冯思度 杨健叶 韩煦

摘 要:医疗卫生信息对于人们了解、获取医疗资源十分重要,其准确性和实时性则尤其重要。为了方便准确而快速地检索到医疗卫生信息,需要建设一个和医疗卫生信息相关的专题搜索网站。针对上述情况,首先设计基于主题的网络爬虫功能,然后采用MS SQL Server 2008作为数据存储、Visual Studio.NET2010作为开发工具实现专题搜索网站及其网络爬虫的设计。经过实际测试与运行表明,该系统能够满足基本的医疗信息专题搜索的要求。
关键词:搜索引擎;网络爬虫;医疗卫生信息;专题网站
中图分类号:TP311.1 文献标识码:A 文章编号:2096-4706(2019)10-0023-03
Abstract:The medical and health information is very important for people to understand and obtain medical resources,and its accuracy and real-time are particularly important. In order to retrieve medical and health information quickly and conveniently,a special search website related to medical and health information is needed. In view of the above situation,a search website with its web crawler of subject topic were designed,and then using MS SQL Server 2008 as DBMS and Visual Studio.NET 2010 as development tools develop these. Test and operation showed that the system meets the requirements of basic medical information subject search.
Keywords:search engine;web crawler;medical and health information;special subject website
0 引 言
随着互联网的信息的飞速增长,2018年《中国互联网络发展状况统计报告》指出,截止至2017年12月,中国网站数量为533万、增率为10.6%,中国网页数量约为2604亿个,年增长10.3%。如何从这些蕴含海量信息的互联网中准确找到所需的相关内容是Web信息获取的关键所在[1]。在此背景下,搜索引擎成为人们从互联网快速检索、获取信息的重要手段[2]。搜索引擎对于信息的抓取基本上是以全面广泛的方式,当使用关键词进行搜索的时候,它会展现出很多与之相关的信息。但是这种方式也有着一些不足之处。当需要对某些专题信息,如医疗卫生信息、毕业生招聘信息等进行搜索时,综合搜索引擎就不能很好地满足要求[1,3,4]。因此需要为某一专题建立针对性的专题搜索网站。而设计一个专题搜索网站的核心问题之一是搜索引擎中的网络爬虫的设计与实现,以便自动进行万维网网页的抓取并将其保存下来用于搜索引擎之后生成索引供用户搜索[5]。此外,针对医疗卫生信息建立一个专题搜索网站,有助于人们获取及时准确的医疗卫生信息,这对人们就医、诊疗等有着很好的现实意义。
