
摘 要:文章提出了一种基于实时反馈强化学习神经网络控制的船舶艏摇智能控制方法。该方法将神经网络的非线性建模和强化学习的自适应控制技术相结合,能够实现对船舶航行过程中舵角的精确控制。并将PID控制算法、模型预测控制算法和实时反馈强化学习神经网络控制算法进行对比分析,仿真实验结果表明,后者在控制效果和稳定性方面均优于前两种方法,能够有效地提高船舶航行过程中舵角的控制精度和鲁棒性。
关键词:实时反馈;强化学习;神经网络;船舶艏摇
中图分类号:TP39;TP18;U664.82 文献标识码:A 文章编号:2096-4706(2024)08-0083-06
0 引 言
船舶艏摇角是指船舶前部相对于静水面的摇晃角度,是船舶在海洋航行中常见的运动模态之一。艏摇角的大小和稳定性直接关系到船舶的航行性能和安全性,因此艏摇角控制一直是船舶运动控制的重要研究领域。传统的艏摇角控制方法主要基于PID控制算法或者模型预测控制算法,这些方法在控制效果和稳定性方面存在一定的局限性。一方面,PID控制算法需要根据船舶艏摇角的测量值计算控制量,而船舶运动传感器的数据受到环境因素和传感器自身误差的影响,容易产生误差和漂移,从而影响控制效果。另一方面,模型预测控制算法需要建立艏摇角动力学模型,但是艏摇角动力学模型的复杂性和不确定性使得模型预测控制算法的控制效果和稳定性受到限制。近年来,强化学习作为一种基于试错学习的智能控制方法,基于智能体与环境的交互学习不断试错和反馈,探索环境来获取奖励信号,从而得到最优的行为策略,从而提高控制系统的性能和鲁棒性[1]。基于实时反馈强化学习神经网络模型的船舶艏摇智能控制系统,能够实现对舵角的精确控制,提高船舶艏摇角的控制精度和鲁棒性,对船舶的稳定性和航行效率有至关重要的作用。
1 几种控制方法对比研究
1.1 传统的PID控制方法
目前,船舶艏摇控制主要采用传统的PID控制方法,但存在许多局限性,如模型参数难以确定、鲁棒性不够、适应性不足等,只能根据已知的船舶动态模型进行控制,不能根据实时反馈信息及时调整控制策略,因此对于系统的鲁棒性、稳定性以及适应性较差,特别是对于存在未知干扰或模型不准确的情况下,PID控制的性能会急剧下降[2]。
1.2 强化学习方法
为了解决PID控制方法存在的问题,近年来,越来越多的研究者开始探索基于机器学习的控制方法。其中,强化学习(RL)方法因其在不确定环境下自适应学习的能力,成为船舶自动化控制领域的研究热点之一。强化学习通过不断试错的方式,不断调整船舶控制策略,最大限度地发挥预设的奖励功能。相比传统的控制方法,强化学习的适应性和鲁棒性更强。
强化学习的基本框架可以概括为四个主要元素:状态(state)、动作(action)、奖励(reward)和策略(policy)。状态表示环境现在的状态,动作表示智能体可选的行动,奖励表示智能体的行动质量,策略是智能体根据其经验采取行动的规则[3]。其目的是在不确定的环境中学习行为策略,以最大化预期的累积回报。在强化学习中,智能体(即学习算法)通过与环境交互来学习,从而获得有关其当前状态和可用动作的信息。通过试错学习来改善其决策策略,通过策略学习来学习如何在给定的状态下选择动作。强化学习算法可以分为价值基础算法和策略基础算法。价值基础算法的目标是学习如何评估状态和动作的质量,例如Q-learning算法和SARSA算法。策略基础算法的目标是直接学习最优策略,例如Policy Gradient算法和Actor-Critic算法。近年来,深度强化学习结合了深度学习和强化学习的优势,使模型泛化能力更高,性能更好[4]。
1.3 实时反馈深度强化学习方法
基于实时反馈深度强化学习神经网络模型的船舶艏摇角控制方法,利用深度强化学习的思想,通过学习环境状态和动作的映射关系,得到优化的控制策略。具体来说,本文首先构建了船舶艏摇角控制的状态空间,包括船舶的加速度、角速度、角度等状态信息,并使用这些状态信息进行强化学习网络的训练[5]。同时,还考虑了船舶存在的未知干扰因素,对于未知干扰的影响,使用了一种基于模型预测控制(MPC)的方法,通过预测未来状态来优化控制策略,提高系统的鲁棒性。
