
摘" 要:随着大数据时代的到来,数据资源的有效整合与利用已成为高校教育信息化和智能化发展的关键驱动力。对各高校数据资源平台进行相关研究,提出基于全量数据治理的高校数据资源平台实施方案,旨在通过系统化的数据治理服务,解决数据标准、质量、共享开放性及数据资产目录等核心问题。该方案遵循数据湖、标准数据仓库、数据集市的三层架构模型,构建了一个综合性的公共数据库。作为智慧校园建设的核心,该平台不仅促进了教学资源的共享和科研数据的整合,还为管理决策提供了科学化支持,从而推动了高校数据资源管理的现代化进程。
关键词:数据资源平台;全量数据治理;数据共享;高校教育信息化
中图分类号:TP311;G202" " 文献标识码:A" " " 文章编号:2096-4706(2024)21-0139-09
Implementation Plan for Colleges and Universities Data Resource Platform Based on Total Data Governance
ZOU Linlu
(Hangzhou City University, Hangzhou" 310015, China)
Abstract: With the advent of the era of Big Data, the effective integration and utilization of data resources have become a key driving force for the informatization and intellectualization development of colleges and universities education. This paper studies the data resource platform of colleges and universities, and puts forward the implementation plan of colleges and universities data resource platform based on total data governance, aiming at solving the core problems of the data standard, quality, sharing openness, and data asset directory through systematic data governance service. The scheme follows the three-layer architecture model of data lake, standard data warehouse and data mart, and constructs a comprehensive public database. As the core of the construction of the smart campus, the platform not only promotes