摘要:" 基于国家森林资源清查体系,我国积累了大量的森林资源清查数据,为国家的战略规划和政策制定提供重要依据。本文首先对基于分类和聚类的数据方法进行了研究,并对国家森林资源清查数据的特征和数据挖掘的方向展开分析,选取了华东监测区的样地和样木数据,筛选了区域、立地因子、测树因子、生长量等参数,进行了聚类和分类的数据挖掘,提出了关于模型组的合理归并与增减以及避免主观因素造成的误分类等方面的优化方法,而数据挖掘的应用也可以提升智能机器人的感知、决策和交互能力。
关键词:" 数据挖掘;" 分类算法;" 聚类算法;" 数据优化
中图分类号:" "T 10" " " " " " " "文献标识码:" "A" " " " " " " " 文章编号:1001 - 9499(2024)06 - 0061 - 04
基于源自德国的森林资源连续清查的抽样框架体系,我国国家森林资源连续清查每五年一次,截至2018年已经完成了9次;自2021年起,国家林草局联合自然资源部开展了国家林草综合监测工作,期间积累了数百万条样地数据和数亿条样木数据,为森林资源监测工作提供了有力的支持[ 1 , 2 ]。通过清查数据,可以了解森林的分布、类型、面积、质量等信息,进而制定合理的保护、管理和利用政策,以实现国家可持续发展和生态安全的目标[ 3 , 4 ]。然而由于时间跨度较大、调查设备更替、外业调查情况复杂等诸多因素,这些数据对森林资源动态监测,特别是遥感反演生物量、蓄积量等指标来说,可用性存在一定的不足,因此国家森林资源清查数据的优化需要投入更多的研究[ 5 , 6 ]。
信息爆炸时代,海量信息同时也伴随着海量的特征信息,数据挖掘可以从大量数据中揭示出先前未知并且具有潜在价值的信息[ 7 ],主要通过分析每个数据,以及从大量数据间寻找其中的规律。数据挖掘的兴起主要依赖于数学、统计学、人工智能、机器学习等学科的高速发展[ 8 ],而基于数据挖掘方法在智能机器人中的应用场景也非常广阔。本文尝试采用数据挖掘的算法对国家森林资源清查体系下的数据,进行优化,使其在蓄积量、生物量、碳汇量、生长量等更多研究方向上具有更多的使用价值。
1 基于分类和聚类的数据挖掘方法
数据挖掘方法从机器学习的角度来看可以分为有监督和无监督两类。有监督的数据挖掘是利用数据的特定属性构建一个预测性模型,如分类、估值和预测。无监督的数据挖掘则是在所有的属性中寻找某种关系,构建描述性模型,如关联规则和聚类[ 9 - 12 ]。根据数据特性和研究目的,本次研究主要是依靠有监督的分类算法和无监督的聚类算法,因此主要对这两类算法进行研究分析。
1. 1 基于分类的数据挖掘方法
分类方法主要是在已知确定类别的情况下,寻找数据内部的关系,分成相应的类别。通过分类算法来识别物体、人脸、语音等,从而实现自主导航、人机交互等功能。此外,分类算法还可以用于机器人的视觉感知、目标跟踪、姿态估计等方面。常用的分类方法有支持向量机(SVM)算法、决策树算法、随机森林算法、K近邻(KNN)算法等。
