
[5]ZHOUP,PUJARAJ,RENX,etal.Self-discover:LargeLanguage Models Self-compose Reasoning Structures[J/OL].arXiv:2402.03620 [cs.AI].[2025-01-16].https://arxiv.org/abs/2402.03620.
[6]SARTHIP,ABDULLAHS,TULIA,etal.RAPTOR:Recursive Abstractive Processing for Tree-organized Retrieval [ J /OL].arXiv:2401.18059 [cs.CL].[2025-01-03].https://arxiv.org/abs/2401.18059.
[7]LEWISP,PEREZE,PIKTUSA,etal.Retrievalaugmented Generation forKnowledge-intensive NLP Tasks[J/OL].arXiv:2005.11401[cs.CL].[2025-02-06].https://arxiv.org/abs/2005.11401.
[8]VIDIVELLIS,RAMACHANDRAN M,DHARUNBALAJI A.Efficiency-driven Custom ChatbotDevelopment:UnleashingLangChain,RAG,andPerformanceoptimizedLLMFusion[J].Computers,Materialsamp;Continua,2024,80(8):2423-2442.
[9]闵瑞,姜丹,王永刚.基于LangChain与大模型的医疗问答系统研究[J].计算机科学与应用,2025,15(2):33-43.
[10] LANGG,TRIANTORO T,SHARPJH.LargeLanguage Models asAI-powered Educational Assistants:Comparing GPT-4 and Gemini forWriting Teaching Cases[J].Journal ofInformation SystemsEducation,2024,35(3):390.
作者简介:刘安骞(1980一),男,汉族,辽宁大连人,教师,硕士,研究方向:人工智能、低代码平台、大数据分析、职业教育、机器人。