the sharing of teaching resources and the integration of scientific research data, but also provides scientific support for management decision-making, so as to promote the modernization process of data resource management in colleges and universities.
Keywords: data resource platform; total data governance; data sharing; colleges and universities education informatization
0" 引" 言
在信息化浪潮中,数据的战略价值日益凸显,特别是对于高等教育机构而言,数据资源的有效管理和利用成为推动教育信息化、智能化发展的关键。随着大数据、云计算等新兴技术的快速发展,高校面临着数据爆炸式增长的挑战,如何整合分散的数据资源、提升数据质量、实现数据的开放共享,成为高校信息化建设中的重要课题。基于此,本文提出了一种基于全量数据治理[1]的高校数据资源平台实施方案,旨在通过系统化的数据治理服务,构建一个高效、稳定、可扩展的数据资源[2-3]平台,以支撑高校的教学、科研和管理决策[4],促进教育创新和知识发现。
1" 整体框架
1.1" 网络架构
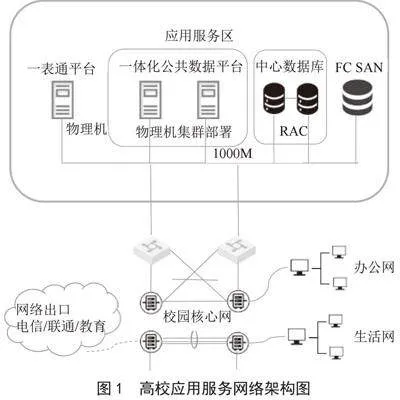
在构建全量数据治理的高校数据资源平台时,本文提出了一种网络架构设计方案,如图1所示,该方案充分考虑了高校现有的网络和服务器资源。
具体的方案详细描述如下:
1)应用部署优先级。所有与数据资源平台相关的应用、平台及数据库服务器,应优先部署在物理服务器上。这一策略的实施基于学校能够提供必要的物理服务器资源的前提,旨在确保平台和应用能够实现高性能运行,并有效支持高并发访问。
2)网络连接设计。在各平台和应用服务器之间,本方案采用千兆以太网技术进行网络互连。这种设计确保了数据传输的高吞吐量,同时保障了网络连接的稳定性,满足大规模数据交换的需求。
3)数据存储策略。在数据存储层面,本方案结合了学校现有的FC SAN共享存储设施。数据库系统采用Oracle RAC(Real Application Clusters)技术构建高可用集群。这种配置不仅提升了数据中心数据库的可用性,也增强了其健壮性,确保了关键数据服务的连续性和可靠性。
通过上述设计,本文提出的方案旨在为高校数据资源平台提供一个高效、稳定和可扩展的网络架构,以支持日益增长的数据管理和分析需求。
1.2" 系统架构
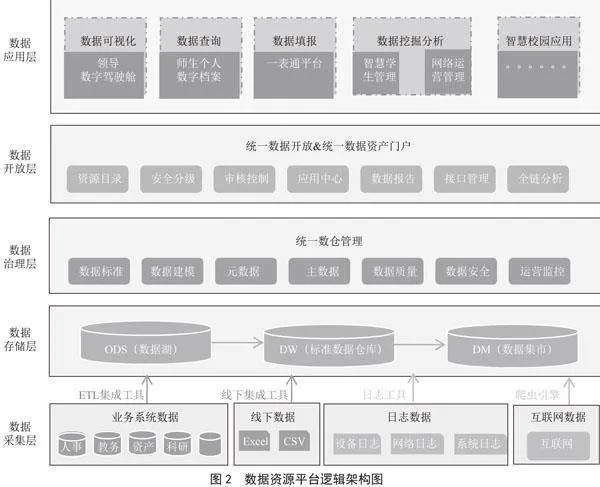
本文提出的全量数据治理高校数据资源平台在逻辑架构[5]上,采用了层次清晰的松耦合架构,将整个数据平台从逻辑上分为5层,分别为:数据采集层、数据存储层、数据治理层、数据开放层、数据应用,如图2所示。基于此架构,通过对数据层面共性能力的抽象和沉淀,在保证学校数据规范化的基础上,快速支撑信息化场景的创新、快速满足变化快的上层业务需求、支撑学校数字化改革需求,从而获得更高的建设效益。
