摘 要:文章通过对数据治理技术的研究,从技术现状、技术发展和数据质量需求方面剖析了其在设计、应用方面的瓶颈,提出了一种适用于石油行业的数据模型结构设计和管理方式,并基于数据模型提供线下数据汇总、数据校验、数据采集配置等数据采集方法、数据集成方法。最后结合应用场景介绍在应用系统实施过程中遇到的难点与所提出的相应解决方案,包括关系型数据库数据及物理文件数据的采集域同步。
关键词:数据治理;数据采集;数据交换
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)12-0162-03
Abstract: Through the research on data governance technology, this paper analyzes its bottlenecks in design and application from the aspects of technical status, technical development and data quality requirements, puts forward a data model structure design and management mode suitable for the petroleum industry, provides data collection methods and data integration methods such as offline data summarization, data verification and data collection configuration based on data model. Finally, combined with the application scenario, the difficulties encountered in the implementation of the application system and the corresponding solutions are introduced, including the collection domain synchronization for relational database data and physical file data.
Keywords: data governance; data collection; data exchange
0 引 言
数据治理是企业步入信息化的基础,研究数据治理技术的目的是为信息应用提供安全的数据通道,通道的起点是企业各种业务系统自动或手工产生的数据,通道的终点是基于信息的各种应用,通道的中间段是数据仓库。当前国内基于数据治理技术的研究不断深入,但采集、存储、集成一直是数据治理的核心需求,石油企业的数据管理员在采用通用数据处理工具时,常常会因为业务功能不匹配而造成数据集成配置任务非常繁重甚至无法满足需求,成为数据治理的瓶颈。
1 数据治理技术
数据治理包括数据采集、数据存储、数据集成三个关键点,管理人员的数据转换配置工作主要集中于数据采集和数据集成,需要解决的突出问题有两点:其一是需要设计结构合理的数据模型存储结构,方便进行集成交换和应用;其二是数据集成需要兼顾各种数据交换的需求,提供充分的数据转换方式和便利的人机交互配置,达到数据仓库与集成系统转换可配置、管理可分开的目标。
1.1 数据模型管理
