
DOI:10.19850/j.cnki.2096-4706.2021.09.018
摘 要:文章设计一种用于识别企业营业执照图像的算法,其可自动提取统一社会信用代码、公司名称等关键字段信息。以开源PaddleOCR框架为基础,通过图像方向自动调整、文本输出结构化、局部二次识别等一系列改进措施,解决了多种图片质量不佳情况下仅通过PaddleOCR无法准确识别信息的问题,整体识别准确率提升至90%以上,且实现秒级检测。该成果已投入实际使用,辅助前台操作人员快速识别所填写的营业执照信息是否准确,提高人工录入效率。
关键词:PaddleOCR;图像识别;企业营业执照;AI
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2021)09-0065-06
Improvement and Practice of Open Source PaddleOCR Technology in Enterprise Business License Recognition
QIU Jianmin
(China Telecom Corporation Limited Jiangsu Branch,Nanjing 210037,China)
Abstract:In this paper,an algorithm for recognizing the enterprise business license image is designed,which can extract automatically the unified social credit code,company name and other key field information. Based on the open source PaddleOCR framework,through a series of improvement measures,such as image orientation automatic adjustment,structured text output,local secondary recognition,the problem that information cannot be accurately recognized only by PaddleOCR under the situation of several kinds of poor image quality is solved,the overall recognition accuracy is improved to more than 90%,and second level detection is realized. This achievement has been put into the actual use to assist the front desk operators to quickly identify whether the business license information filled in is accurate or not,and improve the efficiency of manual entry.
Keywords:PaddleOCR;image recognition;enterprise business license;AI
0 引 言
本文在开源PaddleOCR框架[1]的基础上,设计AI算法自动提取统一社会信用代码、公司名称等关键字段信息。通过一系列改进措施,在PaddleOCR无法准确识别多种质量不佳图片的情况下依然能够准确识别图中关键信息,并实现秒级检测,该成果已投入实际生产系统使用。适合从事图像识别相关工作的人员共同研究讨论。
1 背景
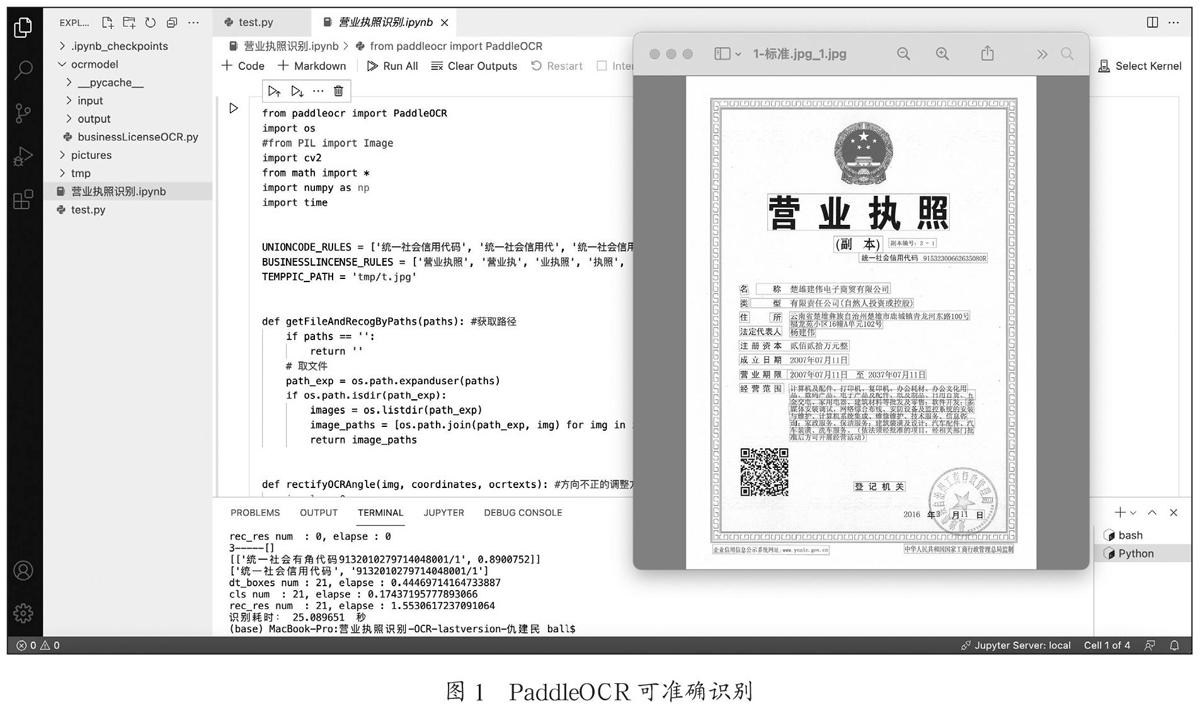
早前,营业员在营业系统中登记企业营业执照信息时均通过人工查看之后手动录入系统,为提升人工录入效率,需设计AI算法,自动提取营业执照中统一社会信用代码、公司名称等关键字段信息[2]。PaddleOCR是由百度公司开源的超轻量OCR(Optical Character Recognition)系统,主要由DB文本检测[3]、检测框矫正[4]和CRNN文本识别[5]三部分组成。通过PaddleOCR能够实现文本的检测与识别,正常识别的图片如图1所示。
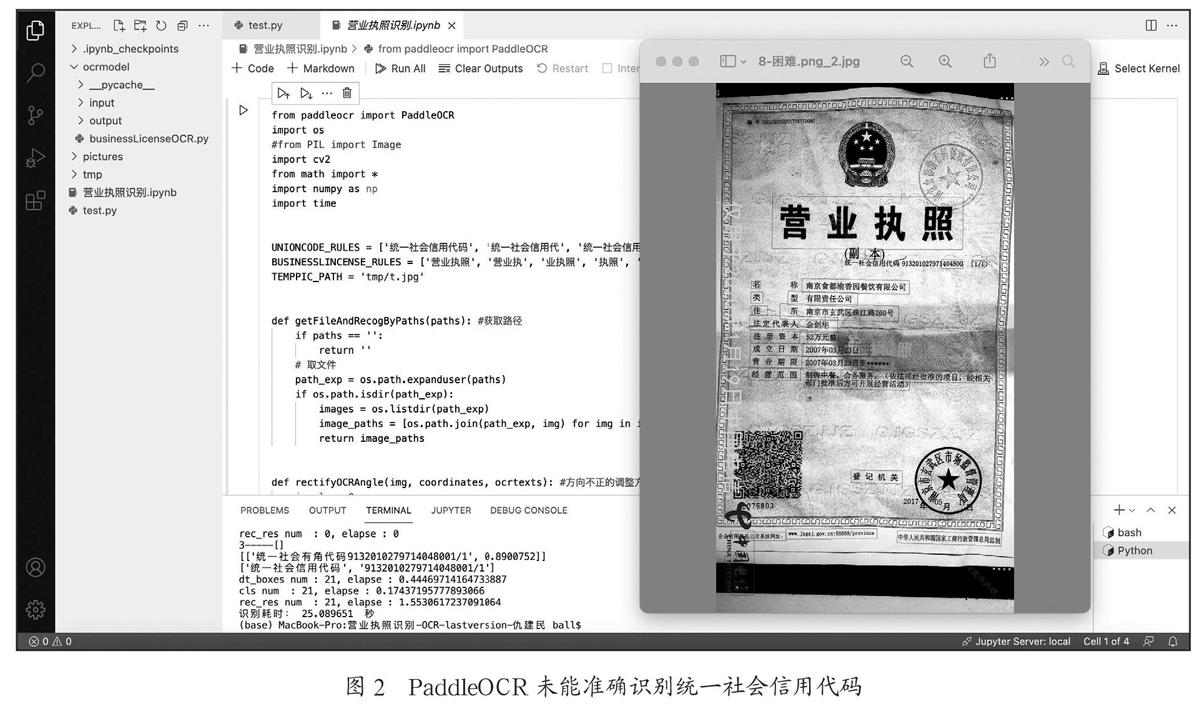
但是当图片存在低亮度、角度歪曲、光照不均、阴影遮挡、水印覆盖、印章覆盖等情况时,PaddleOCR均未能完整准确地识别出关键信息。未能正常识别的图片如图2所示。本文需重点解决以上复杂情况下的文字识别问题。
2 目标