2 实时反馈深度强化学习神经网络模型介绍
2.1 基本原理
实时反馈深度强化学习神经网络模型是强化学习在实时控制问题上的应用,结合了实时反馈和神经网络的特点。其基本原理是通过学习环境状态和采取行动的反馈,通过调整模型参数实现对行动的优化[6]。
具体来说,状态表示环境的特征,动作是智能体对环境的反应,奖励是智能体行动的结果,策略则是智能体在不同状态下采取的行动规则。模型通过不断地尝试,学会了在不同状态下最大限度地发挥奖励的作用,从而将最优的动作选择出来。
2.2 算法设计
基于值函数和策略函数进行优化。其中,值函数用于估计智能体在当前状态下采取某一行动的长期收益,策略函数则用于指导智能体在不同状态下的行动选择。在实时反馈深度强化学习神经网络模型中,值函数和策略函数通常使用神经网络进行建模。
在训练过程中,智能体通过与环境的交互不断优化神经网络的参数,以学习到最优的值函数和策略函数。每一步都需要计算当前状态下的最优行动,根据执行的行动和获得的奖励来更新神经网络的参数,从而实现模型的优化和学习。实时反馈深度强化学习神经网络模型的优点是能够处理实时控制问题,且具有很好的通用性和可扩展性。
3 实验评价指标和方法
3.1 评价指标
为了评价所提出的实时反馈深度强化学习神经网络模型的控制效果,本文采用了以下七个评价指标:
1)训练情况:训练过程中的训练曲线,可以了解模型在不同迭代次数下的表现,并进行调整和优化。
2)模型性能:通过评估模型的预测结果与真实值之间的差距,计算方式为预测值与真实值之差的平方和的平均值,我们主要采用实时的输出值与目标值的差距和误差柱状图对模型性能进行评估。
3)模型误差直方(EH):模型对于预测结果与训练数据和测试数据真实结果之间的区别。误差可以是正值、负值或者零,正值表示模型偏高估计,负值表示模型偏低估计,而零表示模型的预测完全正确。可以提现出模型的预测精度。
4)误差自相关性(EA):在时间序列分析中,同一序列内相邻时间点的误差值之间存在相关性的现象。也就是说,前一个时间点的误差值与后一个时间点的误差值之间存在一定的相关性。
误差自相关性可能会导致模型的预测效果不佳,因为如果误差具有一定的自相关性,那么模型预测出的误差也会受到之前误差的影响,从而可能会导致模型的预测结果出现较大的偏差。
5)最大偏差角度(MAD):艏向角在规定时间内的最大偏差值,衡量了模型对于控制目标的精度和稳定性。
6)稳态最大偏差角度(SSD):当模型达到稳定状态时,艏向角与目标角度之间的偏差值,衡量了模型的稳态性能。
7)调整时间(TAT):模型从初始状态到达稳定状态的时间是用来衡量模型的反应速度。
3.2 实验方法
3.2.1 模型设计思路
实时反馈强化学习神经网络模型,此模型可以做到实时反馈(5 s)数据,每5 ms采样一次,采样对象为艏摇角,每秒钟采样200次,5 s采样的总数据集为1 000次,将5 s作为一个固定时间间隔。如图1所示,我们假设将第一个时间间隔点设为t1,第二个时间间隔点为t2,第三个时间间隔点为t3,第四个时间间隔点为t4,t1到t2时间间隔为T1,t2到t3时间间隔为T2,t3到t4时间间隔为T3,T1 = T2 = T3 = 5 S。
船舶正常航行过程中,在t2时刻,将T1内的艏摇角、舵角实际值导入到Reinforcement Learning Designer模型中进行训练,模型将在T2时间内训练完成并输出控制信号,来预测T3时间内的艏摇角、舵角数据,以达到预测控制。如图1所示,在T3内,将T3实际艏摇角值与T3预测艏摇角值进行对比拟合,如若实际值与预测值拟合结果在设定范围内,则证明模型优良,继续循环此流程来预测T4、T5时间段内的数据;若T3的艏摇角实际值与艏摇角预测值拟合结果不在设定范围内,则将拟合的差值反馈到模型来优化下一次的训练。每次训练的数据集总量为1 000。以此往复循环来预测下个时间间隔内的数据,从而实现对舵的预测控制。
