陈乐 纪炎明 肖忠良
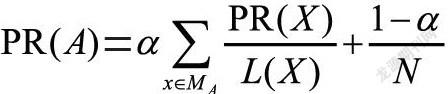




摘 要:微服务、云原生是当前信息系统发展的主流方向,给信息系统带来高可用的同时也让IT系统变得前所未有的复杂,这对IT运维工作带来了巨大的挑战。机器学习正是当前时代下应对复杂系统和海量信息的可选措施。文章将讨论基于PageRank的算法在接口服务调用链上定位异常节点,并且经过测试,可在错综复杂的调用关系上实现快速准确的异常定位。
关键词:IT运维;机器学习;PageRank;调用链分析;异常节点定位
中图分类号:TP18 文献标识码:A文章编号:2096-4706(2021)22-0059-04
Abstract: Microservices and cloud native are the mainstream development directions of current information systems. While bringing high availability to information systems, they also make IT systems more complex than ever before, which bring huge challenges to IT operation and maintenance. Machine learning is an optional measure to deal with complex systems and massive amounts of information in the current era. This paper will discuss the algorithm based on PageRank to locate the exception node on the interface service call chain, and after testing, it can realize fast and accurate exception location on the complex call relationship.
Keywords: IT operation and maintenance; machine learning; PageRank; call chain analysis; abnormal node location
0 引 言
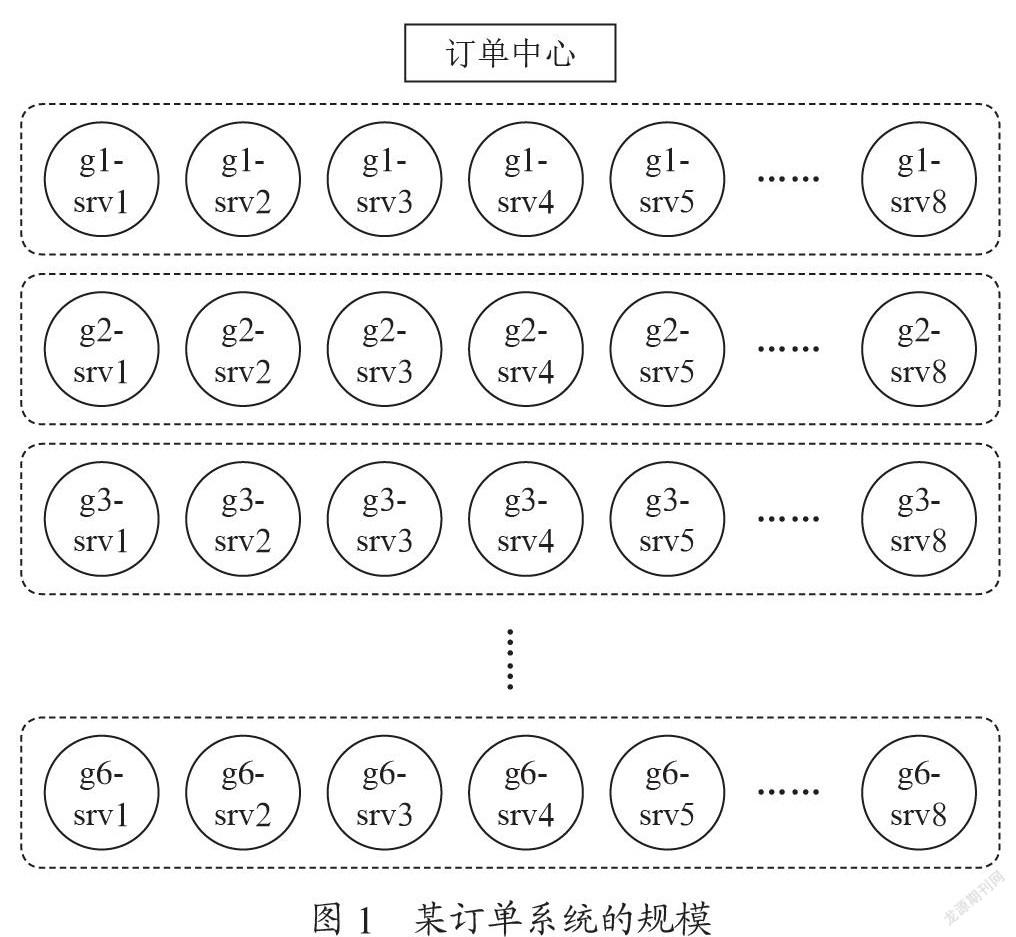
当前的IT系统大多以采用微服务+云原生的架构[1]。微服务架构是将一个复杂的应用拆解成多个独立自治的服务,服务之间以松耦合的形式交互。如此部署应用的优势很明显,即业务逻辑清晰、部署简单、可拓展、高可用等等。以中国移动某省CRM为例,2018年完成了分布式5层云化IT系统,设计的系统极为庞大[2]。其中某订单系统的规模如图1所示。