在PaddleOCR源码基础上,通过补充自定义算法,包括增加图像方向自动调整、文本输出结构化、局部二次识别等技术,解决以上诸多复杂情况下文字识别不准确的问题,将营业执照关键信息的识别准确率由70%提升至90%。
3 改进举措
3.1 自动调整图像方向
因为原始营业执照图像可能方向不正、角度不正,需统一将图像方向调整为竖直方向,增强文字识别的连贯性。做法为:由于营业执照中“营业执照”这四个字的位置相对清晰,PaddleOCR基本均能识别出来,在识别出“营业执照”四个字的基础之上,增加一段代码,定义为函数rectifyOCRAngle,用来判断营业执照的字在图片中的哪个位置:在整体上1/3就认为是上面,在下1/3就认为是下面;在左1/3就认为是左边;在右1/3就认为是右边。进而根据判断结果进行旋转,将图像旋转至竖直方向。rectifyOCRAngle函数代码为:
defrectifyOCRAngle(img, coordinates, ocrtexts):
iangle = 0
idx = -1
sp = img.shape
width = sp[1]
height = sp[0]
foriin range(len(BUSINESSLINCENSE_RULES)):
for j in range(len(ocrtexts)):
idx_find = str(ocrtexts[j][0]).find(BUSINESSLINCENSE_RULES[i])
ifidx_find> -1:
idx = j
break
ifidx> -1:
break
ifidx == -1:
returnidx, img, coordinates, ocrtexts
x_center = coordinates[idx][0][0] + (coordinates[idx][1][0] - coordinates[idx][0][0])/2.0
y_center = coordinates[idx][0][1] + (coordinates[idx][3][1] - coordinates[idx][0][1])/2.0
transposedImage = cv2.transpose(img)
widthper = width / x_center
heightper = height / y_center
ifwidthper1.5:# 正面或下面
ifheightper>2:
angle = 0
else:
img = cv2.flip(img, -1);
for j in range(len(coordinates)):
coordinates[j][0][0] = width - 1 - coordinates [j][0][0]
coordinates[j][0][1] = height - 1 - coordinates [j][0][1]
coordinates[j][1][0] = width - 1 - coordinates [j][1][0]
coordinates[j][1][1] = height - 1 - coordinates [j][1][1]
coordinates[j][2][0] = width - 1 - coordinates [j][2][0]
coordinates[j][2][1] = height - 1 - coordinates [j][2][1]
coordinates[j][3][0] = width - 1 - coordinates [j][3][0]
coordinates[j][3][1] = height - 1 - coordinates [j][3][1]
pt1 = coordinates[j][0]
coordinates[j][0] = coordinates[j][2]
coordinates[j][2] = pt1
pt2 = coordinates[j][1]
coordinates[j][1] = coordinates[j][3]
coordinates[j][3] = pt2
print(coordinates)
angle = 180
else: # 左边或右面
略(可类比前一段代码:正面或下面)
returnidx, img, coordinates, ocrtexts
调节前后的对比图示例如图3所示。
3.2 文本输出结构化
在真实的营业执照图片中,统一社会信用处存在“(1/1)”“副本编码”等额外的非相关文本,根据业务统一规范,利用正则表达式定义函数UnionCodeSechema,用于提取出18位标准代码,删除括号等多余的文本,确保统一社会信用代码准确。UnionCodeSechema函数代码为 :
defUnionCodeSechema(sUnionCode,coordinates,iUnionCode):
i_tmp = sUnionCode.find(()