3.2.2 模型搭建和训练过程
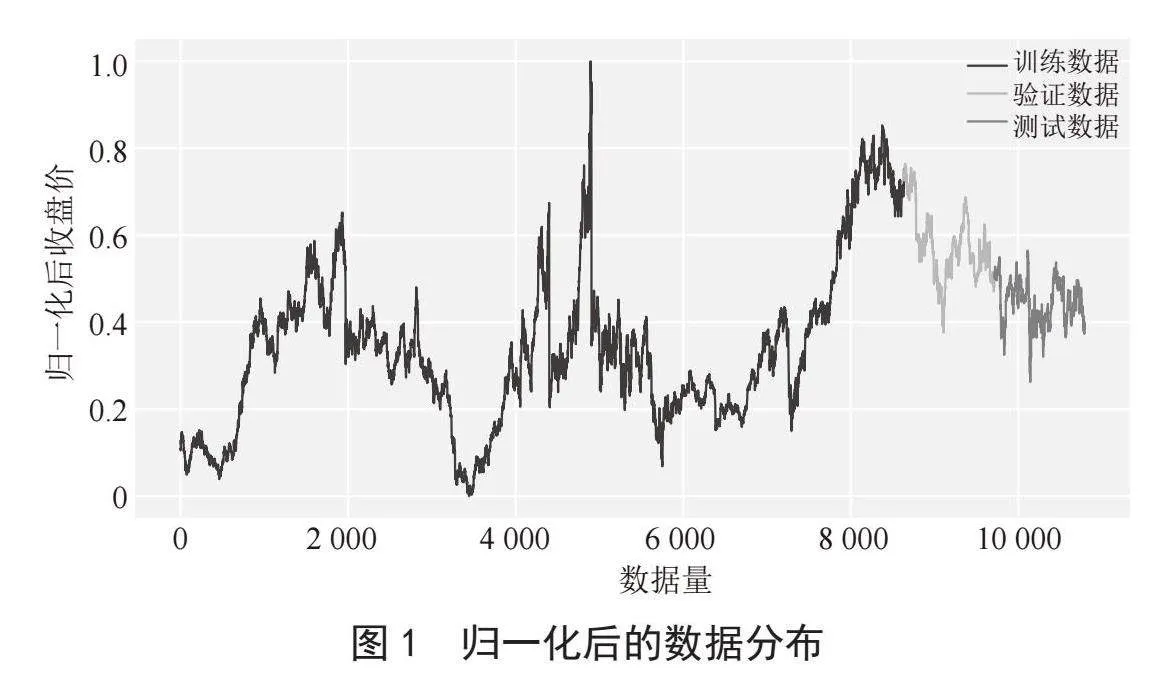
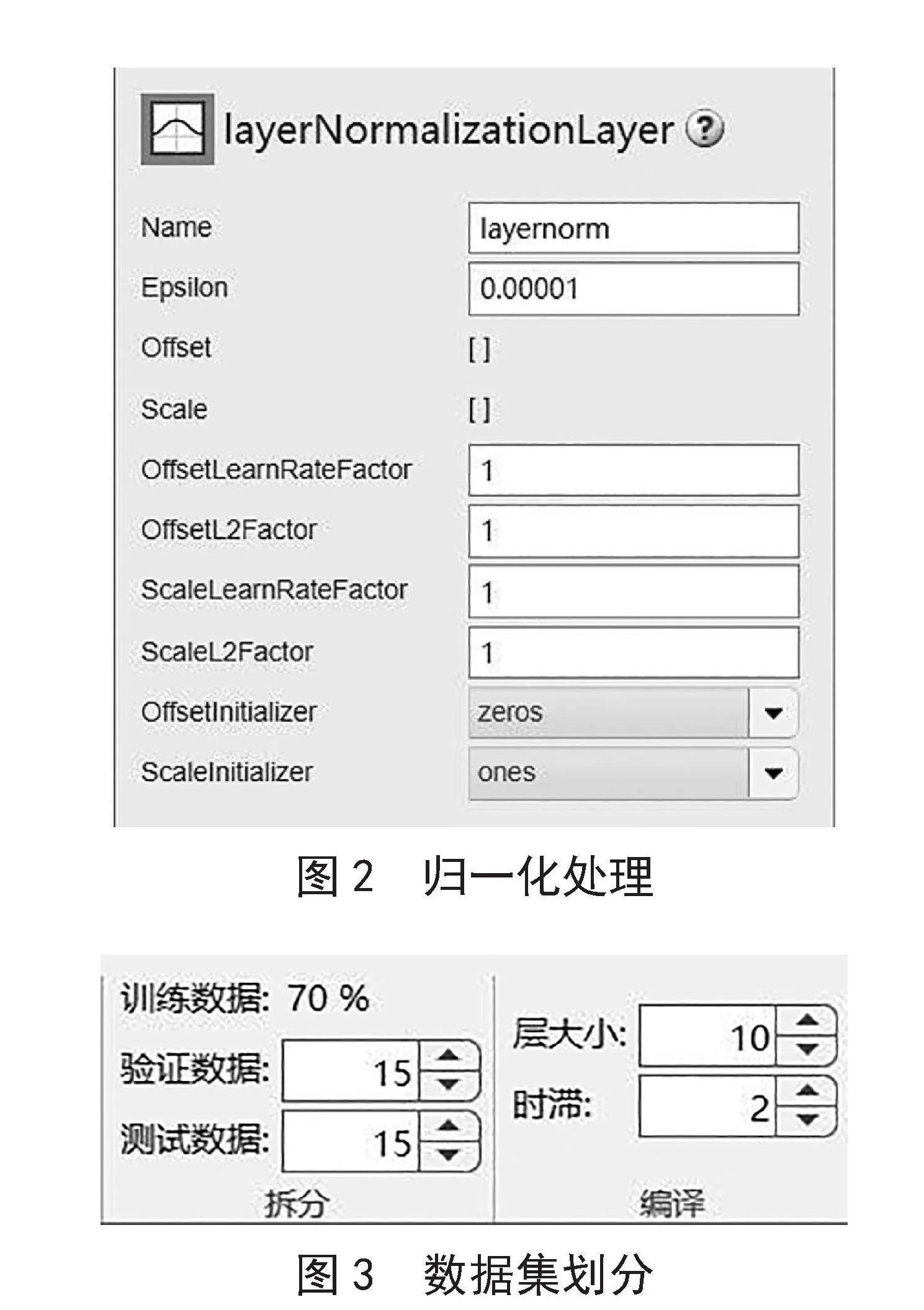
1)数据预处理。我们首先需要对收集的过往的艏摇角和舵角数据集进行预处理。采用数据滤波和归一化方法,以消除噪声并使其适合于神经网络的输入。同时,将训练数据划分为训练集和测试集。首先用Layer Normalization(LN)对数据进行归一化处理,如图2所示。因为LN相比于BN(Batch Normalization),LN不依赖于批次大小,并且可以处理变长序列数据。然后将数据集按70%、15%、15%的比例依次划分为训练集、测试集和验证集,如图3所示。
2)搭建时间序列神经网络模型。使用长短期记忆网络(LSTM)时间序列神经网络来学习数据中的时间依赖关系和非线性性。对于船舶的艏摇角和舵角数据集,采用两个独立的时间序列神经网络来分别学习它们的时间依赖性和非线性性。每个时间序列神经网络都可以处理输入序列,并输出相应的预测值。
利用MATLAB搭建一个LSTM时间序列神经网络的基础模型,代码如下:
% 加载数据集
data = readtable(dataset.csv);
inputs = table2array(data(:, 2:3)); % 过往艏摇角和舵角值作为输入
targets = table2array(data(:, 4:5)); % 预测的艏摇角和舵角值作为输出
% 将数据集分为训练集和验证集
numSamples = size(inputs, 2);
numTraining = round(numSamples * 0.8); % 80%用于训练,20%用于验证
indices = randperm(numSamples);
trainingIndices = indices(1:numTraining);
validationIndices = indices(numTraining+1:end);
trainingInputs = inputs(:, trainingIndices);
trainingTargets = targets(:, trainingIndices);
validationInputs = inputs(:, validationIndices);
validationTargets = targets(:, validationIndices);
% 定义LSTM网络架构
numFeatures = size(inputs, 1); % 输入特征数(艏摇角和舵角)
numResponses = size(targets, 1); % 输出响应数(艏摇角和舵角)
numHiddenUnits = 200; % LSTM隐含层单元数
layers = [
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits, OutputMode, sequence)
dropoutLayer(0.2)
fullyConnectedLayer(numResponses)
regressionLayer
];
% 设置训练选项
options = trainingOptions(adam, ...
MaxEpochs, 100, ...
MiniBatchSize, 64, ...
ValidationData, {validationInputs, validationTargets}, ...
ValidationFrequency, 10, ...
Shuffle, every-epoch, ...
Plots, training-progress);
