
摘" 要:后门攻击对人工智能的应用构成潜在威胁。基于遗忘的鲁棒训练方法可通过隔离后门样本的子集并遗忘该子集,实现在不受信的数据集上训练无后门的模型。然而,错误隔离并遗忘干净样本会导致模型在干净数据上的性能受到损害。为了减少对干净样本的错误隔离,进而保护模型在干净数据上的性能,提出基于样本损失值变化统一性的后门样本隔离方案。后门样本训练过程中损失值的变化较大且较为统一,在隔离的潜在后门样本集中损失值变化统一性较低的样本可以被移除。实验结果表明,应用该方案能够减少对干净样本的错误隔离,在不影响后门防御效果的基础上保护了模型在干净数据上的性能。
关键词:人工智能安全;后门防御;鲁棒训练;后门样本隔离;神经网络模型
中图分类号:TP18" 文献标识码:A" 文章编号:2096-4706(2024)11-0044-05
Backdoor Sample Isolation Based on the Uniformity of Samples Loss Value Changes
ZHANG Jiahui
(School of Cyber Engineering, Xidian University, Xian" 710126, China)
Abstract: Backdoor attacks pose a potential threat to applying AI applications. Unlearning-based robust training methods achieve training models with no backdoor on untrusted datasets by isolating a subset of backdoor samples and unlearning it. However, incorrectly isolating and unlearning clean samples can lead to performance degradation of the model on clean data. In order to reduce 1 isolation of clean samples thus protecting model performance on clean data, a backdoor sample isolation scheme based on the uniformity of samples loss value changes is proposed. During the training process, samples have large and uniform changes in loss value, and samples with low uniformity of loss value changes in the isolated and potential backdoor samples set are removed. Experimental results indicate that the application of the scheme benefits reducing the 1 isolation of clean samples, and protects the models performance on clean data without compromising on defending against backdoor attacks.