ifi_tmp> -1:
sUnionCode = sUnionCode[0:i_tmp]
foriin range(len(sUnionCode)):
if (sUnionCode[i] >= 0andsUnionCode[i] = AandsUnionCode[i] <= Z):
continue
else:
sUnionCode = sUnionCode[0:len(sUnionCode)]
break
iflen(sUnionCode) >= 18:
sUnionCode = sUnionCode[0:18]
else:
pass
returnsUnionCode
统一社会信用代码存在多余文字的示例如图4所示。
图4 统一社会信用代码存在多余文字的示例
3.3 局部二次识别
通过分析原始PaddleOCR识别不准确的案例,发现90%识别不准确都是由于识别出来的文字不完整,当原始图片出现亮度低、角度歪曲、光照不均、阴影遮挡、水印覆盖、印章覆盖等情况,往往会导致直接识别的结果有缺失。为此,我们提出局部二次识别的解决办法。针对各种识别结果局部缺失的情况,将识别不准确的局部图片单独提取出来进行二次单独识别,减少了整张图片的背景干扰,再将局部二次识别出来的结果拼接至首次PaddleOCR识别结果中,从而极大地提升识别的准确率。需要局部二次识别的场景为:
(1)针对统一社会信用代码:
1)前面的字识别出了,后面的编码未识别出或者识别不完整:根据字的定位,提取后面区域的图像进行二次识别,识别出编码。
2)后面的编码识别出了,前面的字未识别出或者识别不完整:根据编码的定位,提取前面区域的图像进行二次识别,识别出字。
3)前面的字未识别出或者识别不完整,后面的编码也未识别出或者识别不完整:根据营业执照和公司名称的位置,估算统一社会信用代码的位置和范围,提取出该段区域进行二次识别,识别出编码。
(2)针对公司名称:
1)前面的字识别出了,后面的公司名称未识别出或者识别不完整:根据字的定位,提取后面区域的图像进行二次识别,识别出公司名称。
2)后面的公司名称识别出了,前面的字未识别出或者识别不完整:根据公司名称的定位,提取前面区域的图像进行二次识别,识别出字。
3)前面的字未识别出或者识别不完整,后面的公司名称也未识别出或者识别不完整:根据营业执照和统一社会信用代码的位置,估算公司名称的位置和范围,提取出该段区域进行二次识别,识别出公司名称。
其中,营业执照识别出的文字满足以下条件之一即可定位:[营业执照, 营业执, 业执照, 执照, 营业]);统一社会信用代码识别出的文字满足以下条件之一即可定位:[统一社会信用代码, 统一社会信用代, 统一社会信用, 统一社会信, 统一社会, 统一社, 社会信用代码, 信用代码, 代码];公司名称识别出的文字满足以下条件之一即可定位:[名称,名,称]。
自定义函数secOCRRecog,用于二次识别,自定义函数TextSechema,用于判断需要二次识别的情况并调用secOCRRecog,代码分别为 :
defsecOCRRecog(self, img, type):
cv2.imwrite(TEMPPIC_PATH, img)
if type == 3:
ocrresult = self.ocrModel.ocr(TEMPPIC_PATH, det=True, rec=True, cls=True)
print(3----- + str(ocrresult))
b_find = False
sp = img.shape
width = sp[1]
height = sp[0]
foriin range(len(ocrresult)):
if (len(ocrresult[i][1][0]) >0):
s_search = re.search(r\d{8}, ocrresult[i][1][0])
ifs_search:
b_find = True
x = int(ocrresult[i][0][0][0])
y_dis = int(ocrresult[i][0][3][1] - ocrresult[i][0][0][1])
y = int(ocrresult[i][0][0][1])
if x > (width // 2):
cropped = img[y:(y + y_dis), int(width / 2):(width - 20), :]
else:
cropped = img[y:(y + y_dis), 20: int(width / 2), :]
ret_tmp = self.secOCRRecog(cropped, 1)
returnret_tmp
ifb_find == False:
cropped = img[(height // 4):(height - height // 4), 30: (width - 30), :]