微服务的劣势也随着IT系统规模的扩大而愈发明显,各个组件的调用关系错综复杂,对运维的压力也与日俱增。为了掌握系统的实时状态,大多数IT厂商会建设集中化监控系统,在IT系统中部署采集agent,实时采集系统各个层级,比如应用、中间件、主机等的告警信息。这从原来缺少信息的极端,走到信息过载的另一个极端。同时,高度复杂的IT系统架构意味着,一旦某个局部组件发生异常,故障信息就极易在短时间内扩散,触发大量告警。大量的告警信息中存在巨大的冗余,会淹没掉真正有用的信息。《数字企业杂志》于2019年的IT运维管理研究报告中显示,大型厂商的IT系统每停机1小时,可造成12.7万美元的损失,而恢复系统正常平均需要3.7个小时[3]。
面对这样的挑战,传统的运维方式属于被动式响应,杂乱无章且充斥冗余信息的告警事件让运维人员疲于奔命,在异常事件发生时,被动的人工排查方式存在故障定位困难、运维效率低下的问题。并且随着业务的拓张,系统的扩容也在所难免,而运维的扩展很难跟上系统扩容的速度。而机器学习算法辅助的智能运维[4],正是实现复杂系统运维和处理海量告警信息的可行方向。本文通过引入图的链接(link analysis)的代表性算法PageRank,在多笔业务调用链构成的有向图上计算每个节点的异常得分,最终在高度复杂的调用关系网络中快速准确的定位到异常节点,帮助运维人员在异常、故障发生时快速定位异常根因,从而缩短修复时间,快速恢复业务正常可用。
1 基于PageRank的调用链算法流程
1.1 PageRank算法描述
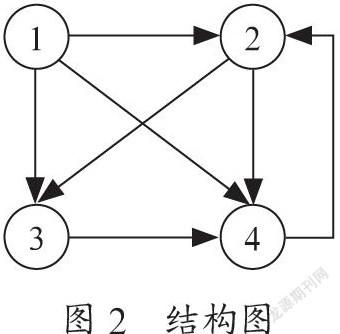
PageRank最初是用于计算网页重要度的方法,于1966年由Page和Brin提出[5],并用于谷歌搜索引擎的网页排序。除此之外,在图书影响力评价[6]、全球贸易网络格局演变分析[7]、微博用户影响力评价[8]等方面都有广泛引用。PageRank算法的基本思想是在将网页及其访问关系定义为有向图,并在图上定义一个随机游走模型,即一阶马尔可夫链,模拟网页访问者随机浏览网页的过程。网页访问者在每个网页依照网页链接出去的超链接,以一定概率跳转到下一个网页,不断重复这个过程,极限情况下每个网页的访问概率收敛于平稳分布,这时候每个网页的访问概率就是其PageRank值,也就是网页的重要度。如图2所示。
PageRank基于两个假设:
(1)如果一个网页能被很多其他的网页链接到,说明这个网页非常重要,PageRank值也就越高。
(2)一个PageRank值非常高的网页链接到另一个网页,被链接网页的PageRank也应该提高。
接下来使用PR值代表网页的PageRank值,来总结PageRank值的计算方法。
输入:需要计算网页PR值的N个网页,以及网页之间互相链接构成的有向图。