Keywords: Artificial Intelligence security; backdoor defense; robust training; backdoor sample isolation; neural network model
0" 引" 言
人工智能相关的应用在人们的生活中带来了极大的便利。为了使人工智能模型能够迎合需求的发展并输出恰当的结果,服务提供商需要频繁收集数据用于训练新模型或重训练现有模型。这为潜在的攻击者提供了机会:后门攻击者试图在模型的训练数据集中注入后门样本,从而在模型中构建后门[1,2],令模型在接收附带特殊标记的输入时输出指定结果。
现有的鲁棒训练[3,4]试图在训练过程中阻止后门的构建。具体来说,基于遗忘的鲁棒训练在训练过程中隔离后门样本的一个子集并应用模型遗忘技术遗忘该子集,从而实现在不受信的数据集上训练不含后门的模型。然而,在不受信的数据集上隔离出后门样本的过程中存在错误隔离干净样本的可能,而遗忘干净样本会导致模型性能下降。
本文基于对样本损失值变化量的观察,结合对模型结构的分析,认为在模型训练过程中后门样本的损失值变化有较强的统一性。模型中存在与后门触发关联紧密的神经元,随着这类神经元连接上权重的更新,大部分后门样本的损失值会具有不完全相等但大致统一的变化,即样本损失值变化统一性较强。在现有后门样本隔离方案中基于损失值变化统一性分析对隔离方案进行调整可以减少对干净样本的错误隔离,进而在鲁棒训练中保护模型的性能。
1" 技术介绍
1.1" 神经网络模型
神经网络模型包含多个神经元,神经元接收输入并通过激活函数输出。多个神经元构成了神经网络的输入层、隐藏层和输出层。应用于模型训练或访问的单个数据可以被称为样本。神经网络模型的训练过程最小化一个损失函数,损失函数反映了模型输出和样本实际标签的差距。在训练过程中,神经元之间连接的权重得到调整,影响了神经元之间的激活情况,最终使得模型的输出得到更新。模型的训练优化目标可以表示为:
(1)
其中,fθ (x)为模型对输入x的输出,y为该样本的实际标签;l (·)为损失,如交叉熵损失; 为训练过程最小化的目标,即在数据集D上最小化其中样本的平均损失。
在模型工作时,模型根据任务输出一个经过归一化处理的向量,其中向量的维度对应输出结果的种类。每个维度上的值表示模型认为应当输出该结果的概率。模型选择具有最高概率的类别作为输出。
1.2" 针对智能模型的后门攻击
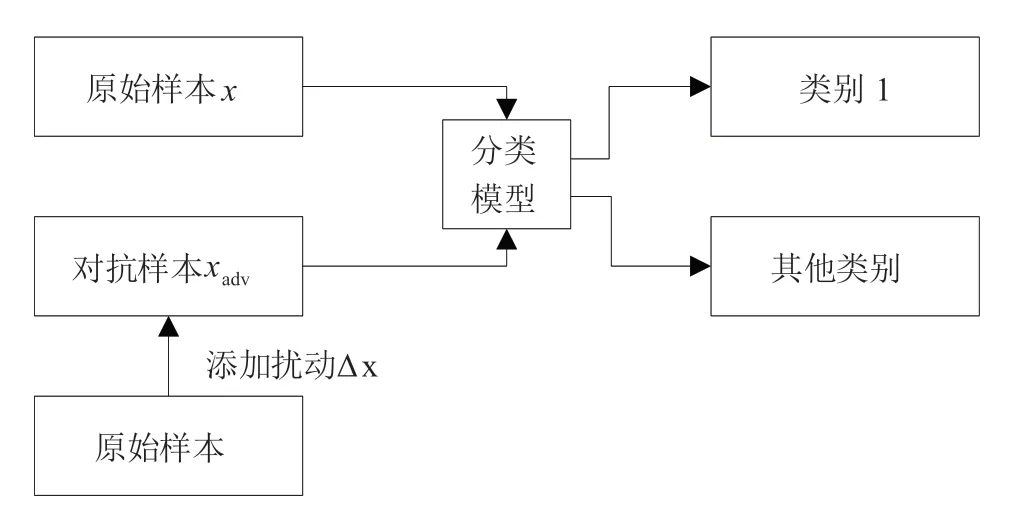
Gu等[1]首先提出针对模型的后门攻击,其向模型的训练数据集中注入后门样本,使得模型在训练过程中学习到由攻击者设计的特殊识别模式。受攻击的模型对普通数据仍然输出正常的结果,但对附加了特殊标记的数据则会输出由攻击者指定的结果。现有的大多数后门攻击旨在实现不需修改标签的后门数据[5]、优化标识的隐蔽性[6]或增强攻击效果,但仍然遵循了通过注入后门样本构建特殊识别模式的攻击框架,如图1所示。
后门攻击的优化目标可以表示为:
(2)
其中,Dc和Db分别为训练过程使用的干净数据集和后门数据集,yt为由攻击者指定的后门样本标签。
1.3" 后门防御
现有的大部分后门防御针对已经遭受攻击的模型实现后门检测与后门消除中至少一项功能。后门检测检查训练数据集或检验模型的输出以测定模型是否已经被植入后门;后门消除通过剪枝[7]或遗忘[8]等手段改变模型内部参数或结构,从而抹除后门。鲁棒训练试图直接在训练过程中抵御后门攻击,在训练正常任务的同时阻止后门的构建,实现在不受信的数据集上训练出干净模型。
1.3.1" 剪枝防御