依据数据全链路流向,逻辑架构层次说明如下:
1)数据采集层。对学校的业务系统数据、线下电子表格数据进行采集,通过不同的数据集成方式实现以上两大类的数据采集,保证对于学校数据资产的积累,夯实数据服务能力。
2)数据存储层。本项目对数据存储,支持关系型数据库(MySQL、Oracle、SQL" Server、PostgreSQL等)和非关系型数据库(HDFS、Hive、Kafka、MongoDB、Impala等)。实现不同类型数据可分类有序的存储,保障数据实际使用场景的需求。
3)数据治理层。采集完成的数据,通过数据治理服务,形成数据标准、数据接口、数据采集、数据清洗等在内的数据治理规则。通过业务部门数据现状调研,实现字段级数据权威来源部门的归属确权,提升元数据管理能力。同时对数据治理后的数据进行运营监控,提高数据使用的安全性。并定期生成数据质量报告反馈至数据权威部门,闭环提升数据质量。
4)数据开放层。通过统一数据开放,帮助校方数据管理员以可视化的方式对数据进行全生命周期的管理,以快速、简便、安全的多种数据服务方式支撑上层数据应用建设。通过统一数据资源门户可依据元数据信息,对校级数据资源目录进行编制、校对及发布,根据不同的共享使用权限,完整呈现和检索学校当前的数据清单详情以及使用路径。校内各个部门可以查看本部门提供数据的情况、获取数据的情况、数据存在的质量问题和改善进度、数据在全校流动的全生命周期信息等,实现数据治理的全部门参与,促进学校数据体系的持续完善。
5)数据应用层。利用治理后的数据资源,支撑建设一表通平台,一方面检验公共数据平台和数据治理建设成果,另一方面可通过应用端的建设,将治理后的数据价值进行输出,利用信息化手段切实解决师生在日常工作中普遍遇到的重复填报问题,提升师生对学校信息化数据层面建设的感知度。
2" 系统通用设计
基于底层架构的健壮性,考虑存储容灾、网络容灾、数据库容灾、应用服务器容灾等需求。
存储容灾方面,采用RAID5方式进行磁盘划分,防止由于磁道损坏导致的文件丢失,实现文件级的容灾方案。
网络容灾考虑链路冗余和网口冗余,链路冗余采用管理网络和存储网络分开,且管理网络和存储网络均为双交换机的热备冗余,实现网络链路的容灾方案,重要资源项再用网口绑定技术,防止单网口故障导致的网络传输故障,实现网口级的冗余方案。
数据库容灾需求中,核心数据库采用RAC架构部署,双节点同时提供服务,当某一节点发生故障时,存活的节点继续提供数据库服务,前端业务无感知,防止数据库的单点故障,使用MAA架构实现核心数据库集群主备数据库集群切换,防止集群故障导致的业务长时间中断,短时间内切换至备库集群提供数据服务,实现集群级的灾备方案,数据库文件采用Oracle自带ASM磁盘管理,ASM(Automatic Storage Management)是Oracle10g R2中为了简化Oracle数据库的管理而推出来的一项新功能。ASM它提供了以平台无关的文件系统、逻辑卷管理以及软RAID服务,实现数据库文件级的容灾方案。