% 训练LSTM网络
net = trainNetwork(trainingInputs, trainingTargets, layers, options);
% 测试LSTM网络
testInputs = inputs(:, validationIndices);
testTargets = targets(:, validationIndices);
predictions = predict(net, testInputs);
% 绘制结果图像
figure
subplot(2,1,1)
plot(testTargets(1,:))
hold on
plot(predictions(1,:))
title(艏摇角)
legend(实际值, 预测值)
subplot(2,1,2)
plot(testTargets(2,:))
hold on
plot(predictions(2,:))
title(舵角)
legend(实际值, 预测值)
3)搭建强化学习模型。采用策略梯度强化学习模型,以最大化某些奖励信号并达到某个目标。接收来自时间序列神经网络的预测值作为输入,并输出相应的行动。在这个模型中,将艏摇角值作为输入;舵角值作为行动;当前的艏摇角值与模型预测的艏摇角值之间的误差作为奖励,当误差较小或者模型性能较好时,可以给予正的奖励;当误差较大或者模型性能较差时,可以给予负的奖励,以期望达到目标艏摇角作为奖励信号;采用Reinforce深度强化学习算法作为策略。采用Q值函数可以通过神经网络来建模,以当前状态和行动作为输入,预测未来的奖励期望值作为输出。
训练过程可以分为两个阶段:探索阶段和利用阶段。在探索阶段,模型随机选择行动,以探索更多的状态空间。在利用阶段,模型根据策略选择最优行动。可以通过使用经验回放和目标网络等技术来提高训练效率和稳定性。MATLAB代码如下:
% 定义环境
env = rlPredefinedEnv(\"ShipEnvironment\");
% 定义状态空间
obsInfo = getObservationInfo(env);
% 定义动作空间
actInfo = getActionInfo(env);
% 定义代理网络
numHiddenUnits = 64;
statePath = [
imageInputLayer([obsInfo.Dimension(1) obsInfo.Dimension(2) 1],Normalization,none,Name,observation)
fullyConnectedLayer(numHiddenUnits,Name,fc1)
reluLayer(Name,relu1)
fullyConnectedLayer(numHiddenUnits,Name,fc2)
reluLayer(Name,relu2)
fullyConnectedLayer(actInfo.Dimension(1),Name,
fc3)];
actorNet = layerGraph(statePath);
% 定义代理
agentOpts = rlACAgentOptions(...
NumStepsToLookAhead,64, ...
EntropyLossWeight,0.1, ...
GradientThreshold,1);
agent = rlACAgent(actorNet,obsInfo,actInfo,agentOpts);
% 定义训练选项
trainOpts = rlTrainingOptions(...
MaxEpisodes,1000, ...
MaxStepsPerEpisode,200, ...
Verbose,1, ...
Plots,training-progress, ...
StopTrainingCriteria,AverageReward, ...
StopTrainingValue,100, ...
