龙 志,陈湘州(教授)
一、引言随着经济全球化进程的加速和经济政策改革,中国经济得到快速发展,成为世界第二大经济体。党的二十大报告中强调了优化资源配置、加强统筹推进,以推动企业绿色创新和高质量发展。然而,随着我国企业规模的扩大,企业在高质量发展道路上必然会面临艰巨的挑战。作为国民经济的重要组成部分,企业的健康成长对于国家保持可持续性的高质量发展至关重要。财务状况是企业发展情况的直观体现,也成为投资者、企业和政府等利益相关者关注的焦点。因此,利益相关者需要对企业的财务风险进行合理评估,以作出科学决策。
财务风险是指企业在特定的经济环境下,其财务状况和财务健康可能受到内部和外部因素的影响,从而导致经济损失、债务违约、利润下降或资不抵债等风险(Acharya和Richardson,2009)。相应地,财务风险预警是一种早期发现和识别企业财务风险的过程。其目的是帮助企业和监管机构及时识别潜在的财务问题,并采取适当的措施来防范和化解风险,以确保企业的财务健康和可持续发展(Koyuncugil 和Ozgulbas,2012;蔡立新和李嘉欢,2018)。20 世纪30 年代,Fitzpatrick(1932)以健康企业和破产企业为研究对象构建了单变量财务风险预警模型,结果表明众多财务指标中的股东权益率和资产负债率具有更好的判别性,为后续研究提供了早期的理论基础。随后,Beaver(1966)和Altman(1968)分别提出了单变量模型和Z-score 模型,并将其用于企业财务困境的预测。然而,这些方法存在严格的前提条件,例如变量间必须存在线性关系,而现实并非如此。
随着机器学习和深度学习的应用与发展,这类模型能够自动从数据中学习和提取特征,自适应地调整模型参数,同时能够捕捉和处理数据中的非线性关系(Jordan和Mitchell,2015;LeCun等,2015)。因此,它们在处理大样本、高维度数据上比传统数理模型更为有效。以机器学习为例,Halteh 等(2018)选取18 个财务指标构建了基于随机森林和随机梯度提升的融合模型,加速推进了企业财务困境的预测研究。另外,Yao等(2019)采用遗传算法(GA)自动优化支持向量机(SVM)模型的超参数,验证了机器学习在财务预测中的有效性。此外,Metawa 等(2021)从特征选择角度考虑,提出了一种PIO-XGBoost 模型,该模型能够有效预测企业是否会倒闭。