应用服务器容灾主要指一体化公共数据平台的应用容灾,通过NGINX负载均衡技术,避免共享Web服务的单点故障,从而实现应用服务级别的容灾方案。
3" 数据治理服务具体实施方案
3.1" 校级数据标准制定服务
在制定校级数据标准的过程中,本方案遵循了一套系统化的方法,确保了数据标准的科学性和实用性,主要流程包括编制、审查和发布。所有操作均有数据标准管理[6]部门进行,包括后续的说明保存备案留存等。数据标准的编制、审查和发布通过数据治理的数据标准管理模块实现。
3.1.1" 标准制定
本方案基于实际情况,结合教育部2012版信息标准(JY/T 1006—2012,以下简称“部标”)和高校实习情况,落地过程中在此基础上优化后形成符合学校实际业务需求的校级标准。具体优化内容如下:
1)优化表结构。结合学校实际数据使用场景进行表结构的优化,例如:学校实际用到的学生基本信息表,从部标中的基本信息系+学籍信息两张表整合而来。
2)命名规范扩展。在部标的基础上,增加了数据开发、过程管理、接口管理等方面的命名规范,确保了数据命名的一致性和规范性。例如ETL接口、任务、索引、序列、过程、函数等,且将命名规范纳入数据开发规范,以实现对浅笑数据开发进行规范化管理的目标。
3)优化代码集。针对学校使用的代码集,建立了映射关系,例如:学校1、2、3、4表中使用了A代码集,5表中使用了B代码集,A\B代码集表示含义相同而差别很大,依据选举原则,确定使用A代码集作为学校标准,人工建立A、B代码集的映射关系,使用了B代码集的表5进行数据转换;
4)补充新标准。在部标的基础上,根据学校的特定需求,补充了新的数据标准,例如教师的教师学习记录课程代码集名称、一卡通数据集标准、日志数据标准等。
3.1.2" 数据标准具体实施
在数据标准的实施过程中,学校协调了数据提供者和执行者参与数据属性的收集和整理,形成了数据标准的初稿。初稿经过审查和讨论后,由数据标准管理部门进行修改和完善,最终完成数据标准的发布,并更新至数据标准管理模块中。
3.2" 全量数据采集服务
3.2.1" 业务系统数据采集
本项目业务系统数据采集范围:人事、教务、教学、学工、就业、迎新、资产、财务、外事、智慧教学、图书、一卡通等各个业务域。
3.2.2" 线下表格采集
全面采集各部门使用的包含管理数据的线下Excel电子表格数据。
3.2.3" 数据湖的构建与优化
数据湖的建设服务旨在创建一个集中的物理数据库环境,用以存储来自不同源头的原始数据副本。通过这种方式,多源异构数据得以整合于单一数据库实例之中,实现数据的同构化和同实例化处理。此举的益处在于简化了后续数据处理流程,消除了跨库操作及异构数据整合所带来的技术障碍,从而确保了数据的完整性和各维度的统一。
3.3" 数据质量检查服务
数据采集识别完毕后,需要进行数据质量检查,并在“统一数仓管理”的数据质量管理模块落实,具体步骤方式如下:
1)规则设定。
2)规则绑定。
3)质量检测执行,输出质量检测报告。
3.3.1" 质量分析和预警
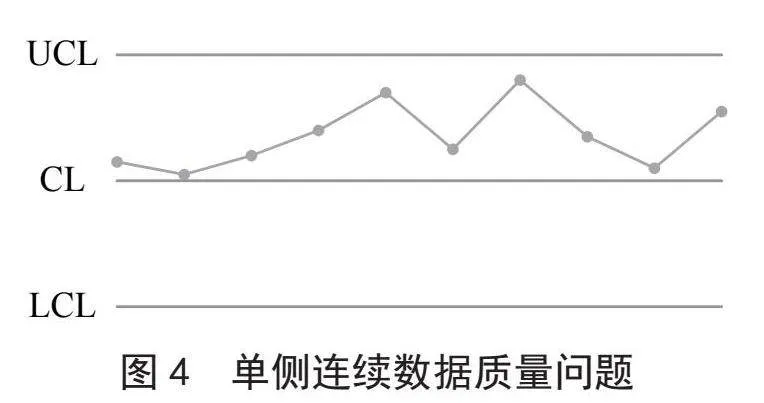
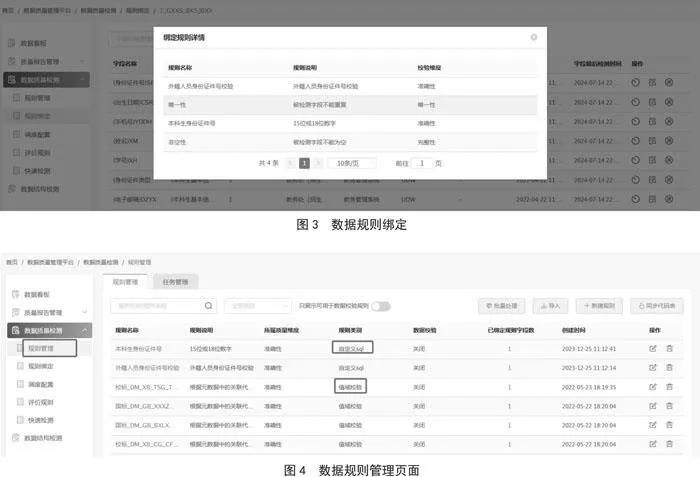