剪枝防御深入模型结构,观察神经元的激活情况。Liu等[7]提出,部分神经元在输入后门样本(标记)时激活,而输入干净样本时通常休眠。可以说,模型在训练过程中形成了与后门强关联的神经元。因此,可以通过检查神经元触发特性并修剪特定神经元的方式阻断后门的触发。
1.3.2" 基于模型遗忘的鲁棒训练
Wu等[9]提出,后门样本相对于干净样本更易于学习,因此在训练过程中其损失值的下降更为剧烈。基于相似的观察结论,Li等[3]提出了一种在训练过程中根据损失值隔离潜在后门样本并遗忘的鲁棒训练方法ABL(Anti-Backdoor Learning)。具体来讲,在训练过程中后门样本的损失值l ( fθ (x), yt)相比于干净样本通常更低。因此,可以将一部分损失值低的样本视为后门样本并将之隔离,再通过模型遗忘技术[8]阻止后门的构建。
基于模型遗忘技术的鲁棒训练的优化目标可以表示为:
(3)
在隔离后门样本集Db时,为了扩大后门样本和干净样本的损失值差距,Li等[3]在执行隔离之前的训练阶段改用一种名为局部梯度上升LGA(Local Gradient Ascent)的优化目标:
(4)
其中,sign(·)为符号函数。该方法利用了后门样本易于学习的特性:由于后门样本易于学习,它们的损失值很低,在其损失值低于γ并置为负后,其绝对值较小;而干净样本学习缓慢,模型优化过程中其损失值偏大,在其低于γ并置为负后损失值绝对值较大。当优化过程中损失值为负时,优化后的模型对该样本的性能会下降。由于后门样本损失值置为负后绝对值仍然较小,后门样本仍然能被较好地学习到,而干净样本则不然,从而实现干净样本和后门样本之间损失值差距的扩大。
2" 提出的后门样本的隔离方法
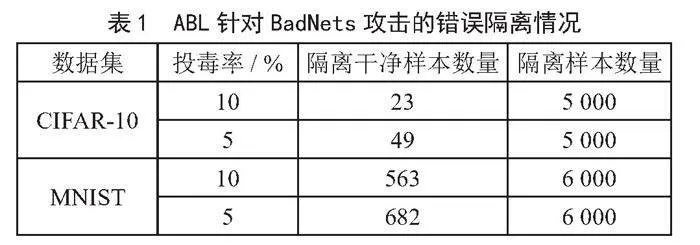
现有的基于模型遗忘的鲁棒训练方法在隔离过程中存在错误隔离干净样本的风险,会导致模型在干净数据上的性能受损。在CIFAR-10数据集上应用基于遗忘的鲁棒训练方法时,若在包含5 000个样本的隔离样本集中将500个后门样本替换为干净样本,遗忘后模型在干净数据上的准确率从89.27%降低到了85.61%。
如表1所示,即便Li等[3]在其设计的鲁棒训练方法ABL中通过LGA扩大了干净样本和后门样本的损失差距,其基于样本损失值的隔离方法中仍然错误隔离了一部分获得了较低损失值的干净样本。针对这一问题,基于对样本损失值变化量的分析,一种基于样本损失值变化统一性的后门样本隔离方法被提出。
2.1" 针对样本损失值变化量的分析
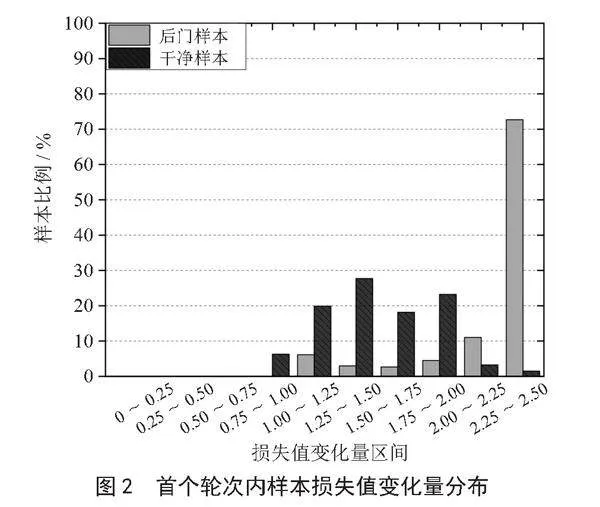
在CIFAR-10数据集上应用LGA时首个训练轮次中样本损失值变化量的分布如图2所示,其中后门样本的损失值变化量倾向于集中在一个值域内,而干净样本的损失值变化量的分布较为分散。在后门攻击中,攻击的目标是快速构建后门样本与目标标签的稳健识别关系,在训练过程表现为后门样本的损失值更低且变化更为剧烈[9],即在训练的早期阶段中后门样本的损失值变化量集中于一个高值。
在训练的晚期阶段,模型决策趋于稳定,后门样本和干净样本的损失值变化量都普遍较小,即样本的损失值变化量大多分布在低值。但后门样本相对干净样本的损失值变化量分布仍然更为集中。
后门样本在训练过程中损失值变化量的特征可以总结为:在模型训练过程中的单个训练轮次内,后门样本损失值变化量的分布更为集中,而干净样本的损失值分布相对分散,称之为后门样本损失值变化量表现出较强的统一性。
2.2" 对样本损失值变化统一性的理解
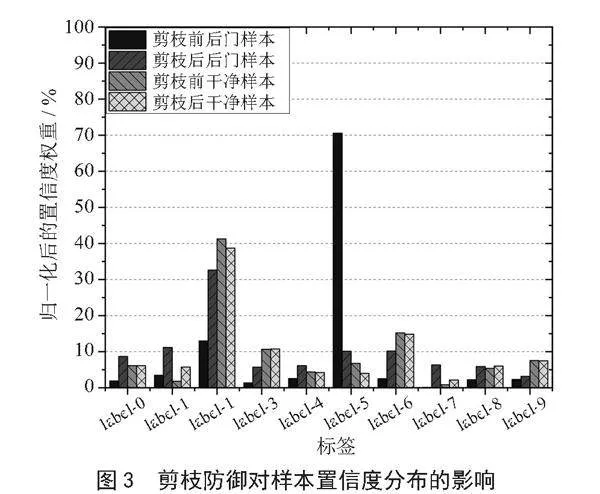
