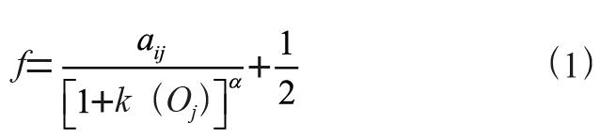彭宜丹 刘洪伟 高鸿铭

摘 要:电信用户的消费行为与消费特征不尽相同,如何对电信用户群体进行有效划分,是值得关注的问题。文章研究了利用电信用户的自身属性与业务属性,构建潜在类别模型,通过10个外显变量对其进行分类,并根据划分结果分析每一类用户的消费特征。研究结果表明,电信用户可分为临时型、低值型、传统型、公务型、佛系型和稳定型6种类型,其中公务型用户群体消费水平最高且相对稳定,具有较高的用户维护价值,运营商应给予最多的关注。
关键词:电信用户;RFM分析;潜在类别模型;用户分类
中图分类号:TP311.13 文献标识码:A 文章编号:2096-4706(2021)02-0006-06
Abstract:The consumption behavior and consumption characteristics of telecom users are different. How to divide telecom user groups effectively is a problem worthy of attention. Based on the self attributes of telecom users and service attribute,this paper constructs latent class model,classifies them by 10 explicit variables,and analyzes the consumption characteristics of each category of users according to the classification results. The results show that telecom users can be divided into six types:temporary,low value,traditional,official,buddhist and stable. Among them,the consumption level of official users is the highest and relatively stable,which has higher user maintenance value,and operators should pay more attention to it.
Keywords:telecom user;RFM analysis;latent class model;user classification
0 引 言
随着5G技术的逐渐成熟,移动5G用户数正呈井喷式上升,对于移动运营商来说,如何在新的竞争环境下获取更高收益的问题迫在眉睫。同时,由于移动互联网的高速发展,电信行业传统的通话、短信业务量严重下滑,取而代之的是流量消费的需求日益增加。面对电信用户消费结构的变化,运营商如何管理用户关系、识别用户特征、有效划分用户类别并进行精准营销,以减少用户流失,在新一轮的“抢人大战”中占据主导权显得尤为关键。