然而,上述机器学习模型在处理高维度、复杂样本时存在一定的不适应性。因此,学者们纷纷将深度学习引入金融领域。Chen 等(2020)利用卷积神经网络(CNN)模型进行金融量化投资,并获得了风险更低、收益更高的投资策略。Jang 等(2020)将建筑行业内的特殊指标引入基于长短期记忆(LSTM)神经网络的模型中,分别预测未来1 年、2 年和3 年建筑承包商的绩效。Yin 等(2022)构建了基于CNN的供应链金融风险预警模型,但仅根据是否被ST简单地将企业划分为两个类别,且样本量较少。Li 等(2023)通过对2017 ~2020 年上市公司的财务风险分析,发现基于优化的反向传播神经网络(BPNN)模型的准确率能够达到80%以上。
综上,目前企业财务风险预警研究还存在以下问题:一是大多数预警研究仅实现对企业财务风险的度量和评级,而鲜有学者利用深度学习对其进行智能预测分类;二是指标体系庞大,可能导致模型出现过拟合问题,从而影响预测准确率;三是关于企业财务风险等级的划分,现有文献大多将其分为两类(如健康或被ST 处理过),可能导致不同类别样本量不平衡的问题。针对上述问题,本文展开如下研究工作:首先,运用熵权TOPSIS 对企业财务风险进行综合评分;其次,对评分结果进行FCM聚类,有效划分财务风险的等级区间,为CNN 模型的监督学习奠定基础;然后,引入SMOTE 算法解决各等级企业样本不平衡的问题;最后,通过消融和多模型对比实验,验证本文所构建模型的预测性能。本文的研究旨在实现更准确、全面和可靠的企业财务风险评估,为我国企业的可持续发展提供实践和政策指导。
二、研究设计(一)样本选取与数据来源金融企业通常具有较大的财务风险,并且其业务模式与其他行业的企业存在显著差异,这可能对财务风险预警模型的预测性能产生影响(Abdulsaleh 和Worthington,2013;Wu和Huang,2022)。因此,本文在选择样本时剔除了金融行业的企业。本文以2018 ~2022年我国4975家A股上市公司的财务数据为研究对象,包括零售业、信息技术、制造、医药等多个行业。经过缺失值处理后,最终得到20183 个样本。为平衡样本的类别分布,本文采用了SMOTE过采样方法,将样本容量调整为36180 个。随后,将数据集按照样本比例7∶1∶2 分别抽取训练集、验证集和测试集。数据来源于CSMAR数据库。本文所有实验均基于Pytorch深度学习框架的PyCharm编程软件完成。
(二)财务风险预警指标体系参考国内外相关研究(Wang 和Wu,2017;赵腾和杨世忠,2019;Zhang等,2022;Venkateswarlu等,2022),从偿债能力、经营能力、盈利能力、现金流能力、发展能力五个方面选取财务指标。同时,本文额外选取了5个公司治理结构方面的非财务指标,分别是股东总数、员工人数、董事薪酬总额、监事薪酬总额和高级管理人员薪酬总额。具体的指标体系见表1。
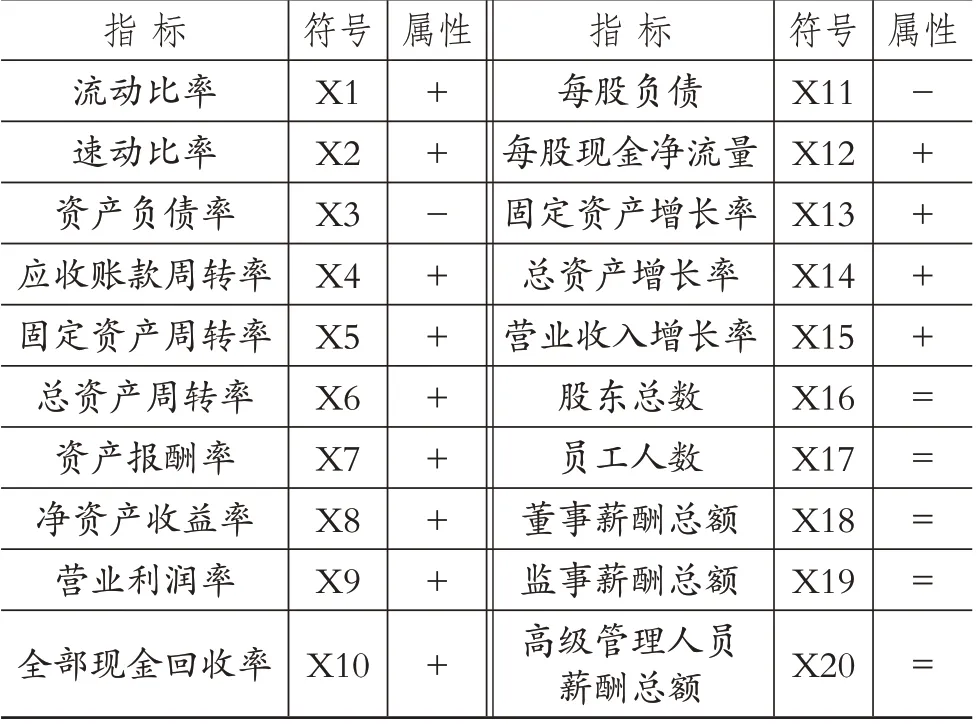
表1 各指标的描述性统计