构建数据模型的目标是为数据仓库定义一个大而全的数据结构,由分类表、属性表及数据表组成,属性表和数据表均通过分类表id寻址类型,数据表采用Json格式记录值,其优势体现在三个方面:(1)数据按调用频率分表,前端查看分类和属性的速度明显加快;(2)存取数据值时充分利用了根据Json字段对数据库进行检索的技术;(3)三个表仅通过id关联,业务层对编码或名称修改互补影响,用户可编辑修改与数据表关键项分开,减少对数据库表的关联修改。
1.2 数据采集技术
根据原始数据的多样性需求设计适用的采集方案,将数据采集到数据仓库,常规表数据的采集可以基于原值获取、字典转义、条件取值、自定义值等方法,本文着重介绍对层级路径和文件表的采集方式,以下是解决方案。
1.2.1 层级路径
例如一个数据源表是一个树式表,即下一行数据是上一行数据的子集,需要采集子集id、父级id或层级路径,线下数据录入员习惯将子集数据写在父集数据行的下面,通常不会特别标注第几行是第几行的子集,甚至位于同一列的内容若与上一行相同则会省略不写,将数据采集到数据仓库需要将所采集的数据自动生成编码id、隶属的父级id、层级路径,因此在配置层级路径采集方式时,需要选中层级目录相关字段作为关键列,程序进行采集时逐行生成id,同时在内存中记录关键列,以便子集数据通过与内存中数据的对比找到隶属的父级id,构造出层级路径。
1.2.2 文件表采集
基于企业标准文件编码规范(例如文件名由设计阶段-文件类型-设备位号-序号组成),实现从一个物理文件目录下自动提取编码生成文件表,通过对编码的识别也可对目录和文件名进行校验。实现文件表采集,应首先保证对标准目录树管理和文档规则管理,其中文档规则定义了文档的名称,包括几段编码,例如文件编码、文件描述、版本号三段编码,每段编码由哪些项和分隔符等组成;目录树管理则定义了一棵囊括企业所有目录层级的标准树,目录树节点与文档规则一一对应,在采集配置时,只要选择本地文件夹下的某级主目录,其下的子目录和文件即可以参数化的方式自动提取出分类文件表写入数据模型。
1.3 数据集成技术
数据集成是通过配置将数据仓库内的数据进行转换并提交目标系统,提供用户便利的配置源与目标的转换关系。
1.3.1 数据分组
是指将目标表分组,分组的原值包括按导入顺序分组、按源相似性分组、按使用性质分组。当某目标表的导入数据依赖于或需要查询其他已导入数据表时,因导入存在先后顺序即需要进行分组,以便用户在数据同步时可以根据分组名称按顺序操作;当多源导入同一目标时,应区分源的多样性中是否有不同的唯一判定字段或必填字段,系统在同步上传数据时依据统一设定的获取规则和校验规则会阻断不符合要求的数据,所以要求数据按源相似性分组后配置不同的规则;在系统运行时,有些目标表是为了写入而进行配置,而有些目标表用于转换过程中转义或是查表获取数据,用户应按使用性质进行分组管理。
1.3.2 导入配置
导入配置是完成对目标选择数据源的工作,选择匹配的源字段与目标字段对应,方法包括自动匹配和搜索匹配,当目标与源系统采用统一的名称编码时,自动匹配功能将有效减少配置时间,搜索匹配功能用于在源多表中通过关键字获得匹配项;当目标的获取方式为条件取值时,需要对设置的条件字段逐个匹配目标表中的字段。
2 技术应用实例
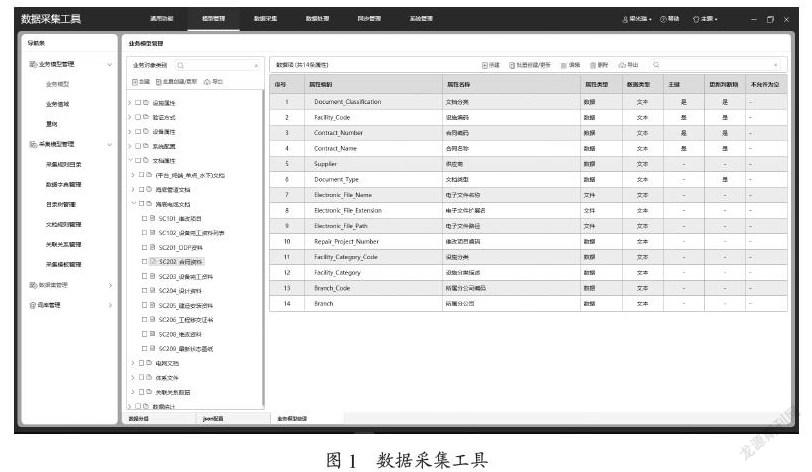
数据采集工具(DPT)是根据石油行业数据治理需求而开发出的一款专用系统,如图1所示,采用node.js框架开发,主要功能包括通用工具、数据模型、数据采集、数据归档、同步管理,实现对线下数据治理、线下数据校验清洗入库、入库数据的后处理、入库数据的集成交换。
2.1 数据采集系统
用户首先从系统中下载Excel格式采集模板,例如采集模板分为设施、设备、文档三大类,设备分类下包含发动机、注水泵等数百种设备的采集模板,在生产过程中可直接对新建项目应用采集模板填写数据,对已建项目,系统提供一系列通用功能将存量数据汇总至采集模板。