ret_tmp = self.secOCRRecog(cropped, 1)
print(ret_tmp)
ifret_tmp:
returnret_tmp
else:
cropped = img[(height // 6):(height - height // 2), 30: (width - 30), :]
ret_tmp = self.secOCRRecog(cropped, 1)
ifret_tmp:
returnret_tmp
else:
cropped = img[(height // 2):(height - height // 6), 30: (width - 30), :]
ret_tmp = self.secOCRRecog(cropped, 1)
returnret_tmp
elif type == 1or type == 2:
略(类比前一段代码iftype == 3,继续完成type == 1和type == 2)
defTextSechema(self, img, coordinates, ocrTexts, icode):
ls_ret = []
b_find = False
sp = img.shape
width = sp[1]
height = sp[0]
foriin range(len(UNIONCODE_RULES)):
for j in range(len(ocrTexts)):
ifocrTexts[j][0].find(UNIONCODE_RULES[i]) > -1:
iflen(ocrTexts[j][0]) >10:
s_search = re.search("\d", ocrTexts[j][0])
i_tag = s_search.start()
ls_ret.append([统一社会信用代码, UnionCodeSechema (ocrTexts[j][0][i_tag:], coordinates, j)])
b_find = True
else:
略
ifb_find == False:
print(coordinates[j])
x = int(coordinates[j][0][0])
y = int(coordinates[j][0][1])
y_dis = int(coordinates[j][3][1] - coordinates[j][0][1])
cropped = img[y:(y + y_dis), x:(x + int(width / 2) + 20), :]
ret_tmp = self.secOCRRecog(cropped, 1)
ifret_tmp:
ls_ret.append([统一社会信用代码, UnionCodeSechema (ret_tmp[1], coordinates, j)])
b_find = True
for j in range(len(ocrTexts)):
if (len(ocrTexts[j][0]) == 2andocrTexts[j][0] == 名称and (
(j + 1
ls_ret.append([名称, ocrTexts[j + 1][0]])
i_name = j + 1
break
eliflen(ocrTexts[j][0]) == 1andocrTexts[j][0] == 称andlen(ocrTexts[j + 1][0]) >2:
ls_ret.append([名称, ocrTexts[j + 1][0]])
i_name = j + 1
break
elif (len(ocrTexts[j][0]) >1) and (ocrTexts[j][0][0] == 称):
ls_ret.append([名称, ocrTexts[j][0][1:]])
i_name = j
break
elif (len(ocrTexts[j][0]) >2) and (ocrTexts[j][0][0] == 名) and (ocrTexts[j][0][1] == 称):
ls_ret.append([名称, ocrTexts[j][0][2:]])
i_name = j
break
elif (ocrTexts[j][0].find(名称) > -1) and (len(ocrTexts[j][0]) >2):
ls_ret.append([名称, ocrTexts[j][0]])
i_name = j
break
elif (ocrTexts[j][0] == 名) and ((j + 2)
ocrTexts[j + 1][0][0] != 称):
ls_ret.append([名称, ocrTexts[j + 1][0]])
i_name = j + 1
break
elif (ocrTexts[j][0] == 名) and ((j + 1)
i_name = j