ScoreAveragingWindowLength,10);
% 训练代理
trainStats = train(agent,env,trainOpts);
% 使用训练好的代理进行预测
obs = reset(env);
for i = 1:200
action = getAction(agent,obs);
[obs,reward,done] = step(env,action);
if done
break
end
end
3.2.3 训练结果
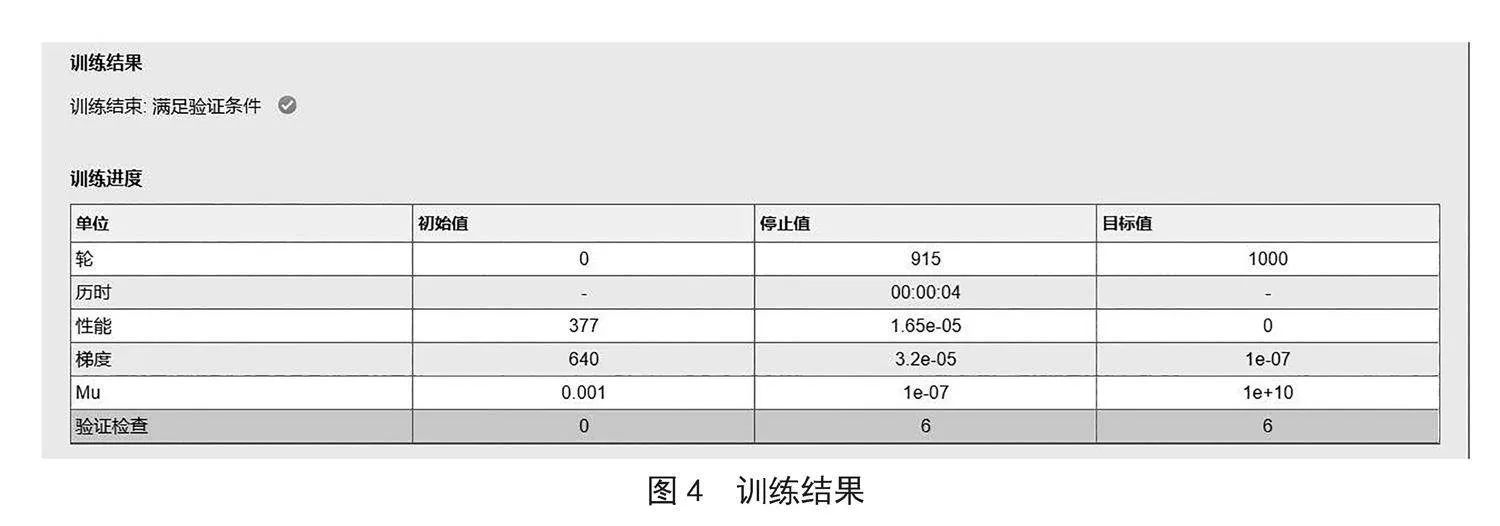
在训练过程中,使用的优化器是Adam优化器,学习率为0.001。本文采用的是分批次进行训练,每批次数据量为1 000,共训练1 000次,每隔100次训练,测试一次性能,并记录最优性能所对应的训练次数和参数。具体实验结果如图4所示。
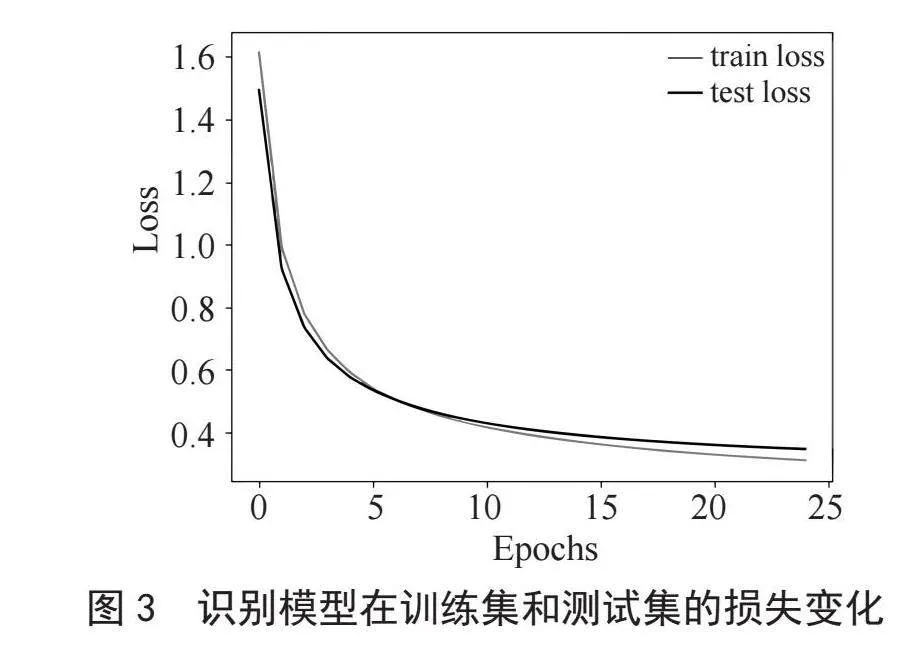
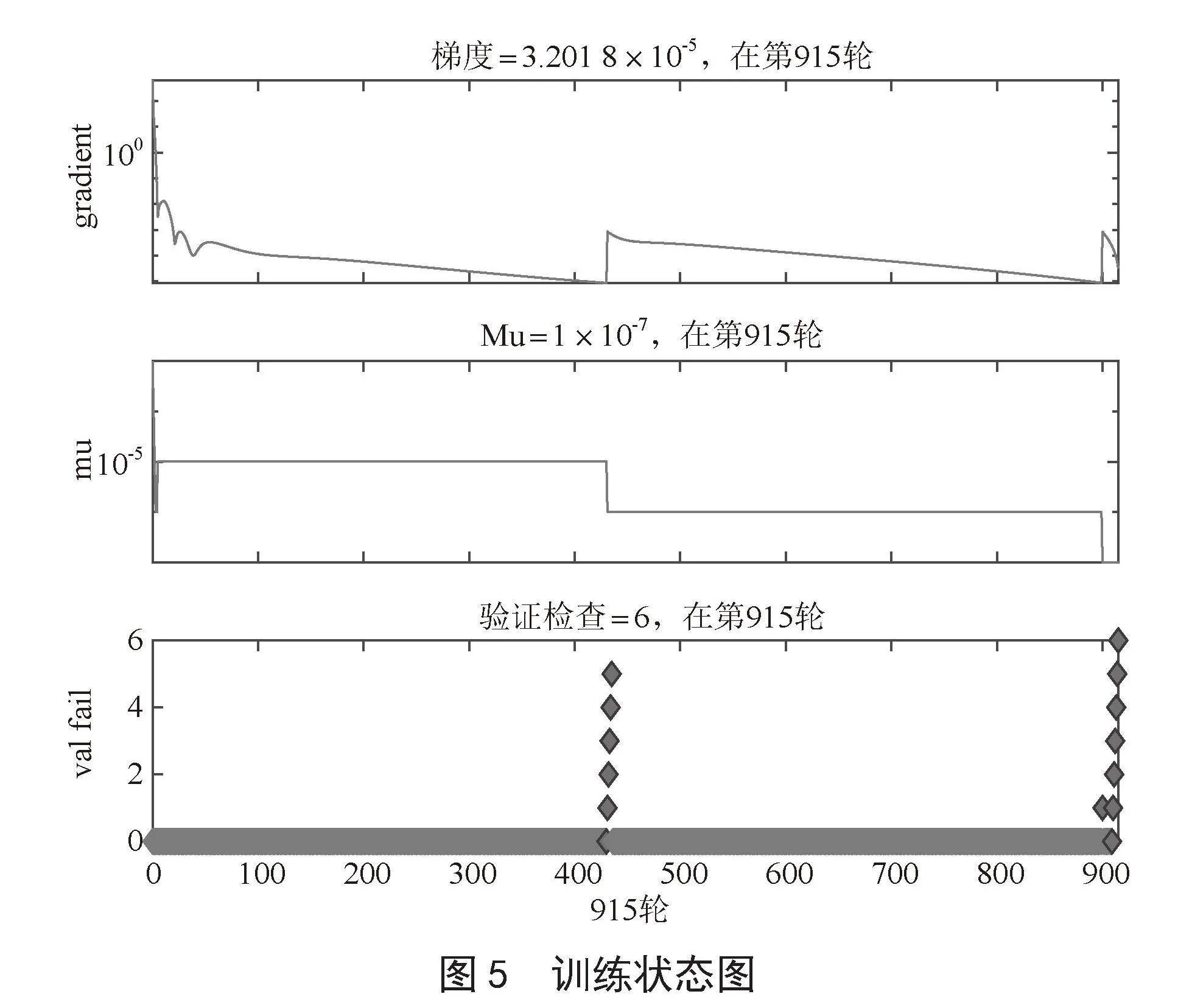
如图5所示,训练结果符合预期各项指标,均在1 000次训练内达到稳定效果,训练时间均为5秒以内,符合设定的时间间隔。性能、梯度、误差精度均在预期误差内,模型训练结果优良。
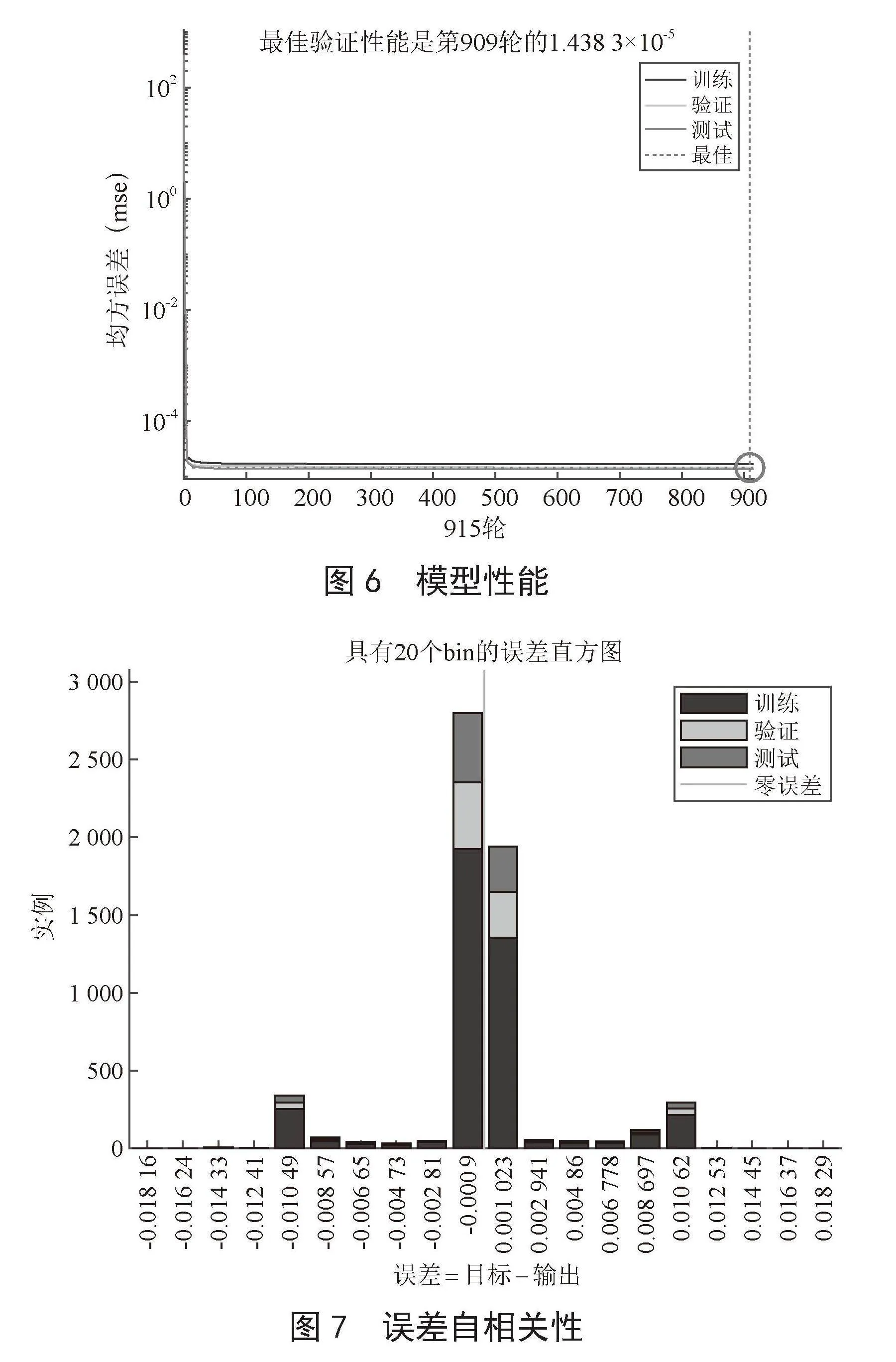
如图6所示,模型在25轮前均方误差有骤减趋势,说明模型控制效率高;在100轮时,均方误差趋于稳定,直到915轮输出最终的艏摇角预测值和舵角控制信号,证明模型稳定性、安全性高。
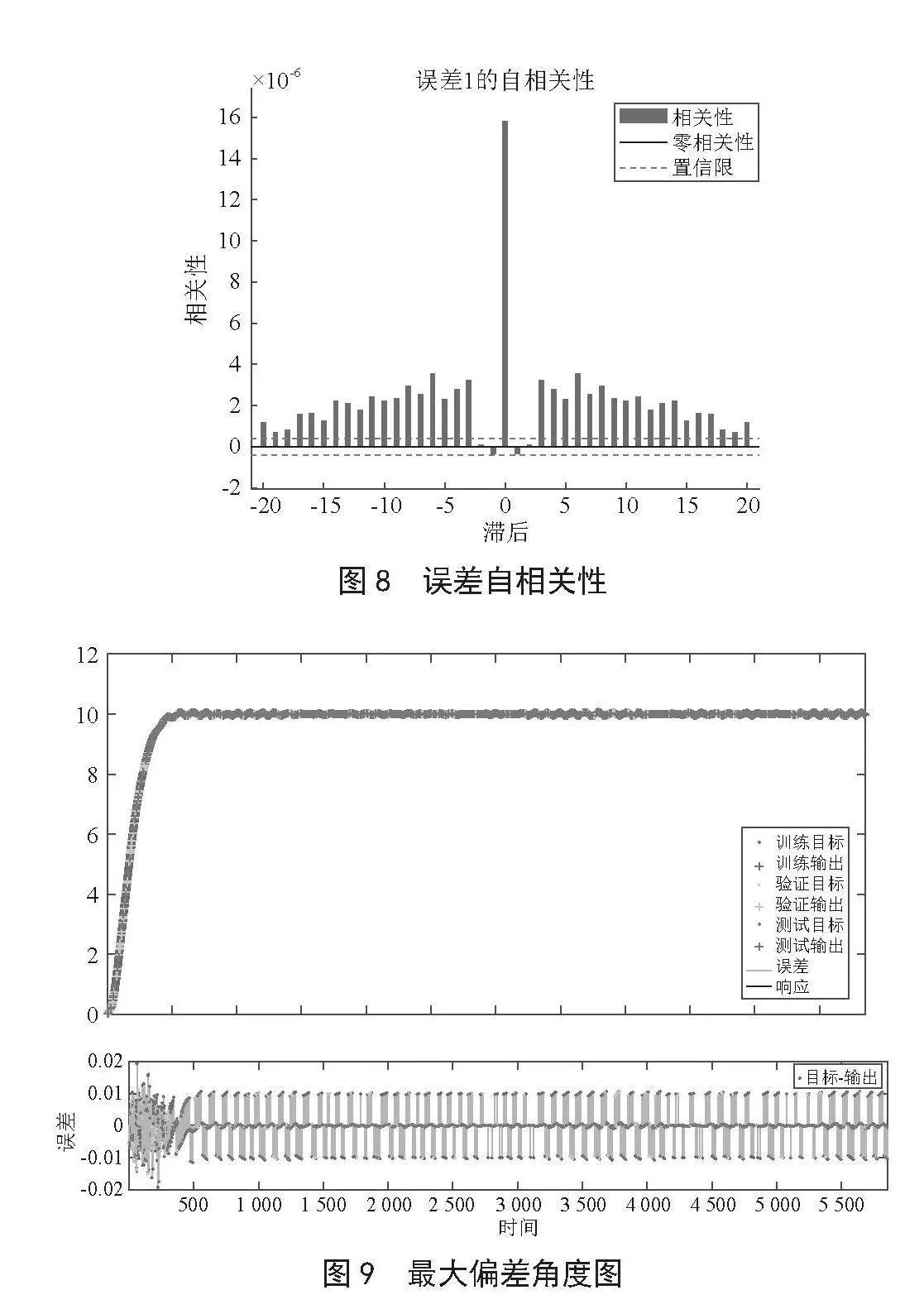
如图7、图8所示,实时反馈强化学习神经网络结果显示出了良好的误差分布直方图和自相关性效果。
3.3 结论分析
在实验中,比较了实时反馈强化学习神经网络模型和传统的PID控制方法在上述指标上的表现。为了使实验结果更加客观和准确,本文采用了10组不同的实验数据,并将其平均化以得出最终结果。同时,每组实验数据重复实验5次,确保结果可靠。为了可以更好的体现模型的控制效果,我们将船舶原始航向角设为0°,我们将航向角设置为10°,来观察实时控制效果,具体实验数据如图9所示。