一般来说,用户分类管理是用户关系管理的重要手段,用户细分主要基于用户的三大特征,即人口统计学特征,行为特征以及心理特征。随着研究的深入,相对于其他行业来说,电信行业在数据流量上拥有优势,电信运营商通常依据其中1~2个维度对用户进行等级划分,使用不同的营销手段,例如,中国三大运营商之一的移动根据用户网龄、月均消费金额、合约情况、停机次数等数据对用户进行星级评定,对于不同星级的用户给予不同的优惠政策。但这一划分方式通常只是简单根据用户当月的消费金额等进行等级评定,并未从用户统计学特征、消费特征等多方面进行综合分析,详细构建用户画像。另外,传统的研究通常利用K-mean聚类算法[1]、混合回归模型[2]、因子分子的方法进行用户细分,但这些聚类算法往往存在一定的缺陷,如聚类结果不稳定,易受初始值影响等。
为更精准的评判用户价值,对用户进行精细化管理,本文拟在RFM理论的基础上,从用户属性和业务属性角度出发,对电信用户进行分类;同时,通过贝叶斯理论,使用一种新的概率分析方法,引入潜在变量,并根据潜在类别模型将每个用户划分到某个潜在类别中来达到用户分类的目的。
1 理论基础
用户是企业的核心竞争力,企业通过使用有效地用户管理方法,能够及时了解不同用户特点,有效维护用户关系,充分保留高价值用户。因此,采用有效地分类方法显得至关重要。Arthur Hughes提出,用户特点可由3个要素来描述,分别为最近一次消费(Recency)、消费频率(Frequency)、消费金额(Monetary)[3]。其中,R表示用户最近一次消费的时间间隔,时间越短,用户对企业的服务或产品响应越快;F表示在限定时间内用户消费的次数,消费的次数越多,用户的活跃度就越高;M表示用户限定时间段内的消费金额,也是企业利润的来源,消费金额越高,用户价值也越高[4]。
一般而言,企业利用最近一次消费时间与消费频率来衡量用户的流失情况,利用消费金额作为判断用户价值的主要指标,依据三个要素的不同组合关系,将用户分为不同类型以采用不同的管理模式进行管理。例如李飞、王高[5]等根据RFM指标,对一家购物中心的交易数据进行了实证分析,表明RFM指标可以有效分析顾客的消费行为与顾客价值,对企业的顾客管理有积极的实践意义。Khajvand M[6]等利用RFM三个指标对企业用户进行细分,确认针对不同类型用户进行服务定制可以提高用户忠诚度,并能够通过消耗最小的成本实现高价值用户保有率。刘朝华[7]等分析了用户分类与用户关系管理的关系,基于RFM评价了用户分类的价值评价模型,为每类用户价值的相对大小提供了技术手段。在电信行业,肖旭[8]考虑了RFM指标的不同权重,应用K-均值聚类法对用户进行了分类,并比较了各类用户的终身价值,证实了RFM指标分类的有效性。上述研究表明,RFM作为用户分类指标,在各个研究与实践中得到了充分的运用,但大多数研究都专注于RFM的指标权重分析,并未充分挖掘RFM在实践中的实际意义,RFM作为分类的基础与实际应用,有待进一步探索。