针对医疗卫生信息主题搜索的需求,本文设计开发了一个医疗信息相关搜索引擎的网络爬虫模块。爬虫专门用于在互联网上爬取与医疗相关的信息,从而可以更加专业化、定制化地检索到所需要的医疗卫生信息。
1 网络爬虫的工作原理及关键技术
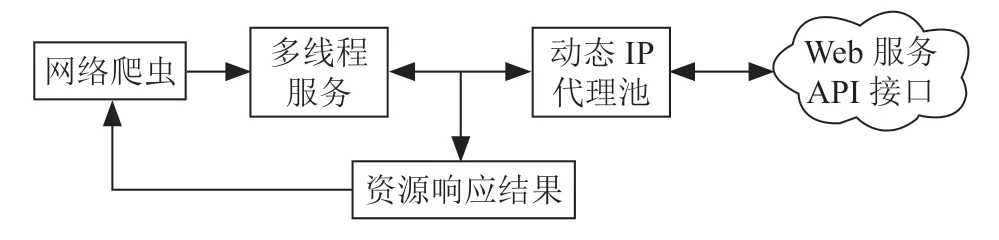
网络爬虫(也称网络蜘蛛、网络机器人)是用于抓取网络资源的计算机程序,是搜索引擎的重要组成部分。网络爬虫通过全面和快速地向分析系统和索引系统提供网页数据,起到搜索引擎的数据支撑作用[6]。网络爬虫通过网页上的链接关系来分析和寻找网页,读取网页内容,通过种子站点寻找下一个网页,周而复始,直到把所需的所有网页抓取完毕。
针对医疗卫生方面的网络爬虫设计需要以下三个关键技术[7]:
(1)信息收集和存储技术(即网页抓取优先策略,决定使用何种待爬行URL的访问次序);
(2)信息预处理技术(即关键词的提取、倒排索引的建立);
(3)信息检索及处理技术。
2 网络爬虫系统设计
2.1 网络爬虫模块的设计
网络爬虫程序可以实现对指定URL内容、标题和相应的链接的爬取,并根据爬取到的新链接进行迭代爬取工作。常用的爬取策略有广度优先遍历和深度优先遍历。本网络爬虫采用广度优先遍历的策略,主要基于以下三个原因:
(1)重要的网页往往离种子比较近,就像用户打开新闻网站的时候看到的往往都是最热门的新闻,随着不断的深入浏览,用户所看到的网页的重要性越来越低;
(2)万维网的实际深度并不深,而且横向价值密度较高[8,9]。而且到达某一个网页总会存在一个很短的路径,广度优先遍历会以很快的速度到达这个网页;
(3)相对于深度优先遍历的策略来说,广度优先遍历的策略不会存在短时间不断地访问同一台服务器的问题,也不会轻易陷入无限循环的文档树之中[10]。
2.2 网页的预处理模块设计
2.2.1 索引网页库
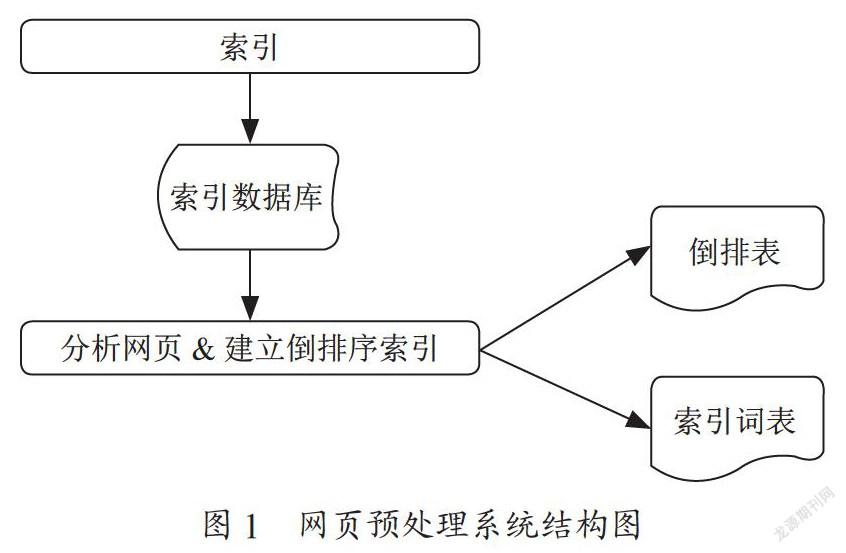
网页信息预处理的第一步就是为原始网页建立索引,在实现索引网页库,有了索引之后,就可以为搜索引擎提供网页快照的相关功能;第二步是针对索引网页库进行网页切分,将每一篇网页转化为一组次的集合;最后一步是将网页到索引词的映射转变成为索引词到网页的映射,这样做之后形成倒排文件和相应的索引词表,过程如图1所示。
2.2.2 网页编码的识别与分析
在网页预处理的时候,对于中文的网页我们需要对其进行切词,在这之前我们需要对网页的编码进行识别。一般的几种编码识别方式有这几种:第一种是从HTTP中head头部里面的charset内容获得相对应的编码方式;第二种是从head头部中的meta标签的charset属性获得编码方式;第三种是从网页页面的语言类型来推测一个编码方式,这种方式的实现有些困难。
2.2.3 分析网页和建立倒排文件
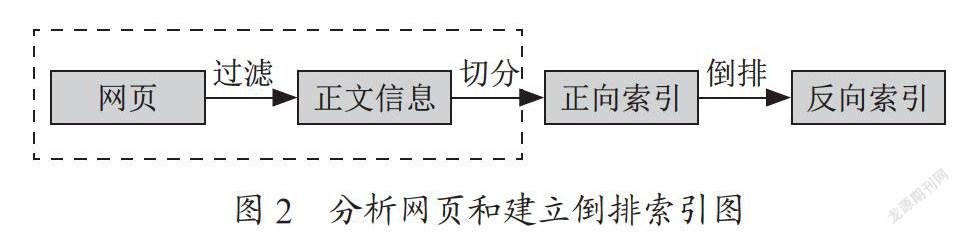
首先进行网页的正文信息提取和正文信息切分这两个阶段,在得到网页的正文信息之后,系统调用相对应的切词模块可以获得正向的索引,在建立完成正向的索引之后,使用相应的算法建立倒排索引和相应的倒排文件,处理过程如图2所示。
2.3 信息检索服务模块设计