SVM算法主要可以用于解决小样本下的数据挖掘问题,并且提高泛化性能,通过映射也可以对高维、非线性的问题求解,主要面向二分类问题,处理多分类的问题可能需要重分类,或者多次二分类,相对麻烦。
决策树算法基本思想首先是从单一根节点开始,对实例的单项特征值进行测试,然后根据测试结果将实例分配到其子节点,再递归地对实例进行测试并分配,直到到达叶节点,最后实例就被完全分到叶节点的类中。
随机森林算法是在决策树算法的基础上,对样本进行了重采样,并且也随机选取了特征,形成多棵树,数据的最终分类则通过投票的方式决定。显然随机森林算法的稳定性和抗过拟合化的能力都得到了大幅度的提高,但是相应的时间复杂度和计算成本也相应提高了,对数据的依赖性相对较强。
KNN算法是一种主要依靠测量特征值之间的距离来进行分类的方法,其精度相对较高,可以用于非线性分类,对数据的依赖性相对较弱,不过计算量相对较大,并且对样本分类不均衡的问题,容易带来误判,因此可解释性也相对较差。
1. 2 基于聚类的数据挖掘方法
聚类方法主要是用于类别不确定的情况下,利用数据在距离、密度、连通性等层面的相似度将数据聚合成不同的类别。其中较为常见的数据挖掘算法有基于距离的K均值(K-means)算法、基于密度聚类(DBSCAN)算法、基于Kohonen网络的聚类算法等。
K-means算法首先选取部分数据组,随机初始化产生中心点,通过计算每个数据点到中心点的距离,划分类别,对得到的每一类中心点设为新的中心点,经过多次的迭代,得到最终的聚类结果。在优化过程中,可以采用多次随机产生初始化中心点,选取迭代最优的结果。
DBSCAN算法的关键是确定半径和临界值,再从任意数据点开始,判断以这个点为中心,确定半径的圆内包含点的数量是否超过临界值,如果没超过临界值则该点被标记为噪声点,反之则会被标记为中心点,然后重复,直到所有的点都被遍历,需要注意的是当一个噪声点位于另外一个中心点的圆内时,则这个点应被标记为边缘点,反之则仍为噪声点。该算法的特点是不需要知道类别的数量,但如何寻找更优的半径和临界值,往往需要借助经验或多次的尝试。
基于Kohonen网络的聚类算法是一种基于自组织特征映射网络的人工神经网络算法,网络包含一个输入层和一个输出层,不包括隐层,输入层中的每个输入节点呈二维结构分布,并都与输出节点完全相通,且节点之间具有侧向连接连。算法的过程是首先确定聚类的初始类中心,然后计算欧式距离,当某个样本输入网络时,与样本距离最近的一个输出节点“获胜”,该节点即是对相应信号刺激反应最敏感的节点。调整获胜节点及其邻接节点的网络权值,将使“获胜”节点更接近相应样本。通过调整权值则会使该节点再次接近这类样本。当不同结构的样本输入网络后,将有其他输出节点分别“获胜”和进行权值调整。这样经过样本输入和不断的权值调整,使得最后的结果呈现出若干输出节点分别对应着若干样本群,且每个样本群内部输入变量结构特征相似,不同样本群间结构特征差异明显。
2 国家森林资源清查数据的分析