而在电信用户的关注上,聚类分析是常用的分析方法。K-means聚类、因子分析都曾运用在电信用户的分类关系上,但这类方法均基于自身存在一定的缺陷。与此同时,潜在类别模型这一类统计分类方法正在逐步得到运用,研究者利用可以测量的外显变量来对潜在的类别进行分析[9,10]。随着研究的深入,通过对用户特征的分析,来发现隐藏在模型背后的用户类别变量,以此达到用户分类的目的。这类潜在类别分析的方法在国外已取得了大量的理论与实践成果。而国内的研究目前主要应用在心理学[11]与医学行业[12],对于电信行业来说,目前鲜少有文献利用潜在变量对用户进行分类研究。
综上所述,本文将RFM要素与潜在类别模型方法应用于信用分类的研究尚属空白,考虑到RFM要素与潜在类别模型在用户分类中的优势,本文拟将两者结合起来,对电信用户进行分类研究,以探索不同用户群体的差异性,为电信运营商在用户管理上提供支持。
2 电信用户潜在类别分类建模
潜在变量模型(Latent Variable Model)是讨论潜在变量模型化分析的一种统计方法,其中主要涉及两类变量——不可直接测量的潜在变量和可直接观察测量的外显变量。根据潜在变量与外显变量是否连续可将潜在变量模型分为不同类别。当潜在变量和外显变量均为类别型时,称为潜在类别模型(Latent Class Model)。潜在类别分析(Latent Class Analysis)是通过潜在类别变量来解释外显变量之间的联系,使外显指标之间的关联能够通过潜在类别变量来估计,进而保持其局部独立性的分析方法。
2.1 潜在类别模型基本原理
典型的潜在变量模型的统计原理建立在条件概率与贝叶斯分析之上。典型的LCM通常由一个或多个潜在类别变量和多个外显变量组成。对于电信用户数据,假设现在一个具有T个潜在变量的X可以解释N个外显变量Y(Y=Y1,Y2,…,YN)之间的关系,且每个外显变量Yn拥有不同的水平数Mn。
根据条件概率的基本性质,LCM有两个应满足的基本假设,一是各潜在类别的概率总和为1,如式(1)所示:
二是由于潜在变量下的各水平Mn中的各外显变量完全互斥且独立,因此各外显变量在各潜在类别内条件概率总和为1,如式(2)所示:
其中,P(X=t)表示电信用户属于潜在类别t的概率,即潜在类别概率;P(Yn=mnX=t)表示第t个类别中的用户在第n个外显变量上取值为m的条件概率(mn=1,2,…,Mn)。
根据全概率公式,则:
其中,P(Yn=mn)表示边际概率,表示用户在第n个外显变量上取值为mn的概率。根据LCM中外显变量在每个潜在类别内相互独立的基本约束,则:
因此,电信用户的N个观测变量在潜在类别模型中的联合概率为:
其中,P(Y1=m1,…,YN=mN)表示观测数据中水平为{m1,…,mN}的组合占全部观察数据的比例。
最后,根据贝叶斯理论,计算每个用户分类到各潜在类别的后验概率,随后由属于各个后验概率大小判断该用户应归类的潜在类别。
其中,P(X=tY1=m1,…,YN=mN)表示某用户分类到某个潜在类别的后验概率,P(X=t)(Yn=mnX=t)表示用户分类到某个潜在类别的概率。
2.2 参数估计与模型拟合
LCM的参数估计就是要得到式(5)中P(X=t)和P(Yn=mnX=t)的值。为了满足潜在类别模型的基本假设,在进行参数估计时,各外显变量的条件概率中,会有一个是固定的。因此,各组潜在类别的待估计条件概率(待估计参数)为M-1,需要估计的概率参数总数为T(MN-N)+T-1。
本研究中参数估计的方法采用极大似然估计法,同时兼顾EM的稳定性与NR速度优点的情况下,在估计初期先以EM算法进行迭代,当接近收敛时,可应用NR算法运算[13]。