应用剪枝防御[7]时,模型在剪枝前和剪枝后对同一组样本输出的平均置信度分布如图3所示,其中,选择了具有相同真实标签label-2的30个干净样本与30个后门样本,后门样本的目标标签都是label-5。剪枝后,后门样本的置信度分布会贴近于干净样本的分布;然而,剪枝消去与后门强关联的神经元也会导致模型在干净数据上的置信度出现小幅变化。从模型结构的角度分析,认为这一现象的产生是因为与后门强关联的神经元同目标标签对应的输出层神经元之间的连接权重较大,而与输出层其他神经元之间也存在连接但连接权重小。
结合上述结论,后门样本损失值变化表现出统一性更强的原因可以解释为:在模型训练过程中存在激活情况与后门强关联的神经元,模型优化过程可以对这些特殊神经元的连接权重进行大幅度的修改,从而使得后门样本的损失值出现较大且统一的变化,而这些神经元的权重的变化对干净样本损失值的影响较小。其他与后门关联不强的神经元的连接权重修改使得干净样本正常被学习,并使得后门样本之间的损失值变化仍然存在些许差距。
根据上述分析,认为可以基于样本损失值变化统一性隔离后门样本,即样本损失值变化量最为集中的一些样本更可能是后门样本。值得一提的是,样本损失值变化量的统一性不仅仅可以在单个训练轮次中评估,在某一训练轮次中损失值变化量集中的后门样本在其他训练轮次中的损失值变化量分布仍然较为集中。因此,可以在多个训练轮次观察样本损失值变化量,并隔离后门样本。
2.3" 后门样本的隔离策略
后门样本相比干净样本在损失值变化上表现出更强的统一性,基于样本损失值变化统一性的后门样本隔离策略设计如下:
1)在模型训练过程中,计算并保存样本的损失值。
2)计算样本在一个或多个轮次的损失值变化量。
3)在每个轮次中对样本分组。以0为起点,以m为步长对样本根据损失值变化量分组,在该轮次内同一分组中的样本两两之间的损失值变化量之差小于m。
4)定义指定样本为中心判定统一性的方法。基于样本x,以k为最大步长检验其他样本,若其他样本在各个轮次的损失值变化量的分组序号与x的序号之差都小于等于k,即样本在各个轮次内的损失值变化量与x的差都小于(k + 1)×m,则记为受检样本相对样本x在该训练轮次中的样本损失值变化量上具有(k,m)强度的统一性。
5)隔离后门样本集。在已知特定样本为后门的情况下,将现有的后门样本定为x,并隔离相对样本x在指定训练轮次内样本损失值变化量上都具有(k,m)强度的统一性的样本;在没有已知的后门样本的情况下,将两两之间都具有统一性的样本分为一类,将其中样本数量最多的一类视为后门样本并隔离。
对样本先分组再评估会导致损失值变化量在分组临界值两侧的样本统一性评估较差。但是考虑到基于遗忘的鲁棒训练本身就不要求找出所有后门样本,而直接使用损失值变化量评估统一性会大幅增加计算量,因此采用先分组后评估的隔离策略。此外,为了能够更明显地评估样本损失值变化统一性,可以在模型训练早期设置较低的学习率。较低的学习率下与后门关联弱的神经元对模型输出的调整较小,但是后门易于学习,与后门关联强的神经元的连接权重仍能获得较大修改。此时,后门样本损失值的变化更多是受与后门关联强的神经元影响,而更少收到其他普通神经元的影响,后门样本的损失值变化量也会更倾向于分布在同一值域内。
基于样本损失值变化统一性的后门样本隔离策略可应用于现有的数据隔离方法辅助隔离。在现有隔离样本集中对样本的统一性进行分析可以缩减分析范围,减少计算量。在现有隔离方法所隔离的潜在后门样本集中可以依据其隔离思想选定最可能是后门样本的样本作为初始后门样本,并隔离与这个(些)样本具有统一性的样本;或将不与这个(些)样本具有统一性的样本移出隔离样本集。