(三)熵权TOPSIS-FCM-CNN模型的构建1.熵权TOPSIS。本文采用熵权TOPSIS方法来确定指标体系中各指标的权重和各企业的综合评分。熵权TOPSIS方法是一种多属性决策分析方法,通常用于评估多个备选方案或对象的最佳选择。它结合了熵权法和TOPSIS方法,可更好地处理不确定性和主观性信息。具体步骤如下:
第一步,构造具有多属性的初始评价矩阵。假设企业数量为m个,影响企业财务风险的指标有n个,第i个样本的第j个指标的评价值为aij,则评价矩阵为:
采用最大最小值标准化方法来无量纲化各指标。其中,正向指标、中性指标用公式(2)处理,负向指标用公式(3)处理:
第二步,利用熵权法确定各指标的权重。例如,第j个指标的权重为wj,公式如下:
第三步,利用TOPSIS 法确定评价对象与正、负理想解之间的欧式距离。计算评价矩阵A=W×(aij)m×n。aij的正、负理想解为:
因此,第i个企业与理想企业的综合评分(接近度)为:
其中,综合评分越高,表明该企业的财务风险越小,反之亦然。
2.FCM 聚类。在对所有企业的财务风险进行综合评分后,通过对未标记的企业样本进行聚类,可实现财务风险等级分类效果,从而帮助企业和政府做出相应的策略调整。FCM是一种模糊聚类算法,用于将数据点分组形成具有相似性的集群。与传统的硬聚类方法(如K 均值)不同,FCM 允许数据点属于多个集群,具有更强的灵活性(Bezdek等,1984)。因此,本文选择FCM聚类算法来生成企业财务风险的等级标签。
待聚类的企业样本X={x1,…,xn}属于P维欧式空间,xi∈RP(i=1,…,n),将其分类为C 类,V={v1,…,vC}表示C个聚类中心点集,U=(uik)表示隶属度矩阵,uik表示第k 个样本在第i 类中的隶属度,且满足=1。设目标函数为:
式中:m∈[1,∞)是加权指数,一般取1.5≤m≤2.5。
目标函数J(U,V)表示各类别中样本到其所在聚类中心的加权距离平方和。其中,权重是样本xk对第i类隶属度的m次方。通过引入J(U,V),将聚类问题转化为求解MinJ(U,V)的非线性规划问题,经过优化迭代后,获得近似最优解U、V,便可以最终确定样本所属的类别。具体计算过程如下:
第一步,初始化参数。假定企业财务风险等级个数为C(聚类类别数为C),2≤C≤n,模糊加权指数m=2。设定迭代停止的阈值为ε,0.001≤ε≤0.01。初始化聚类原型模式V。
第二步,计算或更新划分矩阵U。对于∀i,k,如果dik>0,则有:
如果∃i,k使得dik=0,则有uik=1。
第三步,更新矩阵V。
第四步,计算目标函数J(U,V)。如果J(U,V)<ε,则算法停止并输出隶属度矩阵U 和聚类原型矩阵V,否则重复上述步骤二和三。