检验LCM模型拟合优度广泛采用的方法主要有似然卡方统计量检验(G2)、Pearson卡方检验(χ2)以及基于似然函数的信息准则评价指标AIC(Akaike Information Criterion)和BIC(Bayesian Information Criterion)。其中,AIC作为模型拟合优度检验指标时,多应用于估计参数较少、自由度较大的单纯模型,而当样本数较大且估计参数较少时,通常采用BIC指标,它们的指标值越小表明模型拟合的越好。一般情况下,会将几种主要指标进行结合来评价模型的拟合效果。
3 用户分类与结果分析
本文研究数据来源于中国移动运营公司某省2018年某月的样本数据,经过初步整理与统计处理,由于话费敏感度级别为0的用户不具备有效性,因此,在剔除0级话费敏感度用户后,得到数据共计49 985条。
3.1 外显变量的选取与RFM要素分类
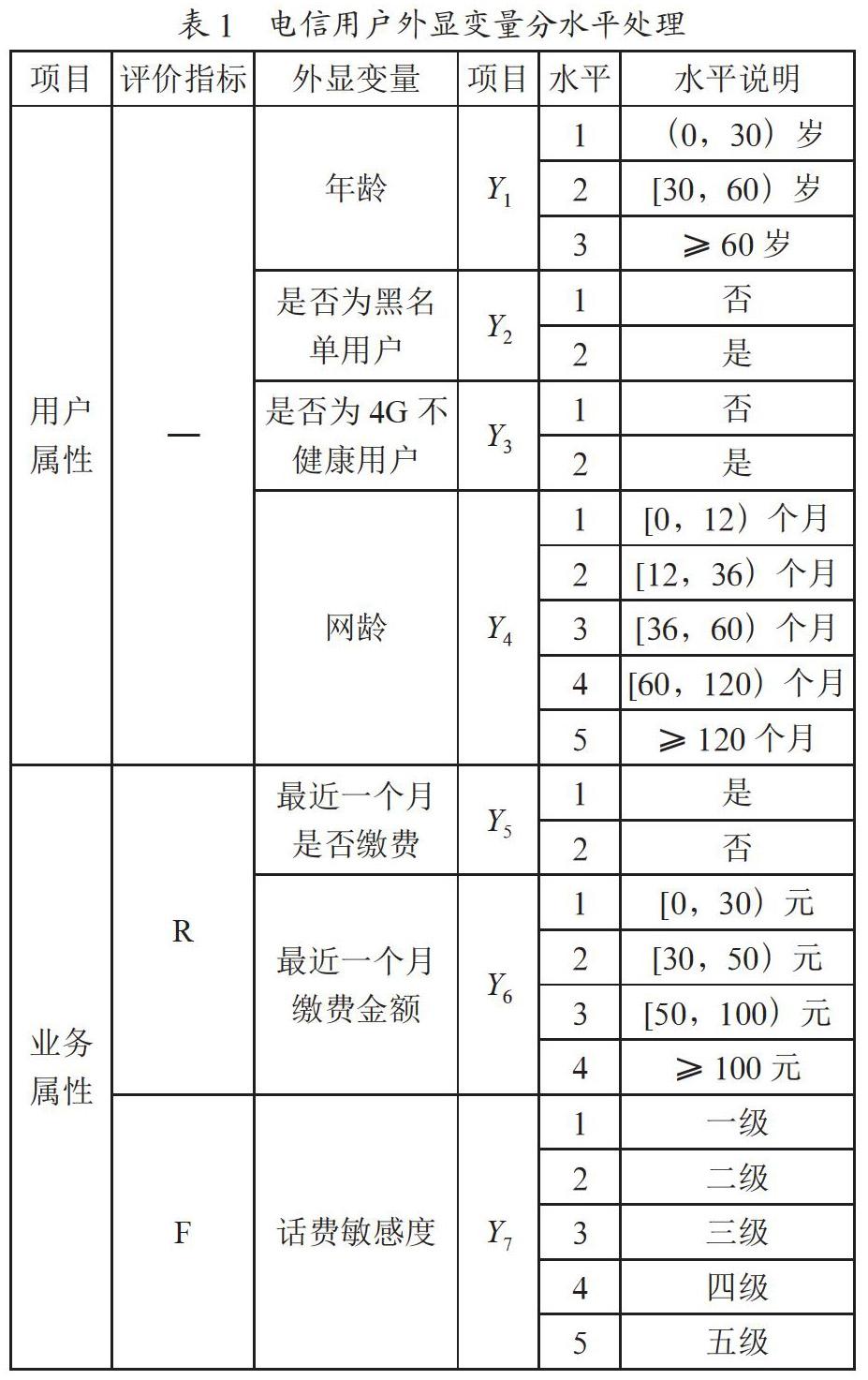
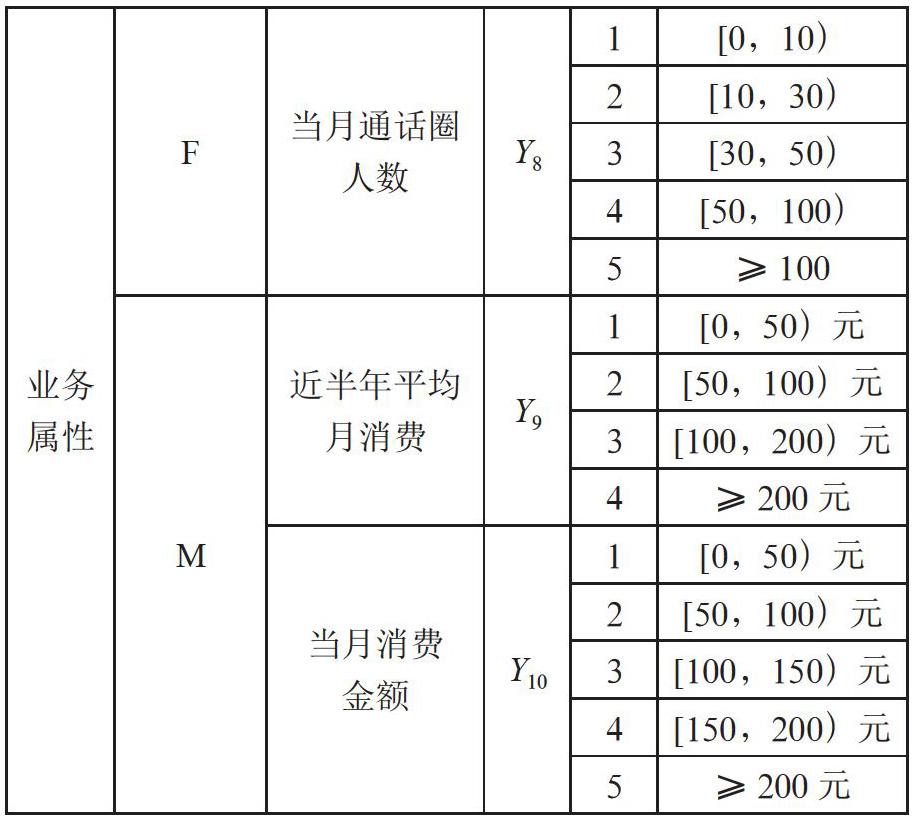
移动用户数据主要包括两个方面,一是用户属性,包括用户年龄、网龄、健康程度等;二是业务数据,包括缴费信息、消费信息、以及通话信息等。本研究主要从这两方面出发,选择用户年龄、是否为黑名单用户、是否为4G健康用户、最近一个月是否缴费、最近一个月缴费金额、近半年平均月消费、当月消费金额、话费敏感度、当月通话圈人数,9类影响因素作为外显变量,经过对数据的初步统计分析后,根据数据描述性统计结果对外显变量进行分水平处理,每个不同的数字表示外显变量的不同水平,外显变量的定义与水平分类如表1所示。
根据传统的RFM模型,三个常用的评价指标分别是近度(Recency)、频度(Frequency)、值度(Monentary)。近度指用户最近一次消费的时间,但对于电信用户来说,消费无时无刻不在进行,间隔时间无法准确获取;而就一段时间内消费的次数而言,用户很有可能在某一时间持续通话,时间段内的消费次数无法统计。因此,传统的RFM模型不能很好地分析电信用户,本文从用户当月缴费角度出发,以用户最近一个月是否缴费及缴费金额来表示近度;而由于用户对话费的敏感程度与当月通话人数都会对用户的缴费频率产生影响,因此选用这两个变量来表示频度,值度则用半年的月平均消费及当月消费金额表示。
3.2 模型评价与参数估计结果
从假设潜在类别个数为开始,逐步增加潜在类别个数,分别求解并对各个模型进行拟合优度检验,研究中共拟合了7个潜在类别模型,表2表示各个模型的拟合优度检验结果。
从表2中可以看出,随着潜在类别个数的增加,AIC、BIC、G2、χ2四个指标均在减小,但当潜在类别数从6开始,四个指标下降的幅度变得很小。因此,选择包含6个潜在类别的模型最为合适。
本研究中,使用R语言对最优模型参数进行估计,设置潜在类别个数T=6,表3表示了潜在类别概率与各个外显变量的条件概率。可以看出,不同潜在类别群体在各个外显变量上的差异比较明显,尤其是业务属性方面,表明业务属性的外显变量是分类的主要影响因素。从表中可以看出,第2、3、5类的潜在类别概率较大,分别为0.269、0.245、0.298,最小的是第4类,概率为0.076,其次是第1类和第6类,概率分别为0.096和0.115。