输出:全部网页的PR值,以及按照PR值排序得到的网页重要性顺序。
(1)统计每个网页的出链对象,以及所有的出链数量。假设网页A的全部的出链对象有网页B和C,则其出链数量为2。
(2)给每个网页赋予一个初始PR值,假设存在N个网页,定义每个网页的初始PR值为1/N。
(3)在每一个epoch中,依次计算每个网页的PR值,迭代计算方式为:
其中α是阻尼系数,一般设定为0.85,MA指的是对网页A出链的全部网页,L(x)指的是网页X的出链数量,N为网页总数。
(4)持续迭代多个epoch,直到每网页的PR值不再显著变化。即全部的网页的PR值不再显著变化。
(5)输出每个网页的PR值。并将网页按照PR值进行排序,输出重要性排行靠前的网页。
1.2 改进PageRank算法
PageRank算法主要用作计算互联网网页重要度的算法。其实除了之前提到的2个假设外,存在一个隐藏假设,即各个网页之间存在大量的、充分的互相访问构成的链接关系,并且网页之间按照一定概率进行随机跳转。这也是PageRank的核心迭代公式的简单理解。
但对于接口服务的业务调用构成的调用网络上,直接使用PageRank的节点权重计算方式则存在一定的问题,其基本假设不成立,即:
(1)单位时间内节点之间的访问次数是有限的,比如5分钟内可能存在最多50笔业务,而我们需要在这50笔业务调用中定位到异常节点,如果节点非常多,则可能存在某些节点未被调用。我们需要基于单位时间内产生的有限业务调用中定位到异常节点。
(2)节点之间的访问存在层次关系,比如接口服务层节点调用应用层节点,应用层调用中间件节点,依次类推,不存在顶层的接口服务节点直接调用底层的主机节点的情况。
因此我们需要对PageRank做一定的改进,使其能应用到业务调用的异常节点定位。
首先,我们定义一个节点与它上下文的调用节点、被调用节点存在图相邻关系。假设在多笔调用链构成的调用关系网络中,节点H分别调用了节点O、P、Q,而有节点A、B、C调用了节点H,则H和节点列表{A,B,C,O,P,Q}都存在图相邻关系。
其次,基于调用关系和调用耗时,定义节点之间的有向边E和权重W。假设节点H调用了节点A,则存在一个有向边H->A。SRE中提到的4个黄金指标中,耗时最适合用作计算异常得分。这里基于节点之间的调用耗时,定义边的权重。假设单位时间内存在50笔业务,每笔业务的总耗时为Ti,i=1,2,...,50,则节点H与节点A的边H->A的边权重为:
wHA=tHA
其中tHAt为单位时间内发生的所有业务调用中节点H调用节点A的平均耗时。
再则,假设节点H被调用时的平均耗时越大,则H的异常得分也越大。而一个异常得分很高的节点调用另一个节点时,被调用节点的异常得分也相应增大。
最后,基于节点的多笔调用链构成的调用关系,改进PageRank的节点异常得分的迭代公式为:
其中vj是调用vi的节点,M(vi)表示调用节点vi的节点集合,out(vj)表示被节点vj调用的节点集合,wjt表示调用节点vj和vi之间有向边的权重。
由于节点间的业务调用可能并不充分,部分节点存在不被调用的可能,并且还去除了节点之间随机调用,这意味着经过多次epoch迭代后,节点的PR值可能不会收敛。因此我们判断迭代是否停止的条件需要做修改,即每个epoch结束时,输出节点的PR值和节点的PR排名,如果排名和上一个epoch相等时则停止迭代。
改进PageRank算法总结:
输入:基于多笔调用链构成的调用网络N,每笔调用链的调用总耗时T,以及每个节点之间的调用平均耗时t。
输出:节点的异常得分序列PR及其排序R。
计算过程为:
(1)定义节点的初始PR值。假设调用网络的总节点数为N。则每个节点的初始PR值为:
(2)定义节点之间的有向边的权重。假设节点vj调用节点vj的平均耗时为,则节点vj和节点vj之间的有向边的权重wjt为:
wjt=tjt
(3)从epoch=1开始,依次对计算每个节点vj 的PR值,计算方式为:
其中vj是调用vj的节点,M(vi)表示调用节点vi的节点集合,out(vj)表示被节点vj调用的节点集合,wjt表示调用节点vj和vi之间有向边的权重。
(4)输出每个节点的PR值及其排序R,如果第m+1个epoch输出的节点排序Rm+1和前一次,也就是第m个epoch输出的节点排序Rm一样,则停止迭代,否则重复步骤3。
以上就是本文用于调用链异常节点定位的改进PageRank算法。
2 实验与结果分析
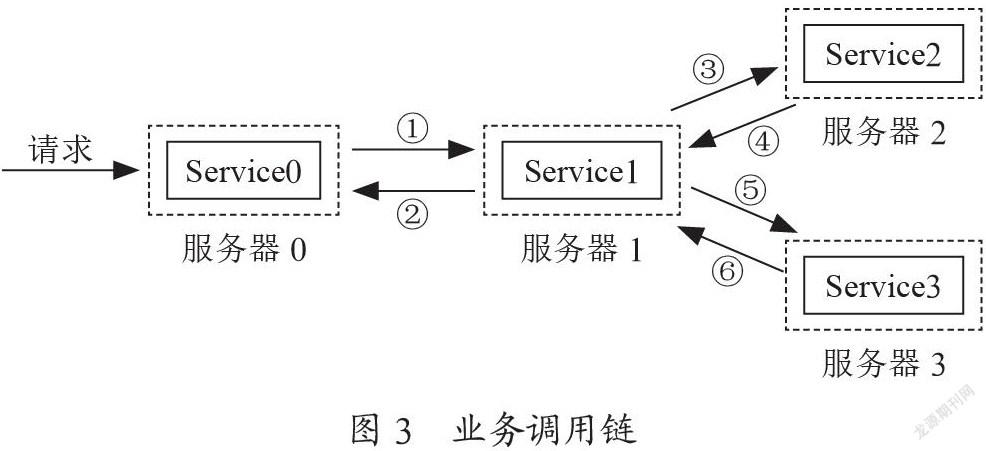
一个典型的业务调用链如图3所示。
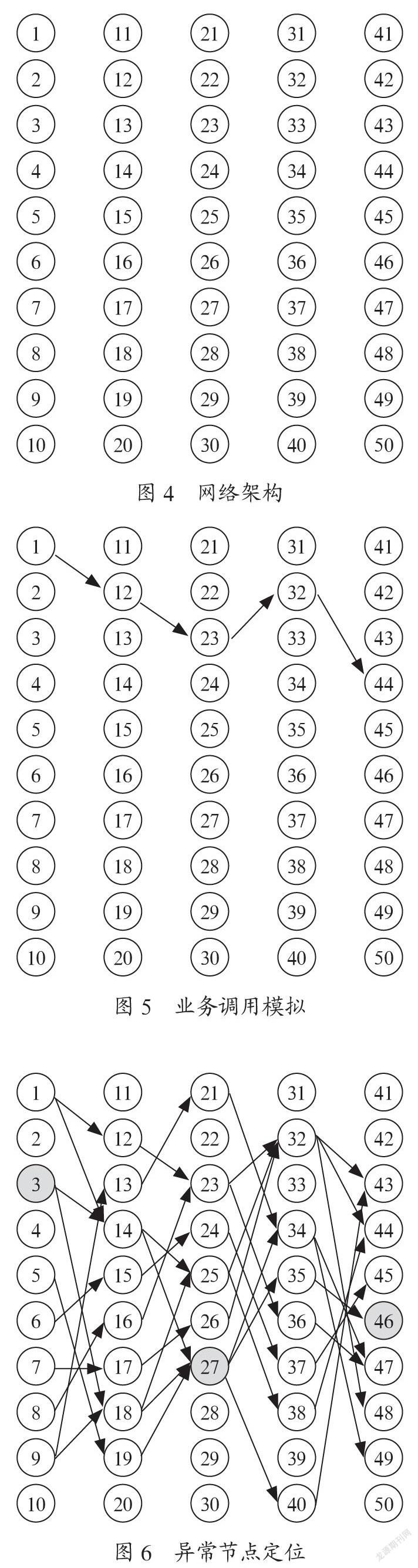
由于目前计算机系统的故障次数很少,为了验证改进PageRank算法在异常节点定位的准确率,我们基于业务特征仿真了一个接口服务调用网络,本次模拟定义了5层业务系统,每层分别有10个节点,只有相邻网络层可以相互调用。如此构成了如图4所示的网络架构。
接下来在网络图中随机将1个节点,或2个节点定义为异常节点,异常节点可能在最底层,也可能在最外层。基于调用耗时区分普通节点和异常节点,普通节点的被调用耗时为0~100 ms,而异常节点在耗时为200 ms~300 ms。
之后,在接口服务调用网络中,模拟多笔业务的完整调用,每一笔业务都是从最外层节点一直执行到最里层。比如其中的一笔业务调用如图5所示。
通过在网络上模拟w笔业务,并使用改进的PageRank算法计算每个节点的异常得分,也就是PR值,推举排序最高的3个作为推荐结果。如果预埋的异常节点都在推荐结果之内,则定义算法的异常节点定位正确。本次实验中主要验证改进PageRank算法在不同的预埋节点k和模拟业务次数w下的异常节点定位准确率。图6中白色节点为算法推荐的3个异常节点。