3.CNN 深度学习模型。在通过聚类生成等级标签并使用SMOTE扩充样本后,本文采用CNN模型来实现企业财务风险等级的分类预测。CNN 是深度前馈神经网络,包括卷积和深度结构,由多个卷积、池化和全连接层组成,用于处理企业财务风险指标。它的参数共享和GPU并行计算提高了模型效率,降低了模型应用的复杂度和计算成本。CNN 在图像处理等领域表现出色。近些年,开始有学者将CNN引入企业破产预测研究中(Hosaka,2019),证明了CNN 对处理企业财务数据信息具有可行性。
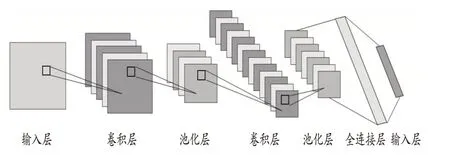
图1 CNN的基本原理示意图
4.模型性能评估。实际上,企业财务风险预测可视为一个多类别不平衡分类问题。对于该问题,通常使用多角度、多模型和多指标来综合评估模型的性能。本文采用消融实验和多模型对比思路,分别对BP神经网络、支持向量机SVM、随机森林RF、极限梯度增强算法XGBoost、轻型梯度增强机LightGBM 进行预测效果对比,以检验本文所构建模型的有效性和优越性。
(1)模型准确性检验。假设Pi表示第i个模型的企业总识别率,(j=A,B,C,D)表示第i 个模型的财务风险A、B、C、D等级企业样本识别率,表示第i个模型的企业样本识别率的平均水平,公式如下:
(2)模型全面性检验。一个非常好的模型预测效果不仅具备较大的Pi值,还需要考虑该模型分别对财务风险为A、B、C、D等级企业样本的预测效果。假设第i 个模型的识别率Pi、(j=A,B,C,D)的标准差和变异系数分别为CVi、σi。其计算公式如下:
式中:i=1,2,…,5 分别对应BPNN、SVM、RF、XGBoost 和LightGBM;变异系数CVi值越小,即第i个模型的识别率Pi、(j=A,B,C,D)五者间的相对离散程度越小,表明第i个模型对不同财务风险等级企业的预测效果越均衡,模型的全面性越好,反之亦然。此外,模型性能综合评估原则为:准确性>全面性。
5.企业财务风险预警流程。基于熵权TOPSISFCM-CNN模型的企业财务风险预警流程,如图2所示。
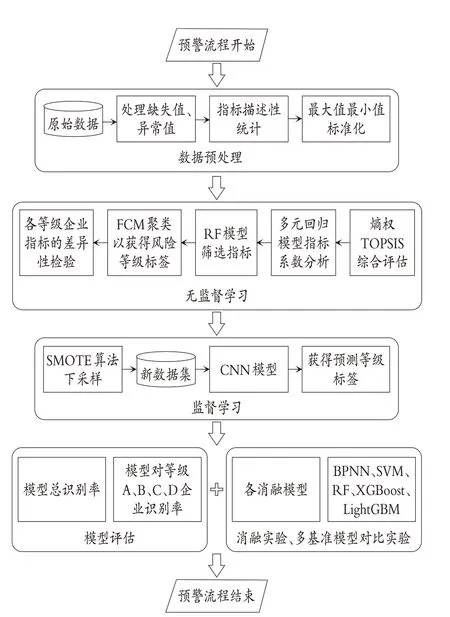
图2 本文模型的预警流程
三、实验结果与分析(一)熵权TOPSIS综合评分通过熵权TOPSIS法中的公式,计算出各企业与正理想解、负理想解之间的欧式距离并获得各企业的综合评分Gi。其中,综合评分越高,表明该企业的财务风险越小。熵权TOPSIS 模型下综合评分最高的6家企业和最低的6家企业,如表2所示。
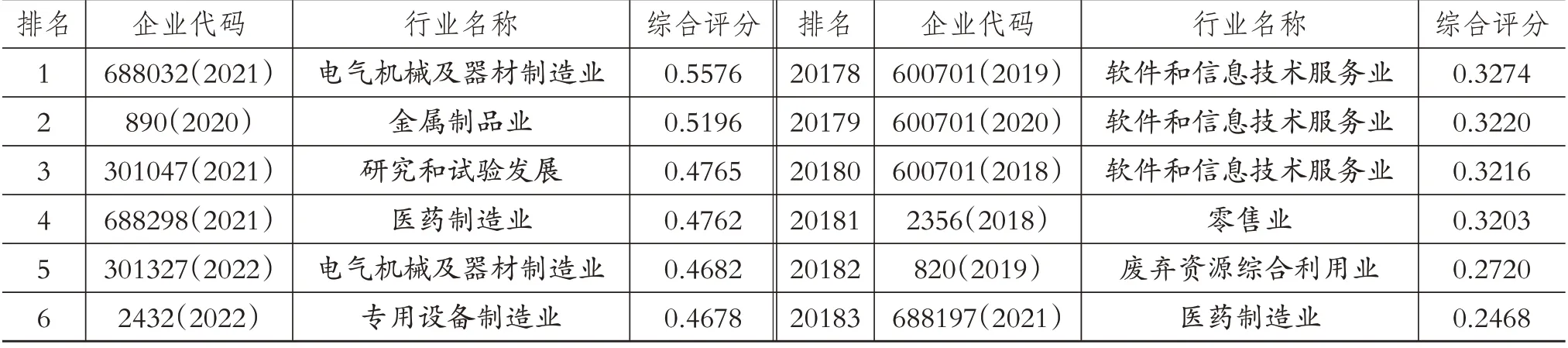
表2 各企业财务风险的综合评分与排名