4 结 论
本文基于实时反馈深度强化学习神经网络模型的船舶艏摇角控制方法,在MATLAB/Simulink仿真环境下进行了大量实验验证。通过实验应用的分析,模型控制的艏摇角最大偏差角为1.427 7,在慢慢训练过程中逐渐趋于稳态,最大偏差角符合预期值。也证明了该方法的实际应用效果。在船舶智能操纵系统中使用本方法,可以提高船舶操纵员的工作效率和安全性。实验结果表明,所提出的方法能够适应不同的船舶动态模型和未知干扰。因此,对于提高船舶自动化控制水平、提高船舶安全性和经济性具有一定的参考价值。
参考文献:
[1] 理查德·桑顿,安德鲁·巴图.强化学习:第2版 [M].俞凯,等译.北京:电子工业出版社,2019.
[2] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Human-Level Control Through Deep Reinforcement Learning [J].Nature,2015,518(7540):529-533.
[3] SILVER D,HUANG A,MADDISON C J,et al. Mastering the Game of Go with Deep Neural Networks and Tree Search [J].Nature,2016,529(7587):484-489.
[4] MNIH V,BADIA A P,MIRZA M,et al. Asynchronous Methods for Deep Reinforcement Learning [C]//Proceedings of the 33rd International Conference on International Conference on Machine Learning.New York:JMLR.org,2016:1928-1937.