现有基于损失值的后门样本隔离方法中认为损失值低的样本倾向于是后门样本。因此可以在其隔离样本集中首先将损失值最低的一个或多个样本视为后门样本,并仅隔离选定的样本以及与选定样本具有统一性的样本。值得注意的是,Li等[3]提出的LGA机制限制干净样本的损失值于γ之上,但是并没有对模型结构进行限制。因此,在应用了LGA机制时,即便干净样本的损失值变化量被集中在初始损失值loss0与loss0-γ之间,干净样本的损失值变化量分布仍然较为分散,并且相对后门样本不表现出足够强的统一性。
3" 实验结果及分析
3.1" 实验设置
服务器使用Windows 10系统,使用Python,通过Sklearn函数库处理样本并进行模型训练。实验在ABL [3]框架下,在MNIST和CIFAR-10数据集上分别注入BadNets [1],Trojan [2]和LBA [10]共三种攻击的后门样本,训练了6个WRN-16神经网络模型。后门样本的投毒率被设定为10%。其中,设置统一性检验的损失值变化量分组步长m为0.25,分组判断步长k为0,选定的检验轮次为训练过程的前5个轮次与最后一个轮次。
3.2" 实验内容
实验针对6个模型,在Li等[3]的基于样本损失值的后门数据隔离结果上应用基于样本损失值变化统一性的后门隔离策略。实验中依照基于样本损失值隔离后门样本的思想,在其隔离的潜在后门样本集中选定10个损失值最低的样本作为判定样本统一性的中心,并放弃隔离在现有隔离结果中不与选定样本具有统一性的样本。实验在调整隔离结果后的隔离样本集中检验隔离的干净样本数量,并检验遗忘经过调整的隔离样本集后的模型性能表现。
3.3" 实验结果与分析
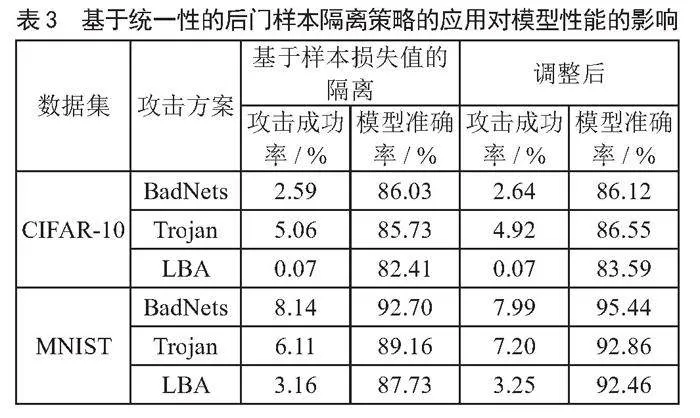
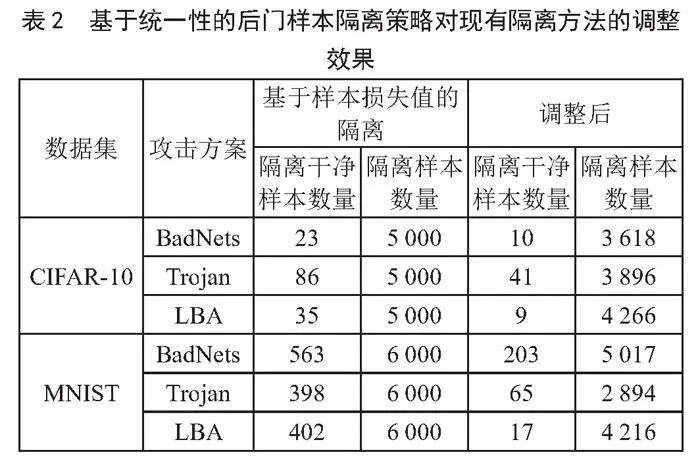
如表2所示,在现有隔离方法的基础上应用基于样本损失值变化统一性的后门样本隔离策略大幅减少了对干净样本的错误隔离。
如表3所示,在现有隔离方法上应用基于样本损失值变化统一性的后门样本隔离策略后,模型在遗忘过程中仍然成功阻止了后门的构建,并且模型在干净数据上的准确率得到了提升。由于通过模型遗忘技术阻止后门构建过程仅需隔离后门样本的子集,因此减少对后门样本的隔离并不会导致攻击成功率的大幅上升,而减少对干净样本的隔离则在模型遗忘的过程中保护了模型在干净数据上的性能。尤其是在MNIST数据集上,基于样本损失值变化统一性的后门样本隔离策略的应用在三种攻击上平均减少了73.27%的错误隔离,并将模型准确率平均提高了3.72%。
4" 结" 论
神经网络中存在与后门强关联的神经元,这些神经元的权重变化对后门样本的损失值会产生统一的巨大影响,因此大量后门样本在训练过程中在损失值变化量上表现出强统一性。基于样本损失值变化统一性,可以在训练过程隔离后门样本。此外,也可以在现有后门样本隔离方法的基础上对潜在后门样本类进行分析,通过移除不与潜在后门样本具有统一性的样本减少对干净样本的错误隔离。在基于遗忘的鲁棒训练中,应用基于样本损失值变化统一性的辅助隔离策略能实现减少错误隔离,保护了模型在干净数据上的性能,有助于人工智能应用的安全使用与安全模型训练。
参考文献:
[1] GU T Y,DOLAN-GAVITT B,GARG S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain [J/OL].arXiv:1708.06733 [cs.CR].(2017-08-22).https://arxiv.org/abs/1708.06733.