在完成前面的网页抓取和网页的预处理之后,就是信息检索服务的模块了。检索服务包括获取用户输入的关键词、对关键词进行相应的检索、最后获得与关键词相匹配的结果并且以一定的排序方法显示给用户。比较典型的排序方法就是谷歌的PageRank(PR)和百度的竞价排名方法。本网络爬虫设计采用的是一种基于谷歌PR方法和实际的医疗卫生信息情况相结合的方法。
2.4 数据库关键表逻辑结构设计
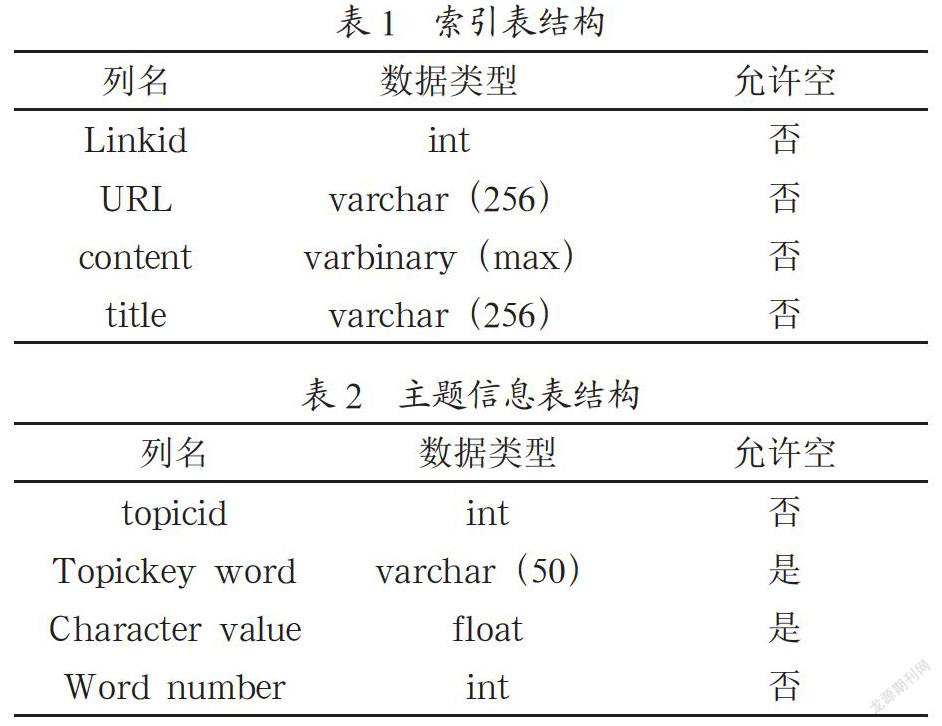
数据库中表用于爬取到的网页信息,本系统中部分主要表结构如表1、2所示。
3 网络爬虫系统的实现
首先利用网络爬虫程序来爬取和医疗相关的信息。在指定爬取的URL和爬取获取的文件保存位置后,就可以爬取网页信息了,在完成爬取后进行网页文件的存储。然后将获取到的网页的标题和链接插入到数据库中,建立专业化、定制化索引表,如图3所示,便于下一步的用户查询使用。在完成这些工作以后,用户就可以利用这些进行相关信息检索了,在如图所示的界面中,如图4所示,用户在关键词输入框中输入检索的关键词,单击确定即可使输入的关键词匹配索引数据库中的内容,并将得到的结构以超链接的形式显示在网页下方,单击链接即可跳转到对应的网页。
4 结 论
随着互联网信息的急剧增长和互联网信息使用人数的飞增,网络爬虫的使用也越来越多,对它性能的要求也越来越高。本文的设计在网络爬虫的爬取策略方面,只实现了基本的广度优先策略,因此在网络爬虫爬取策略、网页相关度分析、动态网页的爬取等方面还可以进行进一步研究。
在爬取后的内容索引建立方面,完成了基本的内容获取以及标题、链接的获取与使用。但是在检索和建立索引的时候,还有很多更加复杂的切词、插入、排序等方法有待研究和加入使用。
在最后的用户检索模块,可以设计出一种基于PR算法和实际医疗卫生信息专题网站相结合的排序算法,来更好地满足网站的需求。
总之,在完成了基本的网络爬虫程序以后,可以在以后进一步完善和加强,能够使网络爬虫程序、搜索引擎程序更加满足人们对于互联网信息检索获取的需要。
参考文献:
[1] 唐志,王成良.遗传算法在主题Web信息采集中的应用研究 [J].计算机科学,2006(7):71-74.
[2] 王继成,萧嵘,孙正兴,等.Web信息检索研究进展 [J].计算机研究与发展,2001(2):187-193.
[3] 左楠.个性化搜索引擎的设计与实现 [D].石家庄:河北科技大学,2013.
[4] 张博,蔡皖东.面向主题的网络蜘蛛技术研究及系统实现 [J].微电子学与计算机,2009,26(5):52-55.
[5] 印鉴,陈忆群,张钢.搜索引擎技术研究与发展 [J].计算机工程,2005(14):54-56+104.
[6] 刘金红,陆余良.主题网络爬虫研究综述 [J].计算机应用研究,2007(10):26-29+47.
[7] 周立柱,林玲.聚焦爬虫技术研究综述 [J].计算机应用,2005(9):1965-1969.
[8] 王彦博,樊营,高潜.大数据时代网络爬虫技术在商业银行中的应用 [J].银行家,2016(6):114-116.
[9] 张晶,肖智斌,容会,等.改进型遗传算法在网络蜘蛛上的应用 [J].山东大学学报(理学版),2015,50(5):1-6.
[10] 罗刚,王振东.自己动手写网络爬虫 [M].北京:清华大学出版社,2010.
作者简介:冯思度(1998-),男,汉族,江苏徐州人,本科在读,研究方向:数据库技术、医学信息工程。