由表2可知:第一,企业综合评分的均值为0.3951,标准差为0.0073,变异系数为0.0184,25%分位数为0.3913,50%分位数为0.3945,75%分位数为0.3982,表明企业整体综合评分数据相对较为稳定,但有近四分之三的企业综合评分低于均值水平;第二,排名前六位的行业包括电气机械及器材制造业、金属制品业、研究和试验发展、医药制造业和专用设备制造业,且年份主要集中在2020 ~2022 年,而排名后六位的行业包括软件和信息技术服务业、零售业、废弃资源综合利用业和医药制造业,且年份主要集中在2018 ~2021 年。以上研究结果表明,综合评分高的企业所在行业之间存在协同发展情况,在创新能力、竞争能力等方面表现出色,同时也反映出我国正逐步推进高质量发展。
将熵权TOPSIS 的综合评分与标准化后的指标数据代入多元线性回归模型中,进一步分析各指标与企业财务风险之间的关系。具体结果如表3所示。
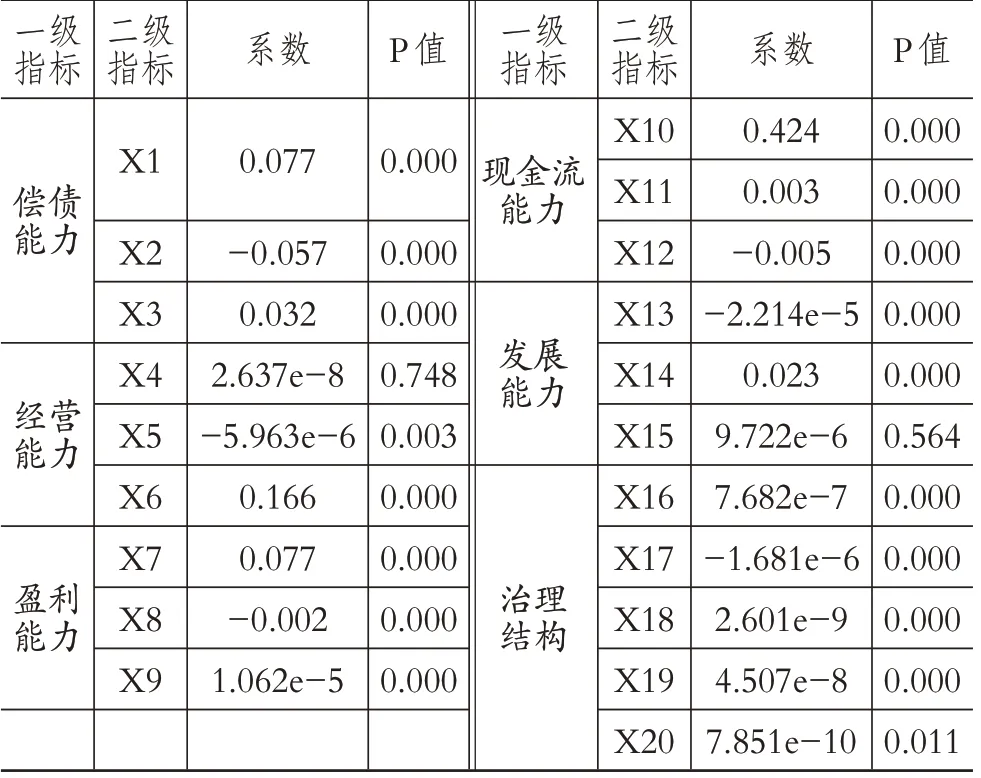
表3 多元回归模型指标系数
由表3可知:第一,现金流能力对企业的财务风险影响最大,而治理结构(非财务指标)对财务风险的影响程度最小;第二,多元回归模型的线性关系是显著的(Significance F=0.000<α),但回归系数检验中却有3 个指标(应收账款周转率X4、固定资产周转率X5和营业收入增长率X15)没有通过t 检验,表明模型中存在多重共线性问题;第三,速动比率X2、固定资产周转率X5、净资产收益率X8、每股现金净流量X12、固定资产增长率X13 和员工人数X17 的回归系数为负值,即它们的增加会使企业财务风险增加,这与预期不一致,同样表明模型中存在多重共线性问题。
多重共线性是回归分析中的问题,指自变量间高度相关,导致模型过拟合风险。为应对此问题,本文采用RF机器学习模型进行指标筛选。RF通过评估指标划分前后信息熵减少来衡量指标相对重要性,且RF模型具有高效和可解释的特点。本文使用RF 评估了20个影响企业财务风险的指标,计算了其重要性。数值越大,指标越重要。取10次实验的平均值作为最终结果,如表4所示。
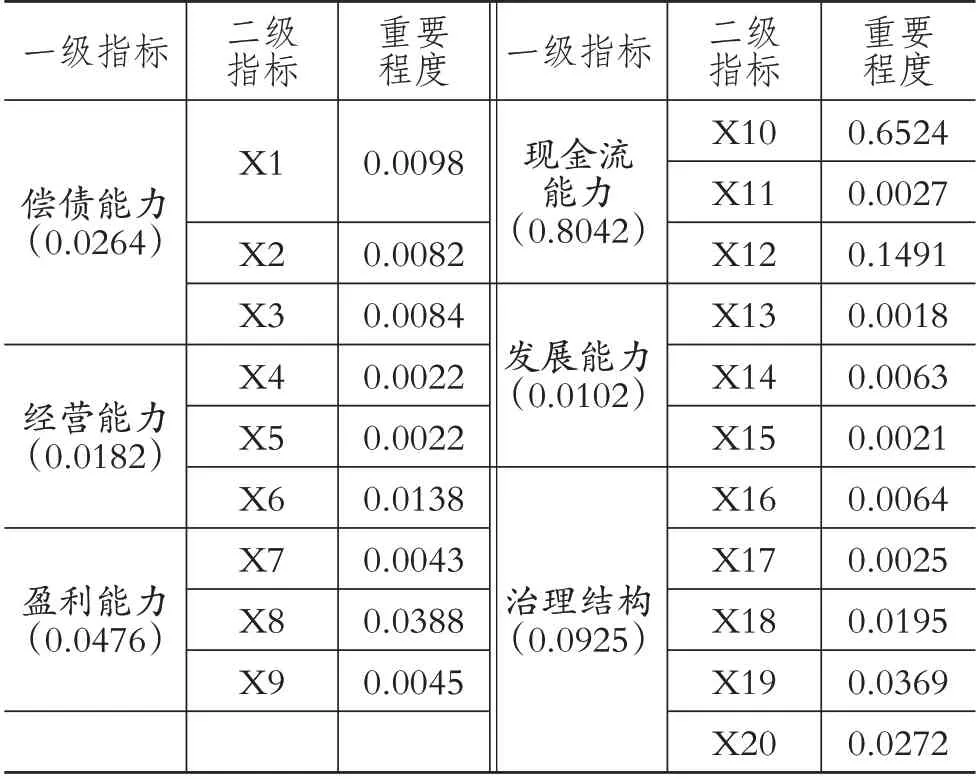
表4 基于RF筛选的指标重要性程度
由表4 可知:第一,根据重要性程度,一级指标从高到低排序依次为现金流能力、治理结构、盈利能力、偿债能力、经营能力、发展能力;第二,根据重要性程度,二级指标从高到低排序依次为X10、X12、X8、X19、X20、X18、X6、X1、X3、X2、X16、X14、X9、X7、X11、X17、X4、X5、X15、X13。为了比较在后续实验中RF筛选指标是否对模型的预测性能产生影响,借鉴杨贵军等(2022)的研究,本文对于重要程度小于0.01的二级指标不予考虑,故选取前7 个财务风险指标作为指标筛选的最终结果。