数据采集设置是对采集模板数据入库进行采集规则设置和校验规则设置,数据采集设置的方式包括原值获取、自动编码、条件取值、固定值、当前用户、当前时间等;校验方式包括文本、数值、百分比、日期、时间、序列、正则表达式、数据字典、文件路径、特殊项,其中文件路径验证用于物理文件的采集,验证条件是指定表数据内的路径、文件名称、扩展名,验证将要采集入库的文件是否在指定的文件夹中;特殊项可以指定验证条件为当前系统变量,如当前项目、当前工程等。
2.2 数据集成与数据同步系统
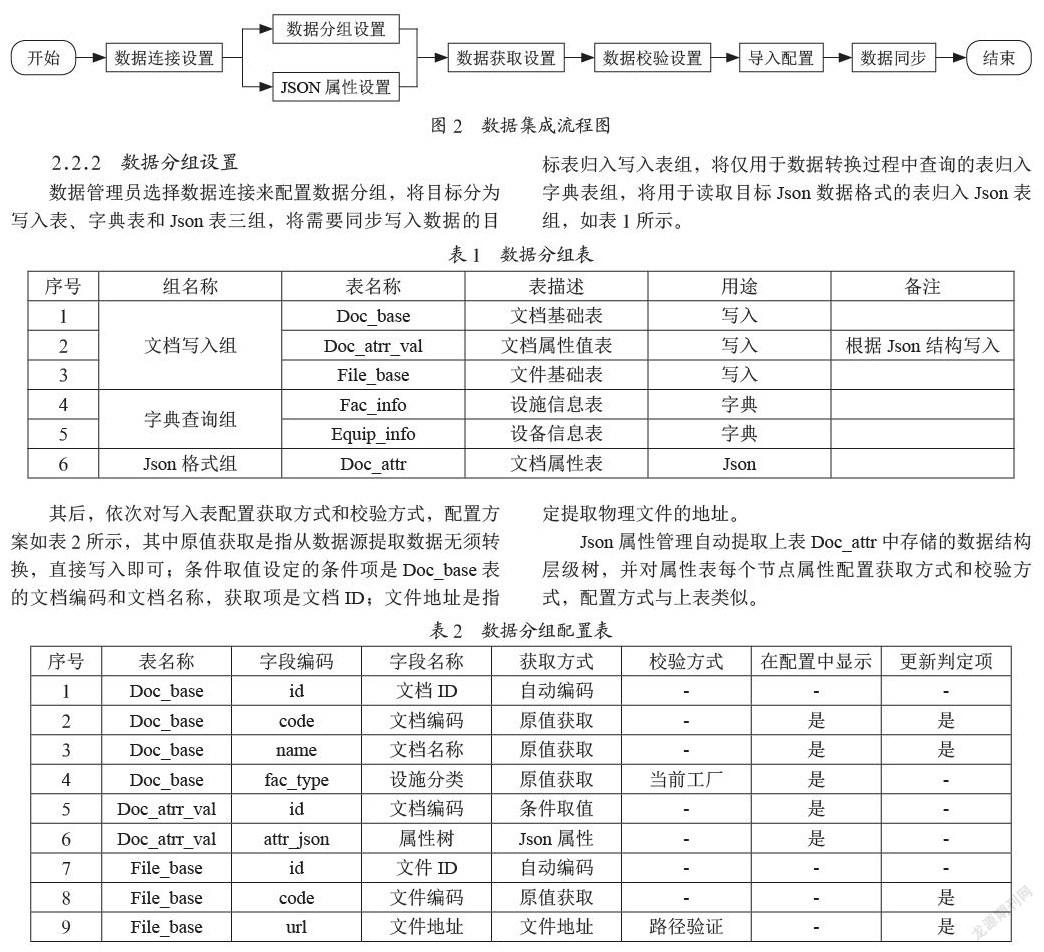
DPT以数据仓库为源负责向各种数据展示平台提供数据,将数据仓库数据结构转换成目标结构传送,其实现流程如图2所示。
2.2.1 数据连接设置
数据连接设置支持常用数据库和文件系统,包括MsServer、MySQL、Oracle数据库连接参数设置,FastDFS、MinIO文件系统参数设置,方便用户对目标连接参数进行集中管理。
2.2.2 数据分组设置
数据管理员选择数据连接来配置数据分组,将目标分为写入表、字典表和Json表三组,将需要同步写入数据的目标表归入写入表组,将仅用于数据转换过程中查询的表归入字典表组,将用于读取目标Json数据格式的表归入Json表组,如表1所示。
其后,依次对写入表配置获取方式和校验方式,配置方案如表2所示,其中原值获取是指从数据源提取数据无须转换,直接写入即可;条件取值设定的条件项是Doc_base表的文档编码和文档名称,获取项是文档ID;文件地址是指定提取物理文件的地址。
Json属性管理自动提取上表Doc_attr中存储的数据结构层级树,并对属性表每个节点属性配置获取方式和校验方式,配置方式与上表类似。
2.2.3 导入配置与数据同步
不同于数据分组主要面向同步目标进行配置,导入配置主要面向数据源的选择,例如当数据分组中对文档编码设置了原值获取,则导入配置中通过自动匹配或搜索匹配源中的合同、维改项目资料、设备完工资料中的文档编码;表2当数据分组设置条件取值时,条件项文档名称也应选择数据源中合同、维改项目资料、设备完工资料中的文档名称,导入配置完成后,同步操作依据用户设置完成从源到目标的提取、转换、校验和导入。
3 结 论
根据上文研究可得以下两点结论:(1)数据治理为企业的生产经营活动提供助力,解决方案需要具有通用性和扩展性来满足日益增长的线上信息化需求;同时系统的设计也应具有弹性,兼顾到生产经营活动的现状,尤其是对线下数据治理的充分支持,从而让数据治理工作在实施过程中可以从线下到线上循序推进。(2)数据采集和数据集成的功能设计中应区别数据源与目标,明确划分各功能模块,充分设计数据获取、数据校验的各种方法,减少人工配置的工作量。
参考文献:
[1] 许可.2020数据治理的趋势与大局 [J].互联网经济,2020(Z1):36-39.
[2] 金励,周坤琳.数据共享的制度去障与司法应对研究 [J].西南金融,2020(3):88-96.
[3] 刘俊良.新时代数据中台研究与设计 [J].电子世界,2020(5):119.
[4] 刘童桐.数据中台建设中最重要的事 [J].通信企业管理,2019(7):25-27.
[5] 赵佳鑫.浅谈需求元数据管理 [J].中国金融电脑,2019(7):80-81.
[6] 安晖.关于数据治理的思考和实践 [J].软件和集成电路,2019(8):68-69.
作者简介:梁光瑞(1987—),男,汉族,山东泰安人,信息技术工程师,研究方向:油气田生产数字化。