[2] LIU Y Q,MA S Q,AAFER Y,et al. Trojaning Attack on Neural Networks [C]//Network and Distributed System Security Symposium.San Diego:NDSS,2017:1-15.
[3] LI Y G,LYU X X,KOREN N,et al. Anti-backdoor Learning: Training Clean Models on Poisoned Data [J/OL].arXiv:2110.11571 [cs.LG].(2021-10-22).https://arxiv.org/abs/2110.11571.
[4] ZHANG Z X,LIU Q,WANG Z C,et al. Backdoor Defense Via Deconfounded Representation Learning [C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Vancouver:IEEE,2023:12228-12238.
[5] YANG J,ZHENG J,BAKER T,et al. Clean-label Poisoning Attacks on Federated Learning for IoT [J].Expert Systems,2023,40(5):e13161.
[6] LI S F,XUE M H,ZHAO B Z H,et al. Invisible Backdoor Attacks on Deep Neural Networks Via Steganography and Regularization [J].IEEE Transactions on Dependable and Secure Computing,2021,18(5):2088-2105.
[7] LIU K,DOLAN-GAVITT B,GARG S.Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks [J/OL].arXiv:1805.12185 [cs.CR].(2018-05-30).https://arxiv.org/abs/1805.12185.
[8] LIU Y,FAN M Y,CHEN C,et al. Backdoor defense with Machine Unlearning [C]//IEEE INFOCOM 2022-IEEE Conference on Computer Communications.London:IEEE,2022:280-289.
[9] WU B Y,CHEN H R,ZHANG M D,et al. BackdoorBench: A Comprehensive Benchmark of Backdoor Learning [J/OL].arXiv:2206.12654 [cs.LG].(2022-06-25).https://arxiv.org/abs/2206.12654v2.
[10] YAO Y S,LI H Y,ZHENG H T,et al. Latent backdoor attacks on Deep Neural Networks [C]//Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security.London:ACM,2019:2041-2055.
作者简介:张家辉(1998—),男,汉族,辽宁沈阳人,硕士在读,研究方向:人工智能安全、后门攻击、后门防御。
收稿日期:2023-12-07