print(coordinates[j])
x = int(coordinates[j][0][0])
y = int(coordinates[j][0][1])
y_dis = int(coordinates[j][3][1] - coordinates[j][0][1])
cropped = img[y:(y + y_dis), x:(x + int(width / 2) + 150), :]
ret_tmp = self.secOCRRecog(cropped, 2)
ifret_tmp:
ls_ret.append(ret_tmp)
break
if (b_find == False) and (i_name> -1):
print(营业执照位置 + str(coordinates[icode]) + \n)
print(名称 + str(coordinates[i_name]) + \n)
x = int(20)
y = int(coordinates[icode][3][1] + 3)
y_ = int(coordinates[i_name][0][1] - 6)
if y < y_:
cropped = img[y:y_, x: (width - 20), :]
else:
cropped = img[y_:y, x: (width - 20), :]
ret_tmp = self.secOCRRecog(cropped, 3)
ifret_tmp:
ls_ret.append(
[统一社会信用代码, UnionCodeSechema (ret_tmp[1], coordinates, icode)])
returnls_ret
针对前面章节中的图2,PaddleOCR识别结果不完整,通过增加局部二次识别,补充识别出完整的统一社会信用代码,示例对比如图5所示。
4 结果及应用情况
使用完整的代码识别773张样本,最终识别结果准确率超过90%,分析识别失败的案例,基本是由于文字中存在生僻字,导致文本识别不准确。识别失败的案例如图6所示。
得益于PaddleOCR的轻量化模型部署,识别图像的速度较快,新增的代码仅仅针对需要二次识别的部分才会进行二次识别。经实际测验,使用CPU机器识别单张营业执照,约1~3秒钟可出结果;使用GPU机器识别单张营业执照,约0.5~1秒钟可出结果。整体识别准确率和效率均达预期。因此将本模型部署至实际生产系统,用于营业人员在前台录入营业执照信息时进行自动识别,提升了人工录入效率。
5 结 论
本文在开源PaddleOCR框架基础上,对代码进行了相应的改进和完善,解决了PaddleOCR无法准确识别复杂场景下的营业执照的问题,并将模型顺利部署至实际生产系统,帮助前台营业人员自动录入营业执照关键信息,具有较好的经济效益。后续可以继续以PaddleOCR框架为基础,增加生僻字的fine turning,继续提升识别准确率。
参考文献:
[1] DU Y N,LI C X,GUO R Y,et al. PP-OCR:A Practical Ultra Lightweight OCR System [J/OL].arXiv:2009.09941 [cs.CV].(2020-09-21).https://arxiv.org/abs/2009.09941v3.
[2] 邵慧敏.营业执照自动识别技术的研究 [D].乌鲁木齐:新疆农业大学,2020.
[3] LIAO M H,WAN Z Y,Yao C,et al. Real-Time Scene Text Detection with Differentiable Binarization [J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):11474-11481.
[4] YU D L,Li X,ZHANG C Q,et al. Towards Accurate Scene Text Recognition With Semantic Reasoning Networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle:IEEE,2020.
[5] LI W,CAO L B,ZHAO D Z,et al. CRNN:Integrating classification rules into neural network[C]//The 2013 International Joint Conference on Neural Networks(IJCNN).Dallas:IEEE,2013.
作者简介:仇建民(1988.06—),男,汉族,江苏扬州人,中级工程师,本科,研究方向:IT系统建设与运维、大数据平台、数据仓库、AI开发与应用(文本分类、图像识别)等。
收稿日期:2021-04-06