改进PageRank在多次实验的异常定位准确率如表1所示。
异常定位准确率很好的反映了算法的有效性。以上数据表明,随着模拟业务次数w的增多,改进PageRank对异常节点的定位准确率也在逐渐提升,当业务次数为节点数量的2倍以上,算法的异常定位也更稳定,基本满足业务所需。
3 结 论
针对复杂系统中难以定位异常节点的问题,本文基于图分析算法PageRank算法和业务调用特征,改进PageRank算法,改进方向主要是边权重和节点异常分数的计算方式。之后模拟单位时间内产生的多笔业务调用构成调用网络,试验改进PageRank算法在模拟的业务调用中定位异常节点的准确率。实验结果表明,本文提出的方法可以在在复杂的调用关系网络中快速准确的定位到异常节点,可在业务上帮助运维人员在异常或故障发生时快速定位异常原因,缩短修复时间,恢复业务正常可用。
参考文献:
[1] 董瑞志,李必信,王璐璐,等.软件生态系统研究综述 [J].计算机学报,2020,43(2):250-271.
[2] 范鹏里.甘肃移动CRM系统项目优化研究 [D].南京:南京邮电大学,2019.
[3] DANG Y,LIN Q,HUANG P. AIOps:Real-World Challenges and Research Innovations [C]//2019 IEEE/ACM 41ST INTERNATIONAL CONFERENCE ON SOFTWARE ENGINEERING:COMPANION PROCEEDINGS (ICSE-COMPANION 2019).Montreal:IEEE,2019:4-5.
[4]裴丹,张圣林,裴昶华.基于机器学习的智能运维 [J].中国计算机学会通讯,2017,13(12):68-72.
[5] BRIN S,PAGE L. The anatomy of a large-scale hypertextual Web search engine [J].Computer networks,1998,30 (1-7) :107 - 117.
[6] 宋京京,潘云涛,苏成.基于Pagerank算法的图书影响力评价 [J].中华医学图书情报杂志,2015,24(12):9-14.
[7] 蒋雪梅,张少雪.基于Pagerank算法的中间品全球贸易网络格局演变分析 [J].国际商务研究,2021,42(1):38-49.
[8] 吴柯.基于交互行为的微博用户影响力评价研究 [D].广州:华南理工大学,2014.
作者简介:陈乐(1982—),男,汉族,重庆人,项目总监,硕士研究生,研究方向:AIOps、业务支撑系统运营支撑;纪炎明(1995—),男,汉族,广东广州人,项目经理,本科,研究方向:AIOps算法;肖忠良(1986—),男,汉族,广东广州人,项目经理,硕士研究生,研究方向:AIOps、业务支撑系统运营支撑。