(二)基于FCM聚类的无监督学习本文选择将企业财务风险聚类为4 个等级,分别用A、B、C、D 表示非常低风险、低风险、中风险和高风险。通过FCM 算法中的公式,得到企业的聚类结果,并生成相应的等级标签。具体的聚类情况如表5所示。
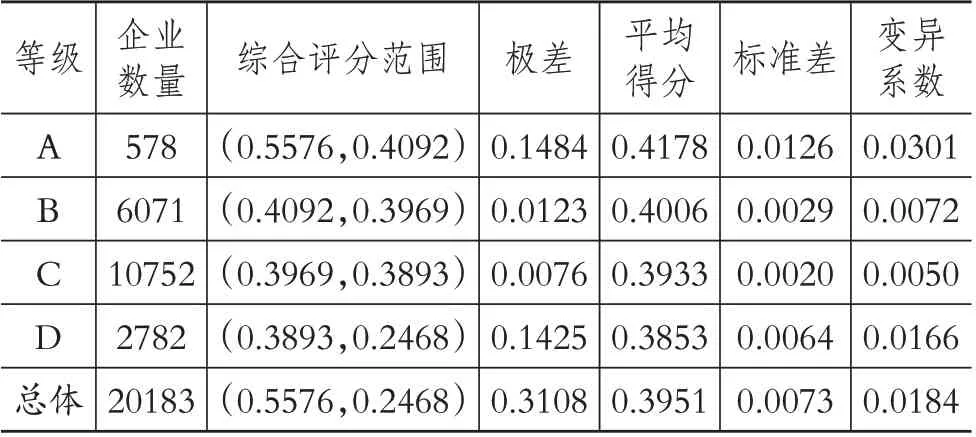
表5 企业财务风险等级的K-means聚类结果
由表5 可知:第一,企业数量上,近四分之三的企业财务风险处于B、C 等级。其中,有578 家A 等级的企业、6071 家B 等级的企业、10752 家C 等级的企业、2782家D等级的企业。这是典型的样本类别不均衡现象,故本文采用SMOTE 过采样算法来解决该问题。第二,聚类后的A、B、C、D 等级企业的平均得分分别为0.4178、0.4006、0.3933、0.3853,数据上呈现逐级递减的变化趋势。第三,变异系数上,A等级的变异系数值最大,即数据的相对离散程度最高,表明A等级中企业的综合评分存在较大的波动幅度,其次是D、B、C等级。第四,未进行FCM 聚类前,被ST或∗ST处理过的企业有495 家。而进行FCM 聚类后,等级为C 的被ST 或∗ST 处理过的企业有206 家,等级为D 的被ST 或∗ST 处理过的企业有216 家,证明了熵权TOPSIS 方法和FCM聚类算法的有效性与合理性。
为了给各等级企业提供有针对性的参考意见,深入了解在不同等级中发挥重要作用的风险指标,并对企业的财务风险进行整体评估和及时调整,本文采用熵权法进一步分析各等级企业财务风险的各项指标权重。具体情况如图3所示。
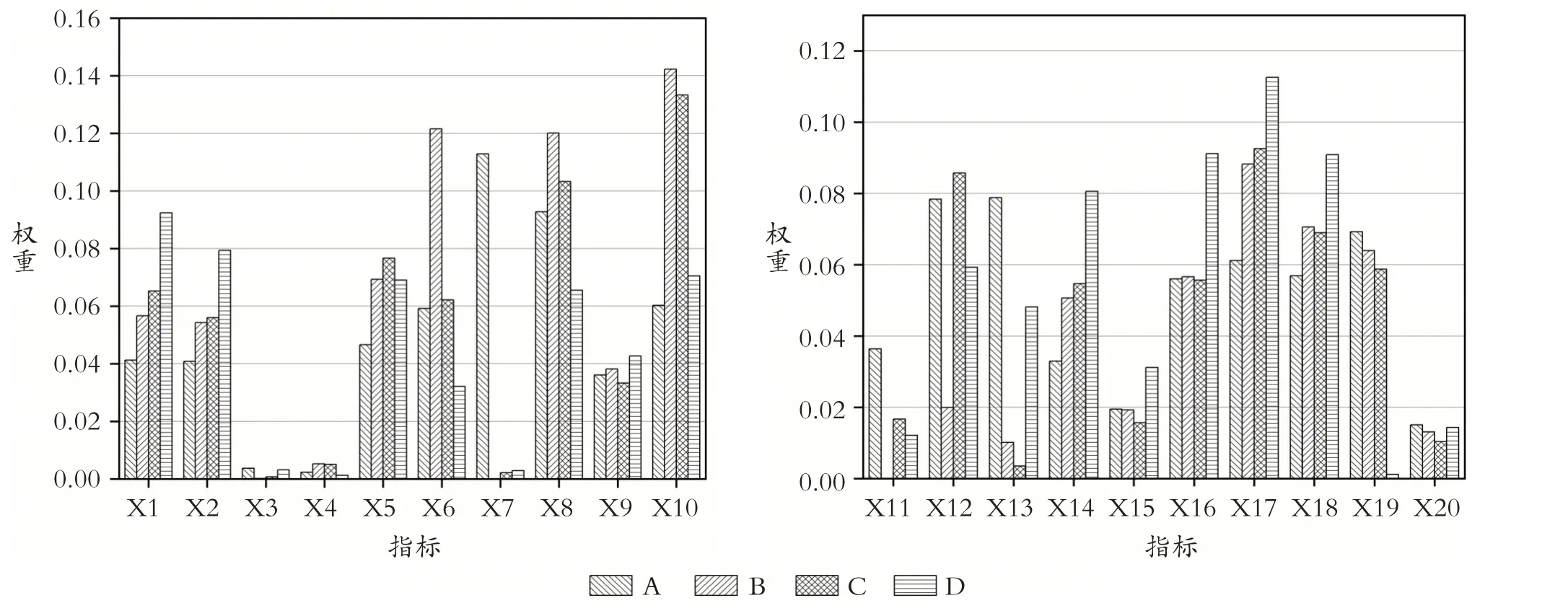
图3 各等级企业财务风险的各项指标权重对比
由图3 可知:第一,财务风险等级为A 的企业中,权重较大的指标依次为资产报酬率X7、净资产收益率X8、固定资产增长率X13、每股现金净流量X12、监事薪酬总额X19、员工人数X17、全部现金回收率X10,累计权重为0.5533;第二,财务风险等级为B 的企业中,权重较大的指标依次为全部现金回收率X10、总资产周转率X6、净资产收益率X8、员工人数X17、董事薪酬总额X18,累计权重为0.5425;第三,财务风险等级为C 的企业中,权重较大的指标依次为全部现金回收率X10、净资产收益率X8、员工人数X17、每股现金净流量X12、固定资产周转率X5、董事薪酬总额X18,累计权重为0.5603;第四,财务风险等级为D 的企业中,权重较大的指标依次为员工人数X17、流动比率X1、股东总数X16、董事薪酬总额X18、总资产增长率X14、速动比率X2,累计权重为0.5468。