3.3 不同潜在类别用户特征分析
结合潜在聚类的结果与外显变量的特征,我们可以看出,第一类用户的4G不健康比例最高,网龄普遍在一年以内且单次缴费金额少,但月消费较高;第二类用户入网时间在3~5年的比例最高,超过99%的用户在最近一个月没有缴费且单次缴费的金额较低,月均消费稳定在50元~100元,通话圈人数在30~50人之间;第三类用户以30岁以下的青年人为主,超过99%的用户在最近一个月没有缴费且单次缴费的金额在50元~100元,月消费金额较高,当月通话圈人数较多且对话费敏感度集中在2~3级;第4类主要为中年用户,他们中黑名单用户的比例最高,超过一半入网时间大于10年,最近一个月消费金额大于100元的比例最高,月均消费值与当月话费值均较高,其中多数用户当月通话圈人数超过100人,且话费敏感度集中在1级;第五类用户以中老年人居多,但他们中超过93%是4G健康用户,且入网时间在1~2年,绝大多数月均消费值与当月总费用不超过50元,当月通话圈人数少于30人,话费敏感度集中在4~5级;第6类用户中4G健康用户的比例最高,他们最近一个月都有缴费但缴费金额低于30元。因此,根据各潜在类别的用户特征,可以将6类用户分别命名为临时型、低值型、传统型、公务型、佛系型和稳定型。不同类别用户的RFM指标特征如图1所示。
从分析图中可以看出,公务型用户的显著特征表现为月均消费与当月消费都超过200元,通话圈人数多数超过100人次且对话费变化非常敏感,消费金额M最高,属于高价值用户,在管理上应着重关注他们的需求,对他们所关注的话费价格与是否为黑名单用户给予一定的优惠措施;其次,对于青年人最为集中的传统型也应给予相对较高的关注,他们虽然并非在最近一个月都有缴费,但每个月的消费水平并不低,都在100~200的区间内,并且他们的话费敏感程度为二级,因此,这类用户有一定的流失风险,应在其所关注的话费高低上着重管理;对于低值型与稳定型用户,也应给予一定的关注度,他们月均消费虽然不高,但是基本每个月都会消费且相对稳定,他们对话费变化并不是很敏感,属于忠诚度较高的用户;最后是临时型与佛系型用户,临时型用户可能某个特殊的时间段消费水平会相对较高,但并不稳定,佛系型用户虽然稳定性较好,不会轻易流失且市场占比最高,但每个月的消费水平低,用户价值不高。
4 结 论
本文在传统RFM分析要素的基础上,结合电信行业特点,提出了用潜在类别模型的方式对电信用户进行分类,利用潜在变量的分类方式更充分的分析了用户的各项数据,描述各类用户的行为特征,对用户关系管理提供强有力的决策支持,为运营商在用户资源竞争中提供优势。以中国移动的实际数据为例,通过分析用户最近消费特征将其分为6个大类,分析各类用户概率与消费特点。结果表明,各类用户群体在移动通话、消费等方面有显著差异。其中,公务型与传统型用户的价值较高,需要管理者长久关注,建议运营商针对不同的分类群体进行精确管理,进行个性化的管理服务。
本文的研究目的是将电信用户分为不同的类别进行消费和行为特征分析,对于影响用户消费高低的因素尚未展开讨论,下一步研究中考虑分析各类别中用户自身属性、缴费行为、话费敏感度等因素对消费行为影响大小,以进一步讨论用户价值。