国家森林资源清查的基础数据主要包括样地、样木和跨角林地等数据,成果数据还包括了生长量、生物量和碳储量等数据,范围涉及到全国各个省份(实际上从森林资源清查体系上来说是各个副总体),百余个树种组,并且从基础数据到成果数据的过程中也是经历过逻辑检查、数据清洗和多轮的模型推演,以2021年度为例,基础的样地数据就达到了45.7万条,涉及到的数据记录达到600亿组,各类蓄积量、生物量、碳储量、生长量等模型也多达1297组。因此我们在对这些数据进一步挖掘的时候需要充分考虑其数据的特征,并且对数据挖掘的方向进行预先的设计。
2. 1 国家森林资源清查数据的特征
从基础数据来看,从类型上分,主要可以分为样地和样木数据两类。样地数据的属性因子有90项,其主要因子包含坐标因子4项、地形地貌因子6项、土壤因子10项、覆盖类型因子6项、立木因子7项等。样木数据的属性因子有22项,其主要因子有树种、胸径、蓄积量等。从关联关系的角度来看,是由样地号这个字段进行关联,样地表的多个属性是由样木表计算得到的,具体计算过程因为不涉及到本次数据优化,故不加以赘述。
从成果数据来看,从类型上分,主要可以分为生长量和储量两种,其中储量包含了蓄积量、生物量和碳储量,三者之间具有密不可分的联系,而生长量和储量之间则主要通过多期数据进行模型推演计算得到。
由此可以看出国家森林资源清查数据的核心是样木和样地数据,属性因子聚焦于地理信息(包含坐标、地形地貌)和立木信息(包含覆盖情况和测树因子)两类。
2. 2 森林资源清查数据挖掘的主要方向
本次数据挖掘的主要目的是为了森林资源动态监测和遥感反演,因此数据挖掘的主要任务是在于寻找不同环境下树木的生长情况和立木情况之间的关系。
具体来说,森林资源动态监测主要研究的是一片区域(省市县乡村各级都有可能)森林资源的变化情况,基于国家层面的森林资源连续清查抽样框架不足以满足精度要求。因此可以从两个方面对国家森林资源清查数据进行优化,一是从生长量模型的角度,将不同地域相同树种的样地、样木数据进行归并,扩充样本数量,寻找内在联系;二是从遥感反演的角度,将不同地域相同树种的胸径和立地条件之间建立关系,寻找新的分组模式,便于下一步遥感反演模型的建立。
3 国家森林资源清查数据的数据挖掘
因为国家森林资源连续清查始于20世纪70年代,过早的数据由于调查设备相对简陋,保存手段较为落后,并且生态环境的变化又比较明显,因此研究选取的是近四次国家森林资源连续清查数据。我国幅员辽阔,为避免出现地域跨越过大,在数据挖掘过程中造成的数据量过大,并且噪声性数据过多,影响数据挖掘的效果,我们把研究区域缩小到华东区域。
3. 1 基于样地生长量的数据挖掘
数据挖掘的过程为:
(1)选取生长量、副总体、地貌、土壤厚度、平均胸径、优势树种作为分析字段,对优势树种组进行归并;
(2)以副总体为初始聚类数,对数据按照不同优势树种组聚类,以凝聚和分离的轮廓测量作为聚类质量的衡量标准,得到新的类分组;
(3)以新的类分组为目标字段,做分类算法,得到新分类的准确度;
(4)对新分类的结果进行分析,确定优化方法。
在聚类算法的选择上,因为不同树种组的聚类半径和临界值差异会相对较大,因此会对优化带来较大的困难,所以排除DBSCAN算法,选择K-means算法、基于Kohonen网络的聚类算法。