以上指标对4 个等级的企业财务风险影响较大,且累计权重均超过0.5。其中,全部现金回收率X10、净资产收益率X8 和员工人数X17 对企业财务风险的影响力最为显著。因此,在对某一企业进行财务风险评估时,投资者、企业和政府可重点关注这些指标的变化情况,并据此制定科学合理的政策措施。
(三)CNN模型分类预测本实验针对财务风险的多分类问题,旨在智能预测风险等级。经过RF 筛选的7 个指标作为模型的输入变量(自变量),而将FCM聚类后的4个财务风险等级作为模型的输出变量(因变量)。CNN 模型参数设置如下:优化器采用Adam 优化器,激活函数为Relu函数,Batch_size 为64 个,CNN 层数为2 层,卷积核数量为16,卷积核大小为2,学习率lr 为0.01,迭代次数Epochs为100次。由于各等级企业的数量比A∶B∶C∶D为578∶6071∶10752∶2782,这是一个典型的类别不平衡多分类问题。因此,在将数据集输入神经网络进行训练前,首先通过SMOTE 算法对少数类别的企业样本进行下采样。随后,进行CNN 模型预测实验。最终,使用测试集来检验模型的预测性能,并获得混淆矩阵,如图4所示。

图4 本文模型在测试集上的混淆矩阵
由图4可知,本文模型的总识别率为91.70%,其中A 等级企业识别率为89.91%、B 等级企业识别率为93.44%、C等级企业识别率为89.89%、D等级企业识别率为95.61%。以上研究结果表明,本文构建的CNN模型在财务风险预测上具有可行性和有效性。
(四)多模型性能比较在熵权TOPSIS 综合评估企业、FCM划分等级后,为进一步验证本文构建的融合模型的分类效果,本文将其进行消融实验和基准模型对比实验。对比模型有RF-SMOTE-CNN模型(M1,本文模型)、RF-CNN模型(M2)、SMOTE-CNN 模型(M3)、CNN 模型(M4)、BP 神经网络模型(M5)、支持向量机SVM 模型(M6)、随机森林RF 模型(M7)、极限梯度增强树XGBoost模型(M8)、轻量梯度增强机LightGBM 模型(M9)。其中,M1 ~M4 为消融实验,M5 ~M9 为基准模型对比实验。取10 次实验的平均值作为最终结果,各模型在测试集中评估指标的对比情况如图5 所示,各模型评估指标的具体取值如表6所示。
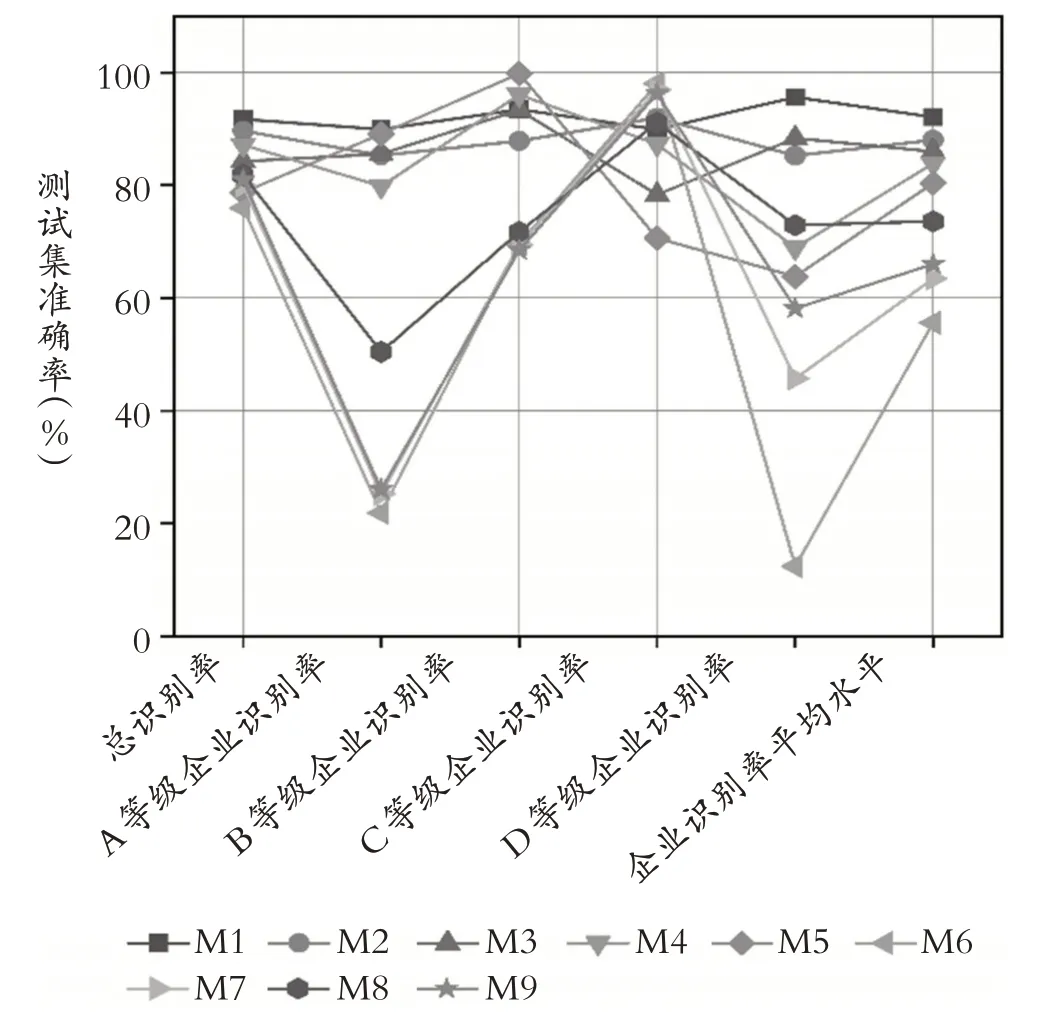
图5 各模型分类效果对比
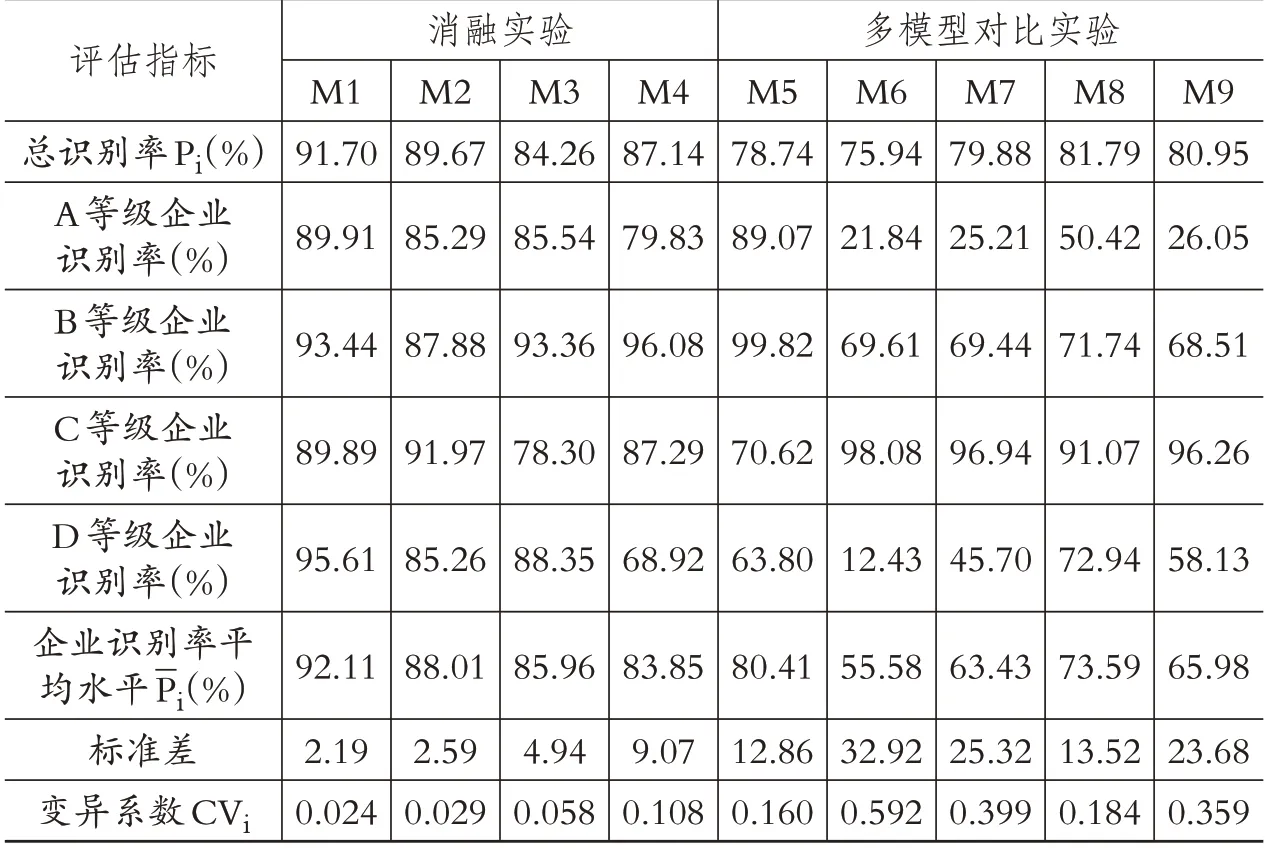
表6 各模型分类效果的具体比较