[5] 朱俊宏,林泽宇,潘柏群,等.基于深度强化学习的火车进路优化方法 [J].自动化学报,2021,47(6):1359-1368.
[6] 刘伟,赵立飞,王华锋,等.基于DRL和LSTM的智能家居能耗预测模型研究 [J].计算机与数字工程,2021,49(7):1251-1257.
作者简介:宋伟伟(1981.05—),女,汉族,山东荣成人,系副主任,教授,硕士研究生,研究方向:船舶运动控制;徐跃宾(2002.10—),男,汉族,山东淄博人,本科在读,研究方向:船舶电子电气技术;段学静(1984.07—),女,汉族,河北保定人,实验管理员,实验师,本科,研究方向:电子技术;崔英明(1985.09—),男,汉族,山东荣成人,教师,工程师,本科,研究方向:船舶工程技术;巩方超(1989.06—),男,汉族,山东枣庄人,讲师,硕士,研究方向:电力系统及其自动化、机器视觉。
收稿日期:2023-10-04
基金项目:山东省船舶控制工程与智能系统工程技术研究中心科研专项(SSCC-2021-0006)
DOI:10.19850/j.cnki.2096-4706.2024.08.019
Research on Intelligent Control of Ship Yaw Based on Real-time Feedback Reinforcement Learning Neural Network
SONG Weiwei1,2, XU Yuebin2, DUAN Xuejing1,2, GONG Fangchao1,2, CUI Yingming2
(1.Research Center of Shandong Province Ship Control Engineering and Intelligent System Engineering and Technology, Weihai 264300, China; 2.Weihai Ocean Vocational College, Weihai 264300, China)
Abstract: This paper proposes an intelligent control method for ship yaw based on real-time feedback reinforcement learning neural network control. This method combines nonlinear modeling of neural networks with adaptive control technology of reinforcement learning to achieve precise control of rudder angle during ship navigation. And the PID control algorithm, model prediction control algorithm, and real-time feedback reinforcement learning neural network control algorithm are compared and analyzed. The simulation experiment results show that the latter is superior to the previous two methods in control effectiveness and stability, and could effectively improve the control accuracy and robustness of the rudder angle during ship navigation.
Keywords: real-time feedback; reinforcement learning; neural network; ship yaw