在分类算法的选择上,由于是多分类问题,所以排除SVM算法,经过尝试,计算成本不是非常大的情况下,随机森林算法与决策树算法相比,更具有优势,因此最终的选择是KNN算法和随机森林算法。
聚类算法的评价标准为凝聚和分离的轮廓测量即轮廓系数S:
S=(B-A)/max(A,B)(1)
式中,A是记录与其聚类中心的距离;B是记录与其非所属最近聚类中心的距离;S的取值区间为[-1,1],且越趋近于1,效果越好,而原始数据的轮廓系数的区间为[0.2,0.25]。
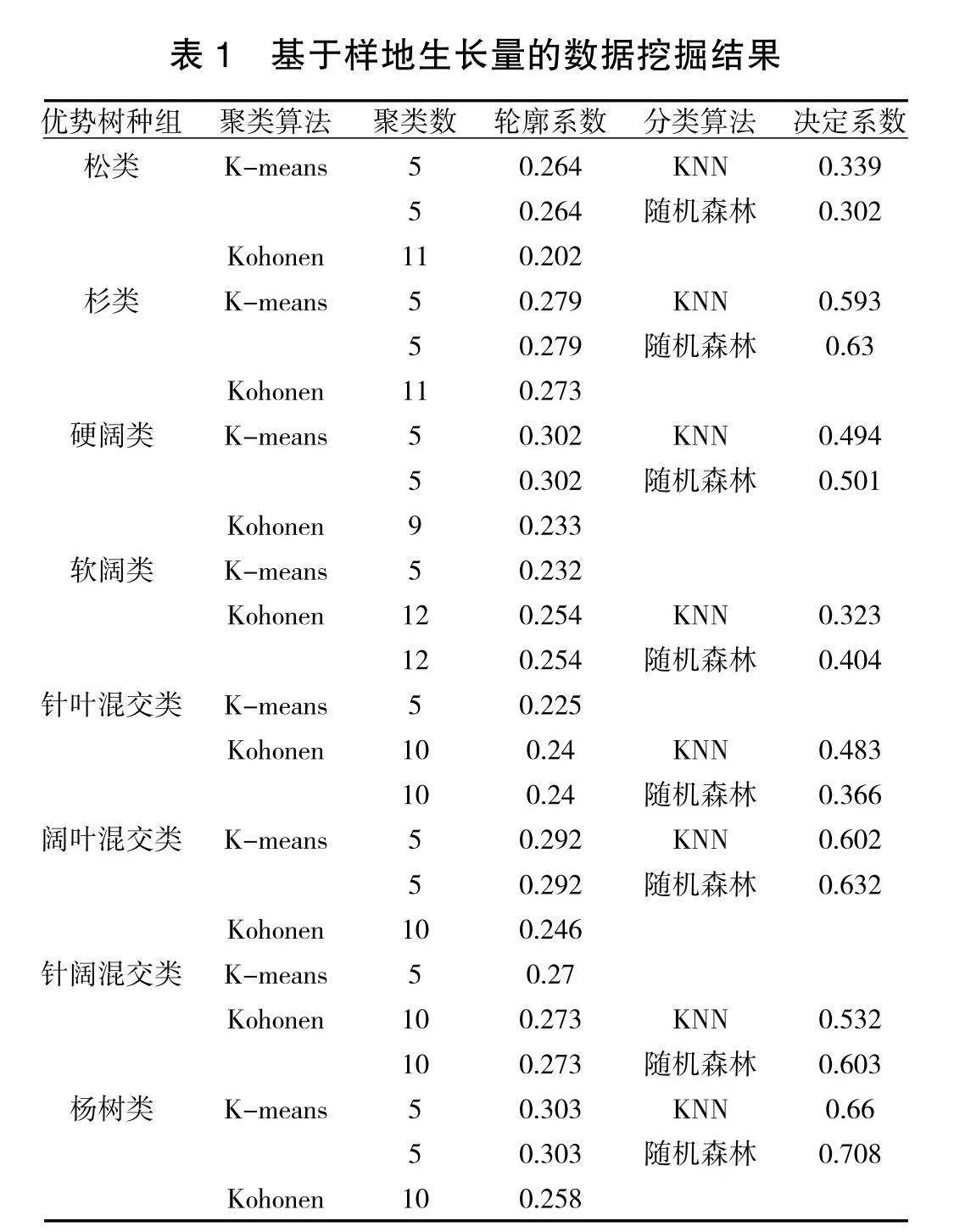
聚类算法的评价指标为模型的决定系数,即R2,数据挖掘的结果见表1。
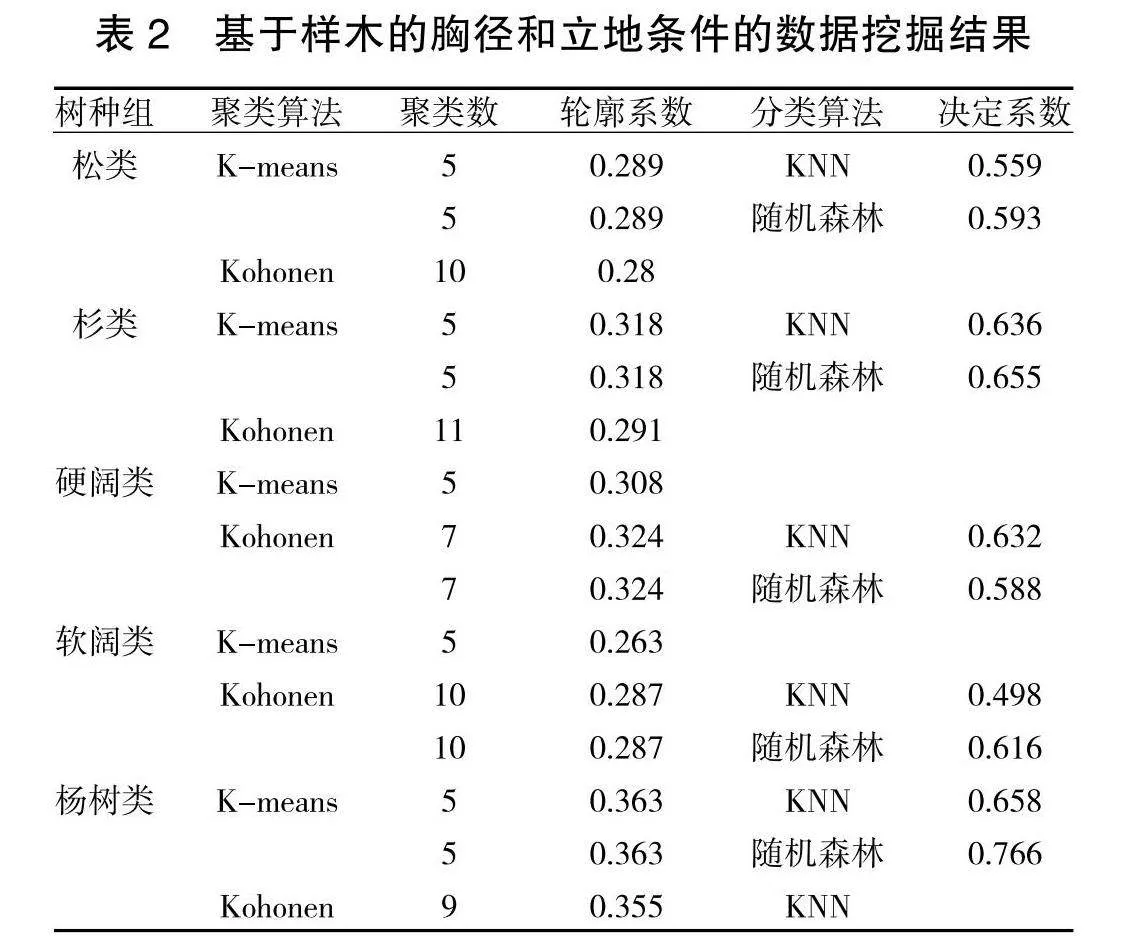
3. 2 基于样木的胸径和立地条件的数据挖掘
数据挖掘的过程为:
(1)选取副总体、地貌、土壤厚度、胸径、树种作为分析字段,将树种进行归并至树种组;
(2)以副总体为初始聚类数,对数据按照不同树种组进行聚类,得到新的类分组;
(3)以新的类分组为目标字段,做分类算法,得到新分类的准确度;
(4)对新分类的结果进行分析,确定优化方法。
聚类和分类算法的选择以及评价标准同上。原始数据的轮廓系数的区间为[0.22,0.26],数据挖掘的结果见表2。
4 数据挖掘结果分析与结论
本文研究结果可以看出,国家森林资源清查数据经过数据挖掘的优化可以体现在几个方面:
(1)可以归并模型组,扩大研究区域内具有相同特征的样地数量,方便后续的遥感反演,如研究杨树类的生长情况时,用新的聚类方式,提升了轮廓系数,减少了类别,并且后续可以依照新的分类模型,去筛选数据,提高之后反演的精度;
(2)可以适当增加模型组,在进一步研究蓄积量、生物量、碳储量等指标时,因地制宜的构建模型组,能够提高预测精度,做出更好的测算;
(3)可以避免一些经验主义的错误,如“南方山区的松类长势都差不多”,减少因主观因素造成错误的分类,影响后续的反演结果。
森林资源清查数据对满足国家重大需求具有重要意义,可以为战略规划、生态环境保护、木材和非木材林产品供应、灾害防控和经济发展等方面提供重要支持。基于数据挖掘的国家森林资源清查数据优化方法涉及面非常广泛,可以研究的方向也有很多,本文仅以华东区域为例,选取了部分清查数据,进行探索,做出了一些优化,为后续更深层次的研究铺垫。
参考文献
[1] 曾伟生," 曹迎春," 陈新云," 等." 河北省主要树种单木和林分生长率模型研建[J]. 林业资源管理, 2020(1): 30 - 37.
[2] 曾伟生," 陈新云," 杨学云." 内蒙古主要树种组立木胸径生长率模型研建[J]. 林业资源管理, 2018(2): 38 - 42, 110.
[3] M. Gerdes, D. Galar, D. Scholz. Genetic algorithms and decision trees for condition monitoring and prognosis of A320 aircraft air conditioning[J]. 2017, 59: 424 - 433.