由图5 和表6 可知:第一,模型的准确性。按照企业识别率的平均水平由高到低排序为,各模型的样本识别率平均水平均高于70%,本文构建的模型M1的准确性排名第一,获得最佳的分类效果。第二,模型的全面性。已知变异系数CVi值越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序为:CVM6>CVM7>CVM9>CVM8>CVM5>CVM4>CVM3>CVM2>CVM1,本文对变异次数CVi≥0.1的模型不予考虑,则有CVM1<CVM2<CVM3<0.1。综上所述,根据“准确性>全面性”的原则,只有本文模型(M1)符合这一标准,即基于熵权TOPSIS-FCM-CNN的企业财务风险预警模型能够更有效地预测企业的财务风险等级。
此外,从表6中还发现,在消融实验中存在以下结论:第一,经过RF 筛选指标的模型M2 的样本识别率平均水平高于没有经过RF筛选指标的模型M4的样本识别率平均水平,表明利用RF算法筛选指标能够有效提高模型的预测准确率;第二,经过SMOTE过采样扩充类不平衡样本的模型M3 的样本识别率平均水平高于没有经过扩充样本的模型M4 的样本识别率平均水平,同样表明利用SMOTE过采样算法解决样本类不平衡问题,也能够有效提升模型的预测准确率。
四、结论针对现有企业财务风险预警研究仅实现风险水平的度量和评级,缺乏对财务风险等级的智能预测、财务风险数据样本不均衡问题的处理,本文以2018 ~2022年我国A股上市公司为例,提出了一种融合熵权TOPSIS-FCM-CNN 的企业财务风险预警模型并开展了相关实证分析。具体的研究结论如下:
第一,本文采用熵权TOPSIS模型对各企业的财务风险进行综合评分,并利用欧式距离来度量各企业的综合评分Gi。例如,电气机械及器材制造业中600519(2021 年)禾迈股份的财务风险较低,而零售业中2356(2018 年)赫美集团的财务风险较高。因此,上述结论也反映出我国正逐步推进高质量发展。
第二,各项指标对不同财务风险等级的企业存在不同的影响程度。在回归模型分析中,本文发现全部现金回收率指标是最重要的,高级管理人员薪酬总额指标是最不重要的;在采用熵权法来分析各财务风险等级企业的各项指标权重时,发现全部现金回收率指标在各等级企业中的权重占比较大。因此,利益相关者应重点关注以上指标的变化情况,以制定更加科学合理的决策。
第三,本文利用RF算法筛选财务风险指标,有效提高了模型的预测准确率。其中,在企业识别率平均水平上,采用该算法筛选过指标的模型为88.01%,没有筛选过指标的模型为83.85%,提升了4.16%。
第四,本文构建的模型在财务风险等级分类预测任务中表现最佳。其中,本文模型的预测准确率达到92.11%,与其他基准模型相比,平均提升了34.31%。