通过预设的数据质量检验规则,结合字段与规则的绑定,对选定的数据字段执行规则检验。具体如图3、图4所示。
3.3.2" 数据质量反馈认领
本方案通过数据质量规则定义功能,系统自动完成数据质量检测,并同步生成预警及统计分析,形成相应质量报告,同时支持实时导出为Excel文件,邮件提醒等功能。
质量报告样例如图5至图7所示。
3.4" 数据清洗及转换服务
3.4.1" 数据清洗
原始数据中可能存在着大量的脏数据,需要根据数据质量管理的要求,利用相关技术对业务系统产生的问题数据进行清洗,将脏数据转换成满足要求的高质量数据。
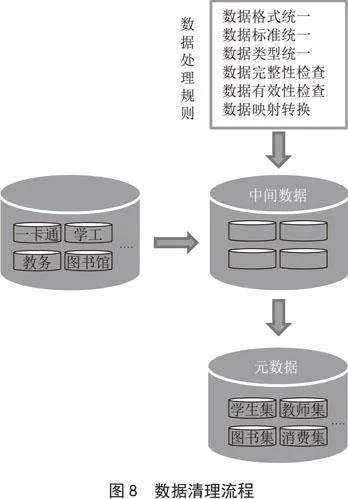
所有业务系统的数据接入并最终入库的过程都需要遵循数据清洗的规范要求,降低脏数据等对于业务和分析结果的影响。数据清理流程如图8所示。
具体介绍如下:
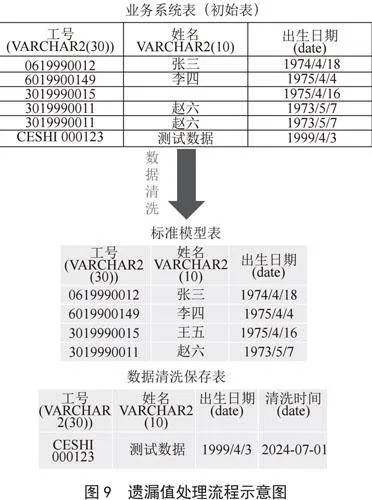
1)遗漏值处理。各个业务系统在进行数据录入时,可能存在某些值遗漏,如图9所示,若“姓名”值遗漏,根据业务实际情况填充。
数据缺失和数据遗漏按照处理的主体不同,可以分为人工处理方法和自动处理方法:
人工处理方法,即通过手工填补所缺失的数值。这种方法的好处是当遗漏的数据量比较少时,填补的准确度相对较高。
自动处理方法,即当发现一个记录的属性值有遗漏时,通过已有的程序自动处理,这种方式的好处在于当遗漏的数据量较大时,在效率上优于手动处理方法。但是自动清洗方法在很大程度上依赖于处理的程序,不够灵活,处理少量缺失数据时准确度不如人工处理高。
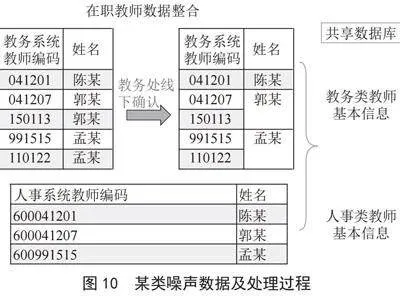
2)噪音数据处理。目前被认定为噪音数据的主要是错误数据和重复数据。其中,错误数据产生的原因是各业务系统不够健全,通过制定的标准规则,从源头抓起提升数据质量。某类噪声数据及处理过程如图10所示。
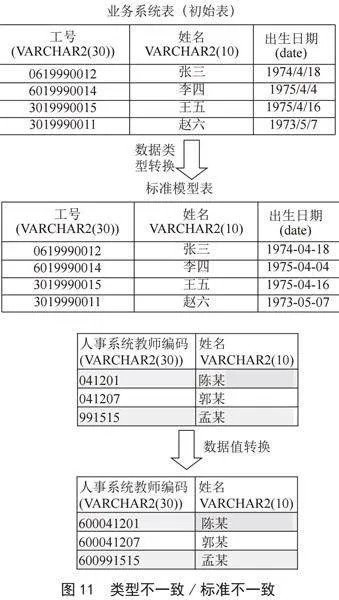
3)不一致数据处理。如图11所示,在进行数据清洗的过程中,往往会发现几个来源的同维度数据,会存在数据内容、类型以及参考标准的不一致。这些不一致数据主要来自两个方面:一是数据冗余,二是并发控制不当。
解决数据不一致性,主要是确认各类数据的权威源头,通过权威数据源头来控制其对于各个共享点的数据同步和更新。
3.4.2" 数据转换
对采集的数据进行标准化处理,保证格式统一。按照数据转换类别分如下情况:
1)格式和命名统一。通过建立统一的数据命名和格式规范,实现数据的标准化,包括数据的计量单位和转换规则。
2)数据类型标准化。解决数据类型不一致的问题,例如,将不同数据源中的工号字段统一转换为标准字符类型,使用数据库内置函数(如Oracle的TO_CHAR)进行类型转换。
3)数据标准统一。统一不同系统中的数据标准,如性别字段在不同系统中方式不同,确保数据在集成时遵循统一的标准。
4)数据的二次计算。在数据仓库中,对原始数据进行必要的计算和汇总,如统计学院人数和职称,以提高分析效率。
3.4.3" 数据集成