[4] 曾伟生," 夏 锐." 全国森林资源调查年度出数统计方法探讨[J].林业资源管理,2021(2): 29 - 35.
[5] Navarro C R M, Gonzalez F E, Garcia G J, et al. Impact of plot size and model selection on forest biomass estimation using airborne LiDAR: A case study of pine plantations in southern Spain[J]. Journal of Forest Science, 2017, 63: 88 - 97.
[6] Sullivan M J, Lewis S L, Hubau W, et al. Field methods for" "sampling tree height for tropical forest biomass estimation[J]. Methods in Ecology and Evolution, 2018, 9: 1179 - 1189.
[7] Wang Y, Ni W, Sun G, et al. Slope-adaptive waveform metrics of large footprint lidar for estimation of forest aboveground biomass[J]. Remote Sensing of Environment, 2019, 224: 386 - 400.
[8] Poudel K P, Temesgen H, Gray A N. Evaluation of sampling
strategies to estimate crown biomass[J]. Forest Ecosystems, 2015, 2(1): 1.
[9] Gilbert B, Lowell K. Forest attributes and spatial autocorrelation and interpolation: effects of alternative sampling schemata in the boreal forest[J]. Landscape amp; Urban Planning, 1997, 37: 235 - 244.
[10] 邹杰." 基于数据挖掘的数据清洗及其评估模型的研究[D].北京: 北京邮电大学, 2017.
[11] 朱文轩." 基于数据挖掘的我国林业统计数据质量评估方法与实证研究[D]. 北京: 北京林业大学, 2021.
[12] 刘海," 徐旭平," 周蔚," 等." 林业样地的数据清洗方法研究及其应用[J].安徽工程大学学报, 2020, 35(3): 62 - 66.