参考文献:
[1] 陈治平,胡宇舟,顾学道.聚类算法在电信客户细分中的应用研究 [J].计算机应用,2007(10):2566-2569.
[2] AHN H,AHN J J,OH K J,et al. Facilitating cross-selling in a mobile telecom market to develop customer classification model based on hybrid data mining techniques [J].Expert Systems with Applications,2011,38(5):5005-5012.
[3] MIGLAUTSCH J R. Thoughts on RFM scoring [J].Journal of Database Marketing & Customer Strategy Management,2000,8(1):67-72.
[4] 张虎,王国华,郑文芳.基于MaxDiff和潜在类别分析的移动支付客户细分研究 [J].数理统计与管理,2017,36(3):506-517.
[5] 马宝龙,李飞,王高,等.随机RFM模型及其在零售顾客价值识别中的应用 [J].管理工程学报,2011,25(1):102-108.
[6] KHAJVAND M,ZOLFAGHAR K,ASHOORI S,et al. Estimating customer lifetime value based on RFM analysis of customer purchase behavior:Case study [J].Procedia Computer Science,2011,3:57-63.
[7] 刘朝华,梅强,蔡淑琴.基于RFM的客户分类及价值评价模型 [J].技术经济与管理研究,2012(5):33-36.
[8] 林盛,肖旭.基于RFM的电信客户市场细分方法 [J].哈尔滨工业大学学报,2006(5):758-760.
[9] 刘建荣,刘志伟.基于出行者潜在类别的公交出行行为研究 [J].华南理工大学学报(自然科学版),2019,47(6):119-126.
[10] 乔珂,赵鹏,文佳星.基于潜在类别模型的高铁旅客市场细分 [J].交通运输系统工程与信息,2017,17(2):28-34.
[11] 刘志伟,刘建荣,邓卫.基于潜在类别的无人驾驶汽车选择行为 [J/OL].吉林大学学报(工学版):1-6[2020-11-04].https://doi.org/10.13229/j.cnki.jdxbgxb20200390.
[12] 曾宪华,肖琳,张岩波.潜在类别分析原理及实例分析 [J].中国卫生统计,2013,30(6):815-817.
[13] 邱皓政.潜在类别模型的原理与技术 [M].北京:教育科学出版社,2008.
作者简介:彭宜丹(1995—),女,汉族,湖北宜昌人,硕士研究生在读,研究方向:工商管理;刘洪伟(1962—),男,汉族,广东广州人,教授,博士生导师,博士,研究方向:信息系统,商务智能,移动商务;高鸿铭(1993—),男,汉族,广东广州人,博士研究生在读,研究方向:管理科学与工程。