将不同的数据源通过ETL[7]合并到统一的数据存储库中,数据集成管理包括:
1) 资源展示。集中展示已配置的数据源信息,包括类型、接口、业务关联、数据规模和更新频率。
2) 集成项目展示。展示已配置的集成项目信息,包括数据源、业务类型、应用系统和交换频度。
3) 过程监控。监控数据集成项目的运行状态,包括启动、停止和运行状态,并提供操作控制。
4) 统计信息展示。提供集成数据的统计信息,如数据总量、数据源连接数、集成表数等。
5) 数据冗余规则。为数据集成设置冗余规则,使用“拉链表”和“历史表”设计,以实现数据的溯源和备份。
6) 运行监视。提供全面的运行监视功能,通过定制的集成任务列表和图表展现运行状态。
7) 异常警告机制。当集成过程中出现异常时,通过邮件或短信发出警告,并提供异常信息的查看和统计功能。
3.4.4" 线下数据清洗服务
对包含管理数据的电子表格数据,进行必要的规范化、标准化处理后,利用文本数据集成功能进行线上化处理,利用数据库进行存储和管理。
3.5" 构建标准数据集服务
3.5.1" 标准数据仓库构建方法
标准化数据仓库的构建基于数据湖[8]中的原始数据,通过一系列数据处理步骤,包括权威来源识别、数据去重、多表关联、格式转换等,形成结构化的数据集合。这一过程确保了数据从原始状态到符合校级数据标准要求的转变,同时避免了数据集市层的特定应用优化。
3.5.2" 标准数仓标准性设计
整个数据仓库的建设都依照数据标准进行建模,通过建模工具结合数据标准规定的分类和格式规范,生成相应的数据仓库结构,再采集学校的各种有价值数据,按照质量要求进行清洗治理,按照数据标准的格式进行建模,利用大数据基础技术架构进行存储,形成全量数据仓库。同时,保留重要的历史数据,确保重要数据全生命周期留痕。
3.5.3" 标准数仓的建模思想
数据仓库的建模思想考虑到高校数据的多样性和复杂性,采用灵活的建模方法以适应不同的应用场景。数据质量由操作性系统保证,而非仅仅依赖于范式约束。
3.5.4" 数据分类与子集建设
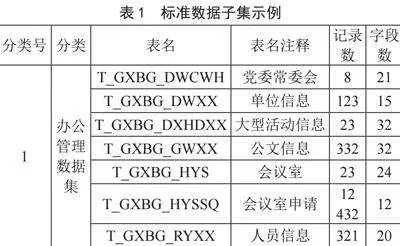
标准化数据仓库中的各个数据表根据其内容被归类到相应的数据子集中。这些子集基于教育部发布的教育行业标准进行扩展和改编,形成了包括学校概况、学生管理、教学管理等11个主要的数据子集。标准数据子集示例如表1所示。
3.5.5" 数据子集建设服务
经过采集、识别、质量检查和清洗治理的原始数据转化为标准数据,并根据数据标准进行清洗和转换后,存储到相应的数据子集中。完成存储后,利用数据仓库管理系统进行数据质量检查,确保数据仓库中的数据符合既定标准。
3.5.6" 主题数据集建设服务
学校信息化建设的许多场景的实现都要求学校必须有多维、完整、高质量的数据来支撑,以达到技术降本、应用提效、业务赋能的目标,但是在通过现有数据支撑业务实现的过程中发现仍有如下问题亟待解决[9]:
1)数据规划与业务需求的脱节导致数据价值难以充分发挥。学校的数据管理员常常需要重复处理相同的数据集,如人员信息、组织架构、一卡通账号等,以支持统一身份认证等业务场景。这种重复性工作消耗了大量精力,而且由于缺乏对共性数据集的归纳整理,即使投入大量资源,也难以跟上业务应用开发对数据的需求速度。
2)数据资源的不透明性限制了其潜力的发挥。数据使用者常常不清楚信息中心所提供的数据种类,也不知道如何高效检索所需数据。数据提供部门与使用部门之间缺乏有效的沟通渠道,导致数据获取和使用效率低下。
为了解决这些问题,本项目提出将数据封装成主题数据集,根据不同部门和业务场景的需求,提供定制化的数据服务。通过公共数据平台发布数据仓库和数据集市的数据,实现数据与应用的无缝对接,打破数据孤岛,充分释放数据价值。
3.5.7" 历史数据留存服务
本文提出的“历史数据留存”方案,对主数据进行存档,方便应用程序从多个维度进行访问和检索,实现全校数据的全生命周期管理。主要实现方式是以拉链表的数据存储结构,在当前数据库其他用户下创建以“表名+_HIS”的命名创建历史过程数据留存表,来记录历史变化的数据。
通常,历史数据存储有如下要求:
1)设计合理的历史数据存储的数据结构,既能实现应用程序不同的访问逻辑,又能减少存储空间。
2)对重要的状态型数据的变化情况进行捕获存档,使应用程序能够方便读取其不同时段的数据变化情况。
3)对大容量的流水型的表数据要进行拆分存储,避免因单表数据量过大造成查询效率低下。
针对上述要求,本方案的历史数据留存详细实现设计如下:
1)历史数据的存储方式设计。存储容器:Oracle,与主表使用同一个Oracle实例。管理方式:主表与历史表分别放在不同用户下。历史数据生成频率:默认3天。数据结构设计:计划采用“拉链表”技术进行历史数据的留存和访问。
2)“拉链表”留存。对于状态数据的变化的数据留存,采用技术较为成熟的“拉链表”方式进行留存,其技术实现较为成熟,既满足了历史数据的留存需求,且避免了以时间维度定时留存导致的存储浪费和检索困难。使用“拉链表”数据结构对历史数据进行存储,还需要应用层面的事务配合支持。
3)辅助字段和表的设计。该阶段主要确定“拉链表”实现所需的辅助表、历史表和字段属性的设计。主要有历史数据表,该表结构与主表字段属性相同,须新增“操作时间”和“过期时间”字段;辅助表主要记录主表中的数据行的版本信息,用以比对自上次历史数据留存后,主表记录的变化情况,定位变更的数据行,然后在历史表中执行数据留存操作;主表的主键字段和时间戳字段共同组成了能够唯一标识该行数据记录的版本信息。需要注意的是:在MySQL和SQLServer数据库中,该类型字段可以由RDBMS自动维护,而Oracle数据库中则需要使用ETL工具或者程序维护。
3.5.8" 数据中心接口迁移服务
本项目通过实施一系列策略,确保了数据接口的平滑、有效迁移。
首先,我们采用了视图共享、ETL推送和API接口等多种迁移方式,以适应不同场景的需求。其次,对所有下行数据接口进行了彻底的解析,包括数据表、字段和表间关联关系,为迁移的准确性奠定了基础。再次,通过在公共数据平台上重现验证原数据接口的业务逻辑,确保了下游业务系统的顺畅运转。最后,项目还设计了回退机制,以应对迁移过程中可能出现的任何问题,保障业务的连续性。
3.6" 数据集市建设服务
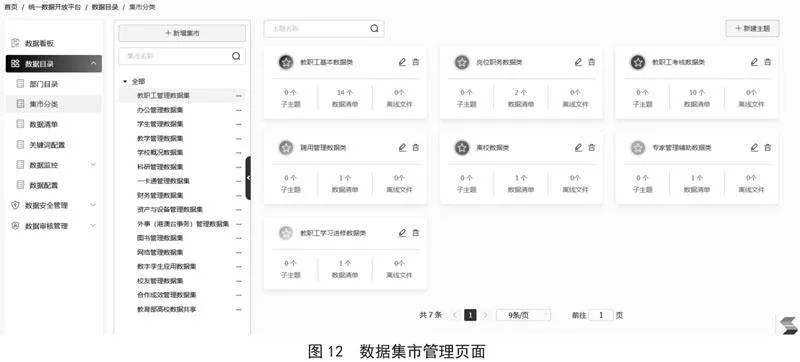
数据集市[10-11]管理功能,将已经通过数据治理的数据资源进行集中分类呈现,数据集市中需显示数据资源的名称、所属主题、数据记录数、字段数、数据更新时间、可提供的服务接口类型等信息,以便数据用户进行检索、预览、申请、调用。图12为数据集市提供数据资源展示功能。
4" 结" 论
本研究提出的高校数据资源平台实施方案,将全量数据治理服务作为核心,旨在全面提升高校数据资源的整合、管理和利用效率。通过构建一个基于数据湖、标准数据仓库和数据集市的三层架构模型,本方案不仅优化了数据存储结构,还强化了数据的标准化、质量管理和安全共享。全量数据治理服务的实施,包括数据采集、清洗、标准化和质量监控等关键环节,确保了数据的准确性和一致性,为高校决策支持、教学资源优化和科研创新提供了坚实的数据基础。
此外,本方案通过数据集市的建设,实现了数据资源的集中分类呈现,简化了数据检索、预览、申请和调用流程,极大提高了数据的可用性和便捷性。同时,历史数据留存服务的引入,为数据的全生命周期管理提供了有力支持,增强了数据的可追溯性和再利用价值。
面向未来,随着技术的不断进步和教育需求的持续发展,全量数据治理服务将持续演进,进一步集成新兴技术,如人工智能和区块链,以提升数据治理的智能化水平和安全性。通过不断的技术创新和服务优化,本方案将助力高校数据资源平台实现更高效、更安全、更智能的数据管理,为推动高等教育信息化和现代化做出积极贡献。
参考文献:
[1] 刘桂锋,钱锦琳,卢章平.国内外数据治理研究进展:内涵、要素、模型与框架 [J].图书情报工作,2017,61(21):137-144.
[2] 王思琪.数据治理在高校信息化建设中的探索与实践 [J].常州信息职业技术学院学报,2019,18(4):13-16.
[3] 宋苏轩,杨现民,宋子强.高校数据治理统筹管理体系的构成与实践路径 [J].中国远程教育,2021(11):58-67.
[4] 周江林.数据治理:大数据时代“双一流”建设的路径优化取向 [J].教育发展研究,2022,42(5):15-21.
[5] 包冬梅,范颖捷,李鸣.高校图书馆数据治理及其框架 [J].图书情报工作,2015(18),134-141
[6] 余鹏,李艳.智慧校园视域下高等教育数据生态治理体系研究 [J].中国电化教育,2020(5):88-100.
[7] 陈锋.ETL数据治理在高校信息化建设中的研究与应用 [J].中国教育信息化,2020(13):68-70.
[8] 刘志勇,何忠江,刘敬龙,等.统一数据湖技术研究和建设方案 [J].电信科学,2021,37(1):121-128.
[9] 高亮.数据治理:让数据质量更好 [J].中国教育网络,2014(12):64-66.
[10] 邓斌,李明东.数据集市技术在高校信息管理中的应用 [J].山东农业大学学报:自然科学版,2004(4):611-614.
[11] 巫莉莉,张波.高校数据治理中提升数据质量的方法研究 [J].重庆理工大学学报:自然科学,2019,33(8):149-156.
作者简介:邹霖璐(1991—),女,汉族,浙江慈溪人,初级职称,硕士研究生,研究方向:高校信息化应用、计算机软件技术、信息技术应用等。